Creación y ejecución de canalizaciones de aprendizaje automático mediante componentes con la CLI de Azure Machine Learning
SE APLICA A:  Extensión de ML de la CLI de Azure v2 (actual)
Extensión de ML de la CLI de Azure v2 (actual)
En este artículo, aprenderá a crear y ejecutar canalizaciones de aprendizaje automático mediante la CLI de Azure y los componentes. Puede crear canalizaciones sin usar componentes, pero los componentes ofrecen el máximo nivel de flexibilidad y reutilización. Las canalizaciones de Azure Machine Learning se pueden definir en YAML y ejecutarse desde la CLI, crearse en Python, o componerse en el Diseñador de Estudio de Azure Machine Learning con una interfaz de usuario que se pueda arrastrar y colocar. Este documento se centra en la CLI.
Prerrequisitos
Si no tiene una suscripción de Azure, cree una cuenta gratuita antes de empezar. Pruebe la versión gratuita o de pago de Azure Machine Learning.
Un área de trabajo de Azure Machine Learning. Creación de recursos para el área de trabajo.
Instalación y configuración de la extensión de la CLI de Azure para Machine Learning.
Clone el repositorio de ejemplos:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/basics
Lecturas previas sugeridas
- ¿Qué es una canalización de Azure Machine Learning?
- ¿Qué es un componente de Azure Machine Learning?
Creación de la primera canalización con componente
Vamos a crear la primera canalización con componentes mediante un ejemplo. Esta sección tiene como objetivo proporcionar información inicial de la apariencia de la canalización y el componente en Azure Machine Learning con un ejemplo concreto.
Desde el directorio cli/jobs/pipelines-with-components/basics del repositorio azureml-examples, vaya al subdirectorio 3b_pipeline_with_data. Hay tres tipos de archivos en este directorio. Estos son los archivos que necesita crear al compilar su propia canalización.
pipeline.yml: este archivo YAML define la canalización de aprendizaje automático. Este archivo YAML describe cómo dividir una tarea de aprendizaje automático completa en un flujo de trabajo de varios pasos. Por ejemplo, en una tarea de aprendizaje automático simple que consista en usar datos históricos para entrenar un modelo de previsión de ventas, puede querer compilar un flujo de trabajo secuencial con pasos de procesamiento de datos, entrenamiento de modelos y evaluación de modelos. Cada paso es un componente que tiene una interfaz bien definida y que se puede desarrollar, probar y optimizar de forma independiente. La canalización YAML también define cómo se conectan los pasos secundarios con otros pasos de la canalización; por ejemplo, el paso de entrenamiento del modelo genera un archivo de modelo y este archivo pasará a un paso de evaluación del modelo.
component.yml: este archivo YAML define el componente. Empaqueta la siguiente información:
- Metadatos: nombre, nombre para mostrar, versión, descripción, tipo, etc. Los metadatos ayudan a describir y gestionar el componente.
- Interfaz: entradas y salidas. Por ejemplo, un componente de entrenamiento del modelo toma los datos de entrenamiento y el número de épocas como entrada y generará un archivo de modelo entrenado como salida. Una vez definida la interfaz, los distintos equipos pueden desarrollar y probar el componente de forma independiente.
- Comando, código y entorno: el comando, código y entorno para ejecutar el componente. "Command" es el comando shell para ejecutar el componente. Normalmente, el código hace referencia a un directorio de código fuente. El entorno puede ser un entorno de Azure Machine Learning (mantenido o creado por el cliente), una imagen de Docker o un entorno de Conda.
component_src: este es el directorio de código fuente de un componente específico. Contiene el código fuente que se ejecuta en el componente. Puede usar el lenguaje que prefiera (Python, R...), pero recuerde que un comando de shell debe ejecutar el código. El código fuente puede tomar algunas entradas de la línea de comandos de shell para controlar cómo se va a ejecutar este paso. Por ejemplo, un paso de entrenamiento puede tomar los datos de entrenamiento, la velocidad de aprendizaje y el número de épocas para controlar el proceso de entrenamiento. El argumento de un comando de shell se usa para pasar entradas y salidas al código.
Ahora vamos a crear una canalización con el ejemplo 3b_pipeline_with_data. Explicaremos el significado detallado de cada archivo en las secciones siguientes.
Primero, enumere los recursos de proceso disponibles con el siguiente comando:
az ml compute list
Si no lo tiene, cree un clúster llamado cpu-cluster mediante la ejecución de:
Nota:
Omite este paso para usar el proceso sin servidor.
az ml compute create -n cpu-cluster --type amlcompute --min-instances 0 --max-instances 10
A continuación, cree un trabajo de canalización definido en el archivo pipeline.yml con el siguiente comando. Se hace referencia al destino de proceso en el archivo pipeline.yml como azureml:cpu-cluster. Si el destino de proceso usa un nombre diferente, recuerde actualizarlo en el archivo pipeline.yml.
az ml job create --file pipeline.yml
Debe recibir un diccionario JSON con información sobre el trabajo de canalización, con la información siguiente:
| Clave | Descripción |
|---|---|
name |
Nombre basado en GUID del trabajo. |
experiment_name |
Nombre con el que se organizarán los trabajos en el estudio. |
services.Studio.endpoint |
Dirección URL para supervisar y revisar el trabajo de canalización. |
status |
El estado del trabajo. Es probable que sea Preparing en este momento. |
Abra la dirección URL de services.Studio.endpoint para ver una visualización gráfica de la canalización.
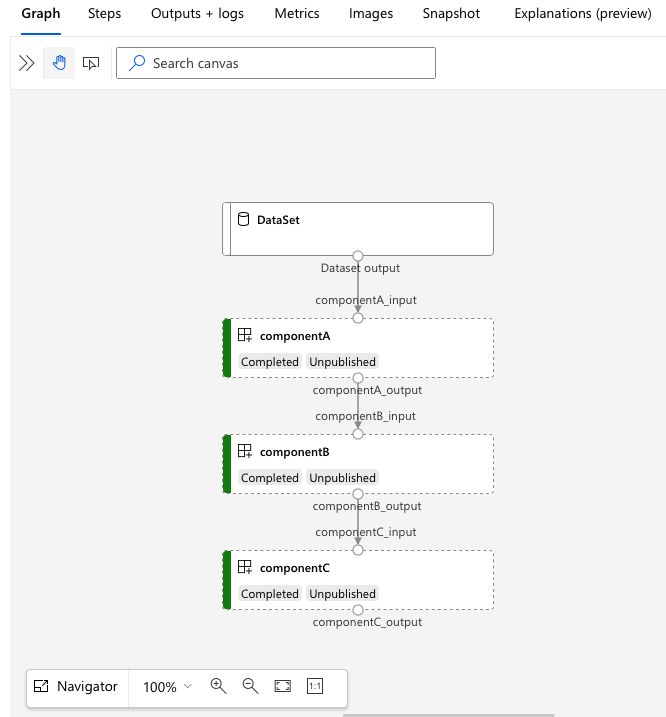
Descripción de la definición de canalización YAML
Echemos un vistazo a la definición de canalización en el archivo 3b_pipeline_with_data/pipeline.yml.
Nota:
Para usar el proceso sin servidor, reemplace default_compute: azureml:cpu-cluster por default_compute: azureml:serverless en este archivo.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 3b_pipeline_with_data
description: Pipeline with 3 component jobs with data dependencies
settings:
default_compute: azureml:cpu-cluster
outputs:
final_pipeline_output:
mode: rw_mount
jobs:
component_a:
type: command
component: ./componentA.yml
inputs:
component_a_input:
type: uri_folder
path: ./data
outputs:
component_a_output:
mode: rw_mount
component_b:
type: command
component: ./componentB.yml
inputs:
component_b_input: ${{parent.jobs.component_a.outputs.component_a_output}}
outputs:
component_b_output:
mode: rw_mount
component_c:
type: command
component: ./componentC.yml
inputs:
component_c_input: ${{parent.jobs.component_b.outputs.component_b_output}}
outputs:
component_c_output: ${{parent.outputs.final_pipeline_output}}
# mode: upload
La tabla muestra los campos más comunes del esquema YAML de canalización. Para más información, consulte el esquema YAML de canalización completa.
| key | description |
|---|---|
| type | Necesario. El tipo de trabajo debe ser pipeline para los trabajos de canalización. |
| display_name | Nombre para mostrar del trabajo de canalización en la interfaz de usuario del estudio. Editable en la interfaz de usuario del estudio. No tiene que ser único en todos los trabajos del área de trabajo. |
| jobs | Requerido. Diccionario del conjunto de trabajos individuales que se ejecutarán como pasos dentro de la canalización. Estos trabajos se consideran trabajos secundarios del trabajo de canalización primario. En esta versión, los tipos de trabajo admitidos en la canalización son command y sweep. |
| inputs | Diccionario de entradas para el trabajo de canalización. La clave es un nombre para la entrada dentro del contexto del trabajo y el valor es el valor de entrada. Las entradas de un trabajo de paso individual de la canalización pueden hacer referencia a estas entradas de canalización mediante la expresión ${{ parent.inputs.<input_name> }}. |
| outputs | Diccionario de configuraciones de salida del trabajo de canalización. La clave es un nombre para la salida dentro del contexto del trabajo y el valor es la configuración de salida. Las salidas de un trabajo de paso individual de la canalización pueden hacer referencia a estas salidas de canalización mediante la expresión ${{ parents.outputs.<output_name> }}. |
En el ejemplo 3b_pipeline_with_data, hemos creado una canalización de tres pasos.
- Los tres pasos se definen en
jobs. El tipo de tres pasos es el trabajo de comando. La definición de cada paso está en el archivocomponent.ymlcorrespondiente. Puede ver los archivos YAML del componente en el directorio 3b_pipeline_with_data. Explicaremos el elemento componentA.yml en la sección siguiente. - Esta canalización tiene dependencia de datos, que es común en la mayoría de las canalizaciones del mundo real. Component_a toma la entrada de datos de la carpeta local en
./data(línea 17-20) y pasa su salida a componentB (línea 29). Se puede hacer referencia a la salida de Component_a como${{parent.jobs.component_a.outputs.component_a_output}}. computedefine el proceso predeterminado para esta canalización. Si un componente dejobsdefine un proceso diferente para este componente, el sistema respeta la configuración específica del componente.

Lectura y escritura de datos en la canalización
Un escenario común es leer y escribir datos en la canalización. En Azure Machine Learning, usaremos el mismo esquema para leer y escribir datos en todo tipo de trabajos (trabajo de canalización, trabajo de comando y trabajo de barrido). A continuación se muestran ejemplos de trabajos de canalización de uso de datos para escenarios comunes.
- datos locales
- archivo web con dirección URL pública
- Almacén de datos y ruta de acceso de Azure Machine Learning
- Recursos de datos de Azure Machine Learning
Descripción de la definición de componentes YAML
Ahora echemos un vistazo al elemento componentA.yml como ejemplo para comprender la definición de componentes YAML.
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
type: command
name: component_a
display_name: componentA
version: 1
inputs:
component_a_input:
type: uri_folder
outputs:
component_a_output:
type: uri_folder
code: ./componentA_src
environment:
image: python
command: >-
python hello.py --componentA_input ${{inputs.component_a_input}} --componentA_output ${{outputs.component_a_output}}
El esquema más común del componente YAML se describe en la tabla. Para obtener más información, consulte el esquema YAML de componente completo.
| key | description |
|---|---|
| name | Requerido. Nombre del componente. Debe ser único en el área de trabajo de Azure Machine Learning. Debe comenzar con una letra minúscula. Debe permitir letras minúsculas, números y guiones bajos (_). La longitud máxima es de 255 caracteres. |
| display_name | Nombre para mostrar del componente en la interfaz de usuario de Studio. Puede no ser único dentro del área de trabajo. |
| comando | Es necesario el comando que se va a ejecutar. |
| código | Ruta de acceso local al directorio de código fuente que se va a cargar y usar para el componente. |
| Environment | Necesario. Entorno que se usa para ejecutar el componente. |
| inputs | Diccionario de entradas de componentes. La clave es un nombre para la entrada dentro del contexto del componente y el valor es la definición de entrada del componente. Se puede hacer referencia a las entradas en el comando mediante la expresión ${{ inputs.<input_name> }}. |
| outputs | Diccionario de salidas de componentes. La clave es un nombre para la salida dentro del contexto del componente y el valor es la definición de salida del componente. Se puede hacer referencia a las salidas en el comando mediante la expresión ${{ outputs.<output_name> }}. |
| is_deterministic | Ya sea para reutilizar el resultado del trabajo anterior si las entradas del componente no cambiaron. El valor predeterminado es true, también conocido como un valor que se vuelve a usar de forma predeterminada. El escenario común cuando se establece como false es forzar la recarga de datos desde un almacenamiento en la nube o una dirección URL. |
Por ejemplo, en 3b_pipeline_with_data/componentA.yml, componentA tiene una entrada y una salida de datos que se puede conectar a otros pasos de la canalización primaria. Todos los archivos de la sección code del componente YAML se cargarán en Azure Machine Learning al enviar el trabajo de canalización. En este ejemplo, los archivos de ./componentA_src en se cargarán (línea 16 en componentA.yml). Puede ver el código fuente cargado en la interfaz de usuario del estudio: seleccione el paso ComponentA y vaya a la pestaña Instantánea, tal como se muestra en la captura de pantalla siguiente. Puede ver que es un script de tipo "hola mundo" si hace una impresión sencilla y escribe la fecha y hora actual en la ruta de acceso componentA_output. El componente toma la entrada y la salida a través del argumento de la línea de comandos y se controla en el elemento hello.py mediante argparse.

Entrada y salida
La entrada y la salida definen la interfaz de un componente. La entrada y la salida pueden ser de un valor literal (de tipo string, number, integer o boolean) o un objeto que contiene el esquema de entrada.
La entrada de objeto (de tipo uri_file, uri_folder, mltable, mlflow_model, custom_model) puede conectarse a otros pasos del trabajo de canalización principal y, por tanto, pasar datos o modelos a otros pasos. En el gráfico de canalización, la entrada de tipo de objeto se representa como un punto de conexión.
Las entradas de valor literal (string, number, integer, boolean) son los parámetros que puede pasar al componente en tiempo de ejecución. Puede agregar el valor predeterminado de las entradas literales en el campo default. Para los tipos number y integer, también puede agregar el mínimo y máximo del valor aceptado mediante los campos min y max. Si el valor de entrada supera el mínimo y el máximo, se produce un error en la canalización de la validación. La validación se produce antes de enviar un trabajo de canalización para ahorrar tiempo. La validación funciona para la CLI, el SDK de Python y la interfaz de usuario del diseñador. En la captura de pantalla siguiente se muestra un ejemplo de validación en la interfaz de usuario del diseñador. De forma similar, puede definir valores permitidos en el campo enum.

Si desea agregar una entrada a un componente, recuerde editar tres lugares:
- El campo
inputsen el componente YAML - El campo
commanden el componente YAML. - El código fuente del componente para controlar la entrada de la línea de comandos. Está marcado en el cuadro verde de la captura de pantalla anterior.
Para más información sobre las entradas y salidas, consulte Administración de entradas y salidas de componentes y canalizaciones.
Environment
El valor "Entorno" define el entorno para ejecutar el componente. Puede ser un entorno de Azure Machine Learning (mantenido o registrado por el cliente), una imagen de Docker o un entorno de Conda. Algunos ejemplos:
- Recurso de entorno registrado de Azure Machine Learning. Se hace referencia a él en la sintaxis
azureml:<environment-name>:<environment-version>del componente siguiente. - imagen pública de Docker
- archivo Conda El archivo Conda debe usarse junto con una imagen base.
Registro de componentes para reutilizarlos y compartirlos
Aunque algunos componentes son específicos de una canalización determinada, la ventaja real de los componentes procede de la reutilización y el uso compartido. Registre un componente en el área de trabajo de Machine Learning para que esté disponible para su reutilización. Los componentes registrados admiten el control de versiones automático para que pueda actualizar el componente, pero asegúrese de que las canalizaciones que requieren una versión anterior sigan funcionando.
En el repositorio azureml-examples, vaya al directorio cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components.
Para registrar un componente, use el comando az ml component create:
az ml component create --file train.yml
az ml component create --file score.yml
az ml component create --file eval.yml
Después de que estos comandos se ejecuten hasta su finalización, puede ver los componentes en Studio en Recurso: componentes >:

Seleccione un componente. Verá información detallada de cada versión del componente.
En la pestaña Detalles, verá información básica del componente, como el nombre, el creador, la versión, etc. También verá campos editables para etiquetas y la descripción. Las etiquetas se pueden usar para agregar palabras clave de búsqueda rápida. El campo de descripción admite el formato Markdown y debe usarse para describir la funcionalidad y el uso básico del componente.
En la pestaña Trabajos, verá el historial de todos los trabajos que usan este componente.
Uso de componentes registrados en un archivo YAML de un trabajo de canalización
Vamos a usar 1b_e2e_registered_components para demostrar cómo usar el componente registrado en la canalización YAML. Vaya al directorio 1b_e2e_registered_components y abra el archivo pipeline.yml. Las claves y los valores de los campos inputs y outputs son similares a los que ya se han analizado. La única diferencia significativa es el valor del campo component de las entradas jobs.<JOB_NAME>.component. El valor component tiene el formato azureml:<COMPONENT_NAME>:<COMPONENT_VERSION>. La definición train-job, por ejemplo, especifica que se debe usar la última versión del componente registrado my_train:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
Administración de componentes
Puede comprobar los detalles de un componente y administrarlo mediante la CLI (v2). Use az ml component -h para obtener instrucciones detalladas sobre los comandos de componentes. En la siguiente tabla se enumeran todos los comandos disponibles. Consulte más ejemplos en la referencia de la CLI de Azure.
| commands | description |
|---|---|
az ml component create |
Crear un componente |
az ml component list |
Enumeración de componentes en un área de trabajo |
az ml component show |
Visualización de detalles de un componente |
az ml component update |
Actualización de un componente Solo algunos campos (descripción, display_name) admiten la actualización |
az ml component archive |
Archivo de un contenedor de componentes |
az ml component restore |
Restauración de un componente archivado |
Pasos siguientes
- Pruebe el ejemplo del componente de la CLI v2.