Depuración interactiva con Visual Studio Code
SE APLICA A: Azure ML del SDK de Python v1
Azure ML del SDK de Python v1
Aprenda a depurar de manera interactiva experimentos, canalizaciones e implementaciones de Azure Machine Learning con Visual Studio Code (VS Code) y depugpy.
Ejecución y depuración de experimentos de manera local
Use la extensión de Azure Machine Learning para validar, ejecutar y depurar los experimentos de aprendizaje automático antes de enviarlos a la nube.
Requisitos previos
Extensión de Azure Machine Learning para VS Code (versión preliminar) Para más información, consulte Configuración de la extensión de Azure Machine Learning para VS Code.
Importante
La extensión Azure Machine Learning para VS Code usa la CLI (v2) de manera predeterminada. En las instrucciones de esta guía se usa la CLI 1.0. Para cambiar a la experiencia de la CLI 1.0, defina la opción
azureML.CLI Compatibility Modeen Visual Studio Code como1.0. Para más información sobre cómo modificar la configuración en Visual Studio Code, consulte la documentación de la configuración de usuario y área de trabajo.Importante
Esta característica actualmente está en su versión preliminar pública. Esta versión preliminar se ofrece sin un Acuerdo de Nivel de Servicio y no se recomienda para cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas.
Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
-
Docker Desktop para Mac y Windows
Motor de Docker para Linux.
Nota
En Windows, asegúrese de configurar Docker para usar contenedores de Linux.
Sugerencia
En Windows, aunque no es necesario, se recomienda encarecidamente usar Docker con el subsistema de Windows para Linux (WSL) 2.
Depuración del experimento de manera local
Importante
Antes de ejecutar el experimento de manera local, asegúrese de que.
- Docker se está ejecutando.
- El valor
azureML.CLI Compatibility Modede Visual Studio Code se establece en1.0como se especifica en los requisitos previos.
En VS Code, abra la vista de la extensión de Azure Machine Learning.
Expanda el nodo de suscripción que contiene el área de trabajo. Si aún no tiene una, puede crear un área de trabajo de Azure Machine Learning mediante la extensión.
Expanda el nodo del área de trabajo.
Haga clic con el botón derecho en el nodo Experiments (Experimentos) y seleccione Create experiment (Crear experimento). Cuando se le pida, proporcione un nombre para el experimento.
Expanda el nodo Experiments (Experimentos), haga clic con el botón derecho en el experimento que quiera ejecutar y seleccione Run Experiment (Ejecutar experimento).
En la lista de opciones, seleccione Local.
Uso por primera vez solo en Windows. Cuando se le pregunte si desea permitir recursos compartidos de archivos, seleccione Yes (Sí). Cuando habilita los recursos compartidos de archivos, permite que Docker monte el directorio que contiene el script en el contenedor. Además, también permite que Docker almacene los registros y los resultados de la ejecución en un directorio temporal del sistema.
Seleccione Yes (Sí) para depurar el experimento. De lo contrario, seleccione No. Si selecciona No, el experimento se ejecutará de manera local sin asociarse al depurador.
Seleccione Create new Run Configuration (Crear configuración de ejecución) para crear la configuración de ejecución. La configuración de ejecución define el script que quiere ejecutar, las dependencias y los conjuntos de datos usados. Como alternativa, si ya tiene una, selecciónela en la lista desplegable.
- Elija el entorno. Puede elegir cualquiera de los mantenidos por Azure Machine Learning o crear el suyo propio.
- Proporcione el nombre del script que quiere ejecutar. La ruta de acceso es relativa al directorio abierto en VS Code.
- Elija si quiere usar un conjunto de datos de Azure Machine Learning o no. Puede crear conjuntos de datos de Azure Machine Learning mediante la extensión.
- La herramienta debugpy es necesaria para asociar el depurador al contenedor que ejecuta el experimento. Para agregar debugpy como dependencia, seleccione Add Debugpy (Agregar debugpy). De lo contrario, seleccione Skip (Omitir). Si no se agrega debugpy como dependencia, el experimento se ejecuta sin asociarse al depurador.
- En el editor, se abre un archivo de configuración que contiene los valores de configuración de ejecución. Si está satisfecho con la configuración, seleccione Submit experiment (Enviar experimento). Como alternativa, abra la paleta de comandos (View > Command Palette [Ver > Paleta de comandos]) en la barra de menús y escriba el comando
AzureML: Submit experimenten el cuadro de texto.
Una vez enviado el experimento, se crea una imagen de Docker que contiene el script y las configuraciones especificadas en la configuración de ejecución.
Cuando se inicia el proceso de compilación de la imagen de Docker, el contenido del archivo
60_control_log.txtse transmite a la consola de salida en VS Code.Nota
La primera vez que se crea la imagen de Docker, esta operación puede tardar varios minutos.
Después de que se ha creado la imagen, aparece un aviso para iniciar el depurador. Establezca los puntos de interrupción en el script y, cuando esté preparado para comenzar la depuración, seleccione Iniciar depuración. Al hacerlo, se asocia el depurador de VS Code al contenedor que ejecuta el experimento. Como alternativa, en la extensión de Azure Machine Learning, mantenga el mouse sobre el nodo de la ejecución actual y seleccione el icono de reproducción para iniciar el depurador.
Importante
No puede tener varias sesiones de depuración para un solo experimento. Sin embargo, puede depurar dos o más experimentos mediante varias instancias de VS Code.
Llegados a este punto, debería poder recorrer el código y depurarlo mediante VS Code.
Si en algún momento quiere cancelar la ejecución, haga clic con el botón derecho en el nodo de ejecución y seleccione Cancelar ejecución.
De forma similar a las ejecuciones de experimentos remotas, puede expandir el nodo de ejecución para inspeccionar los registros y las salidas.
Sugerencia
Las imágenes de Docker que usan las mismas dependencias definidas en el entorno se reutilizan entre ejecuciones. Sin embargo, si ejecuta un experimento con un entorno nuevo o diferente, se crea otra imagen. Dado que estas imágenes se guardan en el almacenamiento local, se recomienda quitar las imágenes de Docker antiguas o sin usar. Para quitar imágenes del sistema, use la CLI de Docker o la extensión de Docker para VS Code.
Depuración y solución de problemas de canalizaciones de aprendizaje automático
En algunos casos, es posible que tenga que depurar interactivamente el código de Python usado en la canalización de ML. Mediante VS Code y debugpy, se puede conectar al código que se ejecuta en el entorno de entrenamiento.
Prerrequisitos
Un área de trabajo de Azure Machine Learning configurada para usar Azure Virtual Network.
Una canalización de Azure Machine Learning que use scripts de Python como parte de los pasos de la canalización. Por ejemplo, PythonScriptStep.
Un clúster de Proceso de Azure Machine Learning, que se encuentre en la red virtual y lo use la canalización para el aprendizaje.
Un entorno de desarrollo que se encuentre en la red virtual. El entorno de desarrollo puede ser uno de los siguientes:
- Una máquina virtual de Azure en la red virtual
- Una instancia de proceso de VM de cuadernos en la red virtual
- Una máquina cliente que tenga conectividad de red privada con la red virtual, ya sea por VPN o a través de ExpressRoute.
Para más información sobre el uso de Azure Virtual Network con Azure Machine Learning, consulte Información general sobre la privacidad y el aislamiento de la red virtual.
Sugerencia
Aunque puede trabajar con recursos de Azure Machine Learning que no están detrás de una red virtual, se recomienda usar una red virtual.
Funcionamiento
Los pasos de la canalización de ML ejecutan scripts de Python. Estos scripts se modifican para realizar las siguientes acciones:
Registrar la dirección IP del host en el que se ejecutan. Se usa la dirección IP para conectar el depurador al script.
Iniciar el componente de depuración debugpy y esperar a que se conecte un depurador.
En el entorno de desarrollo, se supervisan los registros creados por el proceso de aprendizaje para encontrar la dirección IP en la que se ejecuta el script.
Se indica a VS Code la dirección IP a la que se debe conectar el depurador mediante un archivo
launch.json.Se conecta el depurador y se recorre el script de forma interactiva.
Configuración de scripts de Python
Para habilitar la depuración, realice los cambios siguientes en los scripts de Python que se usan en los pasos de la canalización de ML:
Agregue las siguientes instrucciones import:
import argparse import os import debugpy import socket from azureml.core import RunAgregue los siguientes argumentos. Estos argumentos permiten habilitar el depurador según sea necesario y establecer el tiempo de espera para la conexión del depurador:
parser.add_argument('--remote_debug', action='store_true') parser.add_argument('--remote_debug_connection_timeout', type=int, default=300, help=f'Defines how much time the Azure Machine Learning compute target ' f'will await a connection from a debugger client (VSCODE).') parser.add_argument('--remote_debug_client_ip', type=str, help=f'Defines IP Address of VS Code client') parser.add_argument('--remote_debug_port', type=int, default=5678, help=f'Defines Port of VS Code client')Agregue las siguientes instrucciones. Estas instrucciones cargan el contexto de ejecución actual para que pueda registrar la dirección IP del nodo en el que se está ejecutando el código:
global run run = Run.get_context()Agregue una instrucción
ifque inicie debugpy y espere a que se conecte un depurador. Si no se conecta ningún depurador antes de que finalice el tiempo de espera, el script continúa de la forma habitual. Asegúrese de reemplazar los valoresHOSTyPORTde la funciónlistenpor los propios.if args.remote_debug: print(f'Timeout for debug connection: {args.remote_debug_connection_timeout}') # Log the IP and port try: ip = args.remote_debug_client_ip except: print("Need to supply IP address for VS Code client") print(f'ip_address: {ip}') debugpy.listen(address=(ip, args.remote_debug_port)) # Wait for the timeout for debugger to attach debugpy.wait_for_client() print(f'Debugger attached = {debugpy.is_client_connected()}')
En el siguiente ejemplo de Python se muestra un archivo train.py de ejemplo que habilita la depuración:
# Copyright (c) Microsoft. All rights reserved.
# Licensed under the MIT license.
import argparse
import os
import debugpy
import socket
from azureml.core import Run
print("In train.py")
print("As a data scientist, this is where I use my training code.")
parser = argparse.ArgumentParser("train")
parser.add_argument("--input_data", type=str, help="input data")
parser.add_argument("--output_train", type=str, help="output_train directory")
# Argument check for remote debugging
parser.add_argument('--remote_debug', action='store_true')
parser.add_argument('--remote_debug_connection_timeout', type=int,
default=300,
help=f'Defines how much time the Azure Machine Learning compute target '
f'will await a connection from a debugger client (VSCODE).')
parser.add_argument('--remote_debug_client_ip', type=str,
help=f'Defines IP Address of VS Code client')
parser.add_argument('--remote_debug_port', type=int,
default=5678,
help=f'Defines Port of VS Code client')
# Get run object, so we can find and log the IP of the host instance
global run
run = Run.get_context()
args = parser.parse_args()
# Start debugger if remote_debug is enabled
if args.remote_debug:
print(f'Timeout for debug connection: {args.remote_debug_connection_timeout}')
# Log the IP and port
ip = socket.gethostbyname(socket.gethostname())
# try:
# ip = args.remote_debug_client_ip
# except:
# print("Need to supply IP address for VS Code client")
print(f'ip_address: {ip}')
debugpy.listen(address=(ip, args.remote_debug_port))
# Wait for the timeout for debugger to attach
debugpy.wait_for_client()
print(f'Debugger attached = {debugpy.is_client_connected()}')
print("Argument 1: %s" % args.input_data)
print("Argument 2: %s" % args.output_train)
if not (args.output_train is None):
os.makedirs(args.output_train, exist_ok=True)
print("%s created" % args.output_train)
Configuración de la canalización de ML
Para proporcionar los paquetes de Python necesarios para iniciar debugpy y obtener el contexto de ejecución, cree un entorno y establezca pip_packages=['debugpy', 'azureml-sdk==<SDK-VERSION>']. Cambie la versión del SDK para que coincida con la que está usando. El fragmento de código siguiente muestra cómo crear un entorno:
# Use a RunConfiguration to specify some additional requirements for this step.
from azureml.core.runconfig import RunConfiguration
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core.runconfig import DEFAULT_CPU_IMAGE
# create a new runconfig object
run_config = RunConfiguration()
# enable Docker
run_config.environment.docker.enabled = True
# set Docker base image to the default CPU-based image
run_config.environment.docker.base_image = DEFAULT_CPU_IMAGE
# use conda_dependencies.yml to create a conda environment in the Docker image for execution
run_config.environment.python.user_managed_dependencies = False
# specify CondaDependencies obj
run_config.environment.python.conda_dependencies = CondaDependencies.create(conda_packages=['scikit-learn'],
pip_packages=['debugpy', 'azureml-sdk==<SDK-VERSION>'])
En la sección Configuración de scripts de Python, se agregaron nuevos argumentos a los scripts usados por los pasos de la canalización de ML. En el fragmento de código siguiente se muestra cómo usar estos argumentos para habilitar la depuración del componente y establecer un tiempo de espera. También se muestra cómo usar el entorno creado anteriormente estableciendo runconfig=run_config:
# Use RunConfig from a pipeline step
step1 = PythonScriptStep(name="train_step",
script_name="train.py",
arguments=['--remote_debug', '--remote_debug_connection_timeout', 300,'--remote_debug_client_ip','<VS-CODE-CLIENT-IP>','--remote_debug_port',5678],
compute_target=aml_compute,
source_directory=source_directory,
runconfig=run_config,
allow_reuse=False)
Cuando se ejecuta la canalización, cada paso crea una ejecución secundaria. Si está habilitada la depuración, el script modificado registra información similar al siguiente texto en 70_driver_log.txt para la ejecución secundaria:
Timeout for debug connection: 300
ip_address: 10.3.0.5
Guarde el valor de ip_address. Se usa en la siguiente sección.
Sugerencia
También puede encontrar la dirección IP en los registros de la ejecución secundaria para este paso de canalización. Para obtener más información sobre cómo ver esta información, vea Supervisión de métricas y ejecuciones de experimentos de Azure Machine Learning.
Configuración del entorno de desarrollo
Para instalar debugpy en el entorno de desarrollo de VS Code, use el comando siguiente:
python -m pip install --upgrade debugpyPara obtener más información sobre cómo usar debugpy con VS Code, consulte Depuración remota.
Para configurar VS Code para comunicarse con el proceso de Azure Machine Learning que ejecuta el depurador, cree una nueva configuración de depuración:
En VS Code, seleccione el menú Depurar y, luego, seleccione Abrir configuraciones. Se abre un archivo denominado launch.json.
En el archivo launch.json, busque la línea que contiene
"configurations": [e inserte el texto siguiente después de ella. Cambie la entrada"host": "<IP-ADDRESS>"a la dirección IP devuelta en los registros de la sección anterior. Cambie la entrada"localRoot": "${workspaceFolder}/code/step"a un directorio local que contenga una copia del script que se está depurando:{ "name": "Azure Machine Learning Compute: remote debug", "type": "python", "request": "attach", "port": 5678, "host": "<IP-ADDRESS>", "redirectOutput": true, "pathMappings": [ { "localRoot": "${workspaceFolder}/code/step1", "remoteRoot": "." } ] }Importante
Si ya hay otras entradas en la sección de configuraciones, agregue una coma (,) después del código que insertó.
Sugerencia
El procedimiento recomendado, especialmente en el caso de las canalizaciones, es mantener los recursos de los scripts en directorios independientes para que el código sea pertinente solo para cada uno de los pasos. En este ejemplo, el valor de ejemplo
localRoothace referencia a/code/step1.Si va a depurar varios scripts en directorios diferentes, cree una sección de configuración independiente para cada script.
Guarde el archivo launch.json.
Conexión del depurador
Abra VS Code y abra una copia local del script.
Establezca puntos de interrupción donde desee que se detenga el script una vez que se haya conectado.
Mientras el proceso secundario ejecuta el script y se muestra
Timeout for debug connectionen los registros, use la tecla F5 o seleccione Depurar. Cuando se le solicite, seleccione la configuración Azure Machine Learning Compute: remote debug (Proceso de Azure Machine Learning: depuración remota). También puede seleccionar el icono de depuración en la barra lateral, la entrada Azure Machine Learning: remote debug (Azure Machine Learning: depuración remota) en el menú desplegable Depurar y, a continuación, usar la flecha verde para conectar el depurador.En este punto, VS Code se conecta a debugpy en el nodo de ejecución y se detiene en el punto de interrupción que se estableció anteriormente. Ahora puede recorrer el código a medida que se ejecuta, ver variables, etc.
Nota
Si el registro muestra una entrada que indica
Debugger attached = False, el tiempo de espera ha expirado y el script ha continuado sin el depurador. Vuelva a enviar la canalización y conecte el depurador después del mensaje deTimeout for debug connectiony antes de que expire el tiempo de espera.
Depuración y solución de problemas de implementaciones
En algunos casos, es posible que tenga que depurar interactivamente el código de Python incluido en la implementación de modelo. Por ejemplo, si el script de entrada presenta errores y no se puede determinar el motivo mediante un registro adicional. Mediante VS Code y debugpy, puede conectarse al código que se ejecuta en el contenedor de Docker.
Sugerencia
Si usa puntos de conexión e implementaciones en línea administrados localmente, consulte Depuración local de puntos de conexión en línea administrados en Visual Studio Code (versión preliminar).
Importante
Este método de depuración no funciona cuando se usa Model.deploy() y LocalWebservice.deploy_configuration para implementar un modelo de manera local. En su lugar, debe crear una imagen con el método Model.package().
Las implementaciones de servicios web locales requieren una instalación de Docker en funcionamiento en el sistema local. Para obtener más información sobre el uso de Docker, consulte la Documentación de Docker. Al trabajar con instancias de proceso, Docker ya está instalado.
Configuración del entorno de desarrollo
Para instalar debugpy en el entorno de desarrollo de VS Code local, use el comando siguiente:
python -m pip install --upgrade debugpyPara obtener más información sobre cómo usar debugpy con VS Code, consulte Depuración remota.
Para configurar VS Code para comunicarse con la imagen de Docker, cree una configuración de depuración nueva:
En VS Code, seleccione el menú Depurar en la extensión Ejecutar y, luego, seleccione Abrir configuraciones. Se abre un archivo denominado launch.json.
En el archivo launch.json, busque el elemento "configuraciones" (la línea que contiene
"configurations": [) e inserte el texto siguiente después de ella.{ "name": "Azure Machine Learning Deployment: Docker Debug", "type": "python", "request": "attach", "connect": { "port": 5678, "host": "0.0.0.0", }, "pathMappings": [ { "localRoot": "${workspaceFolder}", "remoteRoot": "/var/azureml-app" } ] }Después de la inserción, el archivo launch.json debe ser similar al siguiente:
{ // Use IntelliSense to learn about possible attributes. // Hover to view descriptions of existing attributes. // For more information, visit: https://go.microsoft.com/fwlink/linkid=830387 "version": "0.2.0", "configurations": [ { "name": "Python: Current File", "type": "python", "request": "launch", "program": "${file}", "console": "integratedTerminal" }, { "name": "Azure Machine Learning Deployment: Docker Debug", "type": "python", "request": "attach", "connect": { "port": 5678, "host": "0.0.0.0" }, "pathMappings": [ { "localRoot": "${workspaceFolder}", "remoteRoot": "/var/azureml-app" } ] } ] }Importante
Si ya hay otras entradas en la sección de configuraciones, agregue una coma ( , ) después del código que insertó.
Esta sección se adjunta al contenedor de Docker mediante el puerto 5678.
Guarde el archivo launch.json.
Creación de una imagen que incluye debugpy
Modifique el entorno de conda para la implementación de manera que incluya debugpy. En el ejemplo siguiente se muestra cómo se agrega con el parámetro
pip_packages:from azureml.core.conda_dependencies import CondaDependencies # Usually a good idea to choose specific version numbers # so training is made on same packages as scoring myenv = CondaDependencies.create(conda_packages=['numpy==1.15.4', 'scikit-learn==0.19.1', 'pandas==0.23.4'], pip_packages = ['azureml-defaults==1.0.83', 'debugpy']) with open("myenv.yml","w") as f: f.write(myenv.serialize_to_string())Para iniciar debugpy y esperar una conexión cuando se inicia el servicio, agregue lo siguiente en la parte superior del archivo
score.py:import debugpy # Allows other computers to attach to debugpy on this IP address and port. debugpy.listen(('0.0.0.0', 5678)) # Wait 30 seconds for a debugger to attach. If none attaches, the script continues as normal. debugpy.wait_for_client() print("Debugger attached...")Cree una imagen basada en la definición de entorno y extráigala en el Registro local.
Nota
En este ejemplo se da por supuesto que
wsapunta al área de trabajo de Azure Machine Learning y quemodeles el modelo que se está implementando. El archivomyenv.ymlcontiene las dependencias de conda creadas en el paso 1.from azureml.core.conda_dependencies import CondaDependencies from azureml.core.model import InferenceConfig from azureml.core.environment import Environment myenv = Environment.from_conda_specification(name="env", file_path="myenv.yml") myenv.docker.base_image = None myenv.docker.base_dockerfile = "FROM mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04:latest" inference_config = InferenceConfig(entry_script="score.py", environment=myenv) package = Model.package(ws, [model], inference_config) package.wait_for_creation(show_output=True) # Or show_output=False to hide the Docker build logs. package.pull()Una vez que se haya creado y descargado la imagen (este proceso puede tardar más de 10 minutos), la ruta de acceso de la misma (incluye el repositorio, el nombre y la etiqueta, que en este caso también es su resumen) se mostrará finalmente en un mensaje similar al siguiente:
Status: Downloaded newer image for myregistry.azurecr.io/package@sha256:<image-digest>Para facilitar el trabajo con la imagen localmente, puede usar el comando siguiente para agregar una etiqueta para esta imagen. Reemplace
myimagepathen el siguiente comando por el valor de la ubicación del paso anterior.docker tag myimagepath debug:1Para el resto de los pasos, puede hacer referencia a la imagen local como
debug:1en lugar del valor de la ruta de acceso completa a la imagen.
Depuración del servicio
Sugerencia
Si establece un tiempo de expiración para la conexión de debugpy en el archivo score.py, debe conectar VS Code a la sesión de depuración antes de que se cumpla el tiempo de expiración. Inicie VS Code, abra la copia local de score.py, establezca un punto de interrupción y prepárelo antes de seguir los pasos de esta sección.
Para más información sobre la depuración y el establecimiento de puntos de interrupción, consulte Depuración.
Para iniciar un contenedor de Docker con la imagen, use el comando siguiente:
docker run -it --name debug -p 8000:5001 -p 5678:5678 -v <my_local_path_to_score.py>:/var/azureml-app/score.py debug:1 /bin/bashEste comando asocia el archivo
score.pylocalmente al del contenedor. Por lo tanto, los cambios realizados en el editor se verán reflejados automáticamente en el contenedor.Para una mejor experiencia, puede entrar en el contenedor con una nueva interfaz de VS Code. Seleccione la extensión
Dockeren la barra lateral de VS Code, busque el contenedor local creado que, en esta documentación, se denominadebug:1. Haga clic con el botón derecho en este contenedor y seleccione"Attach Visual Studio Code", se abrirá automáticamente una nueva interfaz de VS Code que mostrará el interior del contenedor creado.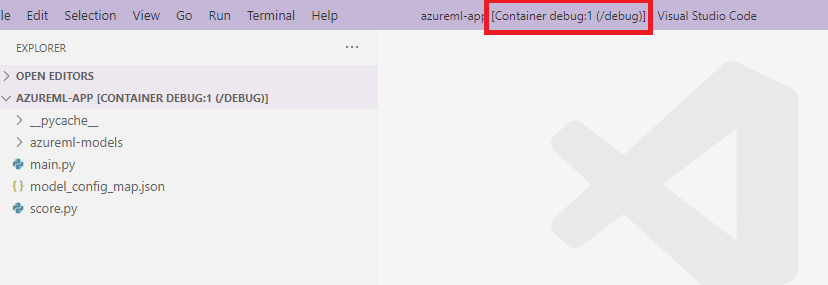
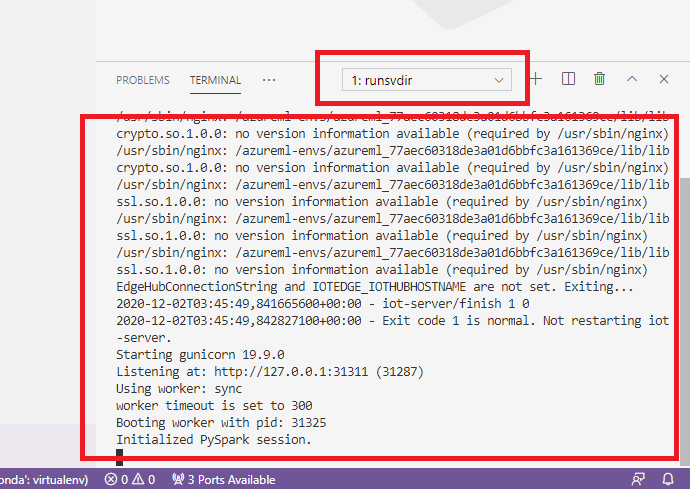
En el contenedor, ejecute el comando siguiente en el shell.
runsvdir /var/runitA continuación, puede ver la siguiente salida en el shell dentro del contenedor:
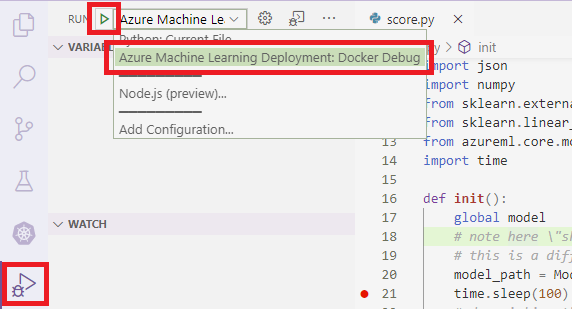
Para adjuntar VS Code a debugpy dentro del contenedor, abra VS Code y use la tecla F5 o seleccione Depurar. Cuando se le solicite, seleccione la configuración Azure Machine Learning Deployment: Docker Debug (Azure Machine Learning Service: depuración de Docker). También puede seleccionar el icono de la extensión Ejecutar en la barra lateral, la entrada Azure Machine Learning Deployment: Docker Debug (Azure Machine Learning Service: depuración de Docker) en el menú desplegable Depurar y, luego, use la flecha verde para adjuntar el depurador.
Después de seleccionar la flecha verde y adjuntar el depurador, en la interfaz del contenedor VS Code puede ver alguna información nueva:
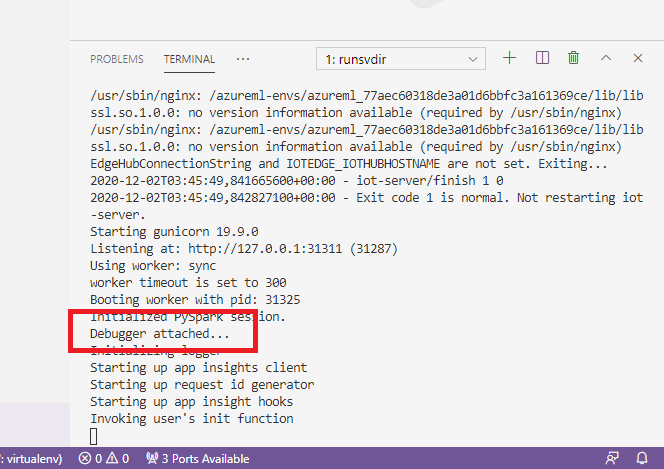
Además, en la interfaz principal de VS Code, lo que puede ver es lo siguiente:
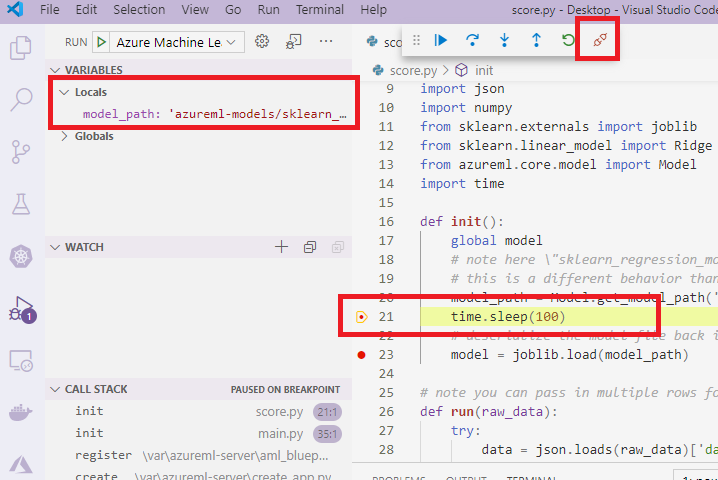
Y ahora, el archivo score.py local que está asociado al contenedor ya se ha detenido en los puntos de interrupción establecidos. En este punto, VS Code se conecta a debugpy dentro del contenedor de Docker y detiene a este en el punto de interrupción que se estableció anteriormente. Ahora puede recorrer el código a medida que se ejecuta, ver variables, etc.
Para más información sobre cómo usar VS Code para implementar Python, consulte Depurar el código de Python.
Detención del contenedor
Para detener el contenedor, use el comando siguiente:
docker stop debug
Pasos siguientes
Ahora que ha configurado VS Code remoto, puede usar una instancia de proceso como proceso remoto desde VS Code para depurar el código de forma interactiva.
Más información sobre solución de problemas: