Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
El entrenamiento del modelo de Machine Learning es un proceso iterativo y requiere una experimentación significativa. Con la experiencia de trabajo interactivo de Azure Machine Learning, los científicos de datos pueden usar el SDK de Python de Azure Machine Learning, la CLI de Azure Machine Learning o Azure Studio para acceder al contenedor donde se ejecuta su trabajo. Una vez que se accede al contenedor de trabajos, los usuarios pueden iterar en scripts de entrenamiento, supervisar el progreso del entrenamiento o depurar el trabajo de forma remota como lo hacen normalmente en sus máquinas locales. Se puede interactuar con los trabajos mediante diferentes aplicaciones de entrenamiento, como JupyterLab, TensorBoard, VS Code o mediante la conexión directa al contenedor de trabajos a través de SSH.
El entrenamiento interactivo es compatible con los clústeres de proceso de Azure Machine Learning y el clúster de Kubernetes habilitado para Azure Arc.
Prerrequisitos
- Revise la introducción al entrenamiento en Azure Machine Learning.
- Para obtener más información, consulte este vínculo para VS Code para configurar la extensión de Azure Machine Learning.
- Asegúrese de que el entorno de trabajo tiene instalados los paquetes
openssh-serveryipykernel ~=6.0(todos los entornos de entrenamiento mantenidos de Azure Machine Learning tienen estos paquetes instalados de forma predeterminada). - Las aplicaciones interactivas no se pueden habilitar en ejecuciones de entrenamiento distribuido en las que el tipo de distribución es distinto de PyTorch, TensorFlow o MPI. Actualmente no se admite la configuración del entrenamiento distribuido personalizado (configuración del entrenamiento de varios nodos sin usar los marcos de distribución anteriores).
- Para usar SSH, necesitará un par de claves SSH. Es posible usar el comando
ssh-keygen -f "<filepath>"para generar un par de claves privadas y públicas.
Interacción con el contenedor de trabajos
Al especificar aplicaciones interactivas en la creación de trabajos, puede conectarse directamente al contenedor en el nodo de proceso donde se ejecuta el trabajo. Una vez que tenga acceso al contenedor de trabajos, puede probar o depurar el trabajo en el mismo entorno en el que se ejecutaría. También puede usar VS Code para asociar al proceso en ejecución y depurar como lo haría localmente.
Habilitación durante el envío del trabajo
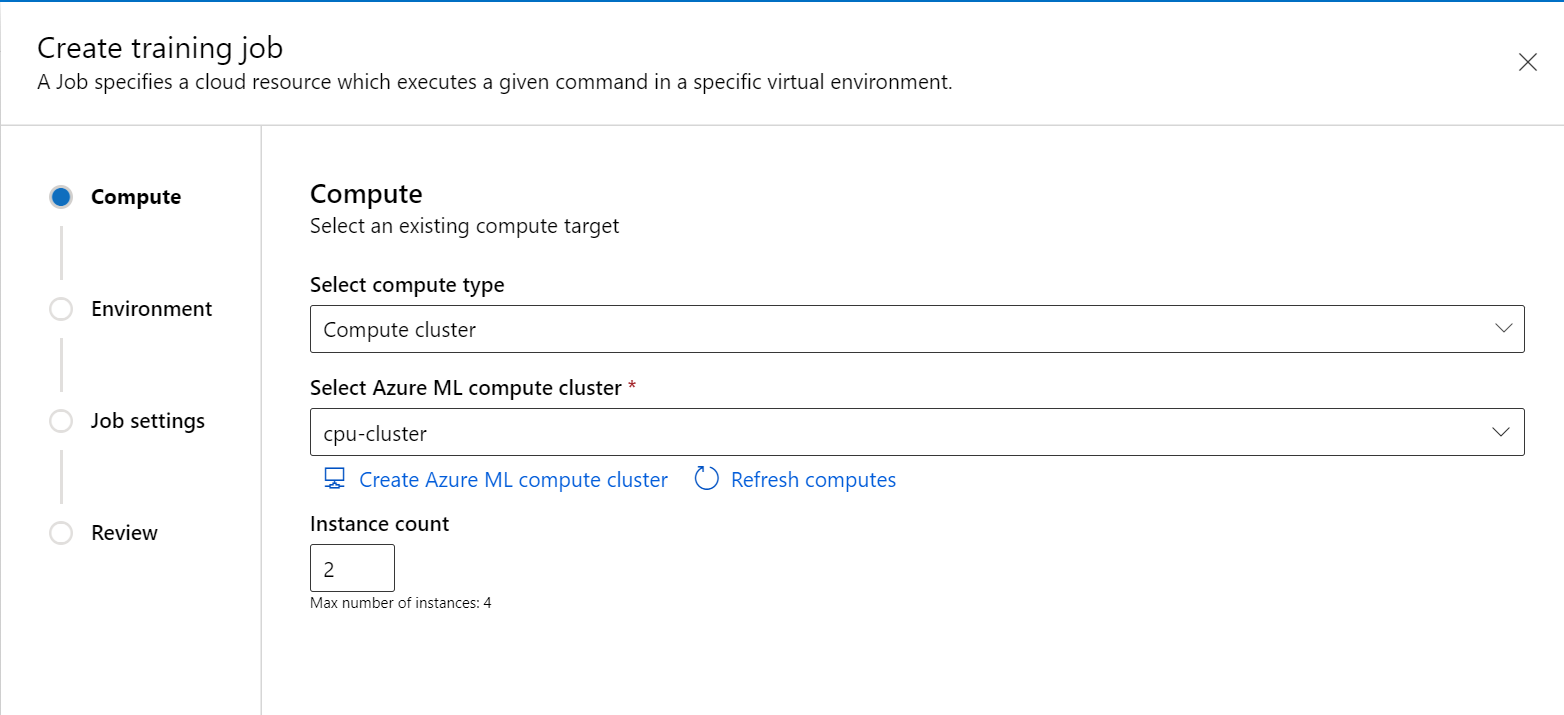
Cree un nuevo trabajo desde el panel izquierdo en el portal de Studio.
Elija Clúster de proceso o Proceso adjunto (Kubernetes) como tipo de proceso, elija el destino de proceso y especifique cuántos nodos necesita en
Instance count.
Siga el asistente para elegir el entorno en el que quiere iniciar el trabajo.
En el paso Script de entrenamiento, agregue el código de entrenamiento (y los datos de entrada y salida) y haga referencia a él en el comando para asegurarse de que está montado en el trabajo.
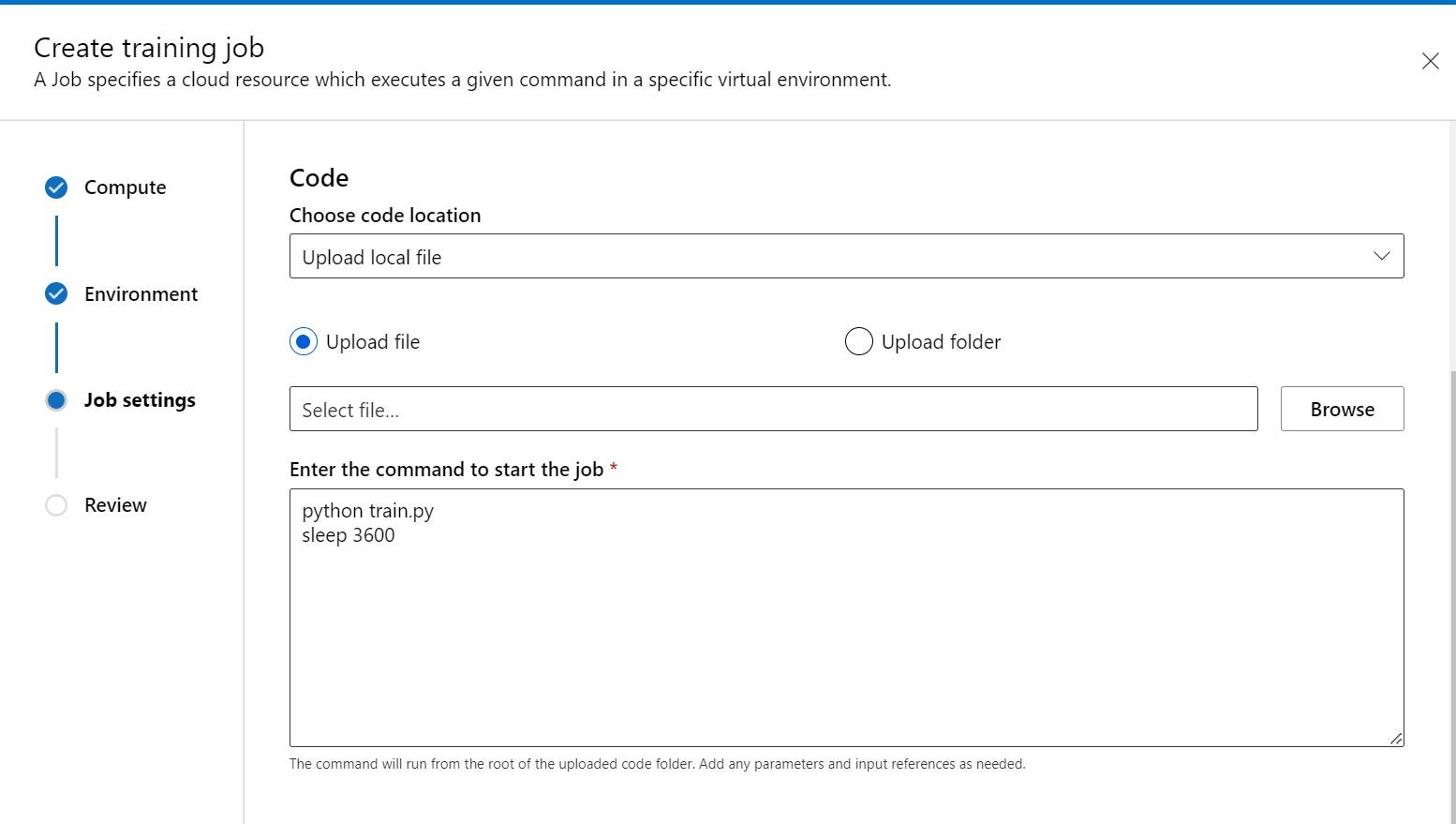
Puede colocar sleep <specific time> al final del comando para especificar la cantidad de tiempo que quiere reservar el recurso de proceso. El formato es como sigue:
- suspensión 1s
- suspensión 1m
- suspensión 1h
- suspensión 1d
También puede usar el comando sleep infinity que mantendría activo el trabajo indefinidamente.
Nota
Si usa sleep infinity, deberá cancelar el trabajo manualmente para dejar de usar el recurso de proceso (y detener la facturación).
- En Configuración de proceso, expanda la opción para aplicaciones de entrenamiento. Seleccione al menos una aplicación de entrenamiento que quiera usar para interactuar con el trabajo. Si no selecciona una aplicación, la característica de depuración no estará disponible.
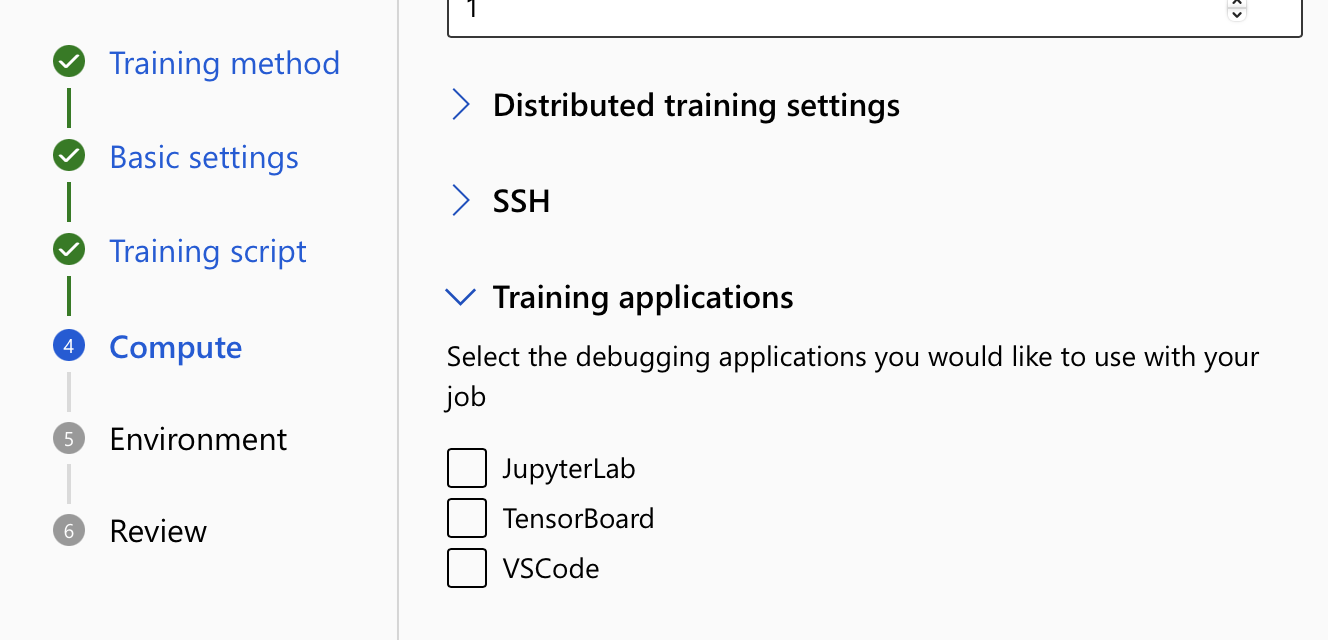
- Revise y cree el trabajo.
Conexión a puntos de conexión
Para interactuar con el trabajo en ejecución, seleccione el botón Depurar y supervisar en la página de detalles del trabajo.
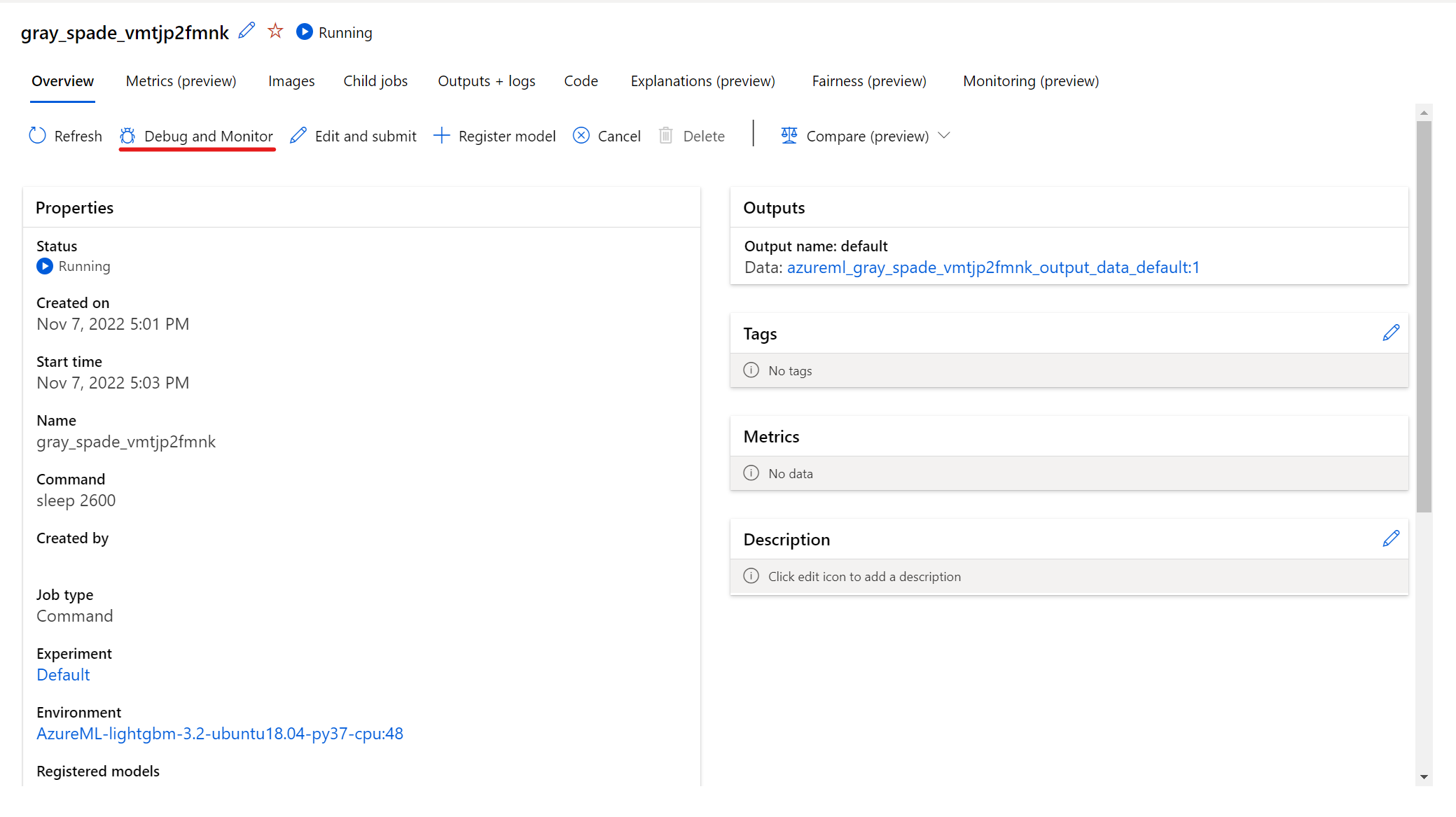
Al hacer clic en las aplicaciones del panel, se abre una nueva pestaña para las aplicaciones. Solo puede acceder a las aplicaciones cuando se encuentran en estado En ejecución y solo el propietario del trabajo está autorizado para acceder a las aplicaciones. Si está entrenando en varios nodos, puede elegir el nodo específico con el que quiere interactuar.
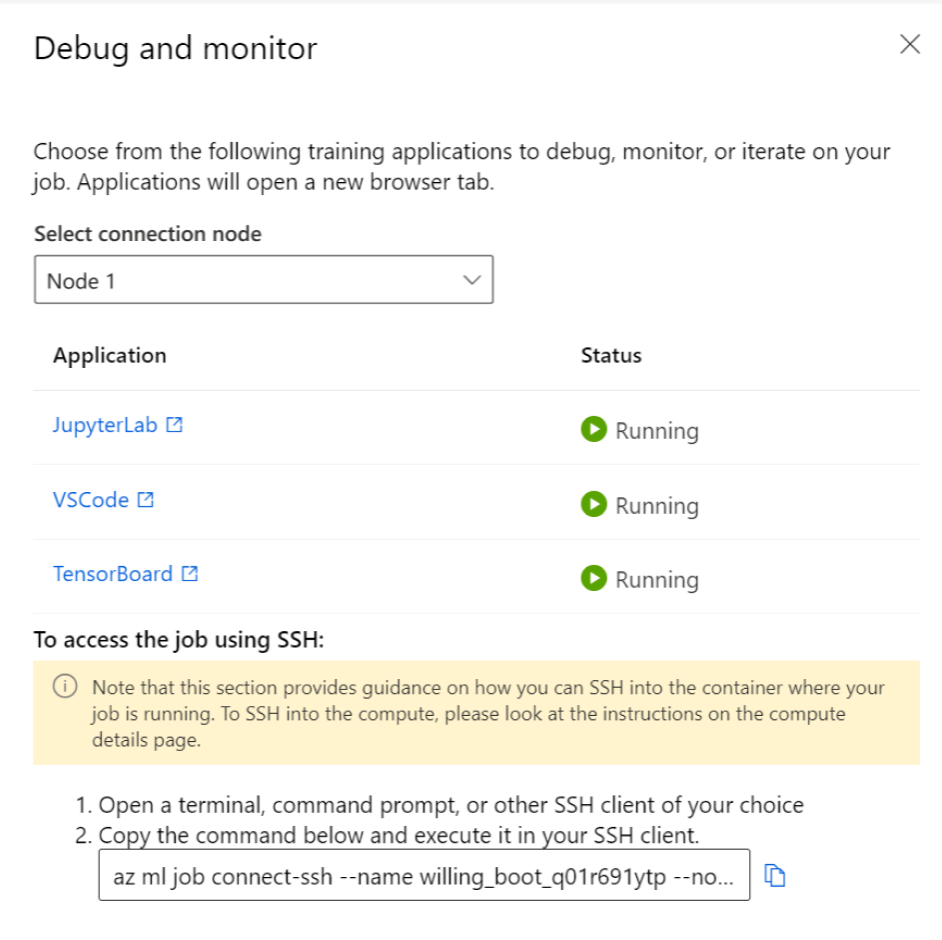
Es posible que se tarde unos minutos en iniciar el trabajo y las aplicaciones de entrenamiento especificadas durante la creación del trabajo.
Interacción con las aplicaciones
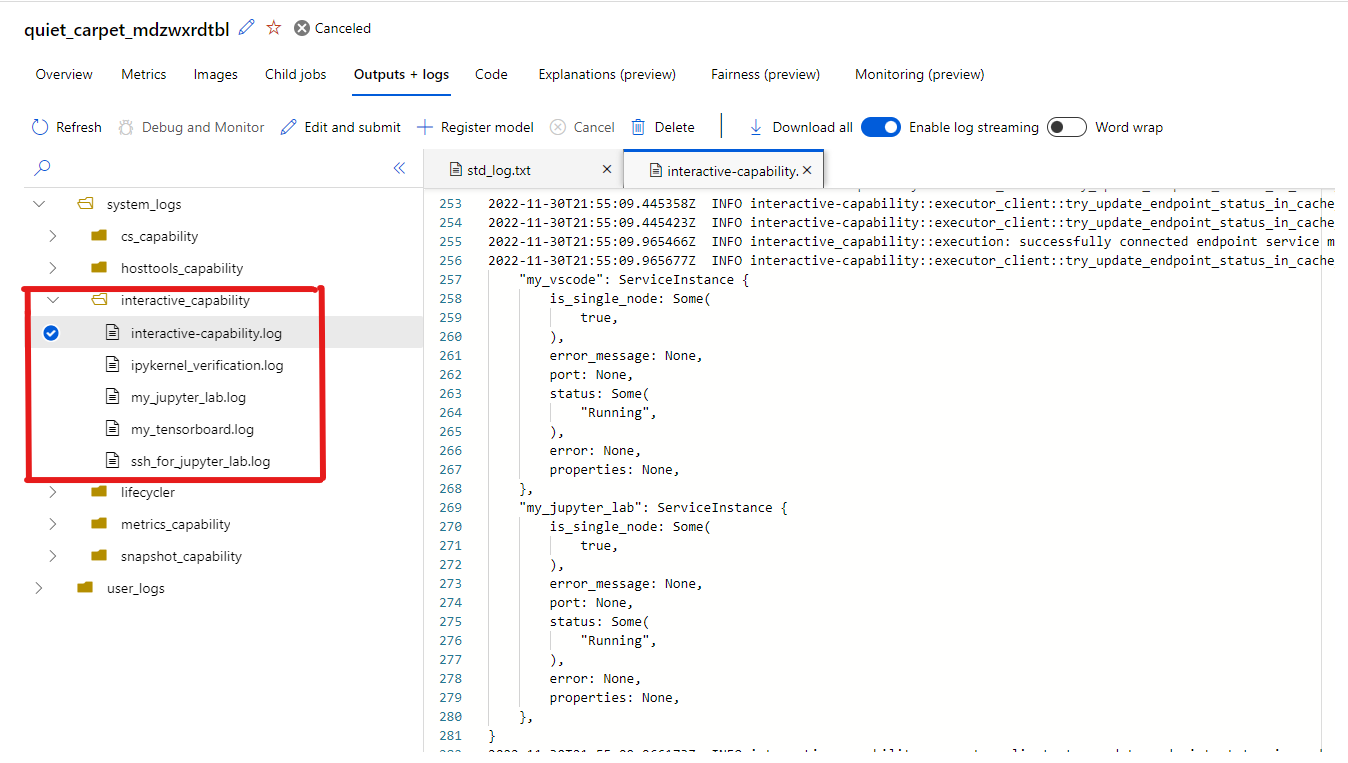
Al seleccionar los puntos de conexión para interactuar con el trabajo, se le llevará al contenedor de usuarios en el directorio de trabajo, donde puede acceder al código, las entradas, las salidas y los registros. Si tiene algún problema al conectarse a las aplicaciones, los registros de aplicaciones y funcionalidad interactivas se pueden encontrar en system_logs-interactive_capability> en la pestaña Salidas y registros.
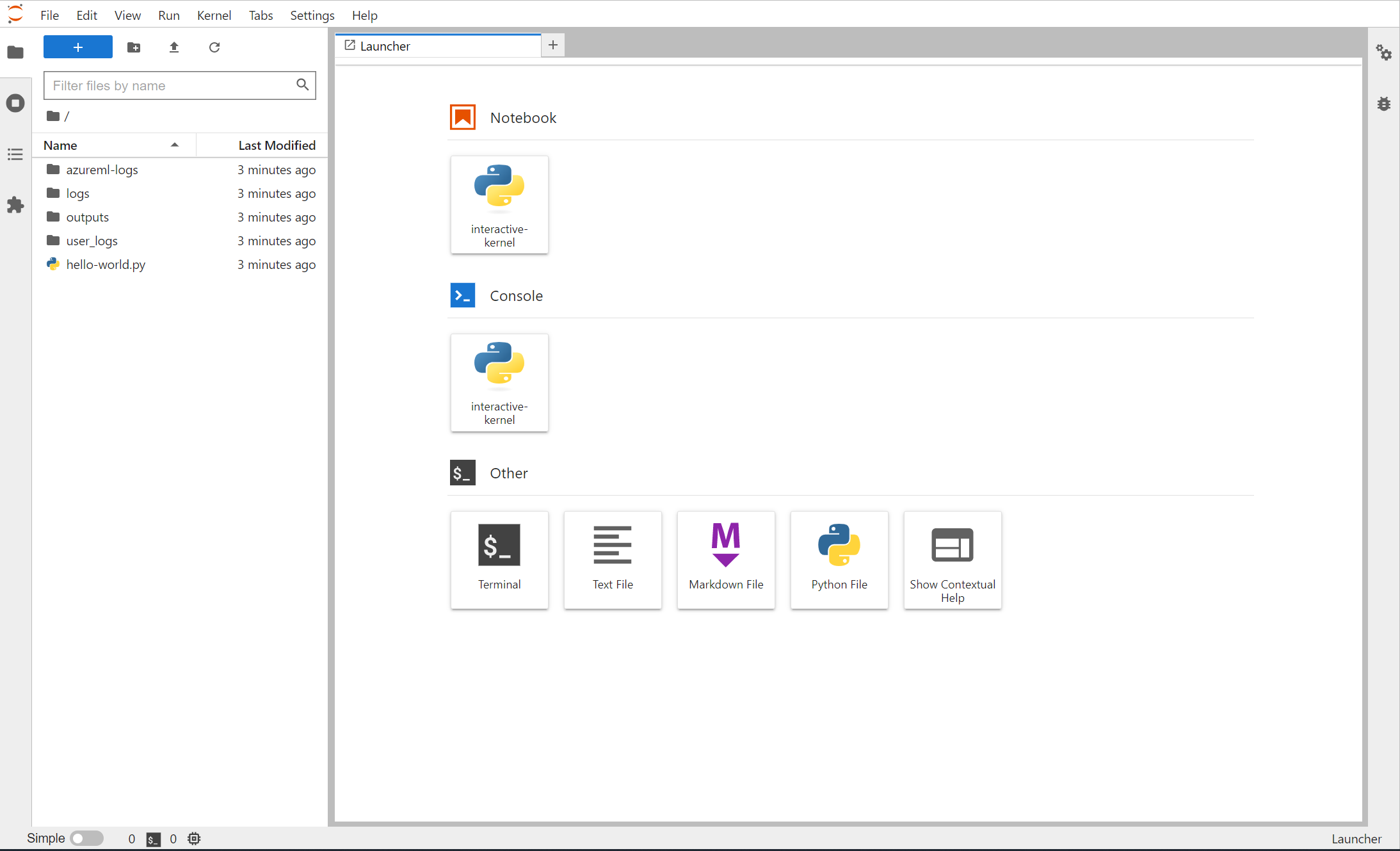
Puede abrir un terminal desde Jupyter Lab y empezar a interactuar dentro del contenedor de trabajos. También puede iterar directamente en el script de entrenamiento con Jupyter Lab.
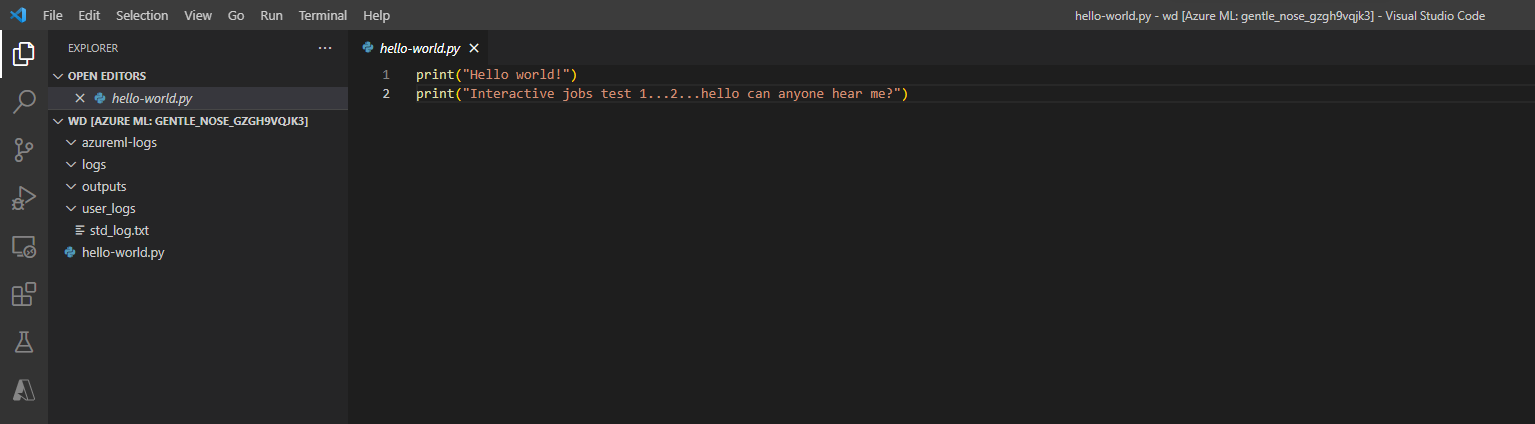
También puede interactuar con el contenedor de trabajos en VS Code. Para adjuntar un depurador a un trabajo durante el envío del trabajo y pausar la ejecución, vaya aquí.
Nota
Las áreas de trabajo habilitadas para vínculo privado no se admiten actualmente al interactuar con el contenedor de trabajos con VS Code.
Si ha registrado eventos de TensorFlow para el trabajo, puede usar TensorBoard para supervisar las métricas cuando se ejecuta el trabajo.
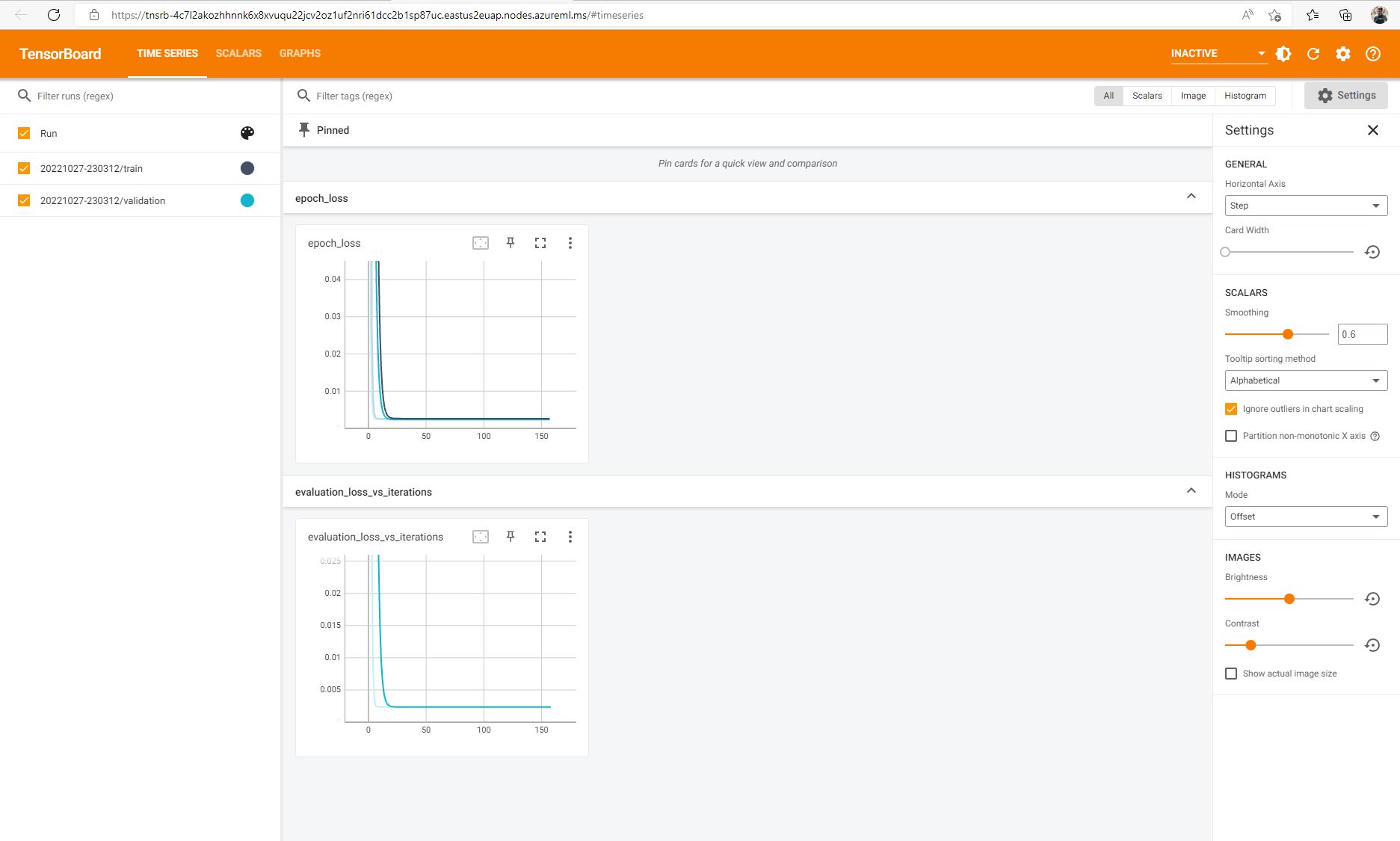
Finalización de un trabajo
Una vez que haya terminado con el entrenamiento interactivo, también puede ir a la página de detalles del trabajo para cancelar el trabajo, lo que liberará el recurso de proceso. Como alternativa, use az ml job cancel -n <your job name> en la CLI o ml_client.job.cancel("<job name>") en el SDK.

Asociación de un depurador a un trabajo
Para enviar un trabajo con un depurador asociado y la ejecución en pausa, puede usar debugpy y VS Code (debugpy debe estar instalado en el entorno de trabajo).
Nota
Las áreas de trabajo habilitadas para vínculo privado no se admiten actualmente al asociar un depurador a un trabajo en VS Code.
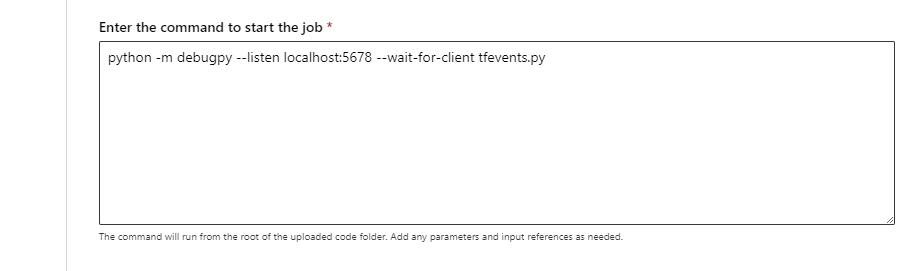
- Durante el envío del trabajo (ya sea a través de la interfaz de usuario, la CLI o el SDK), use el comando debugpy para ejecutar el script de Python. Por ejemplo, en la captura de pantalla siguiente se muestra un comando de ejemplo que usa debugpy para adjuntar el depurador para un script de TensorFlow (
tfevents.pyse puede reemplazar por el nombre del script de entrenamiento).
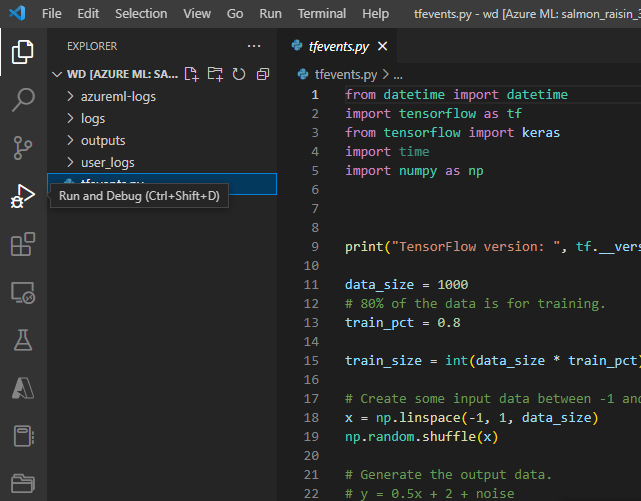
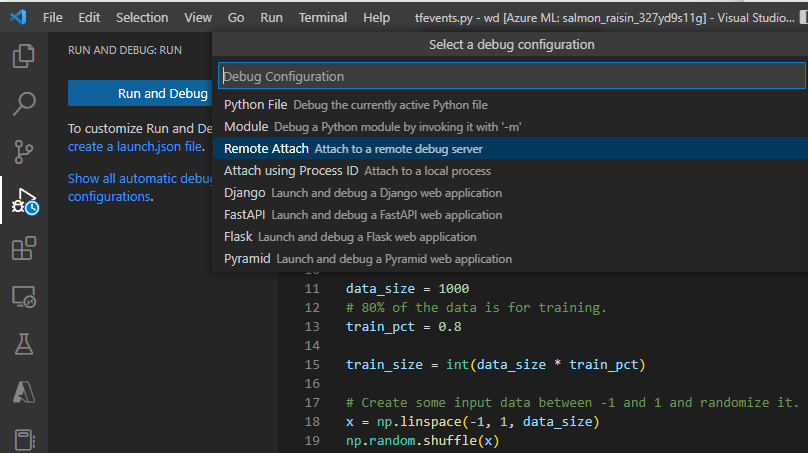
Una vez enviado el trabajo, conéctese a VS Code y seleccione el depurador integrado.
Use la configuración de depuración "Asociación remota" para adjuntar al trabajo enviado y pasar la ruta de acceso y el puerto que configuró en el comando de envío del trabajo. También puede encontrar esta información en la página de detalles del trabajo.
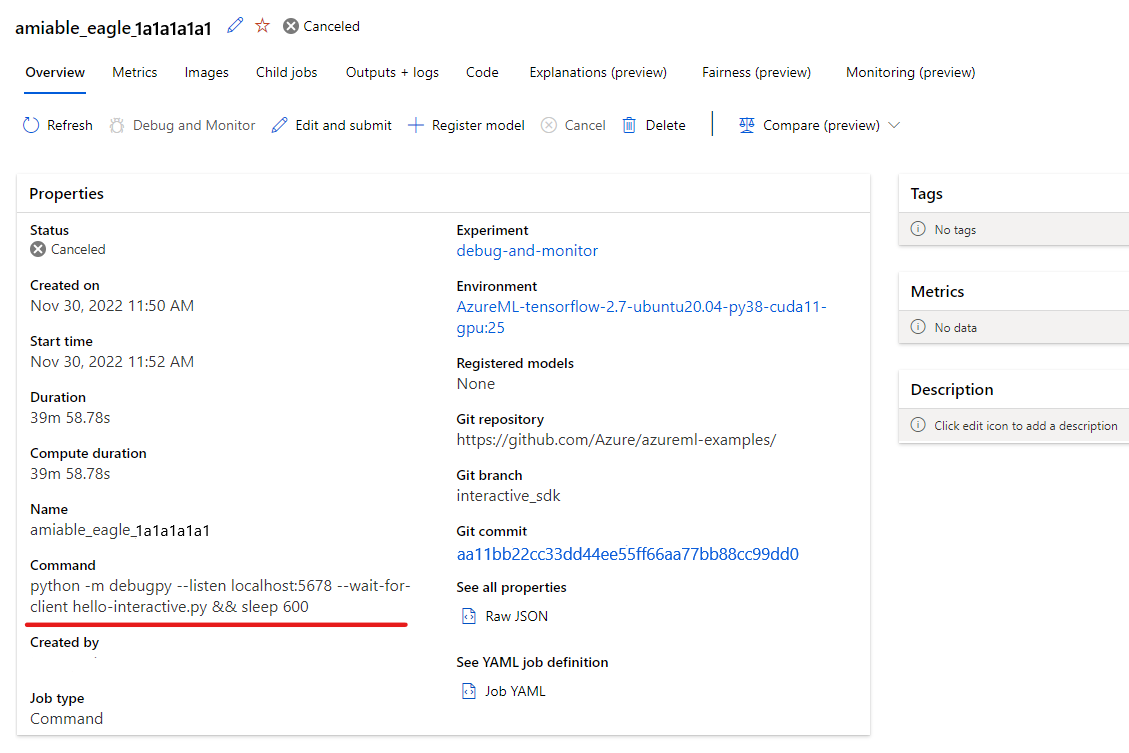
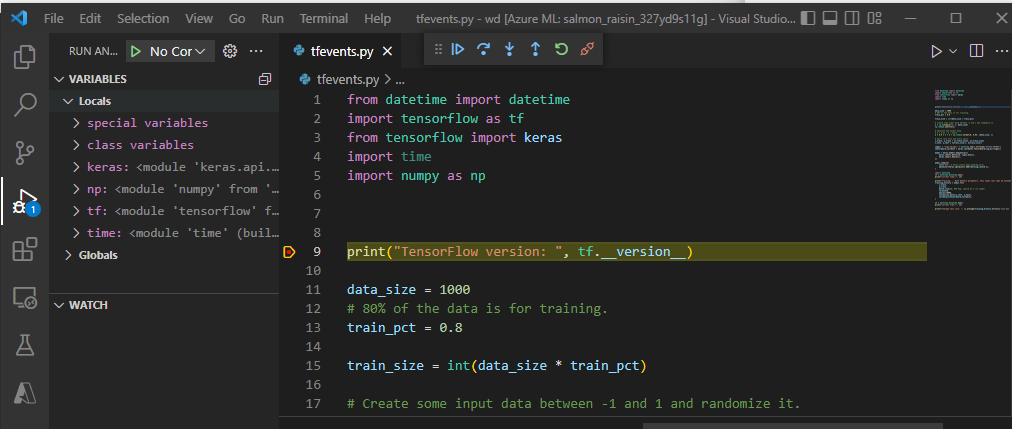
Establezca puntos de interrupción y recorra la ejecución del trabajo como lo haría en el flujo de trabajo de depuración local.
Nota
Si usa debugpy para iniciar el trabajo, el trabajo no se ejecutará a menos que adjunte el depurador en VS Code y ejecute el script. Si no lo hace, el proceso se reservará hasta que se cancele el trabajo.
Pasos siguientes
- Obtenga más información sobre cómo y dónde implementar un modelo.