Supervisión del rendimiento de los modelos implementados en producción
SE APLICA A: Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Aprenda a usar la supervisión de modelos de Azure Machine Learning para realizar un seguimiento continuo del rendimiento de los modelos de Machine Learning en producción. La supervisión de modelos proporciona una amplia vista de las señales de supervisión y alerta sobre posibles incidencias. Al supervisar señales y métricas de rendimiento de modelos en producción, podrá evaluar críticamente los riesgos inherentes asociados a ellos e identificar puntos ciegos que pudieran afectar negativamente a la empresa.
En este artículo aprenderá a realizar las siguientes tareas:
- Realizar una configuración de supervisión avanzada y lista para su uso en modelos que se implementen en puntos de conexión en línea de Azure Machine Learning
- Supervisar las métricas de rendimiento de los modelos en producción
- Supervisar los modelos que se implementen fuera de Azure Machine Learning o en puntos de conexión por lotes de Azure Machine Learning
- Configure la supervisión del modelo con señales y métricas personalizadas
- Interpretación de los resultados de la supervisión
- Integración de la supervisión de modelos de Azure Machine Learning con Azure Event Grid
Requisitos previos
Antes de seguir los pasos de este artículo, asegúrese de que tiene los siguientes requisitos previos:
La CLI de Azure y la extensión
mla la CLI de Azure. Para más información, consulte Instalación, configuración y uso de la CLI v2.Importante
En los ejemplos de la CLI de este artículo se supone que usa el shell de Bash (o compatible). Por ejemplo, de un sistema Linux o Subsistema de Windows para Linux.
Un área de trabajo de Azure Machine Learning. Si no tiene uno, siga los pasos descritos en el artículo Instalación, configuración y uso de la CLI (v2) para crearlo.
Los controles de acceso basado en rol de Azure (RBAC de Azure) se usan para conceder acceso a las operaciones en Azure Machine Learning. Para realizar los pasos descritos en este artículo, la cuenta de usuario debe tener asignado el rol de propietario o colaborador para el área de trabajo de Azure Machine Learning, o un rol personalizado que permita
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Para obtener más información, consulte Administración del acceso a un área de trabajo de Azure Machine Learning.Para supervisar un modelo que se implementa en un punto de conexión en línea de Azure Machine Learning (punto de conexión en línea administrado o punto de conexión en línea de Kubernetes), asegúrese de lo siguiente:
Tener un modelo ya implementado en un punto de conexión en línea de Azure Machine Learning. Se admiten tanto el punto de conexión en línea administrado como el punto de conexión en línea de Kubernetes. Si no tiene un modelo implementado en un punto de conexión en línea de Azure Machine Learning, consulte Implementación y puntuación de un modelo de Machine Learning mediante un punto de conexión en línea.
Habilitar la recopilación de datos para la implementación del modelo. Puede habilitar la recopilación de datos durante el paso de implementación para puntos de conexión en línea de Azure Machine Learning. Para más información, consulte Recopilación de datos de producción de modelos implementados en un punto de conexión en tiempo real.
Para supervisar un modelo que se implementa en un punto de conexión por lotes de Azure Machine Learning o implementado fuera de Azure Machine Learning, asegúrese de lo siguiente:
- Tener un medio para recopilar datos de producción y registrarlos como un recurso de datos de Azure Machine Learning.
- Actualizar el recurso de datos registrado continuamente para la supervisión del modelo.
- (Recomendado) Registrar el modelo en un área de trabajo de Azure Machine Learning para el seguimiento del linaje.
Importante
Los trabajos de supervisión de modelos se programan para ejecutarse en grupos de proceso de Spark sin servidor compatibles con los siguientes tipos de instancia de máquina virtual: Standard_E4s_v3, Standard_E8s_v3, Standard_E16s_v3, Standard_E32s_v3 y Standard_E64s_v3. Puede seleccionar el tipo de instancia de máquina virtual con la propiedad create_monitor.compute.instance_type en la configuración de YAML o en la lista desplegable de Azure Machine Learning Studio.
Configuración de la supervisión de modelos listos para usar
Supongamos que implementa el modelo en producción en un punto de conexión en línea de Azure Machine Learning y habilita recopilación de datos en tiempo de implementación. En este escenario, Azure Machine Learning recopila datos de inferencia de producción y los almacena automáticamente en Microsoft Azure Blob Storage. Después, puede usar la supervisión del modelo de Azure Machine Learning para supervisar continuamente estos datos de inferencia de producción.
Puede usar la CLI de Azure, el SDK de Python o Studio para una configuración integrada de la supervisión de modelos. La configuración de supervisión de modelos preconfigurada proporciona las siguientes funcionalidades de supervisión:
- Azure Machine Learning detecta automáticamente el conjunto de datos de inferencia de producción asociado a una implementación en línea de Azure Machine Learning y usa el conjunto de datos para la supervisión del modelo.
- El conjunto de datos de referencia de comparación se establece como el conjunto de datos de inferencia de producción reciente y anterior.
- La configuración de supervisión incluye y sigue automáticamente las señales de supervisión integradas: desfase de datos, desfase de predicción y calidad de los datos. Para cada señal de supervisión, Azure Machine Learning usa:
- el conjunto de datos de inferencia de producción reciente y anterior como conjunto de datos de referencia de comparación.
- valores predeterminados inteligentes para métricas y umbrales.
- En este ejemplo, un trabajo de supervisión está programado para ejecutarse diariamente a las 3:15. El objetivo es adquirir señales de supervisión y evaluar cada resultado de métrica en su umbral correspondiente. De forma predeterminada, cuando se supera cualquier umbral, Azure Machine Learning envía un correo electrónico de alerta al usuario que configuró el monitor.
La supervisión de modelos de Azure Machine Learning usa az ml schedule para programar un trabajo de supervisión. Puede crear el monitor de modelo predefinido con el siguiente comando de la CLI y la definición de YAML:
az ml schedule create -f ./out-of-box-monitoring.yaml
El siguiente CÓDIGO YAML contiene la definición de la supervisión del modelo lista para usar.
# out-of-box-monitoring.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: credit_default_model_monitoring
display_name: Credit default model monitoring
description: Credit default model monitoring setup with minimal configurations
trigger:
# perform model monitoring activity daily at 3:15am
type: recurrence
frequency: day #can be minute, hour, day, week, month
interval: 1 # #every day
schedule:
hours: 3 # at 3am
minutes: 15 # at 15 mins after 3am
create_monitor:
compute: # specify a spark compute for monitoring job
instance_type: standard_e4s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification # model task type: [classification, regression, question_answering]
endpoint_deployment_id: azureml:credit-default:main # azureml endpoint deployment id
alert_notification: # emails to get alerts
emails:
- abc@example.com
- def@example.com


Configuración de la supervisión avanzada de modelo
Azure Machine Learning proporciona muchas funcionalidades para la supervisión continua de modelos. Consulte Funcionalidades de supervisión de modelos para obtener una lista completa de estas funcionalidades. En muchos casos, deberá configurar la supervisión de modelos con funcionalidades de supervisión avanzadas. En las secciones siguientes, configurará la supervisión de modelos con estas funcionalidades:
- Uso de varias señales de supervisión para obtener una visión amplia.
- Uso de datos históricos de entrenamiento del modelo o datos de validación como conjunto de datos de referencia de comparación.
- Supervisión de las principales características N más importantes y características individuales.
Configuración de la importancia de la característica
La importancia de la característica representa la importancia relativa de cada característica de entrada a la salida de un modelo. Por ejemplo, temperature podría ser más importante para la predicción de un modelo en comparación con elevation. La habilitación de la importancia de las características puede proporcionarle visibilidad de las características que no desea desfase o tener problemas de calidad de datos en producción.
Para habilitar la importancia de las características con cualquiera de las señales (como el desfase de datos o la calidad de los datos), debe proporcionar:
- El conjunto de datos de entrenamiento como conjunto de datos
reference_data. - La propiedad
reference_data.data_column_names.target_column, que es el nombre de la columna de salida o predicción del modelo.
Después de habilitar la importancia de las características, verá una importancia de característica para cada característica que está supervisando en la interfaz de usuario de Azure Machine Learning Model Monitoring Studio.
Puede usar la CLI de Azure, el SDK de Python o Studio para la configuración avanzada de la supervisión de modelos.
Cree una configuración avanzada de supervisión de modelos con el siguiente comando de la CLI y la definición de YAML:
az ml schedule create -f ./advanced-model-monitoring.yaml
El siguiente ejemplo de YAML contiene la definición para la supervisión de modelos avanzada.
# advanced-model-monitoring.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: fraud_detection_model_monitoring
display_name: Fraud detection model monitoring
description: Fraud detection model monitoring with advanced configurations
trigger:
# perform model monitoring activity daily at 3:15am
type: recurrence
frequency: day #can be minute, hour, day, week, month
interval: 1 # #every day
schedule:
hours: 3 # at 3am
minutes: 15 # at 15 mins after 3am
create_monitor:
compute:
instance_type: standard_e4s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification
endpoint_deployment_id: azureml:credit-default:main
monitoring_signals:
advanced_data_drift: # monitoring signal name, any user defined name works
type: data_drift
# reference_dataset is optional. By default referece_dataset is the production inference data associated with Azure Machine Learning online endpoint
reference_data:
input_data:
path: azureml:credit-reference:1 # use training data as comparison reference dataset
type: mltable
data_context: training
data_column_names:
target_column: DEFAULT_NEXT_MONTH
features:
top_n_feature_importance: 10 # monitor drift for top 10 features
metric_thresholds:
numerical:
jensen_shannon_distance: 0.01
categorical:
pearsons_chi_squared_test: 0.02
advanced_data_quality:
type: data_quality
# reference_dataset is optional. By default reference_dataset is the production inference data associated with Azure Machine Learning online endpoint
reference_data:
input_data:
path: azureml:credit-reference:1
type: mltable
data_context: training
features: # monitor data quality for 3 individual features only
- SEX
- EDUCATION
metric_thresholds:
numerical:
null_value_rate: 0.05
categorical:
out_of_bounds_rate: 0.03
feature_attribution_drift_signal:
type: feature_attribution_drift
# production_data: is not required input here
# Please ensure Azure Machine Learning online endpoint is enabled to collected both model_inputs and model_outputs data
# Azure Machine Learning model monitoring will automatically join both model_inputs and model_outputs data and used it for computation
reference_data:
input_data:
path: azureml:credit-reference:1
type: mltable
data_context: training
data_column_names:
target_column: DEFAULT_NEXT_MONTH
metric_thresholds:
normalized_discounted_cumulative_gain: 0.9
alert_notification:
emails:
- abc@example.com
- def@example.com






Configuración de la supervisión de rendimiento de modelos
La supervisión de modelos de Azure Machine Learning permite realizar un seguimiento del rendimiento de los modelos en producción mediante el cálculo de sus métricas de rendimiento. Actualmente se admiten las siguientes métricas de rendimiento de modelos:
Para modelos de clasificación:
- Precisión
- Exactitud
- Recuperación
Para modelos de regresión:
- Error medio absoluto (MAE)
- Error cuadrático medio (MSE)
- Raíz del error cuadrático medio (RMSE)
Más requisitos previos para la supervisión de rendimiento de modelos
Es necesario cumplir con los siguientes requisitos para configurar la señal de rendimiento de modelos:
Tener datos de salida para el modelo de producción (predicciones del modelo) con un id. único para cada fila. Si se recopilan datos de producción con el recopilador de datos de Azure Machine Learning, se proporcionará un
correlation_idpara cada solicitud de inferencia. Con el recopilador de datos, también existe la opción de registrar su propio id. único desde la aplicación.Nota:
Para la supervisión de rendimiento de modelos de Azure Machine Learning, se recomienda registrar su id. único en su propia columna mediante el recopilador de datos de Azure Machine Learning.
Tener datos verdaderos (reales) con un id. único para cada fila. El id. único de una fila determinada debe coincidir con el id. único de las salidas del modelo para esa solicitud de inferencia determinada. Este id. único se usa para unir el conjunto de datos verdadero con las salidas del modelo.
Sin tener datos verdaderos, no se puede realizar la supervisión de rendimiento del modelo. Como hay datos verdaderos en el nivel de aplicación, es su responsabilidad recopilarlos a medida que estén disponibles. También se debe mantener un recurso de datos en Azure Machine Learning que contenga estos datos verdaderos.
(Opcional) tener un conjunto de datos tabular unido previamente con salidas del modelo y datos verdaderos ya unidos.
Supervisión de los requisitos de rendimiento del modelo al usar el recopilador de datos
Si usa el recopilador de datos de Azure Machine Learning para recopilar datos de inferencia de producción sin proporcionar su propio id. único para cada fila como una columna independiente, se generará automáticamente un correlationid y se incluirá en el objeto JSON registrado. Sin embargo, el recopilador de datos agrupará las filas por lotes que se envíen en intervalos cortos de tiempo entre sí. Las filas agrupadas por lotes se incluirán en el mismo objeto JSON y, por lo tanto, tendrán el mismo correlationid.
Para diferenciar entre las filas del mismo objeto JSON, la supervisión de rendimiento del modelo de Azure Machine Learning usa la indexación para determinar el orden de las filas del objeto JSON. Por ejemplo, si tres filas se agrupan por lotes y correlationid fuera test, la fila uno tendrá un id. de test_0, la fila dos tendrá un id. de test_1 y la fila tres tendrá un id. de test_2. Para asegurarse de que el conjunto de datos verdadero contenga id. únicos que coincidan con las salidas del modelo de inferencia de producción recopiladas, asegúrese de indexar cada correlationid correctamente. Si el objeto JSON registrado solo tuviera una fila, el correlationid sería correlationid_0.
Para evitar el uso de esta indexación, se recomienda registrar su id. único en su propia columna dentro del DataFrame de Pandas que esté registrando con el recopilador de datos de Azure Machine Learning. A continuación, en la configuración de supervisión de modelo, especifique el nombre de esta columna para combinar los datos de salida del modelo con los datos verdaderos. Siempre que los id. de cada fila de ambos conjuntos de datos sean los mismos, la supervisión del modelo de Azure Machine Learning puede realizar la supervisión del rendimiento del modelo.
Flujo de trabajo de ejemplo para supervisar el rendimiento del modelo
Para comprender los conceptos asociados a la supervisión del rendimiento del modelo, considere este flujo de trabajo de ejemplo. Si suponemos que implementará un modelo para predecir si las transacciones de tarjetas de crédito son fraudulentas o no, siga estos pasos para supervisar su rendimiento:
- Configure la implementación para usar el recopilador de datos para recopilar los datos de inferencia de producción del modelo (datos de entrada y salida). Supongamos que los datos de salida se almacenan en una columna
is_fraud. - Para cada fila de los datos de inferencia recopilados, registre un id. único. El id. único podría provenir de la aplicación, o bien use el
correlationidque Azure Machine Learning genera de forma única para cada objeto JSON registrado. - Más adelante, cuando los datos verdaderos (o reales)
is_fraudestén disponibles, también se registrarán y se asignarán al mismo id. único que se registró con las salidas del modelo. - Estos datos verdaderos
is_fraudtambién se recopilan, mantienen y registran en Azure Machine Learning como recurso de datos. - Cree una señal de supervisión de rendimiento del modelo que una los recursos de datos verdaderos y los de inferencia de producción del modelo mediante las columnas de id. único.
- Por último, calcule las métricas de rendimiento del modelo.
Una vez que haya cumplido los requisitos previos de supervisión de rendimiento del modelo, configure la supervisión de modelo con el siguiente comando de la CLI y la definición de YAML:
az ml schedule create -f ./model-performance-monitoring.yaml
El siguiente código YAML contiene la definición de la supervisión de modelos con datos de inferencia de producción que ha recopilado.
$schema: http://azureml/sdk-2-0/Schedule.json
name: model_performance_monitoring
display_name: Credit card fraud model performance
description: Credit card fraud model performance
trigger:
type: recurrence
frequency: day
interval: 7
schedule:
hours: 10
minutes: 15
create_monitor:
compute:
instance_type: standard_e8s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification
endpoint_deployment_id: azureml:loan-approval-endpoint:loan-approval-deployment
monitoring_signals:
fraud_detection_model_performance:
type: model_performance
production_data:
data_column_names:
prediction: is_fraud
correlation_id: correlation_id
reference_data:
input_data:
path: azureml:my_model_ground_truth_data:1
type: mltable
data_column_names:
actual: is_fraud
correlation_id: correlation_id
data_context: actuals
alert_enabled: true
metric_thresholds:
tabular_classification:
accuracy: 0.95
precision: 0.8
alert_notification:
emails:
- abc@example.com





Configure la supervisión de modelos mediante la incorporación de los datos de producción a Azure Machine Learning
También puede configurar la supervisión de modelos para los modelos implementados en puntos de conexión por lotes de Azure Machine Learning o implementados fuera de Azure Machine Learning. Si no tiene una implementación, pero tiene datos de producción, puede usar los datos para realizar la supervisión continua del modelo. Para supervisar estos modelos, debe poder:
- Recopilar datos de inferencia de producción de modelos implementados en producción.
- Registrar los datos de inferencia de producción como un recurso de datos de Azure Machine Learning y asegurarse de las actualizaciones continuas de los datos.
- Proporcionar un componente de preprocesamiento de datos personalizado y registrarlo como un componente de Azure Machine Learning.
Debe proporcionar un componente de preprocesamiento de datos personalizado si los datos no se recopilan con el recopilador de datos. Sin este componente de preprocesamiento de datos personalizado, el sistema de supervisión de modelos de Azure Machine Learning no sabrá cómo procesar los datos en formato tabular con compatibilidad con la ventana de tiempo.
El componente de preprocesamiento personalizado debe tener estas firmas de entrada y salida:
| Entrada/salida | Nombre de firma | Tipo | Descripción | Valor de ejemplo |
|---|---|---|---|---|
| input | data_window_start |
literal, cadena | hora de inicio del periodo de datos en formato ISO8601. | 2023-05-01T04:31:57.012Z |
| input | data_window_end |
literal, cadena | hora de finalización del periodo de datos en formato ISO8601. | 2023-05-01T04:31:57.012Z |
| input | input_data |
uri_folder | Los datos de inferencia de producción recopilados, que se registran como recurso de datos de Azure Machine Learning. | azureml:myproduction_inference_data:1 |
| output | preprocessed_data |
mltable | Un conjunto de datos tabular, que coincide con un subconjunto del esquema de datos de referencia. |
Para obtener un ejemplo de un componente de preprocesamiento de datos personalizado, consulte custom_preprocessing en el repositorio de GitHub azuremml-examples.
Una vez que haya cumplido los requisitos anteriores, puede configurar la supervisión del modelo con el siguiente comando de la CLI y la definición de YAML:
az ml schedule create -f ./model-monitoring-with-collected-data.yaml
El siguiente código YAML contiene la definición de la supervisión de modelos con datos de inferencia de producción que ha recopilado.
# model-monitoring-with-collected-data.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: fraud_detection_model_monitoring
display_name: Fraud detection model monitoring
description: Fraud detection model monitoring with your own production data
trigger:
# perform model monitoring activity daily at 3:15am
type: recurrence
frequency: day #can be minute, hour, day, week, month
interval: 1 # #every day
schedule:
hours: 3 # at 3am
minutes: 15 # at 15 mins after 3am
create_monitor:
compute:
instance_type: standard_e4s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification
endpoint_deployment_id: azureml:fraud-detection-endpoint:fraud-detection-deployment
monitoring_signals:
advanced_data_drift: # monitoring signal name, any user defined name works
type: data_drift
# define production dataset with your collected data
production_data:
input_data:
path: azureml:my_production_inference_data_model_inputs:1 # your collected data is registered as Azure Machine Learning asset
type: uri_folder
data_context: model_inputs
pre_processing_component: azureml:production_data_preprocessing:1
reference_data:
input_data:
path: azureml:my_model_training_data:1 # use training data as comparison baseline
type: mltable
data_context: training
data_column_names:
target_column: is_fraud
features:
top_n_feature_importance: 20 # monitor drift for top 20 features
metric_thresholds:
numberical:
jensen_shannon_distance: 0.01
categorical:
pearsons_chi_squared_test: 0.02
advanced_prediction_drift: # monitoring signal name, any user defined name works
type: prediction_drift
# define production dataset with your collected data
production_data:
input_data:
path: azureml:my_production_inference_data_model_outputs:1 # your collected data is registered as Azure Machine Learning asset
type: uri_folder
data_context: model_outputs
pre_processing_component: azureml:production_data_preprocessing:1
reference_data:
input_data:
path: azureml:my_model_validation_data:1 # use training data as comparison reference dataset
type: mltable
data_context: validation
metric_thresholds:
categorical:
pearsons_chi_squared_test: 0.02
alert_notification:
emails:
- abc@example.com
- def@example.com
Configure la supervisión del modelo con señales y métricas personalizadas
Con la supervisión de modelos de Azure Machine Learning, es posible definir su propia señal personalizada e implementar cualquier métrica de su elección para supervisar modelos. Registre esta señal personalizada como un componente de Azure Machine Learning. Cuando el trabajo de supervisión de modelos de Azure Machine Learning se ejecuta según la programación especificada, calcula las métricas que ha definido dentro de la señal personalizada, igual que para las señales precompiladas (desfase de datos, desfase de predicción y calidad de datos).
Para configurar una señal personalizada que se usará para la supervisión del modelo, primero debe definir la señal personalizada y registrarla como un componente de Azure Machine Learning. El componente de Azure Machine Learning debe tener estas firmas de entrada y salida:
Firma de entrada del componente
La entrada del componente DataFrame debe contener los siguientes elementos:
- Un
mltablecon los datos procesados del componente de preprocesamiento - Cualquier número de literales, cada uno de los cuales representa una métrica implementada como parte del componente de señal personalizada. Por ejemplo, si ha implementado la métrica,
std_deviation, necesitará una entrada parastd_deviation_threshold. Por lo general, debe haber una entrada por métrica con el nombre<metric_name>_threshold.
| Nombre de firma | Tipo | Descripción | Valor de ejemplo |
|---|---|---|---|
| production_data | mltable | Un conjunto de datos tabular que coincide con un subconjunto del esquema de datos de referencia. | |
| std_deviation_threshold | literal, cadena | Umbral respectivo para la métrica implementada. | 2 |
Firma de salida del componente
El puerto de salida del componente debe tener la siguiente firma.
| Nombre de firma | Tipo | Descripción |
|---|---|---|
| signal_metrics | mltable | Mltable que contiene las métricas calculadas. El esquema se define en la sección siguiente esquema signal_metrics. |
Esquema de signal_metrics
La salida del componente DataFrame debe contener cuatro columnas: group, metric_name, metric_value y threshold_value.
| Nombre de firma | Tipo | Descripción | Valor de ejemplo |
|---|---|---|---|
| group | literal, cadena | Agrupación lógica de nivel superior que se va a aplicar a esta métrica personalizada. | TRANSACTIONAMOUNT |
| metric_name | literal, cadena | Nombre de la métrica personalizada. | std_deviation |
| metric_value | numérico | Valor de la métrica personalizada. | 44.896,082 |
| threshold_value | numérico | Umbral de la métrica personalizada. | 2 |
En la tabla siguiente se muestra una salida de ejemplo de un componente de señal personalizado que calcula la métrica std_deviation:
| group | metric_value | metric_name | threshold_value |
|---|---|---|---|
| TRANSACTIONAMOUNT | 44,896.082 | std_deviation | 2 |
| LOCALHOUR | 3.983 | std_deviation | 2 |
| TRANSACTIONAMOUNTUSD | 54,004.902 | std_deviation | 2 |
| DIGITALITEMCOUNT | 7.238 | std_deviation | 2 |
| PHYSICALITEMCOUNT | 5.509 | std_deviation | 2 |
Para ver un ejemplo de definición de componente de señal personalizada y código de cálculo de métricas, consulte custom_signal en el repositorio azureml-examples.
Una vez que haya cumplido los requisitos para usar métricas y señales personalizadas, puede configurar la supervisión del modelo con el siguiente comando de la CLI y la definición de YAML:
az ml schedule create -f ./custom-monitoring.yaml
El siguiente YAML contiene la definición de la supervisión de modelos con una señal personalizada. Algunos aspectos que se deben tener en cuenta sobre el código:
- Se supone que ya ha creado y registrado el componente con la definición de señal personalizada en Azure Machine Learning.
- El
component_iddel componente de señal personalizada registrado esazureml:my_custom_signal:1.0.0. - Si ha recopilado los datos con el recopilador de datos, puede omitir la propiedad
pre_processing_component. Si desea usar un componente de preprocesamiento para preprocesar los datos de producción no recopilados por el recopilador de datos, puede especificarlos.
# custom-monitoring.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: my-custom-signal
trigger:
type: recurrence
frequency: day # can be minute, hour, day, week, month
interval: 7 # #every day
create_monitor:
compute:
instance_type: "standard_e4s_v3"
runtime_version: "3.3"
monitoring_signals:
customSignal:
type: custom
component_id: azureml:my_custom_signal:1.0.0
input_data:
production_data:
input_data:
type: uri_folder
path: azureml:my_production_data:1
data_context: test
data_window:
lookback_window_size: P30D
lookback_window_offset: P7D
pre_processing_component: azureml:custom_preprocessor:1.0.0
metric_thresholds:
- metric_name: std_deviation
threshold: 2
alert_notification:
emails:
- abc@example.com
Interpretación de los resultados de la supervisión
Una vez configurado la supervisión del modelo y completada la primera ejecución, puede volver a la pestaña Supervisión de Azure Machine Learning Studio para ver los resultados.
En la vista principal Supervisión, seleccione el nombre de la supervisión de modelos para ver la página información general de la supervisión. En esta página se muestra el modelo, el punto de conexión y la implementación correspondientes, junto con los detalles relacionados con las señales configuradas. En la imagen siguiente se muestra un panel de supervisión que incluye señales de desfase de datos y calidad de datos. En función de las señales de supervisión configuradas, el panel podría tener un aspecto diferente.
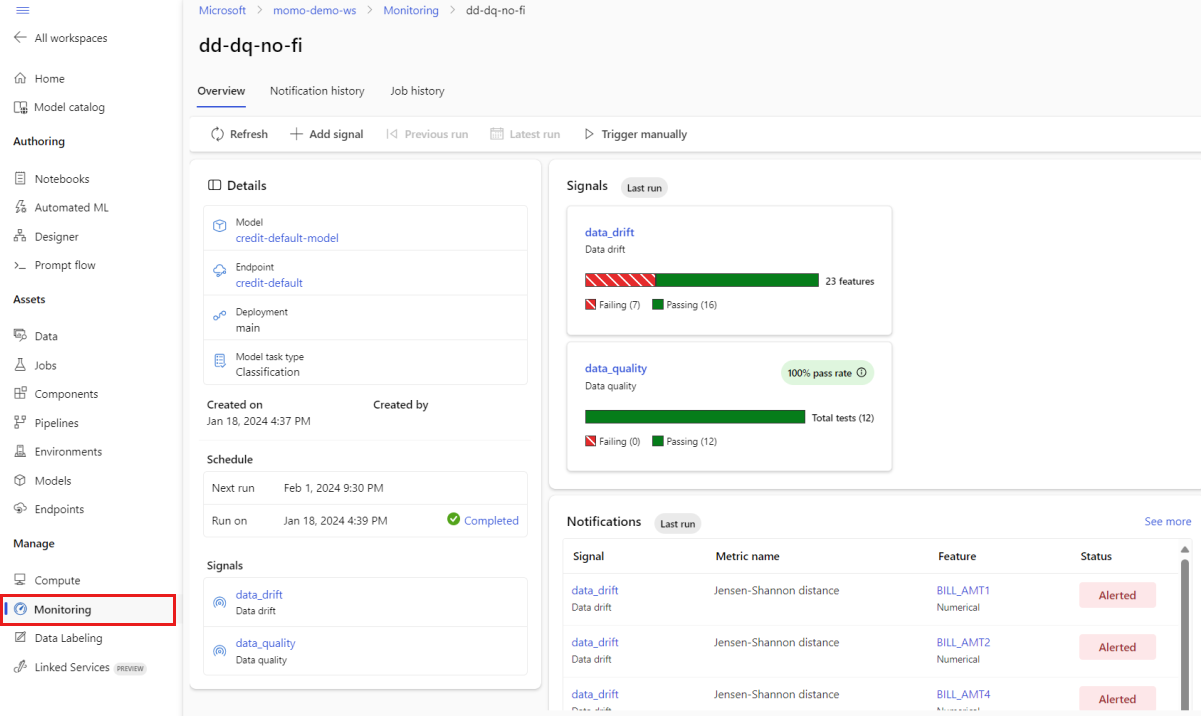
Busque en la sección Notificaciones del panel para ver, para cada señal, qué características infringieron el umbral configurado para sus respectivas métricas:
Seleccione data_drift para ir a la página de detalles del desfase de datos. En la página de detalles, puede ver el valor de la métrica de desfase de datos para cada característica numérica y categórica que incluyó en la configuración de supervisión. Cuando la supervisión tenga más de una ejecución, verá una línea de tendencia para cada característica.
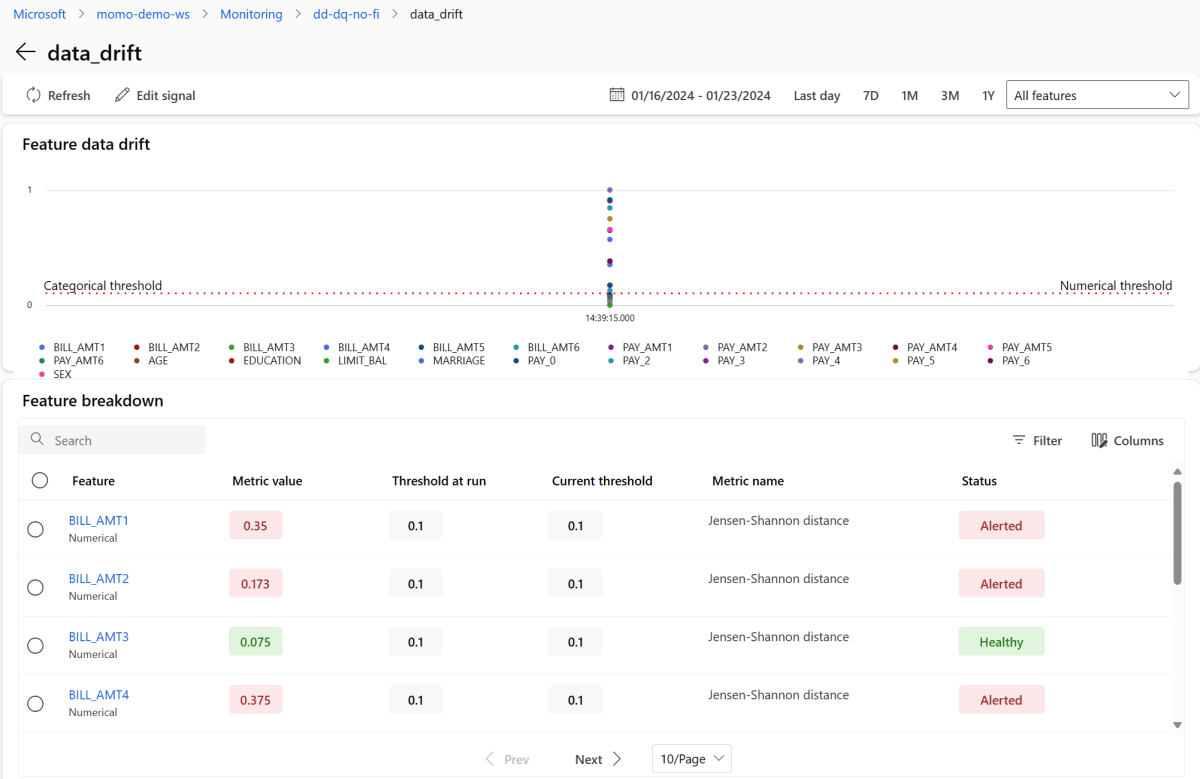
Para ver una característica individual en detalle, seleccione el nombre de la característica para ver la distribución de producción en comparación con la distribución de referencia. Esta vista también le permite realizar un seguimiento del desfase a lo largo del tiempo para esa característica específica.

Vuelva al panel de supervisión y seleccione data_quality para ver la página de señal de calidad de datos. En esta página, puede ver las tasas de valores NULL, las tasas de límite insuficiente y las tasas de error de tipo de datos para cada característica que está supervisando.
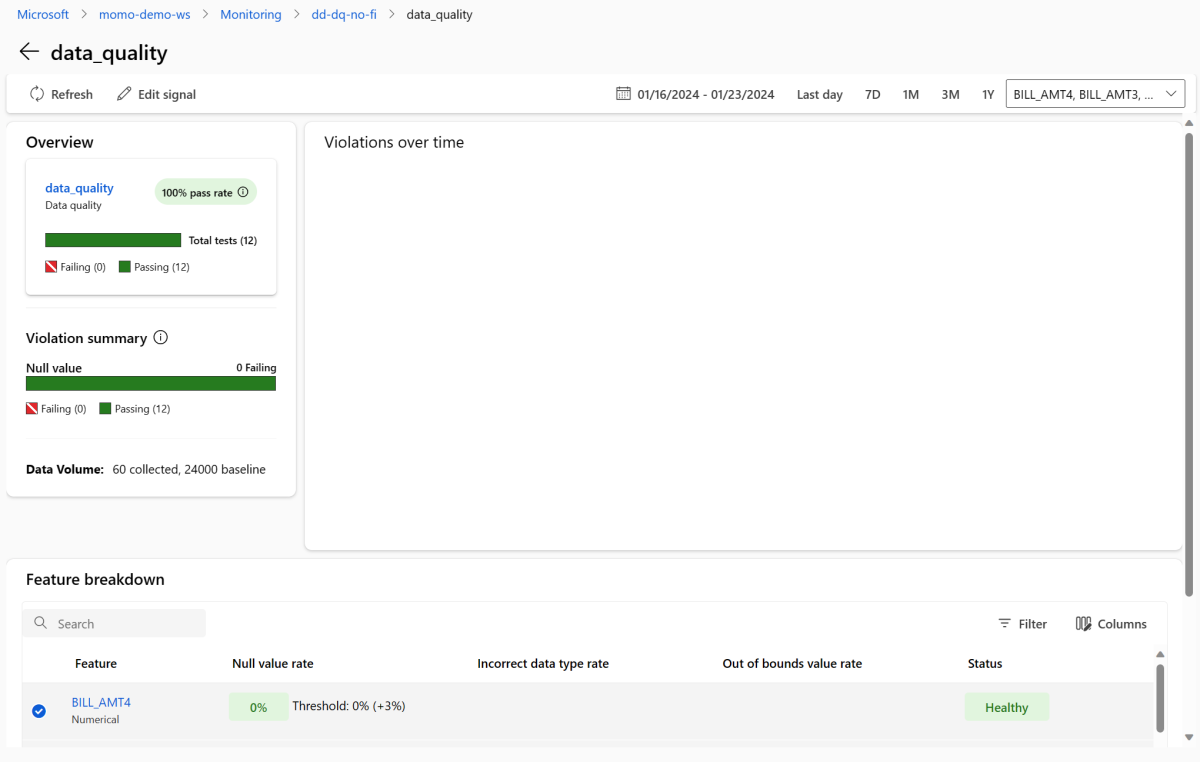




La supervisión de modelos es un proceso continuo. Con la supervisión de modelos de Azure Machine Learning, puede configurar varias señales de supervisión para obtener una visión amplia del rendimiento de los modelos en producción.
Integración de la supervisión de modelos de Azure Machine Learning con Azure Event Grid
Puede usar eventos generados por la supervisión de modelos de Azure Machine Learning para configurar aplicaciones, procesos o flujos de trabajo de CI/CD controlados por eventos con Azure Event Grid. Puede consumir eventos a través de varios controladores de eventos, como Azure Event Hubs, Azure Functions y aplicaciones lógicas. En función del desfase detectado por las supervisiones, puede realizar acciones mediante programación, como configurar una canalización de aprendizaje automático para volver a entrenar un modelo y volver a implementarlo.
Para empezar a integrar la supervisión de modelos de Azure Machine Learning con Event Grid:
Siga los pasos descritos en Configuración en Azure Portal. Asigne un nombre a su Suscripción de eventos, como Evento de monitorización, y seleccione solo la casilla Estado de ejecución cambiado en Tipos de eventos.
Advertencia
Asegúrese de seleccionar Estado de ejecución cambiado para el tipo de evento. No seleccione Desfase del conjunto de datos detectado, ya que se aplica al desfase de datos v1, en lugar de a la supervisión del modelo de Azure Machine Learning.
Siga los pasos descritos en Filtrar y suscribirse a eventos para configurar el filtrado de eventos para su escenario. Vaya a la pestaña Filtros y añada los siguientes Clave, Operador y Valor en Filtros avanzados:
- Clave:
data.RunTags.azureml_modelmonitor_threshold_breached - Valor: se ha producido un error debido a una o varias características que infringen los umbrales de métricas.
- Operador: contiene cadenas
Con este filtro, los eventos se generan cuando cambia el estado de ejecución (de Completado a Error o de Error a Completado) para cualquier supervisión dentro del área de trabajo de Azure Machine Learning.
- Clave:
Para filtrar a nivel de supervisión, utilice las siguientes Clave, Operador y Valor en Filtros avanzados:
- Clave:
data.RunTags.azureml_modelmonitor_threshold_breached - Valor:
your_monitor_name_signal_name - Operador: contiene cadenas
Asegúrese de que
your_monitor_name_signal_namees el nombre de una señal en la supervisión específica para la que desea filtrar los eventos. Por ejemplo,credit_card_fraud_monitor_data_drift. Para que este filtro funcione, esta cadena debe coincidir con el nombre de la señal de supervisión. Debe asignar un nombre a la señal con el nombre de la supervisión y el nombre de la señal para este caso.- Clave:
Cuando haya completado la configuración de Suscripción de eventos, seleccione el punto de conexión deseado para servir como controlador de eventos, como Azure Event Hubs.
Una vez capturados los eventos, puede verlos desde la página del punto de conexión:
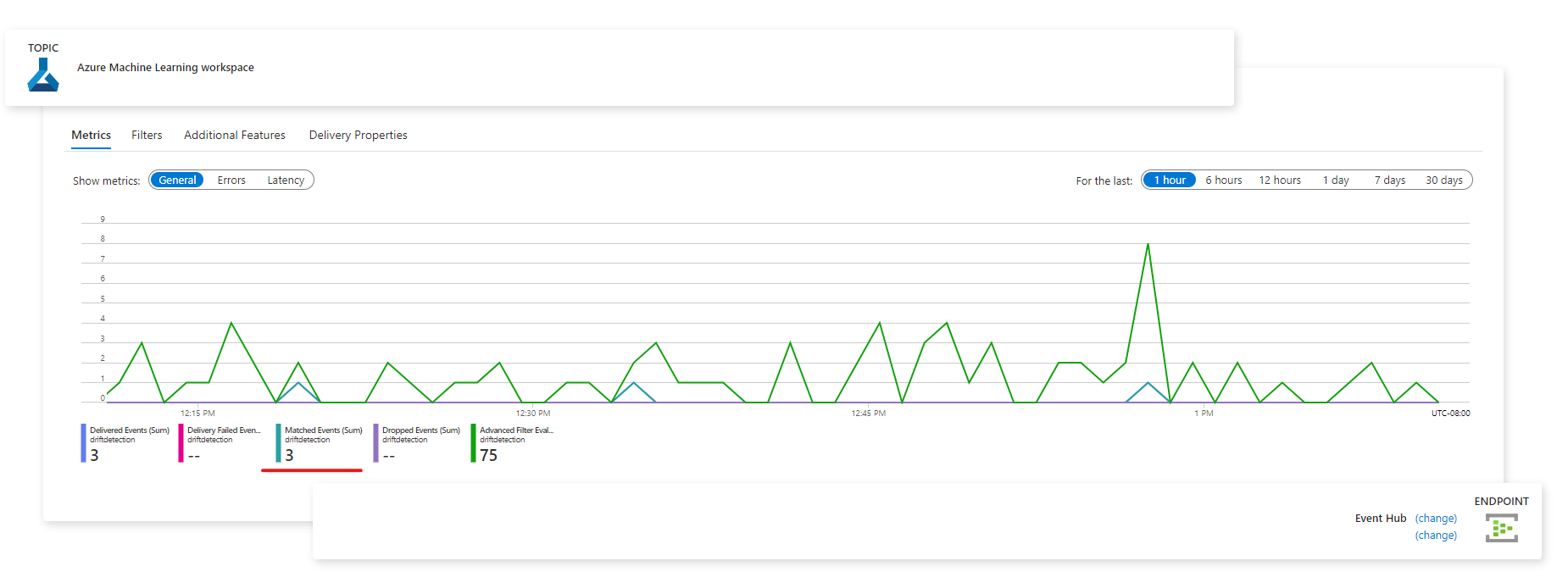

También puede ver eventos en la pestaña Métricas de Azure Monitor:

Contenido relacionado
- Recopilación de datos de modelos en producción (versión preliminar)
- Recopilar datos de producción de modelos implementados para la inferencia en tiempo real
- Programación del esquema YAML de la CLI (v2) para la supervisión de modelos (versión preliminar)
- Supervisión de modelos para aplicaciones de inteligencia artificial generativa
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de