SE APLICA A: Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
En este artículo, verá cómo implementar una nueva versión de un modelo de Machine Learning en producción sin provocar interrupciones. Se usa una estrategia de implementación azul-verde, que también se conoce como estrategia de implementación segura, para introducir una nueva versión de un servicio web en producción. Al usar esta estrategia, puede implementar la nueva versión del servicio web en un pequeño subconjunto de usuarios o solicitudes antes de implementarla por completo.
En este artículo se supone que usa puntos de conexión en línea o puntos de conexión que se usan para la inferencia en línea (en tiempo real). Hay dos tipos de puntos de conexión en línea: puntos de conexión en línea administrados y puntos de conexión en línea de Kubernetes. Para más información sobre los puntos de conexión y las diferencias entre los tipos de punto de conexión, consulte Puntos de conexión en línea administrados frente a puntos de conexión en línea de Kubernetes.
En este artículo se usan puntos de conexión en línea administrados para la implementación. Pero también incluye notas que explican cómo usar puntos de conexión de Kubernetes en lugar de puntos de conexión en línea administrados.
En este artículo, verá cómo:
- Defina un punto de conexión en línea con una implementación denominada
blue para atender la primera versión de un modelo.
- Escale la
blue implementación para que pueda gestionar más solicitudes.
- Implemente la segunda versión del modelo, que se denomina implementación
green, en el punto de conexión, pero envíe la implementación sin tráfico activo.
- Pruebe la
green implementación de forma aislada.
- Refleje un porcentaje del tráfico activo en la implementación de
green para validarlo.
- Envíe un pequeño porcentaje de tráfico activo a la implementación de
green.
- Envíe todo el tráfico activo a la implementación
green.
- Elimine la implementación
blue sin usar.
Requisitos previos
Una cuenta de usuario que tenga al menos uno de los siguientes roles de control de acceso basado en rol de Azure (RBAC de Azure):
- Un rol de propietario para el área de trabajo de Azure Machine Learning
- Un rol colaborador para el área de trabajo de Azure Machine Learning
- Un rol personalizado con
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/* permisos
Para obtener más información, consulte Administración del acceso a un área de trabajo de Azure Machine Learning.
Opcionalmente, Docker Engine, instalado y ejecutándose localmente. Este requisito previo es muy recomendable. Necesita implementar un modelo localmente y resulta útil para la depuración.
SE APLICA A: SDK de Python azure-ai-ml v2 (actual)
Un área de trabajo de Azure Machine Learning. Para conocer los pasos para crear un área de trabajo, consulte Creación del área de trabajo.
Sdk de Azure Machine Learning para Python v2. Para instalar el SDK, use el siguiente comando:
pip install azure-ai-ml azure-identity
Para actualizar una instalación existente del SDK a la versión más reciente, use el siguiente comando:
pip install --upgrade azure-ai-ml azure-identity
Para más información, consulte Biblioteca cliente de Azure Machine Learning Package para Python.
Una cuenta de usuario que tenga al menos uno de los siguientes roles de control de acceso basado en rol de Azure (RBAC de Azure):
- Un rol de propietario para el área de trabajo de Azure Machine Learning
- Un rol colaborador para el área de trabajo de Azure Machine Learning
- Un rol personalizado con
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/* permisos
Para obtener más información, consulte Administración del acceso a un área de trabajo de Azure Machine Learning.
Opcionalmente, Docker Engine, instalado y ejecutándose localmente. Este requisito previo es muy recomendable. Necesita implementar un modelo localmente y resulta útil para la depuración.
Suscripción a Azure. Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Un área de trabajo de Azure Machine Learning. Para obtener instrucciones para crear un área de trabajo, consulte Creación del área de trabajo.
Una cuenta de usuario que tenga al menos uno de los siguientes roles en el control de acceso basado en roles de Azure (Azure RBAC):
- Un rol de propietario para el área de trabajo de Azure Machine Learning
- Un rol colaborador para el área de trabajo de Azure Machine Learning
- Un rol personalizado que tiene permisos
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*
Para obtener más información, consulte Administración del acceso a un área de trabajo de Azure Machine Learning.
Preparación del sistema
Establecimiento de variables de entorno
Puede configurar los valores predeterminados para usarlos con la CLI de Azure. Para evitar pasar valores para la suscripción, el área de trabajo y el grupo de recursos varias veces, ejecute el código siguiente:
az account set --subscription <subscription-ID>
az configure --defaults workspace=<Azure-Machine-Learning-workspace-name> group=<resource-group-name>
Clone el repositorio de ejemplos
Para seguir este artículo, primero clone el repositorio de ejemplos (azureml-examples). A continuación, vaya al directorio del cli/ repositorio:
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples
cd cli
Sugerencia
Use --depth 1 para clonar solo la confirmación más reciente en el repositorio, lo que reduce el tiempo necesario para completar la operación.
Los comandos de este tutorial se encuentran en el archivo deploy-safe-rollout-online-endpoints.sh en el directorio cli y los archivos de configuración de YAML se encuentran en el subdirectorio endpoints/online/managed/sample/.
Nota
Los archivos de configuración de YAML para los puntos de conexión en línea de Kubernetes se encuentran en el subdirectorio endpoints/online/kubernetes/.
Clone el repositorio de ejemplos
Para ejecutar los ejemplos de entrenamiento, primero clone el repositorio de ejemplos (azureml-examples). A continuación, vaya al directorio azureml-examples/sdk/python/endpoints/online/managed:
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/sdk/python/endpoints/online/managed
Sugerencia
Use --depth 1 para clonar solo la confirmación más reciente en el repositorio, lo que reduce el tiempo necesario para completar la operación.
La información de este artículo se basa en el cuaderno online-endpoints-safe-rollout.ipynb. Este artículo contiene el mismo contenido que el cuaderno, pero el orden de los bloques de código difiere ligeramente entre los dos documentos.
Conexión a un área de trabajo de Azure Machine Learning
El área de trabajo es el recurso de nivel superior de Azure Machine Learning. Un área de trabajo proporciona un lugar centralizado para trabajar con todos los artefactos que cree al usar Azure Machine Learning. En esta sección, te conectarás a tu espacio de trabajo, donde realizarás tareas de implementación. Para seguir el procedimiento, abra su cuaderno de notas online-endpoints-safe-rollout.ipynb.
Importe las bibliotecas necesarias:
# import required libraries
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
CodeConfiguration,
)
from azure.identity import DefaultAzureCredential
Nota
Si está utilizando un punto de conexión en línea de Kubernetes, importe las clases KubernetesOnlineEndpoint y KubernetesOnlineDeployment desde la biblioteca azure.ai.ml.entities.
Configure las opciones del área de trabajo y obtenga un identificador para el área de trabajo:
Para conectarse a un área de trabajo, necesita parámetros de identificador: una suscripción, un grupo de recursos y un nombre de área de trabajo. Utilizas esta información en la clase MLClient del módulo azure.ai.ml para obtener acceso al área de trabajo necesaria de Azure Machine Learning. En este ejemplo, se usa la autenticación predeterminada de Azure.
# enter details of your AML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
Si tiene Git instalado en el equipo local, puede seguir las instrucciones para clonar el repositorio de ejemplos. De lo contrario, siga las instrucciones para descargar archivos del repositorio de ejemplos.
Clone el repositorio de ejemplos
Para seguir este artículo, clone el repositorio azureml-examples y, a continuación, vaya a la carpeta azureml-examples/cli/endpoints/online/model-1.
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples/cli/endpoints/online/model-1
Sugerencia
Use --depth 1 para clonar solo la confirmación más reciente en el repositorio, lo que reduce el tiempo necesario para completar la operación.
Descarga de archivos del repositorio de ejemplos
En lugar de clonar el repositorio de ejemplos, puede descargar el repositorio en la máquina local:
- Ir a https://github.com/Azure/azureml-examples/.
- Seleccione <> Código y, a continuación, vaya a la pestaña Local y seleccione Descargar ARCHIVO ZIP.
Definición del punto de conexión y la implementación
Los puntos de conexión en línea se usan para las inferencias en línea (en tiempo real). Los puntos de conexión en línea contienen implementaciones que están listas para recibir datos de los clientes y enviar respuestas en tiempo real.
Definición de un punto de conexión
En la tabla siguiente se enumeran los atributos clave que se deben especificar al definir un punto de conexión.
| Atributo |
Obligatorio u opcional |
Descripción |
| Nombre |
Obligatorio |
Nombre del punto de conexión. Debe ser único en la región de Azure en la que se encuentra. Para más información sobre las reglas de nomenclatura, consulte Puntos de conexión en línea y puntos de conexión por lotes de Azure Machine Learning. |
| Modo de autenticación |
Opcional |
Método de autenticación del punto de conexión. Puede elegir entre la autenticación basada en claves, keyy la autenticación basada en tokens de Azure Machine Learning, aml_token. Una clave no expira, pero un token sí. Para obtener más información sobre la autenticación, consulte Autenticación de clientes para puntos de conexión en línea. |
| Descripción |
Opcional |
Descripción del punto de conexión. |
| Etiquetas |
Opcional |
Diccionario de etiquetas para el punto de conexión. |
| Tráfico |
Opcional |
Reglas sobre cómo enrutar el tráfico entre implementaciones. Representa el tráfico como un diccionario de pares clave-valor, donde la clave representa el nombre de implementación y el valor representa el porcentaje de tráfico a esa implementación. Puede establecer el tráfico solo después de crear las implementaciones en un punto de conexión. También puede actualizar el tráfico de un punto de conexión en línea después de crear las implementaciones. Para obtener más información sobre cómo usar el tráfico reflejado, consulte Asignación de un pequeño porcentaje de tráfico activo a la nueva implementación. |
| Tráfico reflejado |
Opcional |
Porcentaje del tráfico activo que se va a reflejar en una implementación. Para obtener más información sobre cómo usar el tráfico reflejado, consulte Probar la implementación con tráfico reflejado. |
Para ver una lista completa de atributos que puede especificar al crear un punto de conexión, consulte Esquema YAML de endpoint en línea de CLI (v2). Para la versión 2 del SDK de Azure Machine Learning para Python, consulte Clase ManagedOnlineEndpoint.
Definición de una implementación
Una implementación es un conjunto de recursos necesarios para hospedar el modelo que realiza la inferencia real. En la tabla siguiente se describen los atributos clave que se deben especificar al definir una implementación.
| Atributo |
Obligatorio u opcional |
Descripción |
| Nombre |
Obligatorio |
Nombre del despliegue. |
| El nombre del punto de conexión |
Obligatorio |
El nombre del punto de conexión en el que se creará la implementación. |
| Modelo |
Opcional |
Modelo que se usará para la implementación. Este valor puede ser una referencia a un modelo con versiones existente en el área de trabajo o una especificación de modelo en línea. En los ejemplos de este artículo, un modelo realiza regresión scikit-learn. |
| Ruta de acceso al código |
Opcional |
Ruta de acceso a la carpeta del entorno de desarrollo local que contiene todo el código fuente de Python para puntuar el modelo. Puede usar directorios y paquetes anidados. |
| Script de puntuación |
Opcional |
Código de Python que ejecuta el modelo en una solicitud de entrada determinada. Este valor puede ser la ruta de acceso relativa al archivo de puntuación en la carpeta de código fuente.
El script de puntuación recibe los datos enviados a un servicio web implementado y los pasa al modelo. A continuación, el script ejecuta el modelo y devuelve su respuesta al cliente. El script de puntuación es específico para el modelo y debe entender los datos que el modelo espera como entrada y devuelve como salida.
En los ejemplos de este artículo se usa un archivo score.py. Este código de Python debe tener una función init y una función run. La función init se llama después de crear o actualizar el modelo. Puede usarlo para almacenar en caché el modelo en memoria, por ejemplo. Se llama a la función run en cada invocación del punto de conexión para realizar la puntuación o predicción reales. |
| Entorno |
Obligatorio |
Entorno para hospedar el modelo y el código. Este valor puede ser una referencia a un entorno con versiones existente en el área de trabajo o una especificación de entorno en línea. El entorno puede ser una imagen de Docker con dependencias de Conda, un Dockerfile o un entorno registrado. |
| Tipo de instancia |
Obligatorio |
Tamaño de máquina virtual que se va a usar para la implementación. Para obtener una lista de tamaños admitidos, consulte la lista de SKU de puntos de conexión en línea gestionados. |
| Recuento de instancias |
Obligatorio |
El número de instancias que se usarán para la implementación. Basas el valor en la carga de trabajo que esperas. Para lograr una alta disponibilidad, se recomienda usar al menos tres instancias. Azure Machine Learning reserva un 20 % adicional para realizar actualizaciones. Para más información, consulte Puntos de conexión en línea y puntos de conexión por lotes de Azure Machine Learning. |
Para ver una lista completa de atributos que puede especificar al crear una implementación, consulte Esquema YAML de implementación en línea administrada de la CLI (v2). Para la versión 2 del SDK de Python, consulte Clase ManagedOnlineDeployment.
Creación de un punto de conexión en línea
En primer lugar, establezca el nombre del punto de conexión y, a continuación, configúrelo. En este artículo, usará el archivo endpoints/online/managed/sample/endpoint.yml para configurar el punto de conexión. Ese archivo contiene las siguientes líneas:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: my-endpoint
auth_mode: key
En la tabla siguiente se describen las claves que usa el formato YAML del punto de conexión. Para ver cómo especificar estos atributos, consulte Esquema YAML del punto de conexión en línea de la CLI (v2). Para obtener información sobre los límites relacionados con los puntos de conexión en línea administrados, consulte Puntos de conexión en línea y puntos de conexión por lotes de Azure Machine Learning.
| Clave |
Descripción |
$schema |
(Opcional) El esquema de YAML. Para ver todas las opciones disponibles en el archivo YAML, puede ver el esquema en el bloque de código anterior en un explorador. |
name |
Nombre del punto de conexión. |
auth_mode |
Modo de autenticación. Use key para la autenticación basada en claves. Use aml_token para la autenticación basada en tokens de Azure Machine Learning. Para obtener el token más reciente, use el comando az ml online-endpoint get-credentials. |
Creación de un punto de conexión en línea:
Establezca el nombre del punto de conexión ejecutando el siguiente comando de Unix. Reemplace YOUR_ENDPOINT_NAME por un nombre único.
export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"
Importante
Los nombres del punto de conexión deben ser únicos dentro de una región de Azure. Por ejemplo, en la región westus2 de Azure solo puede haber un punto de conexión con el nombre my-endpoint.
Cree el punto de conexión en la nube mediante la ejecución del código siguiente. Este código usa el archivo endpoint.yml para configurar el punto de conexión:
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
Creación de la implementación azul
Puede usar el archivo endpoints/online/managed/sample/blue-deployment.yml para configurar los aspectos clave de una implementación denominada blue. Ese archivo contiene las siguientes líneas:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: ../../model-1/model/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yaml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
Para usar el archivo blue-deployment.yml para crear la implementación de blue para su punto de conexión, ejecute el siguiente comando:
az ml online-deployment create --name blue --endpoint-name $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment.yml --all-traffic
Importante
La marca --all-traffic del comando az ml online-deployment create asigna el 100 % del tráfico del punto de conexión a la implementación recién creada blue.
En el archivo blue-deployment.yaml, la path línea especifica dónde cargar archivos. La CLI de Azure Machine Learning usa esta información para cargar los archivos y registrar el modelo y el entorno. Como procedimiento recomendado para producción, debe registrar el modelo y el entorno y especificar el nombre y la versión registrados por separado en el código YAML. Use el formato model: azureml:<model-name>:<model-version> para el modelo, por ejemplo, model: azureml:my-model:1. Para el entorno, use el formato environment: azureml:<environment-name>:<environment-version>, por ejemplo, environment: azureml:my-env:1.
Para el registro, puede extraer las definiciones de YAML de model y environment en archivos YAML diferentes y usar los comandos az ml model create y az ml environment create. Para obtener más información sobre estos comandos, ejecute az ml model create -h y az ml environment create -h.
Para más información sobre cómo registrar el modelo como un recurso, consulte Registro de un modelo mediante la CLI de Azure o el SDK de Python. Para obtener más información sobre cómo crear un entorno, consulte Creación de un entorno personalizado.
Creación de un punto de conexión en línea
Para crear un punto de conexión en línea administrado, use la clase ManagedOnlineEndpoint. Esta clase proporciona una manera de configurar los aspectos clave del punto de conexión.
Configuración del punto de conexión:
# Creating a unique endpoint name with current datetime to avoid conflicts
import random
online_endpoint_name = "endpt-moe-" + str(random.randint(0, 10000))
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is a sample online endpoint",
auth_mode="key",
tags={"foo": "bar"},
)
Nota
Para crear un punto de conexión en línea de Kubernetes, use la clase KubernetesOnlineEndpoint.
Creación del punto de conexión:
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Creación de la implementación azul
Para crear una implementación para el punto de conexión en línea administrado, use la clase ManagedOnlineDeployment. Esta clase proporciona una manera de configurar los aspectos clave de la implementación.
Configure la implementación de blue:
# create blue deployment
model = Model(path="../model-1/model/sklearn_regression_model.pkl")
env = Environment(
conda_file="../model-1/environment/conda.yaml",
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
)
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
environment=env,
code_configuration=CodeConfiguration(
code="../model-1/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
En este ejemplo, el path parámetro especifica dónde cargar archivos. El SDK de Python usa esta información para cargar los archivos y registrar el modelo y el entorno. Como procedimiento recomendado para producción, debe registrar el modelo y el entorno y especificar el nombre y la versión registrados por separado en el código.
Para más información sobre cómo registrar el modelo como un recurso, consulte Registro de un modelo mediante la CLI de Azure o el SDK de Python.
Para obtener más información sobre cómo crear un entorno, consulte Creación de un entorno personalizado.
Nota
Para crear una implementación para el punto de conexión en línea Kubernetes, use la clase KubernetesOnlineDeployment.
Cree la implementación:
ml_client.online_deployments.begin_create_or_update(blue_deployment).result()
# blue deployment takes 100 traffic
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Al crear un punto de conexión en línea administrado en Azure Machine Learning Studio, debe definir una implementación inicial para el punto de conexión. Para poder definir una implementación, debe tener un modelo registrado en el área de trabajo. En la sección siguiente se muestra cómo registrar un modelo que se va a usar para la implementación.
Registro del modelo
Un registro de modelos es una entidad lógica en el área de trabajo. Esta entidad puede contener un único archivo de modelo o un directorio de varios archivos. Como procedimiento recomendado para producción, debe registrar el modelo y el entorno.
Para registrar el modelo de ejemplo, siga los pasos descritos en las secciones siguientes.
Carga de los archivos de modelo
Vaya a Azure Machine Learning Studio.
Seleccione Modelos.
Seleccione Registrar y, después, Seleccione Desde archivos locales.
En Tipo de modelo, seleccione Tipo no especificado.
Seleccione Examinar y, a continuación, seleccione Examinar carpeta.
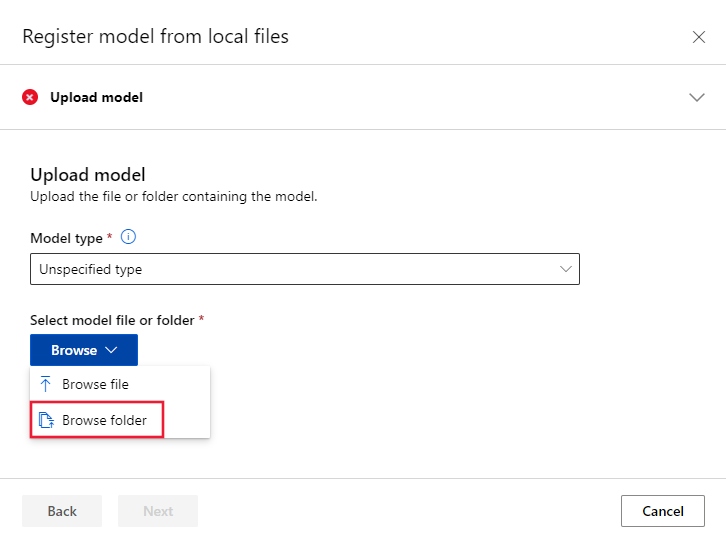
Vaya a la copia local del repositorio que ha clonado o descargado anteriormente y seleccione \azureml-examples\cli\endpoints\online\model-1\model. Cuando se le solicite, seleccione Cargar y espere a que finalice la carga.
Seleccione Siguiente.
En la página Configuración del modelo, en Nombre, escriba un nombre descriptivo para el modelo. En los pasos de este artículo se supone que el modelo se llama model-1.
Seleccione Siguiente y, a continuación, seleccione Registrar para completar el registro.
Para ver los ejemplos posteriores de este artículo, también debe registrar un modelo desde la carpeta \azureml-examples\cli\endpoints\online\model-2\model en la copia local del repositorio. Para registrar ese modelo, repita los pasos de las dos secciones anteriores, pero asigne un nombre al modelo model-2.
Para más información sobre cómo trabajar con modelos registrados, consulte Trabajar con modelos registrados en Azure Machine Learning.
Para obtener información sobre cómo crear un entorno en Studio, consulte Creación de un entorno.
Creación de un punto de conexión en línea administrado y la implementación azul
Puede usar Azure Machine Learning Studio para crear un punto de conexión en línea administrado directamente en el explorador. Al crear un punto de conexión en línea administrado en Estudio, debe definir una implementación inicial. No puede crear un punto de conexión en línea administrado vacío.
Una forma de crear un punto de conexión en línea administrado en el estudio es desde la página Modelos. Este método también ofrece una manera sencilla de agregar un modelo a una implementación en línea administrada existente. Para implementar el modelo denominado model-1 que registró anteriormente en la sección Registrar el modelo , siga los pasos descritos en las secciones siguientes.
Selección de un modelo
Vaya a Azure Machine Learning Studio y seleccione Modelos.
En la lista, seleccione el model-1 modelo.
Seleccione Implementar>Punto de conexión en tiempo real.
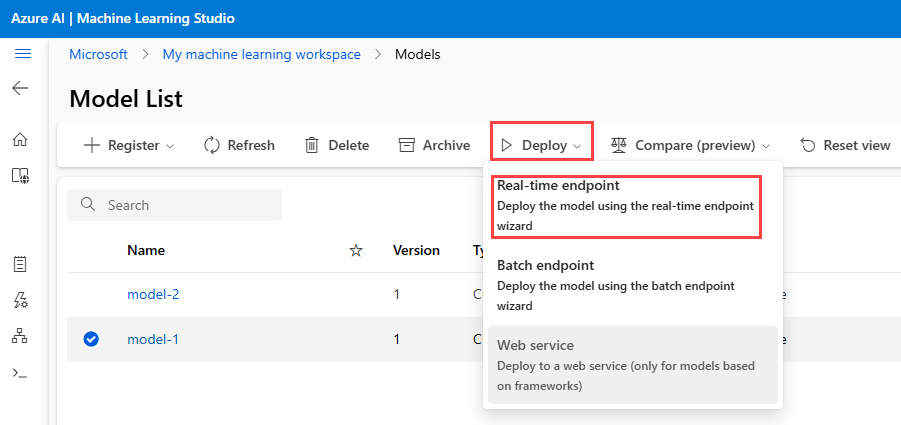
Se abre una ventana que puede usar para especificar información detallada sobre el punto de conexión.

En Nombre del punto de conexión, escriba un nombre para el punto de conexión.
En Tipo de proceso, mantenga el valor predeterminado de Administrado.
En Tipo de autenticación, mantenga el valor predeterminado de la autenticación basada en claves.
Seleccione Siguiente y, después, en la página Modelo , seleccione Siguiente.
Configuración de las opciones restantes y creación de la implementación
En la página Implementación , siga estos pasos:
- En Nombre de implementación, escriba azul.
- Si quieres ver gráficos de las actividades del punto de conexión en el estudio más adelante:
- En Recopilación de datos de inferencia, active el botón de alternancia.
- En Diagnósticos de Application Insights, active el interruptor.
- Seleccione Siguiente.
En la página Código y entorno para la inferencia , siga estos pasos:
- En el apartado Seleccionar un script de puntuación para inferencia, selecciona Examinar y, a continuación, selecciona el archivo \azureml-examples\cli\endpoints\online\model-1\onlinescoring\score.py del repositorio que clonaste o descargaste previamente.
- En el cuadro de búsqueda situado encima de la lista de entornos, empiece a escribir sklearn y, a continuación, seleccione el entorno mantenido sklearn-1.5:19 .
- Seleccione Siguiente.
En la página Cálculo, siga estos pasos:
- En Máquina virtual, mantenga el valor predeterminado.
- En Recuento de instancias, reemplace el valor predeterminado por 1.
- Seleccione Siguiente.
En la página Tráfico activo , seleccione Siguiente para aceptar la asignación de tráfico predeterminada del 100 por ciento a la blue implementación.
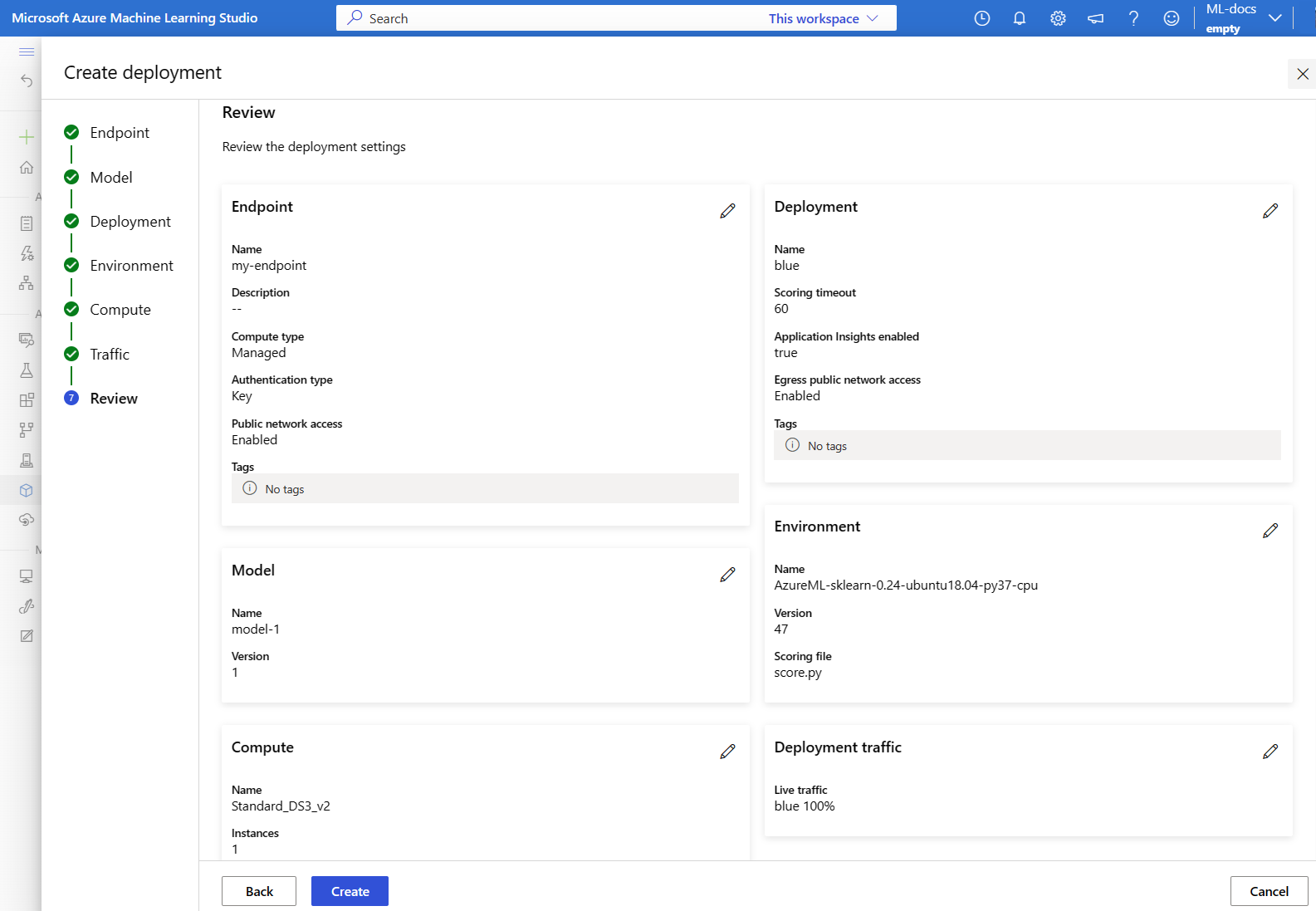
En la página Revisar , revise la configuración de implementación y seleccione Crear.
Creación de un punto de conexión desde la página Puntos de conexión
Como alternativa, puede crear un punto de conexión en línea administrado desde la página Puntos de conexión del estudio.
Vaya a Azure Machine Learning Studio.
Seleccione Puntos de conexión.
Selecciona Crear.
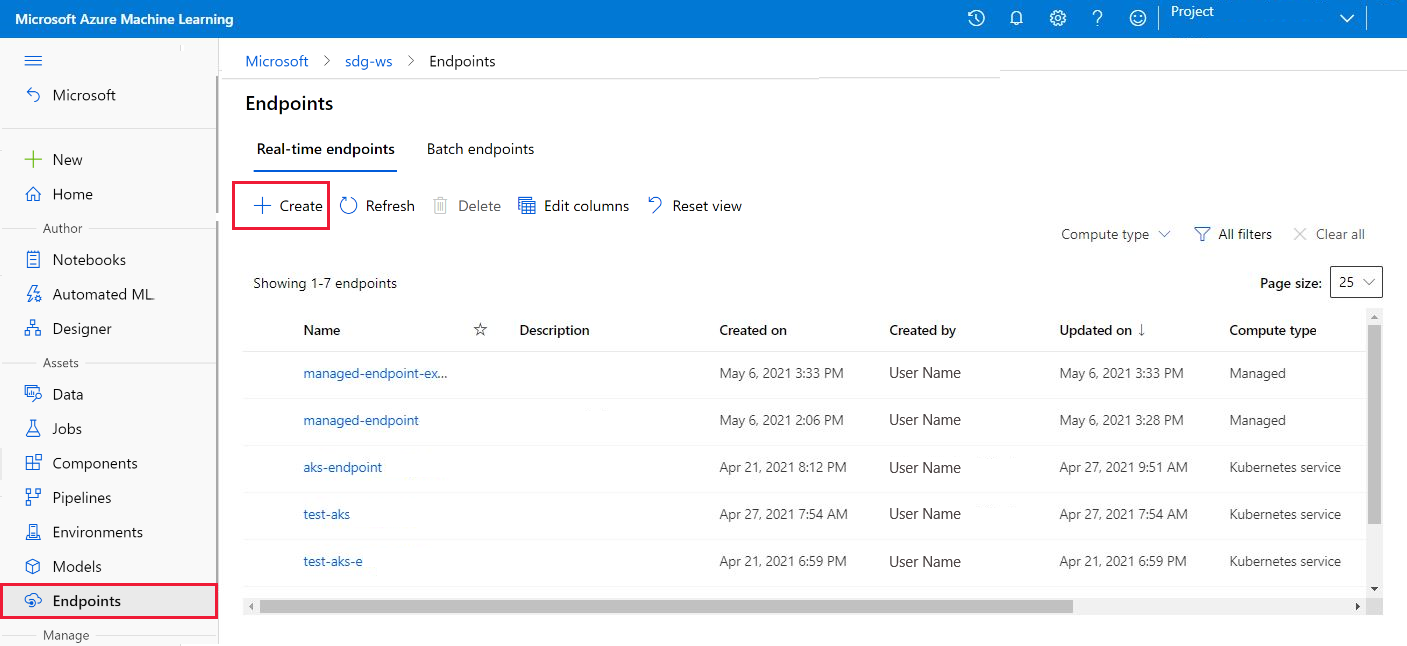
Se abre una ventana que puede usar para especificar información detallada sobre el punto de conexión y la implementación.
Seleccione un modelo y, a continuación, seleccione Seleccionar.
Escriba la configuración del punto de conexión y la implementación, tal como se describe en las dos secciones anteriores. En cada paso, use los valores predeterminados y, en el último paso, seleccione Crear para crear la implementación.
Confirmación de la implementación existente
Una manera de confirmar la implementación existente es invocar su punto de conexión para que pueda puntuar su modelo para una solicitud de entrada determinada. Al invocar el punto de conexión a través de la CLI de Azure o el SDK de Python, puede especificar el nombre de la implementación para recibir el tráfico entrante.
Nota
A diferencia de la CLI de Azure o el SDK de Python, Azure Machine Learning Studio requiere que especifique una implementación al invocar un punto de conexión.
Invocación de un punto de conexión con un nombre de implementación
Al invocar un punto de conexión, puede especificar el nombre de una implementación que desea recibir tráfico. En este caso, Azure Machine Learning enruta el tráfico del punto de conexión directamente a la implementación especificada y devuelve su salida. Puede usar la --deployment-name opción de la CLI de Azure Machine Learning v2 o la deployment_name opción del SDK de Python v2 para especificar la implementación.
Invocación del punto de conexión sin especificar una implementación
Si invoca el punto de conexión sin especificar la implementación que desea recibir tráfico, Azure Machine Learning enruta el tráfico entrante del punto de conexión a las implementaciones del punto de conexión en función de la configuración del control de tráfico.
La configuración del control de tráfico asigna porcentajes especificados del tráfico entrante a cada implementación del punto de conexión. Por ejemplo, si las reglas de tráfico especifican que una implementación determinada en el punto de conexión debe recibir tráfico entrante el 40 % del tiempo, Azure Machine Learning enruta el 40 % del tráfico del punto de conexión a esa implementación.
Para ver el estado del punto de conexión y la implementación existentes, ejecute los siguientes comandos:
az ml online-endpoint show --name $ENDPOINT_NAME
az ml online-deployment show --name blue --endpoint $ENDPOINT_NAME
La salida muestra información sobre el $ENDPOINT_NAME punto de conexión y la blue implementación.
Prueba del punto de conexión mediante datos de ejemplo
Puede invocar el punto de conexión mediante el invoke comando . El siguiente comando usa el archivo JSONsample-request.json para enviar una solicitud de ejemplo:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
Use el código siguiente para comprobar el estado de la implementación del modelo:
ml_client.online_endpoints.get(name=online_endpoint_name)
Prueba del punto de conexión mediante datos de ejemplo
Puede usar la instancia de que ha creado anteriormente para obtener un identificador al punto de conexión MLClient. Para invocar el punto de conexión, puede usar el invoke comando con los parámetros siguientes:
endpoint_name: el nombre del punto de conexión.request_file: un archivo que contiene datos de solicituddeployment_name: el nombre de una implementación que se va a probar en el punto de conexión.
El código siguiente usa el archivo JSONsample-request.json para enviar una solicitud de ejemplo.
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name="blue",
request_file="../model-1/sample-request.json",
)
Visualizar puntos de conexión en línea administrados
Puede ver todos los puntos de conexión en línea administrados en la página de puntos de conexión de Studio. La pestaña Detalles de la página de cada punto de conexión muestra información crítica, como el URI del punto de conexión, el estado, las herramientas de prueba, los monitores de actividad, los registros de implementación y el código de consumo de ejemplo. Para ver esta información, siga estos pasos:
En Studio, seleccione Puntos de conexión. Se muestra una lista de todos los puntos de conexión del área de trabajo.
Opcionalmente, cree un filtro en el tipo de instancia de proceso para mostrar solo los tipos administrados.
Seleccione el nombre de un punto de conexión para ver la página Detalles correspondiente.

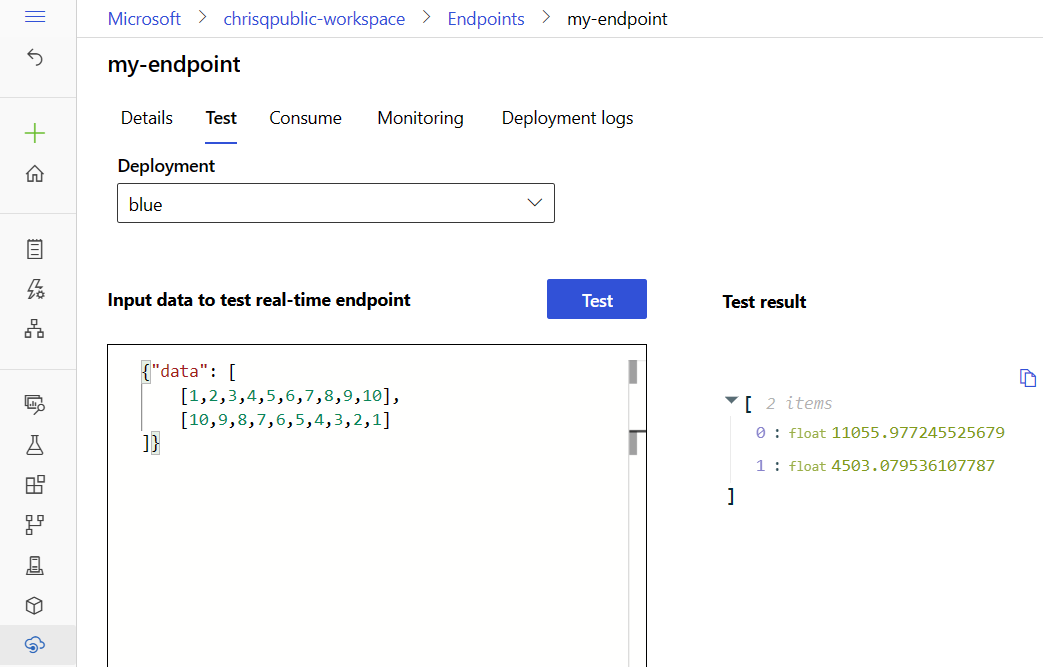
Prueba del punto de conexión mediante datos de ejemplo
En la página del punto de conexión, puede usar la pestaña Prueba para probar la implementación en línea administrada. Para introducir la entrada de ejemplo y ver los resultados, siga estos pasos:
En la página del punto de conexión, vaya a la pestaña Prueba . En la lista Implementación , la blue implementación ya está seleccionada.
Vaya al archivosample-request.json y copie su entrada de ejemplo.
En Studio, pegue la entrada de ejemplo en el cuadro Entrada.
Seleccione Probar.
Escalado de la implementación existente para controlar más tráfico
En la implementación descrita en Implementación y puntuación de un modelo de aprendizaje automático a través de un punto de conexión en línea , el valor instance_count se establece 1 en el archivo YAML de implementación. Puede escalar horizontalmente mediante el comando update:
az ml online-deployment update --name blue --endpoint-name $ENDPOINT_NAME --set instance_count=2
Nota
En el comando anterior, la --set opción invalida la configuración de implementación. Como alternativa, puede actualizar el archivo YAML y pasarlo como entrada al update comando mediante la --file opción .
Puede usar la instancia de MLClient que creó anteriormente para obtener un identificador de la implementación. Para escalar la implementación, puede aumentar o disminuir el valor de instance_count.
# scale the deployment
blue_deployment = ml_client.online_deployments.get(
name="blue", endpoint_name=online_endpoint_name
)
blue_deployment.instance_count = 2
ml_client.online_deployments.begin_create_or_update(blue_deployment).result()
# Get the details for online endpoint
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
# existing traffic details
print(endpoint.traffic)
# Get the scoring URI
print(endpoint.scoring_uri)
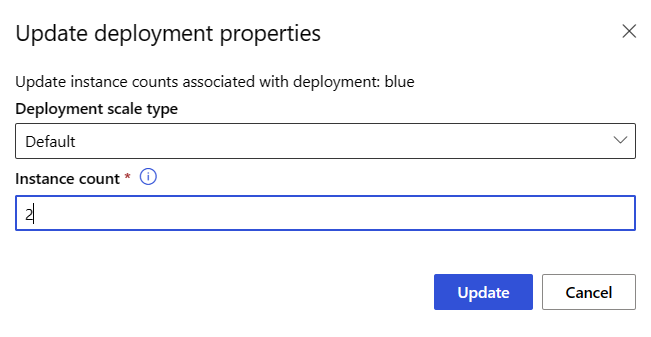
Para escalar o reducir verticalmente la implementación ajustando el número de instancias, siga estos pasos:
En la página del punto de conexión, vaya a la pestaña Detalles y busque la tarjeta de la implementación blue.
En el encabezado de la blue tarjeta de implementación, seleccione el icono de edición.
En Recuento de instancias, escriba 2.
Selecciona Actualización.
Implementar un nuevo modelo pero sin enviar tráfico
Cree una nueva implementación denominada green:
az ml online-deployment create --name green --endpoint-name $ENDPOINT_NAME -f endpoints/online/managed/sample/green-deployment.yml
Dado que no asigna explícitamente ningún tráfico a la implementación green, tiene cero tráfico asignado a ella. Puede comprobar ese hecho mediante el comando siguiente:
az ml online-endpoint show -n $ENDPOINT_NAME --query traffic
Prueba de la nueva implementación
Aunque la green implementación tiene el 0 % del tráfico asignado a ella, puede invocarla directamente mediante la --deployment opción :
az ml online-endpoint invoke --name $ENDPOINT_NAME --deployment-name green --request-file endpoints/online/model-2/sample-request.json
Si desea usar un cliente REST para invocar la implementación directamente sin pasar por reglas de tráfico, establezca el siguiente encabezado HTTP: azureml-model-deployment: <deployment-name>. El código siguiente usa client for URL (cURL) para invocar la implementación directamente. Puede ejecutar el código en un entorno unix o subsistema de Windows para Linux (WSL). Para obtener instrucciones para recuperar el $ENDPOINT_KEY valor, consulte Obtención de la clave o token para las operaciones del plano de datos.
# get the scoring uri
SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query scoring_uri)
# use curl to invoke the endpoint
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --header "azureml-model-deployment: green" --data @endpoints/online/model-2/sample-request.json
Cree una nueva implementación para el punto de conexión en línea administrado y asigne un nombre a la implementación green:
# create green deployment
model2 = Model(path="../model-2/model/sklearn_regression_model.pkl")
env2 = Environment(
conda_file="../model-2/environment/conda.yaml",
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04",
)
green_deployment = ManagedOnlineDeployment(
name="green",
endpoint_name=online_endpoint_name,
model=model2,
environment=env2,
code_configuration=CodeConfiguration(
code="../model-2/onlinescoring", scoring_script="score.py"
),
instance_type="Standard_DS3_v2",
instance_count=1,
)
# use MLClient to create green deployment
ml_client.online_deployments.begin_create_or_update(green_deployment).result()
Nota
Si va a crear una implementación para un punto de conexión en línea de Kubernetes, use la KubernetesOnlineDeployment clase y especifique un tipo de instancia de Kubernetes en el clúster de Kubernetes.
Prueba de la nueva implementación
Aunque la implementación tiene el green 0 % del tráfico asignado a él, todavía puede invocar el punto de conexión y la implementación. El código siguiente usa el archivo JSONsample-request.json para enviar una solicitud de ejemplo.
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name="green",
request_file="../model-2/sample-request.json",
)
Puede crear una nueva implementación para agregar al punto de conexión en línea administrado. Para crear una implementación denominada green, siga los pasos descritos en las secciones siguientes.
En la página del punto de conexión, vaya a la pestaña Detalles y seleccione Agregar implementación.
En la página Seleccionar un modelo , seleccione model-2 y, a continuación, seleccione Seleccionar.
En la página Punto de conexión y en la página Modelo , seleccione Siguiente.
En la página Implementación , siga estos pasos:
- En Nombre de implementación, escriba verde.
- En Recopilación de datos de inferencia, active el interruptor.
- En Diagnósticos de Application Insights, encienda el interruptor.
- Seleccione Siguiente.
En la página Código y entorno para la inferencia , siga estos pasos:
- En Seleccionar un script de puntuación para la inferencia, seleccione Examinar, y a continuación, seleccione el archivo \azureml-examples\cli\endpoints\online\model-2\onlinescoring\score.py archivo del repositorio que ha clonado o descargado anteriormente.
- En el cuadro de búsqueda situado encima de la lista de entornos, empiece a escribir sklearn y, a continuación, seleccione el entorno mantenido sklearn-1.5:19 .
- Seleccione Siguiente.
En la página Proceso, siga estos pasos:
- En Máquina virtual, mantenga el valor predeterminado.
- En Recuento de instancias, reemplace el valor predeterminado por 1.
- Seleccione Siguiente.
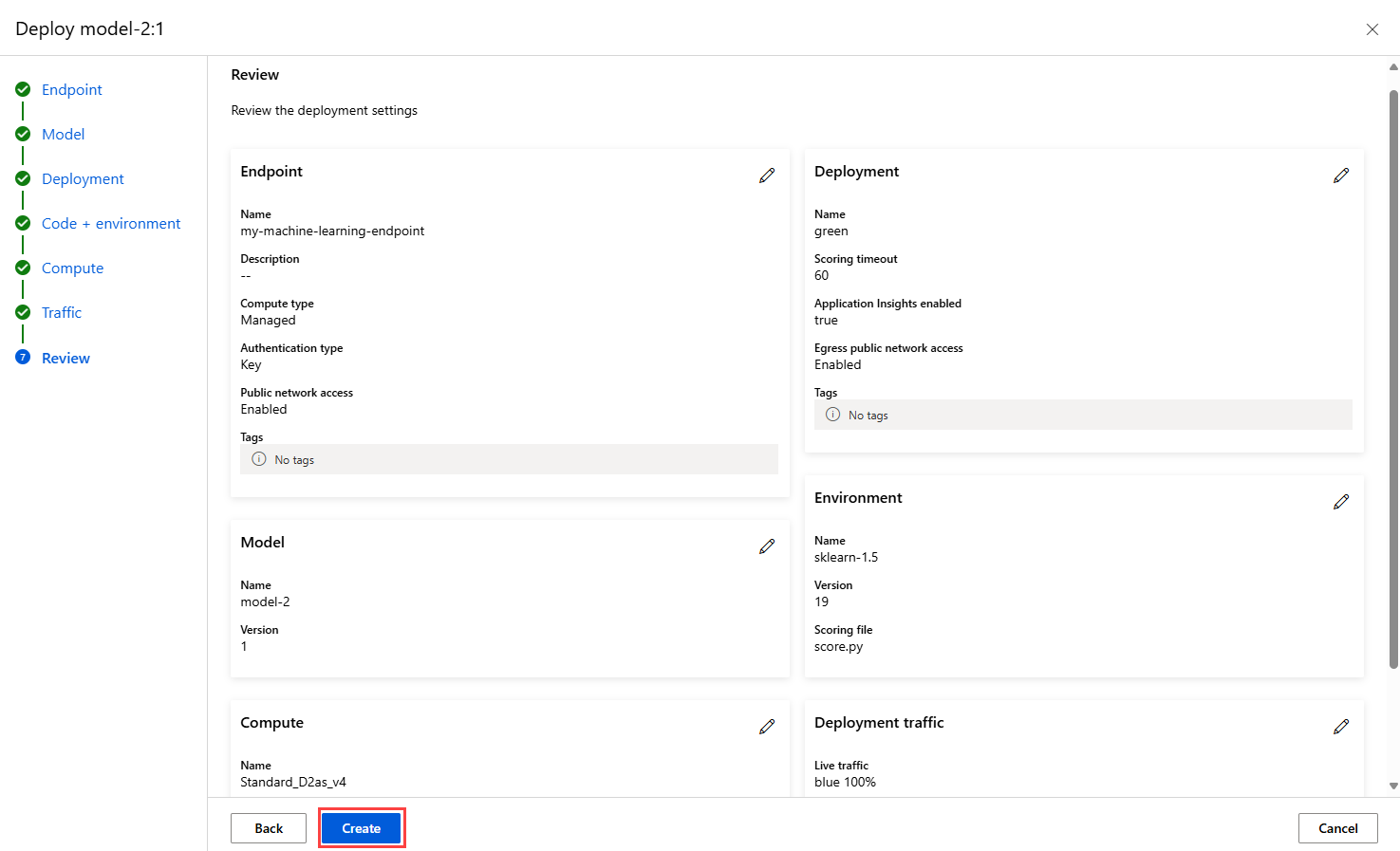
Configuración de las opciones restantes y creación de la implementación
En la página Tráfico activo , seleccione Siguiente para aceptar la asignación de tráfico predeterminada del 100 por ciento a la blue implementación y del 0 por ciento a green.
En la página Revisar , revise la configuración de implementación y seleccione Crear.
Adición de una implementación desde la página Modelos
Como alternativa, puede usar la página Models (Modelos) para agregar una implementación:
En Studio, seleccione Modelos.
Seleccione un modelo en la lista.
Seleccione Implementar>Punto de conexión en tiempo real.
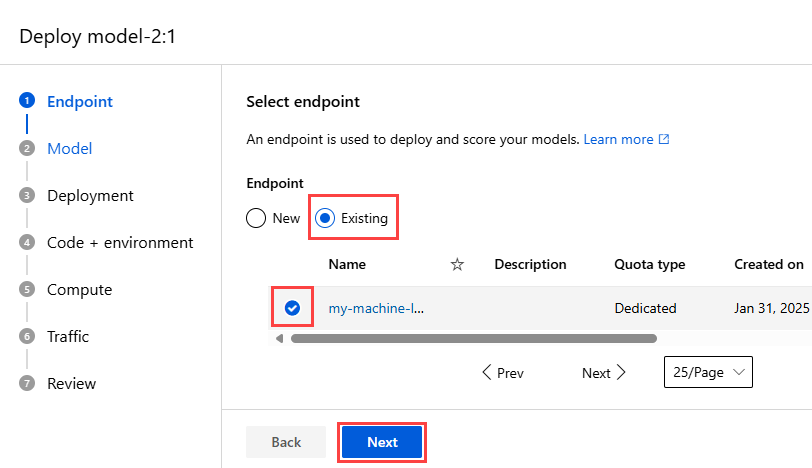
En Punto de conexión, seleccione Existente.
En la lista de puntos de conexión, seleccione el punto de conexión en línea administrado en el que desea implementar el modelo y, a continuación, seleccione Siguiente.
En la página Modelo , seleccione Siguiente.
Para terminar de crear la implementación, siga los green pasos del 4 al 6 de la sección Configurar la configuración inicial y todos los pasos de la sección Configurar las opciones restantes y crear la implementación .
Nota
Al agregar una nueva implementación a un punto de conexión, puede usar la página Actualizar asignación de tráfico para ajustar el equilibrio de tráfico entre las implementaciones. Para seguir el resto de los procedimientos en este artículo, mantenga por ahora la asignación de tráfico predeterminada del 100 por ciento a la implementación blue y del 0 por ciento a la implementación green.
Prueba de la nueva implementación
Aunque el 0 por ciento del tráfico va a la implementación green, todavía puede invocar el punto de conexión y esa implementación. En la página del punto de conexión, puede usar la pestaña Prueba para probar la implementación en línea administrada. Para introducir la entrada de ejemplo y ver los resultados, siga estos pasos:
En la página del punto de conexión, vaya a la pestaña Prueba .
En la lista Implementación , seleccione verde.
Vaya al archivosample-request.json y copie su entrada de ejemplo.
En Studio, pegue la entrada de ejemplo en el cuadro Entrada.
Seleccione Probar.
Prueba de la implementación con tráfico reflejado
Después de probar la implementación green, puede reflejar un porcentaje del tráfico activo al punto de conexión copiando ese porcentaje de tráfico y enviándolo a la implementación green. La creación de reflejo del tráfico, que también se denomina sombreado, no cambia los resultados devueltos a los clientes; el 100 % de las solicitudes siguen fluyendo a la implementación blue. El porcentaje reflejado del tráfico se copia y también se envía a la implementación green para que pueda recopilar métricas y registros sin afectar a los clientes.
La creación de reflejo es útil cuando desea validar una nueva implementación sin que los clientes resulten afectados. Por ejemplo, puede usar la creación de reflejo para comprobar si la latencia está dentro de límites aceptables o para comprobar que no hay errores HTTP. El uso de la creación de reflejo del tráfico o la sombreado para probar una nueva implementación también se conoce como pruebas de sombras. La implementación que recibe el tráfico reflejado, en este caso, la implementación green también se puede denominar implementación sombreada.
La creación de reflejo tiene las siguientes limitaciones:
- La creación de reflejo es compatible con las versiones 2.4.0 y posteriores de la CLI de Azure Machine Learning y las versiones 1.0.0 y posteriores del SDK de Python. Si usa una versión anterior de la CLI de Azure Machine Learning o el SDK de Python para actualizar un punto de conexión, perderá la configuración del tráfico reflejado.
- La creación de reflejo no se admite actualmente en los puntos de conexión en línea de Kubernetes.
- Puede reflejar el tráfico en una sola implementación en un punto de conexión.
- El porcentaje máximo de tráfico que puede reflejar es del 50 %. Este límite limita el efecto en la cuota de ancho de banda del punto de conexión, que tiene un valor predeterminado de 5 MBps. El ancho de banda del punto de conexión se limita si supera la cuota asignada. Para obtener información sobre la supervisión de la limitación de ancho de banda, consulte Limitación de ancho de banda.
Tenga en cuenta también el comportamiento siguiente:
- Puede configurar una implementación para recibir solo tráfico activo o tráfico reflejado, no ambos.
- Al invocar un punto de conexión, puede especificar el nombre de cualquiera de sus implementaciones, incluso una implementación. instantánea para devolver la predicción.
- Al invocar un punto de conexión y especificar el nombre de una implementación para recibir tráfico entrante, Azure Machine Learning no refleja el tráfico en la implementación en sombra. Azure Machine Learning refleja el tráfico en la implementación de sombra desde el tráfico enviado al punto de conexión cuando no se especifica una implementación.
Si establece que la implementación green reciba el 10 % del tráfico reflejado, los clientes seguirán recibiendo predicciones solo de la implementación blue.
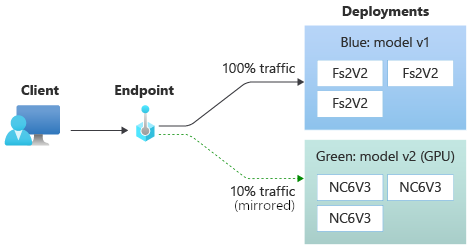
Use el siguiente comando para reflejar el 10 % del tráfico y enviarlo a la green implementación:
az ml online-endpoint update --name $ENDPOINT_NAME --mirror-traffic "green=10"
Puede probar el tráfico reflejado invocando el punto de conexión varias veces sin especificar una implementación para recibir el tráfico entrante:
for i in {1..20} ; do
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
done
Puede confirmar que el porcentaje especificado del tráfico se envía a la green implementación comprobando los registros de la implementación:
az ml online-deployment get-logs --name green --endpoint $ENDPOINT_NAME
Después de las pruebas, puede establecer el tráfico reflejado en cero para deshabilitar la creación de reflejo:
az ml online-endpoint update --name $ENDPOINT_NAME --mirror-traffic "green=0"
Use el código siguiente para reflejar el 10 % del tráfico y enviarlo a la green implementación:
endpoint.mirror_traffic = {"green": 10}
ml_client.begin_create_or_update(endpoint).result()
Puede probar el tráfico reflejado invocando el punto de conexión varias veces sin especificar una implementación para recibir el tráfico entrante:
# You can test mirror traffic by invoking the endpoint several times
for i in range(20):
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="../model-1/sample-request.json",
)
Puede confirmar que el porcentaje especificado del tráfico se envía a la green implementación comprobando los registros de la implementación:
ml_client.online_deployments.get_logs(
name="green", endpoint_name=online_endpoint_name, lines=50
)
Después de las pruebas, puede establecer el tráfico reflejado en cero para deshabilitar la creación de reflejo:
endpoint.mirror_traffic = {"green": 0}
ml_client.begin_create_or_update(endpoint).result()
Para reflejar el 10 % del tráfico y enviarlo a la implementación green, siga estos pasos:
En la página del punto de conexión, vaya a la pestaña Detalles y seleccione Actualizar tráfico.
Active el botón de alternancia Habilitar tráfico reflejado.
En la lista Nombre de implementación , seleccione verde.
En Asignación de tráfico %, mantenga el valor predeterminado del 10 %.
Selecciona Actualización.
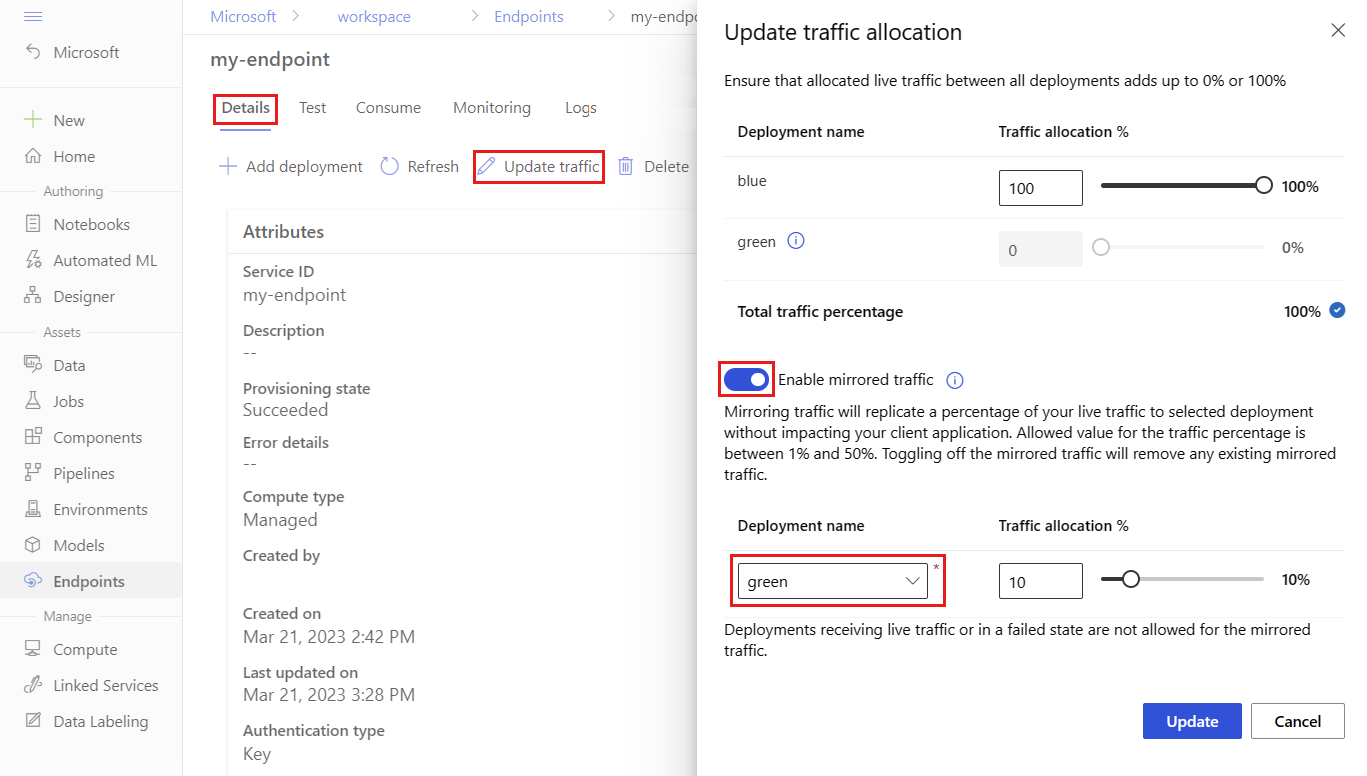
La página de detalles del punto de conexión muestra ahora una asignación de tráfico reflejada del 10 por ciento a la implementación green.

Para probar el tráfico reflejado, consulte las pestañas de la CLI de Azure o Python para invocar el punto de conexión varias veces. Confirme que el porcentaje especificado de tráfico se envía a la implementación green comprobando los registros de la implementación. Para acceder a los registros de implementación en la página del punto de conexión, vaya a la pestaña Registros .
También puede usar métricas y registros para supervisar el rendimiento del tráfico reflejado. Para obtener más información, consulte Supervisión de los puntos de conexión en línea.
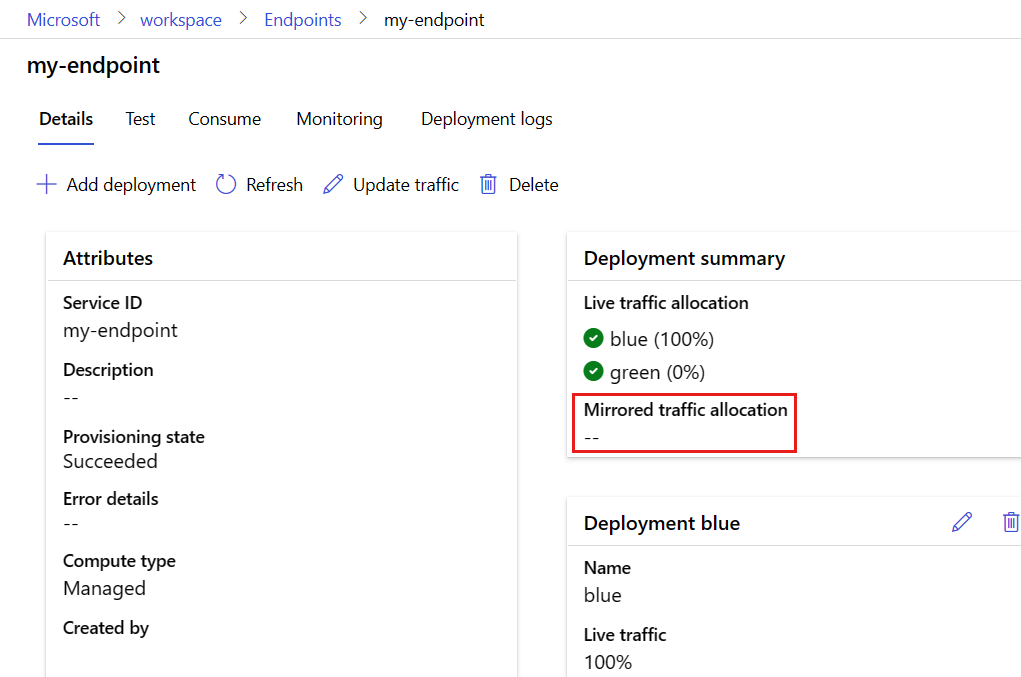
Después de realizar las pruebas, puede deshabilitar la creación de reflejo siguiendo estos pasos:
En la página del punto de conexión, vaya a la pestaña Detalles y seleccione Actualizar tráfico.
Desactive el interruptor Habilitar tráfico reflejado.
Selecciona Actualización.
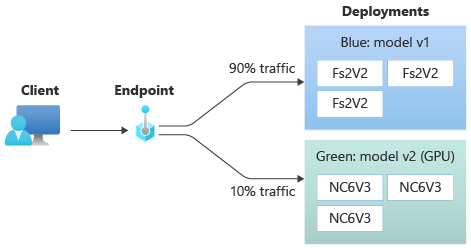
Asignación de un pequeño porcentaje de tráfico en directo a la nueva implementación
Después de probar la green implementación, asigne un pequeño porcentaje de tráfico a ella:
az ml online-endpoint update --name $ENDPOINT_NAME --traffic "blue=90 green=10"
endpoint.traffic = {"blue": 90, "green": 10}
ml_client.begin_create_or_update(endpoint).result()
En la página del punto de conexión, vaya a la pestaña Detalles y seleccione Actualizar tráfico.
Ajuste el tráfico de implementación asignando el 10 % a la implementación green y el 90 % a la implementación blue.
Selecciona Actualización.
Sugerencia
El porcentaje total de tráfico debe ser del 0 por ciento, para deshabilitar el tráfico o el 100 por ciento, para habilitar el tráfico.
La implementación green recibe ahora el 10 % del tráfico activo. Los clientes reciben predicciones de las implementaciones blue y green.
Enviar todo el tráfico a la nueva implementación
Cuando esté satisfecho con la implementación green, cambie todo el tráfico a ella.
az ml online-endpoint update --name $ENDPOINT_NAME --traffic "blue=0 green=100"
endpoint.traffic = {"blue": 0, "green": 100}
ml_client.begin_create_or_update(endpoint).result()
En la página del punto de conexión, vaya a la pestaña Detalles y seleccione Actualizar tráfico.
Ajuste el tráfico de implementación asignando el 100 % a la implementación green y el 0 % a la implementación blue.
Selecciona Actualización.
Eliminación de la implementación anterior
Siga estos pasos para eliminar una implementación individual de un punto de conexión en línea administrado. La eliminación de una implementación individual no afecta a las demás implementaciones en el punto de conexión en línea administrado:
az ml online-deployment delete --name blue --endpoint $ENDPOINT_NAME --yes --no-wait
ml_client.online_deployments.begin_delete(
name="blue", endpoint_name=online_endpoint_name
).wait()
Nota
No se puede eliminar una implementación que tenga tráfico activo asignado. Antes de eliminar la implementación, debe establecer la asignación de tráfico de la implementación en un 0 %.
En la página del punto de conexión, vaya a la pestaña Detalles y, a continuación, vaya a la blue tarjeta de implementación.
Junto al nombre de la implementación, seleccione el icono eliminar.
Eliminación del punto de conexión y la implementación
Si no va a usar el punto de conexión ni la implementación, debe eliminarlos. Al eliminar un punto de conexión, también se eliminan todas sus implementaciones subyacentes.
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)
Vaya a Azure Machine Learning Studio.
Seleccione Puntos de conexión.
Seleccione un punto de conexión en la lista.
Seleccione Eliminar.
Como alternativa, puede eliminar un punto de conexión en línea administrado directamente en la página del punto de conexión; para ello, vaya a las pestañas Detalles y seleccione el icono de eliminación.
Contenido relacionado












