Entrenamiento de modelos de TensorFlow a gran escala con Azure Machine Learning
SE APLICA A:  SDK de Python azure-ai-ml v2 (actual)
SDK de Python azure-ai-ml v2 (actual)
En este artículo, aprenderá a ejecutar los scripts de entrenamiento de TensorFlow a gran escala con el SDK de Python de Azure Machine Learning v2.
El código de ejemplo de este artículo entrena un modelo de TensorFlow para clasificar dígitos manuscritos mediante una red neuronal profunda (DNN), registrar el modelo e implementarlo en un punto de conexión en línea.
Tanto si va a desarrollar un modelo de TensorFlow de aprendizaje profundo desde el principio como si va a incorporar un modelo existente a la nube, puede usar Azure Machine Learning para escalar horizontalmente trabajos de entrenamiento de código abierto mediante recursos de proceso en la nube elástica. Puede compilar, implementar y supervisar modelos de nivel de producción, así como crear versiones de dichos mismos, mediante Azure Machine Learning.
Requisitos previos
Para beneficiarse de este artículo, debe realizar lo siguiente:
- Acceder a una suscripción de Azure. Si todavía no la tiene, cree una cuenta gratuita.
- Ejecute el código de este artículo mediante una instancia de proceso de Azure Machine Learning o en su propio Jupyter Notebook.
- Instancia de proceso de Azure Machine Learning (no requiere descargas ni instalación)
- Complete el tutorial Crear recursos para empezar para crear un servidor de cuadernos dedicado en el que se habrán cargado previamente el SDK y el repositorio de ejemplos.
- Para encontrar un cuaderno completado y expandido, en la carpeta de aprendizaje profundo de ejemplos del servidor de cuadernos, vaya a este directorio: v2 > sdk > python > jobs > single-step > tensorflow > train-hyperparameter-tune-deploy-with-tensorflow.
- Su servidor de Jupyter Notebook
- Instancia de proceso de Azure Machine Learning (no requiere descargas ni instalación)
- Descargue los archivos siguientes:
- script de entrenamiento tf_mnist.py
- scrip de puntuación score.py
- archivo de solicitud de ejemplo sample-request.json
También puede encontrar una versión de Jupyter Notebook completada de esta guía en la página de ejemplos de GitHub.
Para poder ejecutar el código de este artículo a fin de crear un clúster de GPU, deberá solicitar un aumento de cuota para el área de trabajo.
Configuración del trabajo
En esta sección se configura el trabajo para el entrenamiento mediante la carga de los paquetes de Python necesarios, la conexión a un área de trabajo, la creación de un recurso de proceso para ejecutar un trabajo de comando y la creación de un entorno para ejecutar el trabajo.
Conexión a un área de trabajo
En primer lugar, debe conectarse al área de trabajo de Azure Machine Learning. El área de trabajo de Azure Machine Learning es el recurso de nivel superior para el servicio. Proporciona un lugar centralizado para trabajar con todos los artefactos que cree al usar Azure Machine Learning.
Usaremos DefaultAzureCredential para obtener acceso al área de trabajo. Esta credencial es capaz de manejar la mayoría de los escenarios de autenticación del SDK de Azure.
Si DefaultAzureCredential no funciona, consulte azure-identity reference documentation o Set up authentication para obtener más credenciales disponibles.
# Handle to the workspace
from azure.ai.ml import MLClient
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()Si prefiere usar un explorador para iniciar sesión y autenticarse, debe quitar la marca de comentario del código siguiente y usarlo en su lugar.
# Handle to the workspace
# from azure.ai.ml import MLClient
# Authentication package
# from azure.identity import InteractiveBrowserCredential
# credential = InteractiveBrowserCredential()
A continuación, obtenga un identificador para el área de trabajo proporcionando el identificador de suscripción, el nombre del grupo de recursos y el nombre del área de trabajo. Para buscar estos parámetros:
- Busque el nombre del área de trabajo en la esquina superior derecha de la barra de herramientas de Estudio de Azure Machine Learning.
- Seleccione el nombre del área de trabajo para mostrar el identificador de suscripción y el grupo de recursos.
- Copie los valores del grupo de recursos y el identificador de suscripción en el código.
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)El resultado de la ejecución de este script es un manipulador del área de trabajo que se utiliza para administrar otros recursos y trabajos.
Nota:
- La creación de
MLClientno conectará al cliente con el área de trabajo. La inicialización del cliente es lenta y esperará a la primera vez que necesite hacer una llamada. En este artículo, esto ocurrirá durante la creación del proceso.
Creación de un recurso de proceso
Azure Machine Learning necesita un recurso de proceso para ejecutar un trabajo. Este recurso puede ser máquinas de un solo nodo o de varios nodos con sistema operativo Linux o Windows, o un tejido de proceso específico, como Spark.
En el siguiente script de ejemplo, aprovisionamos un Linux compute cluster. Puede ver la página Azure Machine Learning pricing para ver la lista completa de tamaños y precios de máquina virtual. Dado que necesitamos un clúster de GPU para este ejemplo, vamos a elegir un modelo STANDARD_NC6 y crear un proceso de Azure Machine Learning.
from azure.ai.ml.entities import AmlCompute
gpu_compute_target = "gpu-cluster"
try:
# let's see if the compute target already exists
gpu_cluster = ml_client.compute.get(gpu_compute_target)
print(
f"You already have a cluster named {gpu_compute_target}, we'll reuse it as is."
)
except Exception:
print("Creating a new gpu compute target...")
# Let's create the Azure ML compute object with the intended parameters
gpu_cluster = AmlCompute(
# Name assigned to the compute cluster
name="gpu-cluster",
# Azure ML Compute is the on-demand VM service
type="amlcompute",
# VM Family
size="STANDARD_NC6s_v3",
# Minimum running nodes when there is no job running
min_instances=0,
# Nodes in cluster
max_instances=4,
# How many seconds will the node running after the job termination
idle_time_before_scale_down=180,
# Dedicated or LowPriority. The latter is cheaper but there is a chance of job termination
tier="Dedicated",
)
# Now, we pass the object to MLClient's create_or_update method
gpu_cluster = ml_client.begin_create_or_update(gpu_cluster).result()
print(
f"AMLCompute with name {gpu_cluster.name} is created, the compute size is {gpu_cluster.size}"
)Creación de un entorno de trabajo
Para ejecutar un trabajo de Azure Machine Learning, necesita un entorno. Un entorno de Azure Machine Learning encapsula las dependencias (como el tiempo de ejecución de software y las bibliotecas) necesarias para ejecutar el script de entrenamiento de aprendizaje automático en el recurso de proceso. Este entorno es similar a un entorno de Python en la máquina local.
Azure Machine Learning permite usar un entorno mantenido (o listo) (útil para escenarios comunes de entrenamiento e inferencia) o crear un entorno personalizado mediante una imagen de Docker o una configuración de Conda.
En este artículo, reutilizará el entorno de Azure Machine Learning mantenido AzureML-tensorflow-2.7-ubuntu20.04-py38-cuda11-gpu. Use la versión más reciente de este entorno mediante la directiva @latest.
curated_env_name = "AzureML-tensorflow-2.12-cuda11@latest"Configuración y envío del trabajo de entrenamiento
En esta sección, comenzaremos introduciendo los datos para el entrenamiento. A continuación, explicaremos cómo ejecutar un trabajo de entrenamiento mediante un script de entrenamiento que hemos proporcionado. Aprenderá a compilar el trabajo de entrenamiento mediante la configuración del comando para ejecutar el script de entrenamiento. Después, enviará el trabajo de entrenamiento para que se ejecute en Azure Machine Learning.
Obtención de los datos de entrenamiento
Usará datos de la base de datos Modified National Institute of Standards and Technology (MNIST) de dígitos manuscritos. Estos datos proceden del sitio web de Yan LeCun y se almacenan en una cuenta de almacenamiento de Azure.
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"Para obtener más información sobre el conjunto de datos MNIST, visite el sitio web de Yan LeCun.
Preparar el script de entrenamiento
En este artículo, hemos proporcionado el script de entrenamiento tf_mnist.py. En la práctica, debería poder usar cualquier script de entrenamiento personalizado tal cual y ejecutarlo con Azure Machine Learning sin tener que modificar el código.
El script de entrenamiento proporcionado realiza lo siguiente:
- controla el preprocesamiento de datos, dividiendo los datos en datos de prueba y entrenamiento;
- entrena un modelo, utilizando los datos; y
- devuelve el modelo de salida.
Durante la ejecución de la canalización, usará MLFlow para registrar los parámetros y las métricas. Para obtener información sobre cómo habilitar el seguimiento de MLFlow, consulte Seguimiento de experimentos y modelos de ML con MLflow.
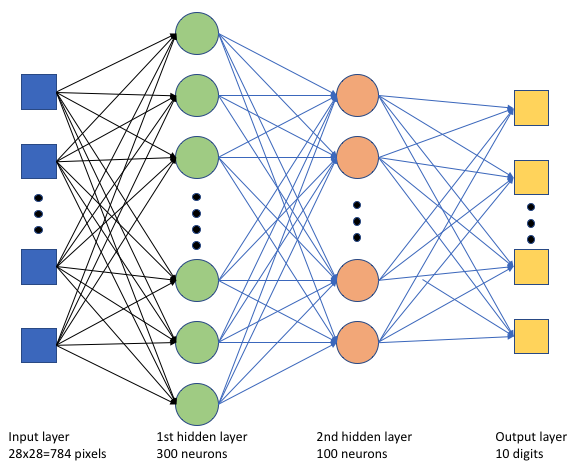
En el script de entrenamiento tf_mnist.py, se crea una red neuronal profunda (DNN) sencilla. Este DNN tiene:
- Capa de entrada con 28 * 28 = 784 neuronas. Cada neurona representa un píxel de imagen.
- Dos capas ocultas. La primera capa oculta tiene 300 neuronas y la segunda capa oculta tiene 100 neuronas.
- Una capa de salida con 10 neuronas. Cada neurona representa una etiqueta de destino de 0 a 9.
Compilación del trabajo de entrenamiento
Ahora que tiene todos los recursos necesarios para ejecutar el trabajo, es el momento de compilar mediante el SDK de Python v2 de Azure Machine Learning. En este ejemplo, estamos creando un command.
Un command de Azure Machine Learning es un recurso que especifica todos los detalles necesarios para ejecutar el código de entrenamiento en la nube. Estos detalles incluyen las entradas y salidas, el tipo de hardware que se va a usar, el software que se va a instalar y cómo ejecutar el código. command contiene información para ejecutar un único comando.
Configuración del comando
Usará el command de uso general para ejecutar el script de entrenamiento y realizar las tareas deseadas. Cree un objeto Command para especificar los detalles de configuración del trabajo de entrenamiento.
from azure.ai.ml import command
from azure.ai.ml import UserIdentityConfiguration
from azure.ai.ml import Input
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"
job = command(
inputs=dict(
data_folder=Input(type="uri_folder", path=web_path),
batch_size=64,
first_layer_neurons=256,
second_layer_neurons=128,
learning_rate=0.01,
),
compute=gpu_compute_target,
environment=curated_env_name,
code="./src/",
command="python tf_mnist.py --data-folder ${{inputs.data_folder}} --batch-size ${{inputs.batch_size}} --first-layer-neurons ${{inputs.first_layer_neurons}} --second-layer-neurons ${{inputs.second_layer_neurons}} --learning-rate ${{inputs.learning_rate}}",
experiment_name="tf-dnn-image-classify",
display_name="tensorflow-classify-mnist-digit-images-with-dnn",
)Las entradas de este comando incluyen la ubicación de datos, el tamaño del lote, el número de neuronas en la primera y la segunda capa y la velocidad de aprendizaje. Observe que hemos pasado la ruta de acceso web directamente como entrada.
Para los valores de parámetro:
- proporcione el clúster de proceso
gpu_compute_target = "gpu-cluster"que creó para ejecutar este comando; - proporcione el entorno mantenido
curated_env_nameque ha declarado anteriormente; - configure la propia acción de la línea de comandos; en este caso, el comando es
python tf_mnist.py. Puede acceder a las entradas y salidas en el comando a través de la notación${{ ... }}; y - configure algunos metadatos, como el nombre para mostrar y el nombre del experimento, donde un experimento es un contenedor para todas las iteraciones que se realizan en un proyecto determinado. Todos los trabajos enviados en el mismo nombre de experimento se enumerarán de manera correlativa en Estudio de Azure Machine Learning.
- proporcione el clúster de proceso
En este ejemplo, usará
UserIdentitypara ejecutar el comando. El uso de una identidad de usuario significa que el comando usará la identidad para ejecutar el trabajo y acceder a los datos desde el blob.
Enviar el archivo
Ahora es el momento de enviar el trabajo para que se ejecute en Azure Machine Learning. Esta vez usará create_or_update en ml_client.jobs.
ml_client.jobs.create_or_update(job)Una vez completado, el trabajo registrará un modelo en el área de trabajo (como resultado del entrenamiento) y generará un vínculo para ver el trabajo en Estudio de Azure Machine Learning.
Advertencia
Azure Machine Learning ejecuta scripts de entrenamiento mediante la copia de todo el directorio de origen. Si tiene información confidencial que no quiere cargar, use un archivo .ignore o no la incluya en el directorio de origen.
¿Qué ocurre durante la ejecución del trabajo?
Durante la ejecución del trabajo, este pasa por las fases siguientes:
Preparando: se crea una imagen de Docker según el entorno definido. La imagen se carga en el registro de contenedor del área de trabajo y se almacena en memoria caché para ejecuciones posteriores. Los registros también se transmiten al historial de trabajos y se pueden consultar para supervisar el progreso. Si se especifica un entorno mantenido, se usará la imagen almacenada en caché que respalda el entorno mantenido.
Escalado: el clúster intenta escalar verticalmente si requiere más nodos para ejecutar la ejecución de los que están disponibles actualmente.
En ejecución: todos los scripts de la carpeta de scripts src se cargan en el destino de proceso, se montan o copian los almacenes de datos y se ejecuta el script. Las salidas de stdout y la carpeta ./logs se transmiten al historial de trabajos y se pueden usar para supervisar el trabajo.
Ajuste de hiperparámetros del modelo
Ahora que ha visto cómo realizar una ejecución de entrenamiento de TensorFlow mediante el SDK, veamos si puede mejorar aún más la precisión del modelo. Puede ajustar y optimizar los hiperparámetros del modelo mediante las funcionalidades de sweep de Azure Machine Learning.
Para ajustar los hiperparámetros del modelo, defina el espacio de parámetros en el que se va a buscar durante el entrenamiento. Para ello, reemplace algunos de los parámetros (batch_size, first_layer_neurons, second_layer_neurons y learning_rate) pasados al trabajo de entrenamiento con entradas especiales del paquete azure.ml.sweep.
from azure.ai.ml.sweep import Choice, LogUniform
# we will reuse the command_job created before. we call it as a function so that we can apply inputs
# we do not apply the 'iris_csv' input again -- we will just use what was already defined earlier
job_for_sweep = job(
batch_size=Choice(values=[32, 64, 128]),
first_layer_neurons=Choice(values=[16, 64, 128, 256, 512]),
second_layer_neurons=Choice(values=[16, 64, 256, 512]),
learning_rate=LogUniform(min_value=-6, max_value=-1),
)Después, configurará el barrido en el trabajo de comando con algunos parámetros específicos del barrido, como la métrica principal para inspeccionar y el algoritmo de muestreo que se va a usar.
En el código siguiente se usa el muestreo aleatorio para probar diferentes conjuntos de configuración de hiperparámetros en un intento de maximizar la métrica principal, validation_acc.
También definimos una directiva de terminación anticipada: BanditPolicy. Esta directiva funciona comprobando el trabajo cada dos iteraciones. Si la métrica principal (validation_acc) se encuentra fuera del intervalo de diez por ciento superior, Azure Machine Learning finalizará el trabajo. Esto evita que el modelo continúe explorando hiperparámetros que no prometen ayudar a alcanzar la métrica de destino.
from azure.ai.ml.sweep import BanditPolicy
sweep_job = job_for_sweep.sweep(
compute=gpu_compute_target,
sampling_algorithm="random",
primary_metric="validation_acc",
goal="Maximize",
max_total_trials=8,
max_concurrent_trials=4,
early_termination_policy=BanditPolicy(slack_factor=0.1, evaluation_interval=2),
)Ahora, puede enviar este trabajo como antes. Esta vez, ejecutará un trabajo de barrido que barrerá el trabajo de entrenamiento.
returned_sweep_job = ml_client.create_or_update(sweep_job)
# stream the output and wait until the job is finished
ml_client.jobs.stream(returned_sweep_job.name)
# refresh the latest status of the job after streaming
returned_sweep_job = ml_client.jobs.get(name=returned_sweep_job.name)Puede supervisar el trabajo mediante el vínculo de la interfaz de usuario de Studio que se presenta durante la ejecución del trabajo.
Búsqueda y registro del mejor modelo
Una vez completadas todas las ejecuciones, puede encontrar la ejecución que generó el modelo con la mayor precisión.
from azure.ai.ml.entities import Model
if returned_sweep_job.status == "Completed":
# First let us get the run which gave us the best result
best_run = returned_sweep_job.properties["best_child_run_id"]
# lets get the model from this run
model = Model(
# the script stores the model as "model"
path="azureml://jobs/{}/outputs/artifacts/paths/outputs/model/".format(
best_run
),
name="run-model-example",
description="Model created from run.",
type="custom_model",
)
else:
print(
"Sweep job status: {}. Please wait until it completes".format(
returned_sweep_job.status
)
)A continuación, puede registrar este modelo.
registered_model = ml_client.models.create_or_update(model=model)Implementación del modelo como un punto de conexión en línea
Después de registrar el modelo, puede implementarlo como punto de conexión en línea, es decir, como un servicio web en la nube de Azure.
Para implementar un Machine Learning Service, normalmente necesita lo siguiente:
- Los recursos del modelo que desea implementar. Estos recursos incluyen el archivo y los metadatos del modelo que ya registró en el trabajo de entrenamiento.
- Algún código que se ejecutará como servicio. El código ejecuta el modelo en una solicitud de entrada determinada (un script de entrada). El script de entrada recibe los datos enviados a un servicio web implementado y los pasa al modelo. Una vez que el modelo procesa los datos, el script devuelve la respuesta del modelo al cliente. El script es específico para el modelo, y debe entender los datos que el modelo espera y devuelve. Cuando se usa un modelo de MLFlow, Azure Machine Learning crea automáticamente este script.
Para más información sobre la implementación, consulte Implementación y puntuación de un modelo de Machine Learning con un punto de conexión en línea administrado mediante el SDK de Python v2.
Creación de un punto de conexión en línea
Como primer paso para implementar el modelo, debe crear el punto de conexión en línea. El nombre del punto de conexión debe ser único en toda la región de Azure. En este artículo, creará un nombre único mediante un identificador único universal (UUID).
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "tff-dnn-endpoint-" + str(uuid.uuid4())[:8]from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="Classify handwritten digits using a deep neural network (DNN) using TensorFlow",
auth_mode="key",
)
endpoint = ml_client.begin_create_or_update(endpoint).result()
print(f"Endpint {endpoint.name} provisioning state: {endpoint.provisioning_state}")Una vez creado el punto de conexión, puede recuperarlo de la siguiente manera:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)Implementación del modelo en el punto de conexión
Después de crear el punto de conexión, puede implementar el modelo con el script de entrada. Un punto de conexión puede tener varias implementaciones. Mediante reglas, el punto de conexión puede dirigir el tráfico a estas implementaciones.
En el siguiente código, creará una implementación única que controla el 100 % del tráfico entrante. Usamos un nombre de color arbitrario (tff-blue) para la implementación. También puede usar cualquier otro nombre, como tff-green o tff-red para la implementación. El código para implementar el modelo en el punto de conexión realiza lo siguiente:
- implementa la mejor versión del modelo que registró anteriormente;
- puntúa el modelo mediante el archivo
score.py; y - usa el mismo entorno mantenido (que ha declarado anteriormente) para realizar la inferencia.
model = registered_model
from azure.ai.ml.entities import CodeConfiguration
# create an online deployment.
blue_deployment = ManagedOnlineDeployment(
name="tff-blue",
endpoint_name=online_endpoint_name,
model=model,
code_configuration=CodeConfiguration(code="./src", scoring_script="score.py"),
environment=curated_env_name,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()Nota
Esta implementación tardará un poco en finalizar.
Prueba de la implementación con una solicitud de ejemplo
Después de implementar el modelo en el punto de conexión, puede predecir la salida del modelo implementado mediante el método invoke en el punto de conexión. Para ejecutar la inferencia, utilice el archivo de solicitud de ejemplo sample-request.json de la carpeta de solicitud.
# # predict using the deployed model
result = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./request/sample-request.json",
deployment_name="tff-blue",
)A continuación, podrá imprimir las predicciones devueltas y representarlas junto con las imágenes de entrada. Utilice un color de fuente rojo y la imagen invertida (blanco sobre negro) para resaltar los ejemplos clasificados incorrectamente.
# compare actual value vs. the predicted values:
import matplotlib.pyplot as plt
i = 0
plt.figure(figsize=(20, 1))
for s in sample_indices:
plt.subplot(1, n, i + 1)
plt.axhline("")
plt.axvline("")
# use different color for misclassified sample
font_color = "red" if y_test[s] != result[i] else "black"
clr_map = plt.cm.gray if y_test[s] != result[i] else plt.cm.Greys
plt.text(x=10, y=-10, s=result[i], fontsize=18, color=font_color)
plt.imshow(X_test[s].reshape(28, 28), cmap=clr_map)
i = i + 1
plt.show()Nota
Como la precisión del modelo es alta, es posible que deba ejecutar la celda varias veces para que pueda ver un ejemplo de clasificación incorrecta.
Limpieza de recursos
Si no va a usar el punto de conexión, elimínelo para dejar de usar el recurso. Asegúrese de que ninguna otra implementación use el punto de conexión antes de eliminarlo.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)Nota
Esta limpieza tardará un poco en finalizar.
Pasos siguientes
En este artículo, ha entrenado y registrado un modelo de TensorFlow. También ha implementado el modelo en un punto de conexión en línea. Consulte estos otros artículos para más información sobre Azure Machine Learning.