Ejecución de puntos de conexión por lotes desde Azure Data Factory
SE APLICA A: Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Los macrodatos requieren un servicio que pueda orquestar y operacionalizar los procesos para convertir estos enormes almacenes de datos sin procesar en información empresarial en función de la cual se puedan emprender acciones. Azure Data Factory es un servicio en la nube administrado creado para estos complejos proyectos híbridos de extracción, transformación y carga (ETL), extracción, carga y transformación (ELT) e integración de datos.
Azure Data Factory permite crear canalizaciones que pueden organizar múltiples transformaciones de datos y administrarlas como una sola unidad. Los puntos de conexión por lotes son un excelente candidato para llegar a ser uno de los pasos en este flujo de trabajo de procesamiento. En este ejemplo, aprenderá a usar puntos de conexión por lotes en actividades de Azure Data Factory mediante la actividad de invocación web y la API de REST.
Requisitos previos
En este ejemplo se supone que usted tiene un modelo implementado correctamente como punto de conexión por lotes. En particular, estamos usando el clasificador de enfermedades cardíacas creado en el tutorial Uso de modelos de MLflow en implementaciones por lotes.
Un recurso de Azure Data Factory creado y configurado. Si aún no ha creado la factoría de datos, siga los pasos descritos en Inicio rápido: Creación de una factoría de datos mediante Azure Portal y Azure Data Factory Studio para crear una.
Después de crearla, vaya a la factoría de datos en Azure Portal:
Seleccione Open (Abrir) en el icono Open Azure Data Factory Studio (Abrir Azure Data Factory Studio) para iniciar la aplicación de integración de datos en una pestaña independiente.
Autenticación contra puntos de conexión por lotes
Azure Data Factory puede invocar las API de REST de los puntos de conexión por lotes mediante la actividad de invocación web. Los puntos de conexión por lotes admiten Microsoft Entra ID para la autorización y, por ello, la solicitud realizada a las API requiere un control de autenticación adecuado.
Puede usar una entidad de servicio o una identidad administrada para autenticarse en puntos de conexión por lotes. Recomendamos usar una identidad administrada, ya que simplifica el uso de secretos.
Para comunicarse con los Puntos de Conexión de por Lotes, puede usar la identidad administrada de Azure Data Factory. En este caso, solo debe asegurarse de que su recurso de Azure Data Factory se implementó con una identidad administrada.
Si no tiene un recurso de Azure Data Factory o ya se implementó sin una identidad administrada, siga estos pasos para crearlo: Identidad administrada para Azure Data Factory.
Advertencia
Tenga en cuenta que en Azure Data Factory no es posible cambiar la identidad de recurso una vez implementado. Una vez creado el recurso, si necesita cambiar su identidad deberá volver a crearlo.
Una vez implementado, conceda acceso a la identidad administrada del recurso que creó en su área de trabajo de Azure Machine Learning, como se explica en Concesión de acceso. En este ejemplo, la entidad de servicio requerirá:
- Permiso en el área de trabajo para leer las implementaciones por lotes y realizar acciones sobre ellas.
- Permisos para leer y escribir en almacenes de datos.
- Permisos para leer en cualquier ubicación en la nube (cuenta de almacenamiento) que se indique como entrada de datos.
Acerca de la canalización
Vamos a crear una canalización en Azure Data Factory que pueda invocar un punto de conexión por lotes determinado a través de algunos datos. La canalización se comunicará con los puntos de conexión por lotes de Azure Machine Learning mediante REST. Para obtener más información sobre cómo usar la API de REST de puntos de conexión por lotes, lea Crear trabajos y datos de entrada para puntos de conexión por lotes.
La canalización tendrá el siguiente aspecto:
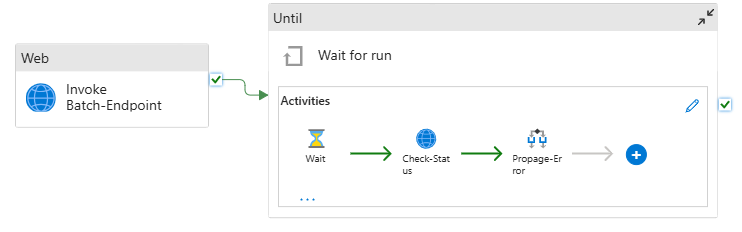
Se compone de las actividades siguientes:
- Ejecutar Punto de Conexión por Lotes: es una Actividad Web que usa el identificador uniforme de recursos del punto de conexión por lotes para invocarla. Pasa el identificador uniforme de recursos de datos de entrada donde se encuentran los datos y el archivo de salida esperado.
- Esperar trabajo: es una actividad de bucle que comprueba el estado del trabajo creado y espera su finalización, ya sea como Completado o Con errores. Esta actividad, a su vez, usa las actividades siguientes:
- Comprobar estado: es una actividad web que consulta el estado del recurso de trabajo que se devolvió como respuesta de la actividad Ejecutar punto de conexión de Batch.
- Wait: es una actividad de espera que controla la frecuencia de sondeo del estado del trabajo. Establecemos un valor predeterminado de 120 (2 minutos).
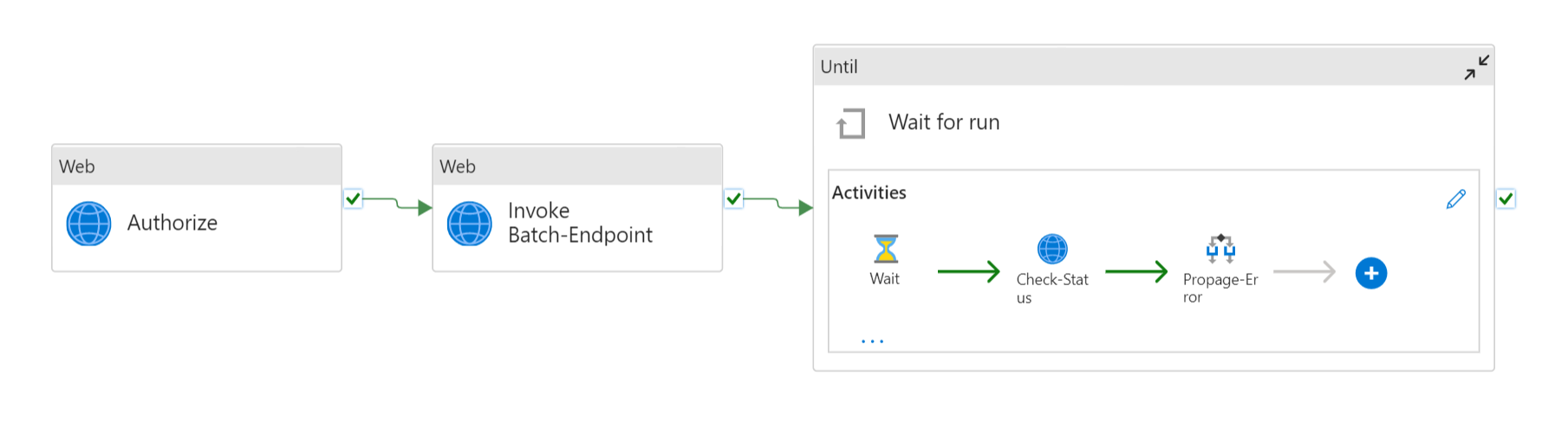
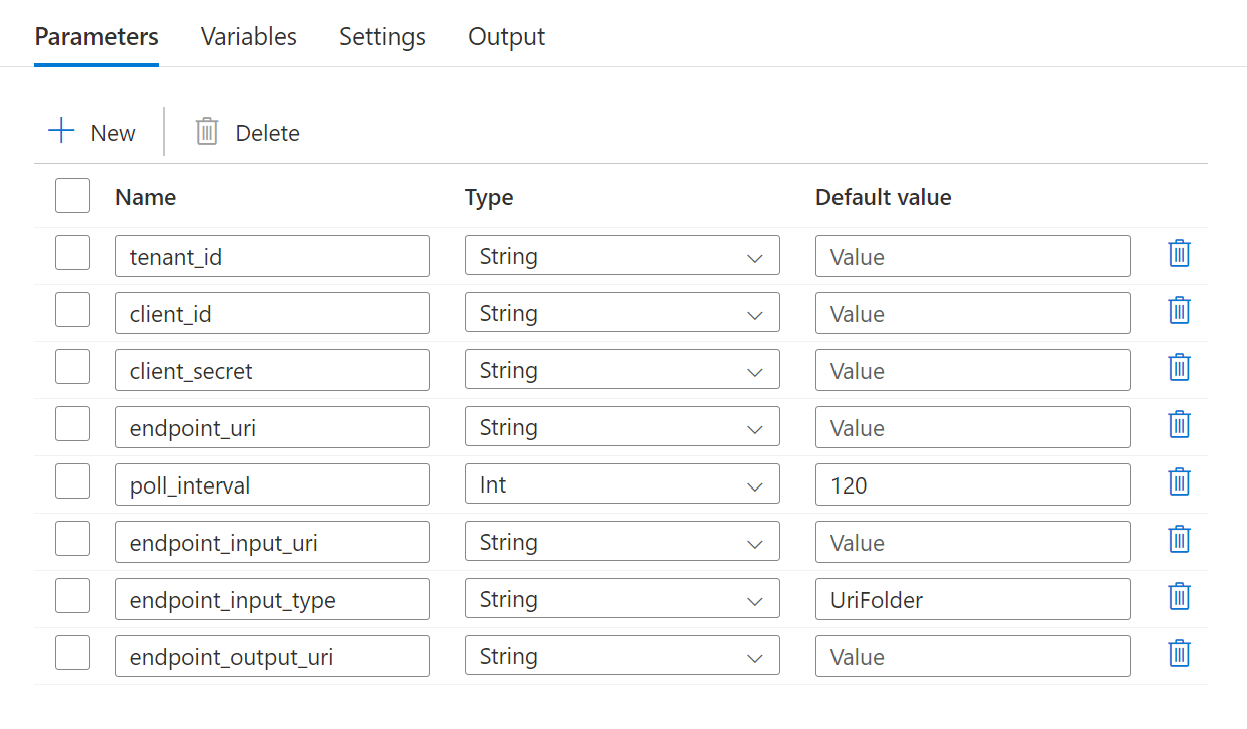
La canalización requiere que se configuren los parámetros siguientes:
| Parámetro | Descripción | Valor de ejemplo |
|---|---|---|
endpoint_uri |
El identificador uniforme de recursos de puntuación del punto de conexión | https://<endpoint_name>.<region>.inference.ml.azure.com/jobs |
poll_interval |
El número de segundos que deben transcurrir antes de comprobar el estado de trabajo para finalizar. Su valor predeterminado es 120. |
120 |
endpoint_input_uri |
Los datos de entrada del punto de conexión. Se admiten varios tipos de entrada de datos. Asegúrese de que la identidad de administración que usa para ejecutar el trabajo tiene acceso a la ubicación subyacente. Alternativa, si usa almacenes de datos, asegúrese de que las credenciales se indican allí. | azureml://datastores/.../paths/.../data/ |
endpoint_input_type |
Tipo de datos de entrada que se proporcionan. Actualmente, los puntos de conexión por lotes admiten carpetas (UriFolder) y Archivo (UriFile). Tiene como valor predeterminado UriFolder. |
UriFolder |
endpoint_output_uri |
El archivo de datos de salida del punto de conexión. Debe ser una ruta de acceso a un archivo de salida de un Almacén de Datos asociado al área de trabajo de Machine Learning. No se admite ningún otro tipo de identificador uniforme de recursos. Puede usar el almacén de datos predeterminado de Azure Machine Learning, denominado workspaceblobstore. |
azureml://datastores/workspaceblobstore/paths/batch/predictions.csv |
Advertencia
Recuerde que endpoint_output_uri debería ser la ruta de acceso a un archivo que aún no existe. De lo contrario, en el trabajo se producirá el error la ruta de acceso ya existe.
Pasos
Para crear esta canalización en la instancia de Azure Data Factory existente e invocar puntos de conexión por lotes, siga estos pasos:
Asegúrese de que el proceso en el que se ejecuta el punto de conexión por lotes tiene permisos para montar los datos que Azure Data Factory proporciona como entrada. Tenga en cuenta que la identidad que invoca el punto de conexión (en este caso Azure Data Factory) sigue concediendo acceso. Pero el proceso en el que se ejecuta el punto de conexión por lotes debe tener permiso para montar la cuenta de almacenamiento que proporcione Azure Data Factory. Consulte Acceso a los servicios de almacenamiento para más información.
Abra Azure Data Factory Studio y, en Recursos de fábrica, haga clic en el signo más.
SeleccioneCanalización>Importar desde la plantilla de canalización
Se le pedirá que seleccione un
ziparchivo. Use la plantilla siguiente si usa identidades administradas o la siguiente si usa una entidad de servicio.En el portal aparecerá una vista previa de la canalización. Haga clic en Use this template (Usar esta plantilla).
La canalización se creará para usted con el nombre Run-BatchEndpoint.
Configure los parámetros de la implementación por lotes que esté utilizando:
Advertencia
Asegúrese de que el punto de conexión por lotes tiene configurada una implementación predeterminada antes de enviarle un trabajo. La canalización creada invocará el punto de conexión y, por tanto, se debe crear y configurar una implementación predeterminada.
Sugerencia
Para mejorar la reutilización, use la canalización creada como plantilla y llámela desde otras canalizaciones de Azure Data Factory aprovechando Ejecutar actividad de canalización. En ese caso, no configure los parámetros de la canalización interna, es preferible que use como parámetros de la canalización externa, como se muestra en la imagen siguiente:
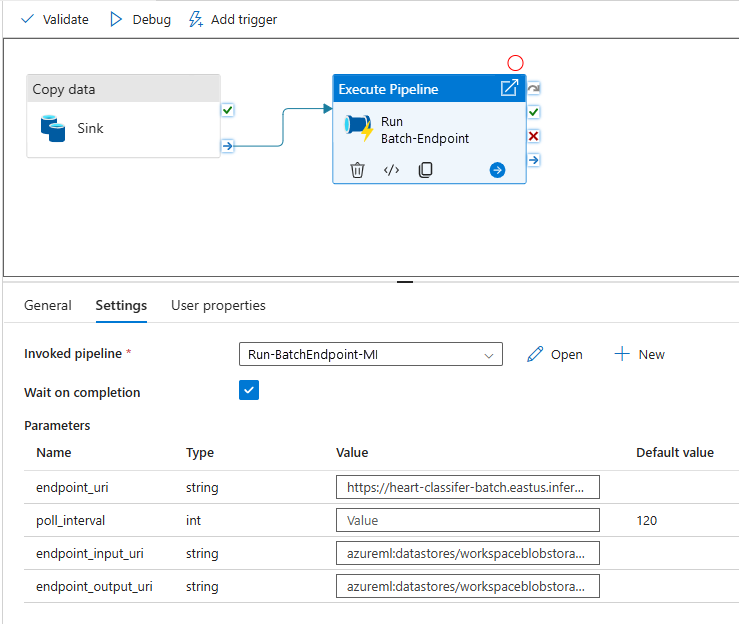
- Su canalización está lista para usarse.
Limitaciones
Tenga en cuenta las siguientes limitaciones al llamar a las implementaciones por lotes de Azure Machine Learning:
Entradas de datos
- Solo se admiten como entradas almacenes de datos de Azure Machine Learning o cuentas de Azure Storage (Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2). Si sus datos de entrada están en otro origen, use la actividad de copia de Azure Data Factory antes de la ejecución del trabajo por lotes para recibir los datos en un almacén compatible.
- Los trabajos de punto de conexión de Batch no exploran las carpetas anidadas y, por tanto, no pueden trabajar con estructuras de carpetas anidadas. Si sus datos se distribuyen en varias carpetas, observe que tendrá que acoplar la estructura.
- Asegúrese de que su script de puntuación que proporcionó en la implementación pueda controlar los datos tal y como se espera que se inserte en el trabajo. Si el modelo es MLflow, lea la limitación en cuanto al tipo de archivo admitido por el momento en Uso de modelos de MLflow en implementaciones por lotes.
Salidas de datos
- Por el momento, solo se admiten almacenes de datos registrados de Azure Machine Learning. Se recomienda registrar la cuenta de almacenamiento que Azure Data Factory usa como almacén de datos en Azure Machine Learning. De este modo, podrá reescribir en la misma cuenta de almacenamiento desde la que está leyendo.
- Solo se admiten para salidas cuentas de Azure Blob Storage. Por ejemplo, Azure Data Lake Storage Gen2 no se admite como salida en trabajos de implementación por lotes. Si necesita enviar los datos a otra ubicación o receptor, use la actividad de copia de Azure Data Factory después de la ejecución del trabajo por lotes.
Pasos siguientes
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de