Seguimiento de experimentos de aprendizaje automático de Azure Synapse Analytics con MLflow y Azure Machine Learning
En este artículo, aprenderá a habilitar MLflow para conectarse a Azure Machine Learning mientras trabaja en un área de trabajo de Azure Synapse Analytics. Puede aprovechar esta configuración para el seguimiento, la administración de modelos y la implementación de modelos.
MLflow es una biblioteca de código abierto para administrar el ciclo de vida de los experimentos de aprendizaje automático. MLFlow Tracking es un componente de MLflow que registra las métricas de ejecución de entrenamiento y los artefactos de modelo y realiza un seguimiento de ellos. Obtenga más información sobre MLflow.
Si tiene un proyecto de MLflow para entrenar con Azure Machine Learning, consulte Entrenamiento de modelos de Machine Learning con MLflow y Azure Machine Learning (versión preliminar).
Requisitos previos
- Un área de trabajo y un clúster de Azure Synapse Analytics.
- Un área de trabajo de Azure Machine Learning.
Instalar bibliotecas
Para instalar bibliotecas en el clúster dedicado de Azure Synapse Analytics:
Cree un archivo
requirements.txtcon los paquetes necesarios para los experimentos, pero asegúrese de que también incluya los paquetes siguientes:requirements.txt
mlflow azureml-mlflow azure-ai-mlVaya al portal del área de trabajo de Azure Analytics.
Vaya a la pestaña Administrar y seleccione Grupos de Apache Spark.
Haga clic en los tres puntos situados junto al nombre del clúster y seleccione Paquetes.
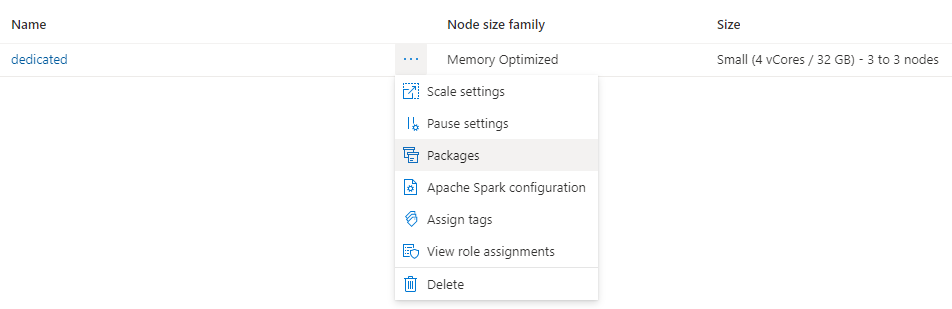
En la sección Archivos de requisitos, haga clic en Cargar.
Cargue el archivo
requirements.txt.Espere a que se reinicie el clúster.
Seguimiento de experimentos con MLflow
Azure Synapse Analytics puede configurarse para realizar un seguimiento de los experimentos con MLflow en el área de trabajo de Azure Machine Learning. Azure Machine Learning proporciona un repositorio centralizado para administrar el ciclo de vida completo de los experimentos, modelos e implementaciones. También tiene la ventaja de habilitar una forma más sencilla para la implementación con las opciones de implementación de Azure Machine Learning.
Configuración de los cuadernos para usar MLflow conectado a Azure Machine Learning
Para usar Azure Machine Learning como repositorio centralizado de los experimentos, puede aprovechar MLflow. En cada cuaderno en el que esté trabajando, debe configurar el URI de seguimiento para que apunte al área de trabajo que va a usar. En el ejemplo siguiente se muestra cómo se puede hacer:
Configurar URI de seguimiento
Obtenga el URI de seguimiento del área de trabajo:
SE APLICA A:
 Extensión de ML de la CLI de Azure v2 (actual)
Extensión de ML de la CLI de Azure v2 (actual)Inicie sesión y configure el área de trabajo:
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>Puede obtener el URI de seguimiento mediante el comando
az ml workspace:az ml workspace show --query mlflow_tracking_uri
Configuración del URI de seguimiento:
A continuación, el método
set_tracking_uri()apunta el URI de seguimiento de MLflow a ese URI.import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)Sugerencia
Al trabajar en entornos compartidos, como un clúster de Azure Databricks, un clúster de Azure Synapse Analytics o similar, resulta útil establecer la variable
MLFLOW_TRACKING_URIde entorno en el nivel de clúster para configurar automáticamente el URI de seguimiento de MLflow para que apunte a Azure Machine Learning para todas las sesiones que se ejecutan en el clúster en lugar de hacerlo por sesión.
Configurar la autenticación
Una vez configurado el seguimiento, también deberá configurar cómo se debe realizar la autenticación en el área de trabajo asociada. De forma predeterminada, el complemento de Azure Machine Learning para MLflow realizará la autenticación interactiva abriendo el explorador predeterminado para solicitar las credenciales. Consulte Configuración de MLflow para Azure Machine Learning: Configuración de la autenticación para otras formas de configurar la autenticación para MLflow en áreas de trabajo de Azure Machine Learning.
En el caso de los trabajos interactivos en los que hay un usuario conectado a la sesión, puede confiar en la autenticación interactiva y, por tanto, no es necesario realizar ninguna otra acción.
Advertencia
La autenticación interactiva del explorador bloqueará la ejecución del código al solicitar las credenciales. No es una opción adecuada para la autenticación en entornos desatendidos, como trabajos de entrenamiento. Se recomienda configurar otro modo de autenticación.
En aquellos escenarios en los que se requiere la ejecución desatendida, tendrá que configurar una entidad de servicio para comunicarse con Azure Machine Learning.
import os
os.environ["AZURE_TENANT_ID"] = "<AZURE_TENANT_ID>"
os.environ["AZURE_CLIENT_ID"] = "<AZURE_CLIENT_ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<AZURE_CLIENT_SECRET>"
Sugerencia
Al trabajar en entornos compartidos, es aconsejable configurar estas variables de entorno en el proceso. Como procedimiento recomendado, puede administrarlos como secretos en una instancia de Azure Key Vault siempre que sea posible. Por ejemplo, en Azure Databricks puede usar secretos en variables de entorno como se indica a continuación en la configuración del clúster: AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}}. Consulte Referencia a un secreto en una variable de entorno para obtener información sobre cómo hacerlo en Azure Databricks o consulte documentación similar en la plataforma.
Nombres de experimento en Azure Machine Learning
De forma predeterminada, Azure Machine Learning realiza un seguimiento de las ejecuciones en un experimento predeterminado que se llama Default. Suele ser una buena idea establecer el experimento en el que va a trabajar. Use la sintaxis siguiente para establecer el nombre del experimento:
mlflow.set_experiment(experiment_name="experiment-name")
Seguimiento de parámetros, métricas y artefactos
Después, puede usar MLflow en Azure Synapse Analytics de la misma manera que acostumbra a usarlo. Para más información, consulte Registro y visualización de métricas y archivos de registro.
Registro de modelos en el registro con MLflow
Los modelos se pueden registrar en el área de trabajo de Azure Machine Learning, que ofrece un repositorio centralizado para administrar su ciclo de vida. En el ejemplo siguiente, se registra un modelo entrenado con Spark MLLib y también se registra en el registro.
mlflow.spark.log_model(model,
artifact_path = "model",
registered_model_name = "model_name")
Si no existe un modelo registrado con el nombre, el método registra un modelo nuevo, crea la versión 1 y devuelve un objeto MLflow ModelVersion.
Si ya existe un modelo registrado con el nombre, el método crea una versión del modelo y devuelve el objeto de versión.
Puede administrar modelos registrados en Azure Machine Learning con MLflow. Vea Administración de registros de modelos en Azure Machine Learning con MLflow para obtener más detalles.
Implementación y consumo de modelos registrados en Azure Machine Learning
Los modelos registrados en el servicio de Azure Machine Learning con MLflow se pueden consumir como:
Un punto de conexión de Azure Machine Learning (en tiempo real y por lotes): esta implementación permite aprovechar la funcionalidad de implementación de Azure Machine Learning para la inferencia en tiempo real y por lotes en Azure Container Instances (ACI), Azure Kubernetes (AKS) o en nuestros puntos de conexión administrador.
Objetos de modelo de MLFlow o UDF de Pandas, que se pueden usar en cuadernos de Azure Synapse Analytics en canalizaciones de streaming o por lotes.
Implementación de modelos en puntos de conexión de Azure Machine Learning
Puede aprovechar el complemento azureml-mlflow para implementar un modelo en el área de trabajo de Azure Machine Learning. Consulte la página Implementación de modelos de MLflow para obtener información completa sobre cómo implementar modelos en los distintos destinos.
Importante
Los modelos deben registrarse en el registro de Azure Machine Learning para poder implementarlos. No se admite la implementación de modelos no registrados en Azure Machine Learning.
Implementación de modelos para la puntuación por lotes con UDF
Puede elegir clústeres de Azure Synapse Analytics para la puntuación por lotes. El modelo de MLFlow se carga y se usa como función definida por el usuario de Pandas de Spark para puntuar nuevos datos.
from pyspark.sql.types import ArrayType, FloatType
model_uri = "runs:/"+last_run_id+ {model_path}
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
Limpieza de recursos
Si quiere conservar el área de trabajo de Azure Synapse Analytics, pero ya no necesita el área de trabajo de Azure Machine Learning, puede eliminar esta última. Si no tiene pensado usar los artefactos o las métricas registradas en el área de trabajo, la funcionalidad para eliminarlos de forma individual no está disponible en este momento. Por ello, deberá eliminar el grupo de recursos que contiene la cuenta de almacenamiento y el área de trabajo para no incurrir en cargos:
En Azure Portal, seleccione Grupos de recursos a la izquierda del todo.
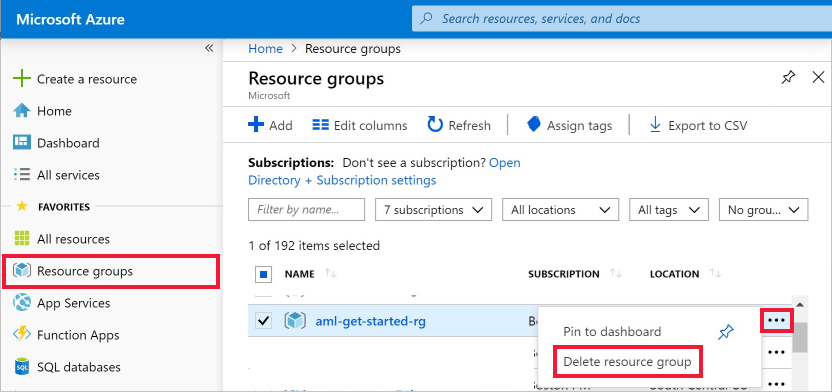
En la lista, seleccione el grupo de recursos que creó.
Seleccione Eliminar grupo de recursos.
Escriba el nombre del grupo de recursos. A continuación, seleccione Eliminar.
Pasos siguientes
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de