Hash de características
Importante
El soporte técnico de Machine Learning Studio (clásico) finalizará el 31 de agosto de 2024. Se recomienda realizar la transición a Azure Machine Learning antes de esa fecha.
A partir del 1 de diciembre de 2021 no se podrán crear recursos de Machine Learning Studio (clásico). Hasta el 31 de agosto de 2024, puede seguir usando los recursos de Machine Learning Studio (clásico) existentes.
- Consulte la información acerca de traslado de proyectos de aprendizaje automático de ML Studio (clásico) a Azure Machine Learning.
- Más información sobre Azure Machine Learning.
La documentación de ML Studio (clásico) se está retirando y es posible que no se actualice en el futuro.
Convierte los datos de texto en características codificadas en enteros con la biblioteca de Vowpal Wabbit
Categoría: Text Analytics
Nota
Se aplica a: solo Machine Learning Studio (clásico)
Hay módulos para arrastrar y colocar similares en el diseñador de Azure Machine Learning.
Información general sobre el módulo
En este artículo se describe cómo usar el módulo Feature Hashing en Machine Learning Studio (clásico), para transformar una secuencia de texto en inglés en un conjunto de características representadas como enteros. A continuación, puede pasar este conjunto de características hash a un algoritmo de aprendizaje automático para entrenar un modelo de análisis de texto.
La funcionalidad de hash de características proporcionada en este módulo se basa en el marco vowpal Wabbit. Para obtener más información, vea Train Vowpal Wabbit 7-4 Model or Train Vowpal Wabbit 7-10 Model.
Más información sobre el hash de características
Feature Hashing funciona mediante la conversión de tokens únicos en enteros. Funciona exactamente en las cadenas que proporcione como entrada y no realiza ningún análisis lingüístico ni preprocesamiento.
Por ejemplo, tome un conjunto de oraciones simples como estas, seguido de una puntuación de opinión. Supongamos que desea utilizar este texto para generar un modelo.
| TEXTO DE USUARIO | OPINIÓN |
|---|---|
| Me gustaba este libro | 3 |
| No me gustaba este libro | 1 |
| Este libro era fantástico | 3 |
| Me encantan los libros | 2 |
Internamente, el módulo Feature Hashing crea un diccionario de n-gramas. Por ejemplo, la lista de bigramas de este conjunto de datos debería tener el siguiente aspecto:
| TÉRMINO (bigramas) | FRECUENCIA |
|---|---|
| Este libro | 3 |
| Me gustaba | 1 |
| No me | 1 |
| Me encanta | 1 |
Puede controlar el tamaño de los n-gramas mediante la propiedad N-grams. Si elige bigramas, también se calcularán los unigramas. Por lo tanto, el diccionario también incluiría términos únicos como estos:
| Término (unigramas) | FRECUENCIA |
|---|---|
| libro | 3 |
| I | 3 |
| libros | 1 |
| gustaba | 1 |
Una vez compilado el diccionario, el módulo Feature Hashing convierte los términos del diccionario en valores hash y calcula si se usó una característica en cada caso. Para cada fila de datos de texto, el módulo genera un conjunto de columnas, una columna para cada característica con hash.
Por ejemplo, después de aplicar el algoritmo hash, las columnas de características pueden tener un aspecto similar al siguiente:
| Rating | Característica de hash 1 | Característica de hash 2 | Característica de hash 3 |
|---|---|---|---|
| 4 | 1 | 1 | 0 |
| 5 | 0 | 0 | 0 |
- Si el valor de la columna es 0, la fila no contiene la característica con hash.
- Si el valor es 1, la fila sí contenía la característica.
La ventaja de usar hash de características es que puede representar documentos de texto de longitud variable como vectores numéricos de características de igual longitud y lograr la reducción de dimensionalidad. Por el contrario, si intentó usar la columna de texto para el entrenamiento tal cual, se trataría como una columna de característica de categorías, con muchos valores distintos.
Tener los resultados como numéricos también hace posible el uso de numerosos y diferentes métodos de aprendizaje automático con los datos, como clasificación, agrupación en clústeres o recuperación de información. Dado que las operaciones de búsqueda pueden utilizar hashes de enteros en lugar de comparaciones de cadenas, obtener los pesos de las características también es mucho más rápido.
Configuración de hash de características
Agregue el módulo Feature Hashing al experimento en Studio (clásico).
Conecte el conjunto de datos que contiene el texto que desea analizar.
Sugerencia
Dado que el hash de características no realiza operaciones léxicas como lematización o truncamiento, a veces puede obtener mejores resultados si realiza el preprocesamiento del texto antes de aplicarlo. Para obtener sugerencias, consulte las secciones Procedimientos recomendados y Notas técnicas .
En Columnas de destino, seleccione las columnas de texto que desea convertir en características con hash.
Las columnas deben ser el tipo de datos de cadena y deben marcarse como una columna característica .
Si elige varias columnas de texto para usarlas como entradas, puede tener un gran efecto en la dimensionalidad de las características. Por ejemplo, si se usa un hash de 10 bits para una sola columna de texto, la salida contiene 1024 columnas. Si se usa un hash de 10 bits para dos columnas de texto, la salida contiene 2048 columnas.
Nota
De forma predeterminada, Studio (clásico) marca la mayoría de las columnas de texto como características, por lo que si selecciona todas las columnas de texto, puede obtener demasiadas columnas, incluidas muchas que no son realmente texto libre. Use la opción Borrar característica en Editar metadatos para evitar que se aplique un algoritmo hash a otras columnas de texto.
Utilice Hashing bitsize (Tamaño de bits de hash) para especificar el número de bits que se va a utilizar al crear la tabla hash.
El tamaño de bits predeterminado es 10. Para muchos problemas, este valor es más que adecuado, pero si basta con los datos depende del tamaño del vocabulario de n-gramas en el texto de entrenamiento. Con un vocabulario grande, es posible que se necesite más espacio para evitar colisiones.
Se recomienda intentar usar un número diferente de bits para este parámetro y evaluar el rendimiento de la solución de aprendizaje automático.
En N-grams (N-gramas), escriba un número que defina la longitud máxima de los n-gramas que se van a agregar al diccionario de entrenamiento. Un n-grama es una secuencia de n palabras, que se trata como una unidad única.
N-gramas = 1: unigramas o palabras simples.
N-gramas = 2: Bigrams, o secuencias de dos palabras, más unigramas.
N-gramas = 3: trigramas, o secuencias de tres palabras, más bigrams y unigramas.
Ejecute el experimento.
Results
Una vez completado el procesamiento, el módulo genera un conjunto de datos transformado en el que la columna de texto original se ha convertido en varias columnas, cada una de las cuales representa una característica del texto. En función del tamaño del diccionario, el conjunto de datos resultante puede ser extremadamente grande:
| Nombre de la columna 1 | Tipo de columna 2 |
|---|---|
| TEXTO DE USUARIO | Columna de datos original |
| OPINIÓN | Columna de datos original |
| TEXTO DE USUARIO: característica de hash 1 | Columna de características con hash |
| TEXTO DE USUARIO: característica de hash 2 | Columna de características con hash |
| TEXTO DE USUARIO: característica de hash 3 | Columna de características con hash |
| TEXTO DE USUARIO: característica de hash 1024 | Columna de características con hash |
Después de crear el conjunto de datos transformado, puede usarlo como entrada para el módulo Entrenar modelo , junto con un buen modelo de clasificación, como la máquina de vectores de soporte de dos clases.
Procedimientos recomendados
Algunos procedimientos recomendados que puede usar al modelar datos de texto se muestran en el diagrama siguiente que representa un experimento.
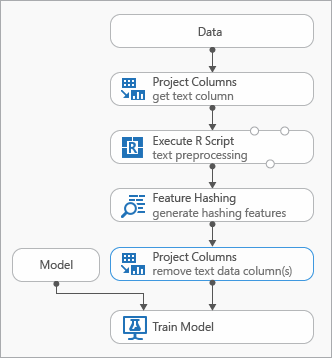
Podría necesitar agregar un módulo Ejecutar script de R antes de usar Hash de características, para preprocesar el texto de entrada. Con el script de R, también tiene la flexibilidad de usar vocabularios personalizados o transformaciones personalizadas.
Debe agregar un módulo Select Columns in Dataset (Seleccionar columnas en el conjunto de datos ) después del módulo Feature Hashing (Hash de características ) para quitar las columnas de texto del conjunto de datos de salida. No necesita las columnas de texto después de que se hayan generado las características de hash.
Como alternativa, puede usar el módulo Editar metadatos para borrar el atributo de característica de la columna de texto.
Considere también el uso de estas opciones de preprocesamiento de texto para simplificar los resultados y mejorar la precisión:
- separación de palabras
- detener eliminación de palabras
- normalización de mayúsculas y minúsculas
- eliminación de signos de puntuación y caracteres especiales
- Derivados.
El conjunto óptimo de métodos de preprocesamiento que se aplican en cualquier solución individual depende del dominio, del vocabulario y de la necesidad empresarial. Se recomienda experimentar con los datos para ver qué métodos de procesamiento de texto personalizados son más eficaces.
Ejemplos
Para obtener ejemplos de cómo se usa el hash de características para el análisis de texto, consulte la Galería de Azure AI:
Categorización de noticias: usa el hash de características para clasificar artículos en una lista predefinida de categorías.
Empresas similares: usa el texto de los artículos de Wikipedia para clasificar las empresas.
Clasificación de texto: en este ejemplo de cinco partes se usa texto de mensajes de Twitter para realizar análisis de sentimiento.
Notas técnicas
Esta sección contiene detalles de implementación, sugerencias y respuestas a las preguntas más frecuentes.
Sugerencia
Además de usar el hash de características, es posible que desee usar otros métodos para extraer características del texto. Por ejemplo:
- Use el módulo Preprocesar texto para quitar artefactos como errores ortográficos o para simplificar la preparación del texto en el hash.
- Use Extraer frases clave para usar el procesamiento de lenguaje natural para extraer frases.
- Use Reconocimiento de entidades con nombre para identificar entidades importantes.
Machine Learning Studio (clásico) proporciona una plantilla de clasificación de texto que le guía a través del uso del módulo Feature Hashing para la extracción de características.
Detalles de la implementación
El módulo Feature Hashing usa un marco de aprendizaje automático rápido denominado Vowpal Wabbit que aplica hash a palabras de características en índices en memoria, mediante un popular código abierto función hash denominada murmurhash3. Esta función hash es un algoritmo de hash no criptográfico que asigna entradas de texto a enteros y es muy conocida porque funciona perfectamente en distribución aleatoria de claves. A diferencia de las funciones hash criptográficas, un adversario puede invertir fácilmente para que no sea adecuado para fines criptográficos.
La finalidad de hash es convertir documentos de texto de longitud variable en vectores de característica numéricos de igual longitud, para admitir la reducción de dimensionalidad y acelerar la búsqueda de pesos de característica.
Cada característica hash representa una o varias características de texto de n-gramas (unigramas o palabras individuales, bi-gramas, trigramas, etc.), dependiendo del número de bits (representado como k) y del número de n-gramas especificados como parámetros. Proyecta nombres de características en la palabra sin signo de la arquitectura de la máquina mediante el algoritmo murhash v3 (solo de 32 bits) que, a continuación, es AND-ed con (2^k)-1. Es decir, el valor hash se proyecta hasta los primeros bits de orden inferior k y los bits restantes se reducen a cero. Si el número especificado de bits es 14, la tabla hash puede contener 2entradas de 14 a 1 (o 16 383).
Para muchos problemas, la tabla hash predeterminada (bitsize = 10) es más que adecuada; sin embargo, dependiendo del tamaño del vocabulario de n-gramas en el texto de entrenamiento, es posible que se necesite más espacio para evitar colisiones. Se recomienda intentar usar un número diferente de bits para el parámetro Hashing bitsize y evaluar el rendimiento de la solución de aprendizaje automático.
Entradas esperadas
| Nombre | Tipo | Descripción |
|---|---|---|
| Dataset | Tabla de datos | Conjunto de datos de entrada |
Parámetros del módulo
| Nombre | Intervalo | Tipo | Valor predeterminado | Descripción |
|---|---|---|---|---|
| Columnas de destino | Any | ColumnSelection | StringFeature | Elija las columnas a las que se aplicará el hash. |
| Tamaño de bits de hash | [1;31] | Entero | 10 | Escribir el número de bits que se usará al aplicar hash a las columnas seleccionadas |
| N-gramas | [0;10] | Entero | 2 | Especifique el número de N-gramas generados durante el hash. De forma predeterminada, se extraen unigramas y bigramas |
Salidas
| Nombre | Tipo | Descripción |
|---|---|---|
| Conjunto de datos transformado | Tabla de datos | Conjunto de datos de salida con columnas con hash |
Excepciones
| Excepción | Descripción |
|---|---|
| Error 0001 | Se produce una excepción si no se encontraron una o más columnas especificadas del conjunto de datos. |
| Error 0003 | Se produce una excepción si una o varias de las entradas son NULL o están vacías. |
| Error 0004 | Se produce una excepción si el parámetro es menor o igual que el valor especificado. |
| Error 0017 | Se produce una excepción si una o varias columnas especificadas tienen un tipo no compatible con el módulo actual. |
Para obtener una lista de errores específicos de los módulos de Studio (clásico), consulte códigos de error Machine Learning.
Para obtener una lista de excepciones de API, consulte Machine Learning códigos de error de la API REST.