Guía sobre el lenguaje de especificación de redes neuronales de Net# para Machine Learning Studio (clásico)
SE APLICA A:  Machine Learning Studio (clásico)
Machine Learning Studio (clásico)  Azure Machine Learning
Azure Machine Learning
Importante
El soporte técnico de Machine Learning Studio (clásico) finalizará el 31 de agosto de 2024. Se recomienda realizar la transición a Azure Machine Learning antes de esa fecha.
A partir del 1 de diciembre de 2021 no se podrán crear recursos de Machine Learning Studio (clásico). Hasta el 31 de agosto de 2024, puede seguir usando los recursos de Machine Learning Studio (clásico) existentes.
- Consulte la información acerca de traslado de proyectos de aprendizaje automático de ML Studio (clásico) a Azure Machine Learning.
- Más información acerca de Azure Machine Learning
La documentación de ML Studio (clásico) se está retirando y es posible que no se actualice en el futuro.
NET # es un lenguaje desarrollado por Microsoft que se utiliza para definir arquitecturas de redes neuronales complejas, como las redes neuronales profundas o las convoluciones de dimensiones arbitrarias. Puede usar estructuras complejas para mejorar el aprendizaje en datos, como imágenes, vídeo o audio.
Puede usar una especificación de arquitectura de Net# en todos los módulos de red neuronal de Machine Learning Studio (clásico):
En este artículo se describen los conceptos básicos y la sintaxis necesaria para desarrollar una red neuronal personalizada con Net#:
- Requisitos de red neuronal y definición de componentes principales
- Sintaxis y palabras clave del lenguaje de especificación Net#
- Ejemplos de redes neuronales personalizadas creadas mediante Net#
Conceptos básicos sobre redes neuronales
Una estructura de red neuronal consta de nodos que se disponen en capas y conexiones ponderadas (o bordes) entre los nodos. Las conexiones son direccionales y cada una de ellas tiene un nodo de origen y un nodo de destino.
Cada una de las capas entrenables (una capa oculta o de salida) tiene uno o varios conjuntos de conexiones. Un conjunto de conexiones consta de una capa de origen y una especificación de las conexiones que salen de esa capa de origen. Todas las conexiones de un conjunto determinado comparten las capas de origen y destino. En Net#, se considera que un conjunto de conexiones pertenece a la capa de destino del conjunto.
Net# admite varios tipos de conjuntos de conexiones, lo que le permite personalizar la forma en que las entradas se asignan tanto a capas ocultas como a las salidas.
El conjunto estándar o predeterminado es un conjunto completo, en el cual cada nodo de la capa de origen se conecta a cada uno de los nodos de la capa de destino.
Además, Net# admite los siguientes cuatro tipos de conjuntos de conexiones avanzados:
Conjuntos filtrados. Para definir un predicado, use las ubicaciones tanto las ubicaciones del nodo de la capa de origen como las del nodo de la capa de destino. Los nodos se conectan siempre que el predicado sea verdadero.
Conjuntos convolucionales. En la capa de origen se pueden definir pequeñas vecindades de nodos. Cada nodo de la capa de destino se conecta con una vecindad de nodos en la capa de origen.
Conjuntos de agrupación y conjuntos de normalización de respuesta. Son similares a los conjuntos convolucionales en cuanto que el usuario define pequeñas vecindades de nodos en la capa de origen. La diferencia es que los usos compartidos de los bordes de estas agrupaciones no son entrenables. En su lugar, se aplica una función predefinida a los valores de nodo de origen para determinar el valor del nodo de destino.
Personalizaciones compatibles
La arquitectura de los modelos de red neuronal creados en Machine Learning Studio (clásico) se puede personalizar ampliamente mediante Net#. Puede:
- Crear capas ocultas y controlar el número de nodos de cada capa.
- Especificar cómo se van a conectar las capas entre ellas.
- Definir estructuras de conectividad especial como convoluciones y conjuntos ponderados de uso compartido.
- Especificar diferentes funciones de activación.
Para obtener detalles sobre la sintaxis del lenguaje de especificación, vea Especificación de estructura.
Para consultar ejemplos de definición de redes neuronales para algunas tareas habituales de aprendizaje automático, desde lo simple a lo complejo, vea Ejemplos.
Requisitos generales
- Debe haber exactamente una capa de salida, al menos una capa de entrada y ninguna o varias capas ocultas.
- Cada capa tiene un número fijo de nodos, ordenados conceptualmente en una matriz rectangular de dimensiones arbitrarias.
- Las capas de entrada no tienen parámetros entrenables asociados y representan el punto en que los datos de la instancia entran en la red.
- Las capas entrenables (las capas ocultas y de salida) tienen parámetros entrenables asociados, conocidos como ponderaciones y sesgos.
- Los nodos de origen y de destino deben encontrarse en capas separadas.
- Las conexiones deben ser acíclicas; en otras palabras, no puede haber una cadena de conexiones que conduzca de nuevo al nodo de origen inicial.
- La capa de salida no puede ser la capa de origen de un conjunto de conexiones.
Especificación de estructura
Una especificación de la estructura de red neuronal se compone de tres secciones: la declaración de constante, la declaración de capa y la declaración de conexión. También hay una sección de declaración de uso compartido opcional. Estas secciones se pueden especificar en cualquier orden.
Declaración constante
Una declaración de constante es opcional. Proporciona un medio para definir los valores utilizados en la definición de la red neuronal. La instrucción de la declaración consta de un identificador seguido por un signo igual y una expresión de valor.
Por ejemplo, la siguiente instrucción define una constante x:
Const X = 28;
Para definir simultáneamente dos o más constantes, escriba los valores y nombres del identificador entre llaves y sepárelos con punto y coma. Por ejemplo:
Const { X = 28; Y = 4; }
La parte derecha de cada expresión de asignación puede ser un entero, un número real, un valor booleano (verdadero/falso) o una expresión matemática. Por ejemplo:
Const { X = 17 * 2; Y = true; }
Declaración de capas
La declaración de capa es obligatoria. Define el tamaño y el origen de la capa, incluidos sus atributos y agrupaciones de conexión. La instrucción de la declaración empieza por el nombre de la capa (de entrada, oculta o de salida) seguida por las dimensiones de la capa (una tupla de enteros positivos). Por ejemplo:
input Data auto;
hidden Hidden[5,20] from Data all;
output Result[2] from Hidden all;
- El producto de las dimensiones es el número de nodos de la capa. En este ejemplo, hay dos dimensiones [5,20], lo que significa que hay 100 nodos en la capa.
- Las capas se pueden declarar en cualquier orden con una excepción: si se define más de una capa de entrada, el orden en que se declaran debe coincidir con el orden de las característica en los datos de entrada.
Para especificar que el número de nodos de una capa se debe determinar de forma automática, utilice la palabra clave auto. La palabra clave auto tiene diferentes efectos, dependiendo de la capa:
- En una declaración de capas de entrada, el número de nodos es el número de características de los datos de entrada.
- En una declaración de capas ocultas, el número de nodos es el número especificado por el valor del parámetro en Número de nodos ocultos.
- En una declaración de capas de salida, el número de nodos es 2 para una clasificación de dos clases, 1 para regresión e igual al número de nodos de salida para la clasificación de varias clases.
Por ejemplo, la siguiente definición de red permite la determinación automática del tamaño de todas las capas:
input Data auto;
hidden Hidden auto from Data all;
output Result auto from Hidden all;
Una declaración de capas para una capa entrenable (las capas de salida u ocultas) puede incluir opcionalmente la función de salida (también llamada función de activación), que se establece de manera predeterminada en sigmoid para los modelos de clasificación y en linear para modelos de regresión. (Incluso si usa el valor predeterminado, se debe indicar explícitamente la función de activación, si lo desea para una mayor claridad).
Se admiten las siguientes funciones de salida:
- sigmoid
- linear
- softmax
- rlinear
- square
- sqrt
- srlinear
- abs
- tanh
- brlinear
Por ejemplo, la siguiente declaración usa la función softmax:
output Result [100] softmax from Hidden all;
Declaración de conexiones
Inmediatamente después de definir la capa entrenable, debe declarar conexiones entre las capas que ha definido. La declaración del conjunto de conexiones empieza por la palabra clave from, seguida del nombre de la capa de origen del conjunto y el tipo de conjunto de conexiones que se va a crear.
Actualmente se admiten cinco tipos de conjuntos de conexiones:
- Conjuntos completos, indicados mediante la palabra clave
all - Conjuntos filtrados, indicados por la palabra clave
where, seguida por una expresión de predicado - Conjuntos convolucionales, indicados por la palabra clave
convolve, seguida de los atributos de convolución - Conjuntos de agrupación, indicados por las palabras clave max pool o mean pool
- Conjuntos de normalización de respuesta indicados por la palabra clave response norm
Conjuntos completos
Un conjunto de conexiones completo incluye una conexión desde cada nodo de la capa de origen a cada nodo de la capa de destino. Este es el tipo de conexión de red predeterminado.
Conjuntos filtrados
Una especificación de conjunto de conexiones filtrado incluye un predicado, expresado sintácticamente de manera muy similar a una expresión lambda de C#. El ejemplo siguiente define dos conjuntos filtrados:
input Pixels [10, 20];
hidden ByRow[10, 12] from Pixels where (s,d) => s[0] == d[0];
hidden ByCol[5, 20] from Pixels where (s,d) => abs(s[1] - d[1]) <= 1;
En el predicado de
ByRow,ses un parámetro que representa un índice en la matriz rectangular de nodos de la capa de entrada,Pixels, ydes un parámetro que representa un índice en la matriz de nodos de la capa oculta,ByRow. El tipo tanto descomo dedes una tupla de enteros de longitud dos. Conceptualmente,sintervalos sobre todos los pares de enteros con0 <= s[0] < 10y0 <= s[1] < 20, ydintervalos de todos los pares de enteros, con0 <= d[0] < 10y0 <= d[1] < 12.En la parte derecha de la expresión del predicado hay una condición. En este ejemplo, para cada valor de
syden los que esa condición sea verdadera, hay un borde que va desde el nodo de la capa de origen al nodo de la capa de destino. Por tanto, esta expresión de filtro indica que el conjunto incluye una conexión desde el nodo definido porshasta el nodo definido porden todos aquellos casos en que s[0] sea igual a d[0].
También tiene la posibilidad de especificar un conjunto de ponderaciones para un conjunto filtrado. El valor del atributo Weights debe ser una tupla de los valores de punto flotante con una longitud que coincida con el número de conexiones definidas por la agrupación. De manera predeterminada, las ponderaciones se generan de manera aleatoria.
Los valores ponderados se agrupan según el índice del nodo de destino. Es decir, si el primer nodo de destino está conectado a nodos de origen K, los primeros K elementos de la tupla Weights son las ponderaciones del primer nodo de destino, en orden del índice de origen. Lo mismo se aplica para los nodos de destino restantes.
Es posible especificar pesos directamente como valores constantes. Por ejemplo, si aprendió anteriormente las ponderaciones, puede especificarlas como constantes con esta sintaxis:
const Weights_1 = [0.0188045055, 0.130500451, ...]
Conjuntos convolucionales
Cuando los datos de entrenamiento tienen una estructura homogénea, se utilizan conexiones de circunvolución habitualmente para aprender funciones de alto nivel de los datos. Por ejemplo, en datos de imagen, audio o vídeo, la dimensionalidad espacial o temporal puede ser bastante homogénea.
Los conjuntos convolucionales usan kernels que se deslizan a través de las dimensiones. Básicamente, cada kernel define un conjunto de ponderaciones aplicado en vecindades locales, conocidas como aplicaciones de kernel. Cada aplicación de kernel se corresponde con un nodo de la capa de origen, conocido como nodo central. Las ponderaciones de un kernel se comparten entre varias conexiones. En un conjunto convolucional, cada kernel es rectangular y todas las aplicaciones de kernel tienen el mismo tamaño.
Los conjuntos convolucionales admiten los siguientes atributos:
InputShape define la dimensionalidad de la capa de origen para los fines de este conjunto convolucional. El valor debe ser una tupla de enteros positivos. El producto de los enteros debe equivaler al número de nodos de la capa de origen, pero no es necesario que coincida con la dimensionalidad declarada para la capa de origen. La longitud de esta tupla se convierte en el valor de aridad del conjunto convolucional. La aridad normalmente hace referencia al número de argumentos u operandos que puede asumir una función.
Para definir la forma y las ubicaciones de los kernels, use los atributos KernelShape, Stride, Padding, LowerPad y UpperPad:
KernelShape: (obligatorio) define la dimensionalidad de cada kernel para el conjunto convolucional. El valor debe ser una tupla de números enteros positivos con una longitud igual a la aridad de la agrupación. Ninguno de los componentes de esta tupla debe superar en tamaño al componente correspondiente de InputShape.
Stride: (opcional) define los tamaños de los pasos de deslizamiento de la convolución (un tamaño de paso para cada dimensión), es decir, la distancia entre los nodos centrales. El valor debe ser una tupla de números enteros positivos con una longitud igual a la aridad de la agrupación. Ningún componente de esta tupla debe superar en tamaño al componente correspondiente de KernelShape. El valor predeterminado es una tupla con todos los componentes iguales a uno.
Sharing: (opcional) define el uso compartido de las ponderaciones de cada dimensión de la convolución. El valor puede ser un único valor booleano o una tupla de valores booleanos con una longitud que sea la aridad de la agrupación. Un valor booleano sencillo se amplía para convertirse en una tupla si la longitud correcta con todos los componentes equivale al valor especificado. El valor predeterminado es una tupla que consta de todos los valores True.
MapCount: (opcional) define el número de mapas de características para el conjunto convolucional. El valor puede ser un número entero positivo o una tupla de enteros positivos con una longitud que sea la aridad de la agrupación. Un valor entero sencillo se amplía para convertirse en una tupla si la longitud correcta con todos los componentes equivale al valor especificado y todos los componentes restantes equivalen a uno. El valor predeterminado es uno. El número total de mapas de características es el producto de los componentes de la tupla. La factorización de este número total entre los componentes determina cómo se agrupan los valores de mapas de características en los nodos de destino.
Weights: (opcional) define las ponderaciones iniciales del conjunto. El valor debe ser una tupla de valores de punto flotante con una longitud que es el número de kernel, el número de pesos por kernel, tal como se define más adelante en este artículo. De manera predeterminada, las ponderaciones se generan de manera aleatoria.
Hay dos conjuntos de propiedades que controlan el completado y que se excluyen mutuamente:
Padding: (opcional) determina si la entrada debe completarse usando un esquema de relleno predeterminado. El valor puede ser un único valor booleano o una tupla de valores booleanos con una longitud que sea la aridad de la agrupación.
Un valor booleano sencillo se amplía para convertirse en una tupla si la longitud correcta con todos los componentes equivale al valor especificado.
Si el valor de una dimensión es verdadero, el origen se completa lógicamente en esa dimensión con celdas de valor cero para atender a las aplicaciones de kernel adicionales, por lo cual los nodos centrales del primer y último kernel de esa dimensión son el primer y último nodo en esa dimensión en la capa de origen. De este modo, el número de nodos "ficticios" de cada dimensión se determina automáticamente, para coincidir exactamente con el número de kernels
(InputShape[d] - 1) / Stride[d] + 1en la capa de origen completada.Si el valor de una dimensión es falso, los kernels se definen de manera que el número de nodos que quedan en cada lado sea el mismo (con una diferencia máxima de 1). El valor predeterminado de este atributo es una tupla con todos los componentes iguales a falso.
UpperPad y LowerPad: (opcional) proporcionan mayor control sobre la cantidad de completado que se usa. Importante: Estos atributos pueden definirse si, y solo si, la propiedad Padding anterior no está definida. Los valores deben ser las tuplas con valores enteros con longitudes que sean la aridad de la agrupación. Cuando se especifican estos atributos, se agregan nodos "ficticios" a los extremos inferior y superior de cada dimensión de la capa de entrada- El número de nodos agregados a los extremos inferior y superior en cada dimensión está determinado por LowerPad[i] y UpperPad[i], respectivamente.
Para asegurarse de que los kernels se corresponden solo a nodos "reales" y no a nodos "ficticios", deben cumplirse las condiciones siguientes:
Cada componente de LowerPad debe ser estrictamente inferior a
KernelShape[d]/2.Ningún componente de UpperPad puede ser superior a
KernelShape[d]/2.El valor predeterminado de estos atributos es una tupla con todos los componentes iguales a 0.
La configuración de Padding = true permite todo el relleno que sea necesario para mantener el "centro" del kernel dentro de la entrada "real". Cambia la expresión matemática un poco para calcular el tamaño de salida. Por lo general, el tamaño de salida D se calcula como
D = (I - K) / S + 1, dondeIes el tamaño de entrada,Kes el tamaño del kernel,Ses el intervalo y/es la división de enteros (redondear hacia cero). Si establece UpperPad = [1, 1], el tamaño de entradaIes efectivamente 29 y, por lo tanto,D = (29 - 5) / 2 + 1 = 13. Sin embargo, cuando Padding = true, esencialmenteIaumenta enK - 1; por lo tanto,D = ((28 + 4) - 5) / 2 + 1 = 27 / 2 + 1 = 13 + 1 = 14. Al especificar valores para UpperPad y LowerPad, obtendrá un mayor control sobre el relleno que si simplemente establece Padding = true.
Para obtener más información acerca de las redes convolucionales y sus aplicaciones, consulte estos artículos:
- http://d2l.ai/chapter_convolutional-neural-networks/lenet.html
- https://research.microsoft.com/pubs/68920/icdar03.pdf
Conjuntos de agrupación
Un conjunto de agrupación aplica una geometría similar a la conectividad convolucional, pero usa funciones predefinidas sobre los valores de los nodos de origen para derivar el valor del nodo de destino. Por tanto, los conjuntos de agrupación no tienen estado entrenable (ponderaciones o sesgos). Los paquetes de agrupación admiten todos los atributos convolucionales, excepto Sharing, MapCount y Weights.
Normalmente, los kernel resumidos por las unidades de agrupación adyacentes no se superponen. Si Stride[d] es igual a KernelShape[d] en cada dimensión, la capa obtenida es la capa de agrupación local tradicional, utilizada habitualmente en redes neuronales convolucionales. Cada nodo de destino calcula el valor máximo o la media de las actividades de su kernel en la capa de origen.
El ejemplo siguiente ilustra un conjunto de agrupación:
hidden P1 [5, 12, 12]
from C1 max pool {
InputShape = [ 5, 24, 24];
KernelShape = [ 1, 2, 2];
Stride = [ 1, 2, 2];
}
- La aridad de la agrupación es 3: es decir, la longitud de las tuplas
InputShape,KernelShapeyStride. - El número de nodos de la capa de origen es
5 * 24 * 24 = 2880. - Esto es un nivel de agrupación local tradicional porque KernelShape y Stride son iguales.
- El número de nodos de la capa de destino es
5 * 12 * 12 = 1440.
Para obtener más información acerca de las capas de agrupación, consulte estos artículos:
- https://www.cs.toronto.edu/~hinton/absps/imagenet.pdf (Sección 3.4)
- https://cs.nyu.edu/~koray/publis/lecun-iscas-10.pdf
- https://cs.nyu.edu/~koray/publis/jarrett-iccv-09.pdf
Conjuntos de normalización de respuesta
La normalización de respuesta es un esquema de normalización local que presentó Geoffrey Hinton, y otros, en el documento ImageNet Classification with Deep Convolutional Neural Networks (Clasificación de ImageNet con redes neuronales convolucionales profundas).
La normalización de respuesta se utiliza para ayudar a la generalización en redes neuronales. Cuando una neurona se activa a un nivel muy alto, una capa de normalización de respuesta local suprime la capa de activación de las neuronas circundantes. Esto se realiza mediante tres parámetros (α, β y k) y una estructura convolucional (o forma de entorno). Cada neurona de la capa de destino y se corresponde con una neurona x de la capa de origen. El nivel de activación de y se determina mediante la fórmula siguiente, donde f es el nivel de activación de una neurona y Nx es el kernel (o el conjunto que contiene las neuronas en el entorno de x) como se define en la siguiente estructura convolucional:
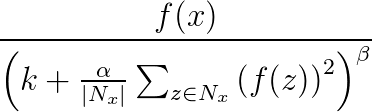
Las agrupaciones de normalización de respuesta admiten todos los atributos convolucionales excepto Sharing, MapCount y Weights.
Si el kernel contiene neuronas en el mismo mapa que x, el esquema de normalización se conoce como normalización del mismo mapa. Para definir la normalización de mismo mapa, la primera coordenada de InputShape debe tener un valor de 1.
Si el kernel contiene neuronas en la misma posición espacial que x, pero las neuronas se encuentran en otros mapas, el esquema de normalización recibe el nombre de normalización entre mapas. El tipo de normalización de respuesta implementa una forma de inhibición lateral inspirada en el tipo encontrado en las neuronas reales, creando competencia para los grandes niveles de activación entre los resultados neuronales calculados en los diferentes mapas. Para definir la normalización entre mapas, el primer coordinado debe ser un entero mayor que uno y no mayor que el número de mapas, y el resto de coordinados debe tener el valor 1.
Dado que los conjuntos de normalización de respuesta aplican una función predefinida a los valores del nodo de origen para determinar el valor del nodo de destino, no tienen un estado entrenable (ponderaciones o sesgos).
Nota:
Los nodos de la capa de destino se corresponden con las neuronas que se encuentran en los nodos centrales de los kernels. Por ejemplo, si KernelShape[d] es impar, KernelShape[d]/2 corresponde al nodo central del kernel. Si KernelShape[d] es par, el nodo central está en KernelShape[d]/2 - 1. Por lo tanto, si Padding[d] es False, el primer y último nodo KernelShape[d]/2 no tienen nodos correspondientes en la capa de destino. Para evitar esta situación, defina Padding como [true, true, …, true].
Además de los cuatro atributos que se han descrito anteriormente, las agrupaciones de normalización de respuesta también admiten los siguientes atributos:
- Alpha: (obligatorio) especifica un valor de punto flotante que corresponde a
αen la fórmula anterior. - Beta: (obligatorio) especifica un valor de punto flotante que corresponde a
βen la fórmula anterior. - Offset: (opcional) especifica un valor de punto flotante que corresponde a
ken la fórmula anterior. De manera predeterminada, su valor es 1.
En el ejemplo siguiente se define un conjunto de normalización de respuesta que utiliza estos atributos:
hidden RN1 [5, 10, 10]
from P1 response norm {
InputShape = [ 5, 12, 12];
KernelShape = [ 1, 3, 3];
Alpha = 0.001;
Beta = 0.75;
}
- La capa de origen incluye cinco mapas, cada uno con una dimensión de 12 x 12, lo que genera un total de 1440 nodos.
- El valor de KernelShape indica que se trata de una capa de normalización de mismo mapa, donde el entorno es un rectángulo de 3x3.
- El valor predeterminado de Padding es False, por lo que la capa de destino tiene solo 10 nodos en cada dimensión. A fin de incluir un nodo en la capa de destino correspondiente a cada uno de los nodos de la capa de origen, agregue Padding = [true, true, true] y cambie el tamaño de RN1 a [5, 12, 12].
Declaración de uso compartido
Net# admite opcionalmente la definición de varios conjuntos con ponderaciones compartidas. Los pesos de las dos agrupaciones se pueden compartir si sus estructuras son iguales. La siguiente sintaxis define agrupaciones con pesos compartidos:
share-declaration:
share { layer-list }
share { bundle-list }
share { bias-list }
layer-list:
layer-name , layer-name
layer-list , layer-name
bundle-list:
bundle-spec , bundle-spec
bundle-list , bundle-spec
bundle-spec:
layer-name => layer-name
bias-list:
bias-spec , bias-spec
bias-list , bias-spec
bias-spec:
1 => layer-name
layer-name:
identifier
Por ejemplo, la siguiente declaración de uso compartido especifica los nombres de las capas, indicando que tanto las ponderaciones como los sesgos deben compartirse:
Const {
InputSize = 37;
HiddenSize = 50;
}
input {
Data1 [InputSize];
Data2 [InputSize];
}
hidden {
H1 [HiddenSize] from Data1 all;
H2 [HiddenSize] from Data2 all;
}
output Result [2] {
from H1 all;
from H2 all;
}
share { H1, H2 } // share both weights and biases
- Las características de entrada se particionan en dos capas de entrada de igual tamaño.
- Las capas ocultas calculan entonces características de niveles más altos en las dos capas de entrada.
- La declaración de uso compartido especifica que H1 y H2 deben calcularse del mismo modo desde sus entradas respectivas.
Es posible también especificarlo con dos declaraciones de uso compartido independientes, del modo siguiente:
share { Data1 => H1, Data2 => H2 } // share weights
<!-- -->
share { 1 => H1, 1 => H2 } // share biases
Solo puede utilizar la forma abreviada cuando las capas contienen una única agrupación. En general, el uso compartido es posible solo cuando la estructura relevante sea idéntica; es decir, cuando tenga el mismo tamaño, la misma geometría convolucional, etc.
Ejemplos de uso de Net#
En esta sección se ofrecen ejemplos acerca del modo de utilizar Net# para agregar capas ocultas, definir el modo en que las capas ocultas interactúan con otras capas y crear redes convolucionales.
Definición de una red neuronal sencilla personalizada: ejemplo "Hello World"
Este sencillo ejemplo demuestra cómo crear un modelo de red neuronal que tenga una única capa oculta.
input Data auto;
hidden H [200] from Data all;
output Out [10] sigmoid from H all;
En el ejemplo se muestran algunos comandos básicos como los siguientes:
- La primera línea define el nivel de entrada (denominado
Data). Cuando se usa la palabra claveauto, la red neuronal incluye automáticamente todas las columnas de características en los ejemplos de entrada. - La segunda línea crea la capa oculta. El nombre
Hse asigna a la capa oculta, que tiene 200 nodos. Esta capa está conectada por completo a la capa de entrada. - La tercera línea define la capa de salida (denominada
Out), que contiene 10 nodos de salida. Si la red neuronal se usa para la clasificación, hay un nodo de salida por clase. La palabra clave sigmoid indica que la función de salida se aplica a la capa de salida.
Definición de varias capas ocultas: ejemplo de visión de equipo
En el ejemplo siguiente se demuestra cómo definir una red neuronal ligeramente más compleja, con varias capas personalizadas ocultas.
// Define the input layers
input Pixels [10, 20];
input MetaData [7];
// Define the first two hidden layers, using data only from the Pixels input
hidden ByRow [10, 12] from Pixels where (s,d) => s[0] == d[0];
hidden ByCol [5, 20] from Pixels where (s,d) => abs(s[1] - d[1]) <= 1;
// Define the third hidden layer, which uses as source the hidden layers ByRow and ByCol
hidden Gather [100]
{
from ByRow all;
from ByCol all;
}
// Define the output layer and its sources
output Result [10]
{
from Gather all;
from MetaData all;
}
Este ejemplo muestra varias funciones del lenguaje de especificación de redes neuronales:
- La estructura tiene dos capas de entrada:
PixelsyMetaData. - La capa
Pixelses una capa de origen en dos agrupaciones de conexiones, con capas de destino,ByRowyByCol. - Las capas
GatheryResultson capas de destino en varias agrupaciones de conexiones. - La capa de salida,
Result, es una capa de destino en dos agrupaciones de conexiones; una con el segundo nivel ocultoGathercomo capa de destino, y la otra con la capa de entradaMetaDatacomo capa de destino. - Las capas ocultas,
ByRowyByCol, especifican conectividad filtrada mediante expresiones de predicado. Más concretamente, el nodo deByRowen [x, y] está conectado a los nodos enPixels, que tienen la primera coordenada de índice igual a la primera coordenada del nodo, x. De forma similar, el nodo deByColen [x, y] está conectado a los nodos dePixels, que tienen la segunda coordenada de índice dentro de una de las segundas coordenadas del nodo, y.
Defina una red de circunvolución para la clasificación multiclass: ejemplo de reconocimiento de dígitos
La definición de la siguiente red está diseñada para reconocer los números y muestra algunas técnicas avanzadas para personalizar una red neuronal.
input Image [29, 29];
hidden Conv1 [5, 13, 13] from Image convolve
{
InputShape = [29, 29];
KernelShape = [ 5, 5];
Stride = [ 2, 2];
MapCount = 5;
}
hidden Conv2 [50, 5, 5]
from Conv1 convolve
{
InputShape = [ 5, 13, 13];
KernelShape = [ 1, 5, 5];
Stride = [ 1, 2, 2];
Sharing = [false, true, true];
MapCount = 10;
}
hidden Hid3 [100] from Conv2 all;
output Digit [10] from Hid3 all;
La estructura tiene una sola capa de entrada:
Image.La palabra clave
convolveindica que las capas llamadasConv1yConv2son capas convolucionales. Cada una de estas declaraciones de capa está seguida por una lista de los atributos de convolución.La red tiene una tercera capa oculta,
Hid3, que está totalmente conectada a la segunda capa oculta,Conv2.La capa de salida,
Digit, está conectada solo a la tercera capa oculta,Hid3. La palabra claveallindica que la capa de salida está conectada por completo aHid3.La aridad de la convolución es tres: la longitud de las tuplas
InputShape,KernelShape,StrideySharing.El número de ponderaciones por kernel es
1 + KernelShape\[0] * KernelShape\[1] * KernelShape\[2] = 1 + 1 * 5 * 5 = 26. O26 * 50 = 1300.Puede calcular los nodos en cada capa oculta del modo siguiente:
NodeCount\[0] = (5 - 1) / 1 + 1 = 5NodeCount\[1] = (13 - 5) / 2 + 1 = 5NodeCount\[2] = (13 - 5) / 2 + 1 = 5El número total de nodos puede calcularse usando la dimensionalidad declarada de la capa, [50, 5, 5], de este modo:
MapCount * NodeCount\[0] * NodeCount\[1] * NodeCount\[2] = 10 * 5 * 5 * 5Dado que
Sharing[d]es False solo parad == 0, el número de kernels esMapCount * NodeCount\[0] = 10 * 5 = 50.
Agradecimientos
El lenguaje de Net# para personalizar la arquitectura de redes neuronales fue desarrollado en Microsoft por Shon Katzenberger (arquitecto, Machine Learning) y Alexey Kamenev (ingeniero de software, Microsoft Research). Se usa internamente para proyectos y aplicaciones de aprendizaje automático que abarcan desde la detección de imágenes para el análisis de texto. Para obtener más información, vea Redes neuronales en Machine Learning Studio: Introducción a Net#.