Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A:  SDK de Python azure-ai-ml v2 (actual)
SDK de Python azure-ai-ml v2 (actual)
Aprenda a implementar un modelo en un punto de conexión en línea mediante el SDK de Python de Azure Machine Learning v2.
En este tutorial, implementará y usará un modelo que predice la probabilidad de que un cliente se realice de forma predeterminada en un pago con tarjeta de crédito.
Los pasos son:
- Registro del modelo
- Creación de un punto de conexión y de una primera implementación
- Implementar una ejecución de prueba
- Enviar manualmente datos de prueba a la implementación
- Obtener detalles de la implementación
- Crear una segunda implementación
- Escalar manualmente la segunda implementación
- Actualizar la asignación del tráfico de producción entre ambas implementaciones
- Obtener detalles de la segunda implementación
- Lanzar la nueva implementación y eliminar la primera
En este vídeo se muestra cómo empezar a trabajar en Azure Machine Learning Studio para que pueda seguir los pasos del tutorial. El vídeo muestra cómo crear un cuaderno, crear una instancia de proceso y clonar el cuaderno. Estos pasos también se describen en las secciones siguientes.
Requisitos previos
-
Para usar Azure Machine Learning, necesita un área de trabajo. Si no tiene una, complete Crear recursos necesarios para empezar para crear un área de trabajo y obtener más información sobre su uso.
Importante
Si su área de trabajo de Azure Machine Learning está configurada con una red virtual administrada, es posible que deba agregar reglas de salida para permitir el acceso a los repositorios públicos de paquetes de Python. Para más información, consulte Escenario: Acceso a paquetes de aprendizaje automático públicos.
-
Inicie sesión en Studio y seleccione el área de trabajo si aún no está abierta.
-
Abra o cree una libreta en el área de trabajo:
- Si desea copiar y pegar código en celdas, cree un cuaderno nuevo.
- O bien, abra tutorials/get-started-notebooks/deploy-model.ipynb desde la sección ejemplos de Studio. A continuación, seleccione Clonar para agregar el cuaderno a sus Archivos. Para encontrar cuadernos de ejemplo, consulte Aprenda con cuadernos de ejemplo.
Consulte su cuota de VM y asegúrese de que tiene suficiente cuota disponible para crear implementaciones en línea. En este tutorial, necesita al menos 8 núcleos de
STANDARD_DS3_v2y 12 núcleos deSTANDARD_F4s_v2. Para ver el uso de su cuota de VM y solicitar aumentos de cuota, consulte Administrar cuotas de recursos.
Establecer el kernel y abrirlo en Visual Studio Code (VS Code)
En la barra superior del cuaderno abierto, cree una instancia de proceso si aún no tiene una.

Si la instancia de proceso se detiene, seleccione Iniciar proceso y espere hasta que se ejecute.

Espere hasta que la instancia de cálculo esté en ejecución. A continuación, asegúrese de que el kernel, que se encuentra en la parte superior derecha, es
Python 3.10 - SDK v2. Si no es así, use la lista desplegable para seleccionar este kernel.
Si no ve este kernel, compruebe que la instancia de proceso se está ejecutando. Si es así, seleccione el botón Actualizar situado en la parte superior derecha del cuaderno.
Si ves un banner que dice que debes autenticarte, selecciona Autenticar.
Puede ejecutar el cuaderno aquí o abrirlo en VS Code para un entorno de desarrollo integrado (IDE) completo con la eficacia de los recursos de Azure Machine Learning. Seleccione Abrir en VS Codey, a continuación, seleccione la opción web o de escritorio. Cuando se inicia de esta manera, VS Code se adjunta a la instancia de proceso, el kernel y el sistema de archivos del área de trabajo.





Importante
El resto de este tutorial contiene celdas del cuaderno del tutorial. Cópielos y péguelos en su nuevo cuaderno, o cambie al cuaderno actual si lo ha clonado.
Nota:
El proceso de Spark sin servidor no tiene Python 3.10 - SDK v2 instalado de forma predeterminada. Se recomienda crear una instancia de proceso y seleccionarla antes de continuar con el tutorial.
Creación de un manipulador para el área de trabajo
Antes de sumergirse en el código, necesitará una manera de referenciar el área de trabajo. Cree ml_client para un identificador en el área de trabajo y use el ml_client para administrar recursos y trabajos.
En la celda siguiente, escriba el identificador de suscripción, el nombre del grupo de recursos y el nombre del área de trabajo. Para establecer estos valores:
- En la barra de herramientas de Estudio de Azure Machine Learning superior derecha, seleccione el nombre del área de trabajo.
- Copie el valor del área de trabajo, el grupo de recursos y el identificador de suscripción en el código.
- Debe copiar un valor, cerrar la ventana, pegar y luego volver para el siguiente.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# authenticate
try:
credential = DefaultAzureCredential()
credential.get_token("https://management.azure.com/.default")
except Exception:
credential = InteractiveBrowserCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Nota:
La creación de MLClient no se conectará al área de trabajo. La inicialización del cliente es diferida y espera por primera vez que necesita realizar una llamada (esto sucede en la siguiente celda de código).
Registro del modelo
Si ya completó el tutorial de entrenamiento anterior, Entrenar un modelo, registró un modelo de MLflow como parte del script de entrenamiento y puede ir directamente a la sección siguiente.
Si no ha completado el tutorial de entrenamiento, debe registrar el modelo. Se recomienda registrar el modelo antes de implementarlo.
El código siguiente especifica la path (desde dónde cargar archivos) en línea. Si ha clonado la carpeta tutoriales, ejecute el código siguiente as-is. De lo contrario, descargue los archivos y metadatos del modelo desde la carpeta credit_defaults_model. Guarde los archivos que descargó en una versión local de la carpeta credit_defaults_model en el equipo y actualice la ruta de acceso en el siguiente código a la ubicación de los archivos descargados.
El SDK carga automáticamente los archivos y registra el modelo.
Para más información sobre cómo registrar el modelo como un recurso, consulte Registro del modelo como recurso en Machine Learning mediante el SDK.
# Import the necessary libraries
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
# Provide the model details, including the
# path to the model files, if you've stored them locally.
mlflow_model = Model(
path="./deploy/credit_defaults_model/",
type=AssetTypes.MLFLOW_MODEL,
name="credit_defaults_model",
description="MLflow Model created from local files.",
)
# Register the model
ml_client.models.create_or_update(mlflow_model)
Confirmación de que el modelo está registrado
Puede consultar la página Modelos en el Azure Machine Learning Studio para identificar la última versión de su modelo registrado.
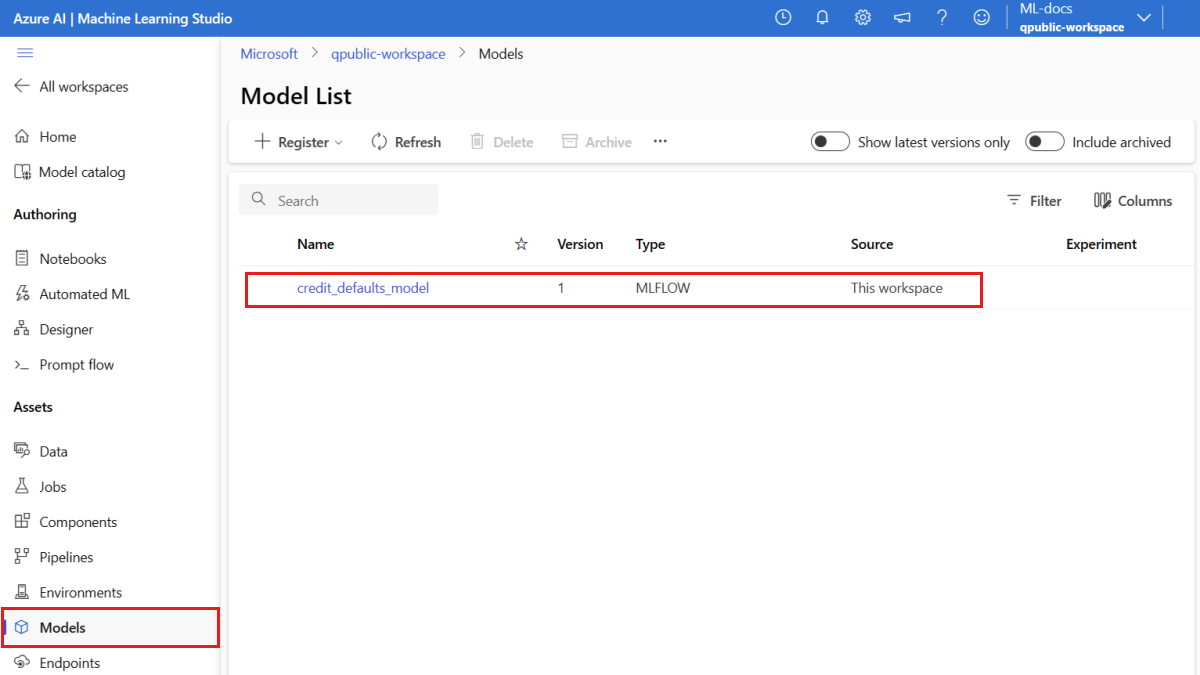
Como alternativa, el código siguiente recupera el número de versión más reciente para que lo use.
registered_model_name = "credit_defaults_model"
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(latest_model_version)
Ahora que tiene un modelo registrado, puede crear un punto de conexión y la implementación. En la siguiente sección se tratan brevemente algunos detalles clave sobre estos temas.
Puntos de conexión e implementaciones
Después de entrenar un modelo de Machine Learning, debe implementarlo para que otros usuarios puedan usarlo para la inferencia. Para ello, Azure Machine Learning le permite crear puntos de conexión y añadirles implementaciones.
Un punto de conexión, en este contexto, es una ruta HTTPS que proporciona una interfaz para que los clientes envíen solicitudes (datos de entrada) a un modelo entrenado y reciban los resultados de la inferencia (puntuación) del modelo. Los puntos de conexión proporcionan:
- Autenticación mediante autenticación basada en "claves o tokens"
- Terminación de TLS (SSL)
- Un URI de puntuación estable (endpoint-name.region.inference.ml.azure.com)
Una implementación es un conjunto de recursos necesarios para hospedar el modelo que realiza la inferencia real.
Un único punto de conexión puede contener varias implementaciones. Los puntos de conexión y las implementaciones son recursos de Azure Resource Manager independientes que aparecen en Azure Portal.
Azure Machine Learning permite implementar puntos de conexión en línea para la inferencia en tiempo real en los datos de cliente y los puntos de conexión por lotes para la inferencia en grandes volúmenes de datos durante un período de tiempo.
En este tutorial, se describen los pasos para implementar un punto de conexión en línea administrado. Los puntos de conexión en línea administrados funcionan con potentes máquinas de CPU y GPU en Azure de una forma escalable y completamente administrada que le libera de la sobrecarga de configurar y administrar la infraestructura de implementación subyacente.
Creación de un punto de conexión en línea
Ahora que tiene un modelo registrado, es hora de crear su punto de conexión en línea. El nombre del punto de conexión debe ser único en toda la región de Azure. En este tutorial, creará un nombre único mediante un identificador único universalmente UUID. Para más información sobre las reglas de nomenclatura de puntos de conexión, consulte Límites de puntos de conexión.
import uuid
# Create a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
En primer lugar, defina el punto de conexión mediante la ManagedOnlineEndpoint clase .
Sugerencia
auth_mode: se usakeypara la autenticación basada en claves. Useaml_tokenpara la autenticación basada en tokens de Azure Machine Learning.keyno expira, peroaml_tokensí lo hace. Para obtener más información sobre la autenticación, vea Autenticar clientes para puntos de conexión en línea.Opcionalmente, puede agregar una descripción y etiquetas al punto de conexión.
from azure.ai.ml.entities import ManagedOnlineEndpoint
# define an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
},
)
Con el MLClient creado anteriormente, cree el punto de conexión en el área de trabajo. Este comando inicia la creación del punto de conexión y devuelve una respuesta de confirmación mientras continúa la creación del punto de conexión.
Nota:
La creación del punto de conexión tardará aproximadamente 2 minutos.
# create the online endpoint
# expect the endpoint to take approximately 2 minutes.
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Una vez creado el punto de conexión, puede recuperarlo de la siguiente manera:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
Descripción de las implementaciones en línea
Los aspectos clave de una implementación incluyen:
-
name- Nombre de la implementación. -
endpoint_name: nombre del punto de conexión que contendrá la implementación. -
model: modelo que se va a usar para la implementación. Este valor puede ser una referencia a un modelo con versiones existente en el área de trabajo o una especificación de modelo en línea. -
environment: el entorno que se usará para la implementación (o para ejecutar el modelo). Este valor puede ser una referencia a un entorno con versiones existente en el área de trabajo o una especificación de entorno en línea. El entorno puede ser una imagen de Docker con dependencias de Conda o un archivo Dockerfile. -
code_configuration- La configuración del código fuente y el script de puntuación.-
path- Ruta de acceso al directorio de código fuente para puntuar el modelo. -
scoring_script: ruta de acceso relativa al archivo de puntuación en el directorio de código fuente. Este script ejecuta el modelo en una solicitud de entrada dada. Para ver un ejemplo de script de puntuación, consulte Comprender el script de puntuación en el artículo " Implementación de un modelo ML con un punto de conexión en línea".
-
-
instance_type: tamaño de máquina virtual que se usará para la implementación. Para la lista de tamaños admitidos, consulte Lista de SKU de puntos de conexión en línea administrados. -
instance_count: número de instancias que se usarán para la implementación.
Implementación mediante un modelo MLflow
Azure Machine Learning admite la implementación sin código de un modelo creado y registrado con MLflow. Esto significa que no es necesario proporcionar un script de puntuación o un entorno durante la implementación del modelo, ya que el script de puntuación y el entorno se generan automáticamente al entrenar un modelo de MLflow. Sin embargo, si usara un modelo personalizado, tendría que especificar el entorno y el script de puntuación durante la implementación.
Importante
Si normalmente implementa modelos mediante scripts de puntuación y entornos personalizados y quiere lograr la misma funcionalidad mediante modelos de MLflow, se recomienda leer Directrices para implementar modelos de MLflow.
Implementación del modelo en el punto de conexión
Empiece por crear una sola implementación que controle el 100 % del tráfico entrante. Elija un nombre de color arbitrario (azul) para la implementación. Para crear la implementación para el punto de conexión, use la clase ManagedOnlineDeployment.
Nota:
No es necesario especificar un entorno o un script de puntuación, ya que el modelo que se va a implementar es un modelo de MLflow.
from azure.ai.ml.entities import ManagedOnlineDeployment
# Choose the latest version of the registered model for deployment
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
Con el MLClient creado anteriormente, cree el despliegue en el espacio de trabajo. Este comando inicia la creación de la implementación y devuelve una respuesta de confirmación mientras continúa la creación de la implementación.
# create the online deployment
blue_deployment = ml_client.online_deployments.begin_create_or_update(
blue_deployment
).result()
# blue deployment takes 100% traffic
# expect the deployment to take approximately 8 to 10 minutes.
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Comprobación del estado del punto de conexión
Puede comprobar el estado del punto de conexión para ver si el modelo se desplegó sin errores:
# return an object that contains metadata for the endpoint
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
# print a selection of the endpoint's metadata
print(
f"Name: {endpoint.name}\nStatus: {endpoint.provisioning_state}\nDescription: {endpoint.description}"
)
# existing traffic details
print(endpoint.traffic)
# Get the scoring URI
print(endpoint.scoring_uri)
Prueba del punto de conexión con datos de ejemplo
Ahora que el modelo está implementado en el punto de conexión, puede ejecutar la inferencia con él. Empiece por crear un archivo de solicitud de ejemplo que siga el diseño esperado en el método run que se encuentra en el script de puntuación.
import os
# Create a directory to store the sample request file.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
Ahora cree el archivo en el directorio deploy. La celda de código siguiente usa IPython magic para escribir el archivo en el directorio que creó.
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
Con el MLClient creado anteriormente, obtenga un identificador para el punto de conexión. Puede invocar el punto de conexión mediante el comando invoke con los parámetros siguientes:
-
endpoint_name: nombre del punto de conexión. -
request_file: archivo con los datos de la solicitud. -
deployment_name: nombre de la implementación específica que se va a probar en un punto de conexión
Pruebe la implementación azul con los datos de ejemplo.
# test the blue deployment with the sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name="blue",
request_file="./deploy/sample-request.json",
)
Obtenga los registros de la implementación
Compruebe los registros para ver si el punto de conexión o la implementación se invocó correctamente. Si tiene errores, vea Solución de problemas de implementación de puntos de conexión en línea.
logs = ml_client.online_deployments.get_logs(
name="blue", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Crear una segunda implementación
Implemente el modelo como una segunda implantación denominada green. En la práctica, puede crear varias implementaciones y comparar su rendimiento. Estas implementaciones podrían usar una versión diferente del mismo modelo, un modelo diferente o una instancia de proceso más eficaz.
En este ejemplo, implementará la misma versión del modelo mediante una instancia de proceso más eficaz que podría mejorar el rendimiento.
# pick the model to deploy. Here you use the latest version of the registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment using a more powerful instance type
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
green_deployment = ManagedOnlineDeployment(
name="green",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_F4s_v2",
instance_count=1,
)
# create the online deployment
# expect the deployment to take approximately 8 to 10 minutes
green_deployment = ml_client.online_deployments.begin_create_or_update(
green_deployment
).result()
Ampliación de la implementación para controlar más tráfico
Con el MLClient creado anteriormente, puede obtener un identificador para la implementación green. Después, puede escalarlo aumentando o disminuyendo el instance_count.
En el código siguiente, se aumenta manualmente la instancia de máquina virtual. Sin embargo, también es posible escalar automáticamente los puntos de conexión en línea. La escalabilidad automática ejecuta automáticamente la cantidad adecuada de recursos para controlar la carga en la aplicación. Los puntos de conexión administrados en línea admiten la escalabilidad automática mediante la integración con la característica de escalabilidad automática de Azure Monitor. Para configurar el escalado automático, vea Escalado automático de puntos de conexión en línea.
# update definition of the deployment
green_deployment.instance_count = 2
# update the deployment
# expect the deployment to take approximately 8 to 10 minutes
ml_client.online_deployments.begin_create_or_update(green_deployment).result()
Actualización de la asignación de tráfico para implementaciones
Puede dividir el tráfico de producción entre las implementaciones. Es posible que primero quiera probar la greenimplementación con datos de ejemplo, al igual que hizo con la implementación blue. Una vez que haya probado la implementación verde, asígnele un pequeño porcentaje de tráfico:
endpoint.traffic = {"blue": 80, "green": 20}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Pruebe la asignación de tráfico invocando el punto de conexión varias veces:
# You can invoke the endpoint several times
for i in range(30):
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
)
Muestre los registros de la implementación green para comprobar que hubo solicitudes entrantes y que el modelo se puntuó correctamente.
logs = ml_client.online_deployments.get_logs(
name="green", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Ver métricas con Azure Monitor
Puede ver varias métricas (número de solicitudes, latencia de solicitudes, bytes de red, uso de CPU/GPU/Disco/Memoria y más) para un punto de conexión en línea y sus implementaciones mediante los siguientes enlaces de la página Detalles del punto de conexión en el Studio. Después de cualquiera de estos vínculos, se le lleva a la página de métricas exactas de Azure Portal para el punto de conexión o la implementación.

Si abre las métricas del punto de conexión en línea, puede configurar la página para ver métricas como la latencia media de las solicitudes, como se muestra en la siguiente ilustración.

Para más información sobre cómo ver las métricas de puntos de conexión en línea, consulte Supervisión de puntos de conexión en línea.
Enviar todo el tráfico a la nueva implementación
Cuando esté plenamente satisfecho con la implementación green, cambie todo el tráfico a ella.
endpoint.traffic = {"blue": 0, "green": 100}
ml_client.begin_create_or_update(endpoint).result()
Eliminar la implementación antigua
Eliminar la implementación antigua (azul):
ml_client.online_deployments.begin_delete(
name="blue", endpoint_name=online_endpoint_name
).result()
Limpieza de recursos
Si no va a usar el punto de conexión y la implementación después de completar este tutorial, debe eliminarlos.
Nota:
El proceso de eliminación tardará aproximadamente 20 minutos.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name).result()
Eliminar todo el contenido
Siga estos pasos para eliminar el área de trabajo de Azure Machine Learning y todos los recursos de proceso.
Importante
Los recursos que creó pueden usarse como requisitos previos para otros tutoriales y artículos de procedimientos de Azure Machine Learning.
Si no va a usar ninguno de los recursos que ha creado, elimínelos para no incurrir en cargos:
En Azure Portal, en el cuadro de búsqueda, escriba Grupos de recursos y selecciónelo en los resultados.
En la lista, seleccione el grupo de recursos que creó.
En la página Información general, seleccione Eliminar grupo de recursos.
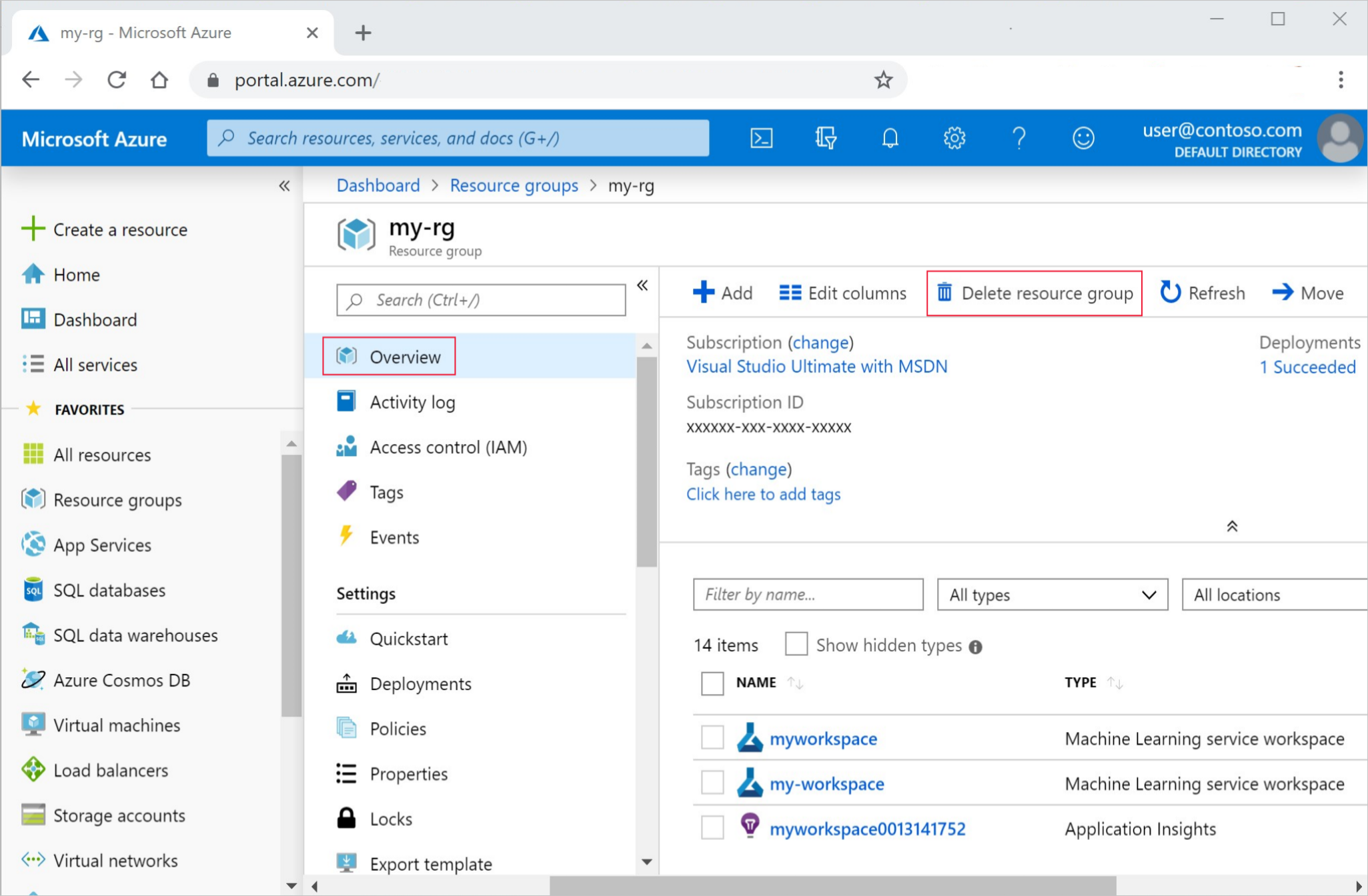
Escriba el nombre del grupo de recursos. A continuación, seleccione Eliminar.