Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este tutorial, aprenderá a entrenar un modelo de clasificación con aprendizaje automático automatizado (AutoML) sin código mediante Azure Machine Learning en el Estudio de Azure Machine Learning. Este modelo de clasificación predice si un cliente suscribirá un depósito a plazo fijo con una institución financiera.
Con el aprendizaje automático automatizado, puede automatizar las tareas que requieren mucho tiempo. El aprendizaje automático recorre en iteración rápidamente muchas combinaciones de algoritmos e hiperparámetros para ayudarle a encontrar el mejor modelo según una métrica de éxito de su elección.
No escribirá ningún código en este tutorial. Use la interfaz de Studio para realizar el entrenamiento. Aprenderá a realizar las siguientes tareas:
- Creación de un área de trabajo de Azure Machine Learning
- Ejecución de un experimento de aprendizaje automático automatizado
- Explorar los detalles del modelo
- Implementar el modelo recomendado
Requisitos previos
Suscripción a Azure. Si no tiene una suscripción a Azure, cree una cuenta gratuita.
Descargue el archivo de datos bankmarketing_train.csv. La columna y indica si un cliente se ha suscrito a un depósito a plazo fijo, que se identifica más adelante como la columna de destino para las predicciones de este tutorial.
Nota:
Este conjunto de conjuntos de marketing bancario está disponible bajo licencia de Creative Commons (CCO: dominio público). Todos los derechos de los contenidos individuales de la base de datos tienen la licencia Database Contents License y están disponibles en Kaggle. Este conjunto de datos estaba disponible originalmente en la base de datos de aprendizaje automático de UCI.
[Moro et al., 2014] S. Moro, P. Cortez y P. Rita. Un enfoque Data-Driven para prever el éxito del telemarketing bancario. Sistemas de apoyo a la decisión, Elsevier, 62:22-31, junio de 2014.
Creación de un área de trabajo
Un área de trabajo de Azure Machine Learning es un recurso básico de la nube que se usa para experimentar, entrenar e implementar modelos de aprendizaje automático. Vincula la suscripción y el grupo de recursos de Azure con un objeto fácilmente consumido del servicio.
Complete los pasos siguientes para crear un área de trabajo y continuar con el tutorial.
Inicie sesión en Azure Machine Learning Studio.
Seleccione Crear área de trabajo.
Especifique la siguiente información para configurar la nueva área de trabajo:
Campo Descripción Nombre del área de trabajo Escriba un nombre único que identifique el área de trabajo. Los nombres deben ser únicos en el grupo de recursos. Utilice un nombre que sea fácil de recordar y que se diferencie del de las áreas de trabajo creadas por otros. El nombre del área de trabajo no distingue mayúsculas de minúsculas. Suscripción Seleccione la suscripción de Azure que quiera usar. Grupo de recursos Use un grupo de recursos existente en su suscripción o escriba un nombre para crear un nuevo grupo de recursos. Un grupo de recursos almacena los recursos relacionados con una solución de Azure. Necesita el rol colaborador o propietario para usar un grupo de recursos existente. Para obtener más información, consulte Administración del acceso a un área de trabajo de Azure Machine Learning. Región Seleccione la región de Azure más cercana a los usuarios y los recursos de datos para crear el área de trabajo. Seleccione Crear para crear el área de trabajo.
Para obtener más información sobre los recursos de Azure, consulte Creación del área de trabajo.
Para otras formas de crear un área de trabajo en Azure, administre áreas de trabajo de Azure Machine Learning en el portal o con el SDK de Python (v2).
Creación de un trabajo de Machine Learning automatizado
Complete los siguientes pasos de configuración y ejecución del experimento mediante Estudio de Azure Machine Learning en https://ml.azure.com. Estudio de Machine Learning es una interfaz web consolidada que incluye herramientas de aprendizaje automático para realizar escenarios de ciencia de datos para los profesionales de ciencia de datos con conocimientos de todos los niveles. Studio no se admite en Internet Explorer.
Seleccione la suscripción y el área de trabajo que ha creado.
En el panel de navegación, seleccione Creación>Aprendizaje automático automatizado.
Como este tutorial es su primer experimento de aprendizaje automático automatizado, verá una lista vacía y vínculos a la documentación.
Seleccione Nuevo trabajo de ML automatizado.
En Método de entrenamiento, seleccione Entrenar automáticamente y, a continuación, seleccione Iniciar configuración del trabajo.
En Configuración básica, seleccione Crear nuevo y, a continuación, en Nombre del experimento, escriba my-1st-automl-experiment.
Seleccione Siguiente para cargar el conjunto de datos.

Creación y carga de un conjunto de datos como un recurso de datos
Antes de configurar el experimento, cargue el archivo de datos en el área de trabajo en forma de un recurso de datos de Azure Machine Learning. Para este tutorial, puede considerar un recurso de datos como su conjunto de datos para el trabajo de ML automatizado. Así podrá asegurarse de que los datos tienen el formato adecuado para el experimento.
En Tipo de tarea y datos, para Seleccionar tipo de tarea, elija Clasificación.
En Seleccionar datos, elija Crear.
En el formulario Tipo de datos, asígnele un nombre al conjunto de datos y, si lo desea, incluya una descripción.
En Tipo, seleccione Tabular. Actualmente, la interfaz de ML automatizado solo admite TabularDatasets.
Seleccione Siguiente.
En la página Origen de datos, seleccione Desde archivos locales. Seleccione Siguiente.
En Tipo de almacenamiento de destino, seleccione el almacén de datos predeterminado que se configuró automáticamente durante la creación del área de trabajo: workspaceblobstore. Cargue el archivo de datos en esta ubicación para que esté disponible para el área de trabajo.
Seleccione Siguiente.
En Selección de archivos o carpetas, seleccione Cargar archivos o carpetas>Cargar archivos.
Seleccione el archivo bankmarketing_train.csv en el equipo local. Descargó este archivo como requisito previo.
Seleccione Siguiente.
Cuando finalice la carga, el área Vista previa de datos se rellenará en función del tipo de archivo.
En el formulario Configuración, revise los valores de los datos. Seleccione Siguiente.
Campo Descripción Valor para el tutorial Formato de archivo Define el diseño y el tipo de datos almacenados en un archivo. Delimitado Delimitador Uno o más caracteres para especificar el límite entre regiones independientes en texto sin formato u otros flujos de datos. Coma Codificación Identifica qué tabla de esquema de bit a carácter se va a usar para leer el conjunto de elementos. UTF-8 Encabezados de columna Indica cómo se tratan los encabezados del conjunto de datos, si existen. Todos los archivos tienen los mismos encabezados Omitir filas Indica el número de filas, si hay alguna, que se omiten en el conjunto de datos. Ninguno El formulario Scheme (Esquema) permite una configuración adicional de los datos para este experimento. En este ejemplo, seleccione el conmutador de alternancia de la característica day_of_week para excluirla. Seleccione Siguiente.
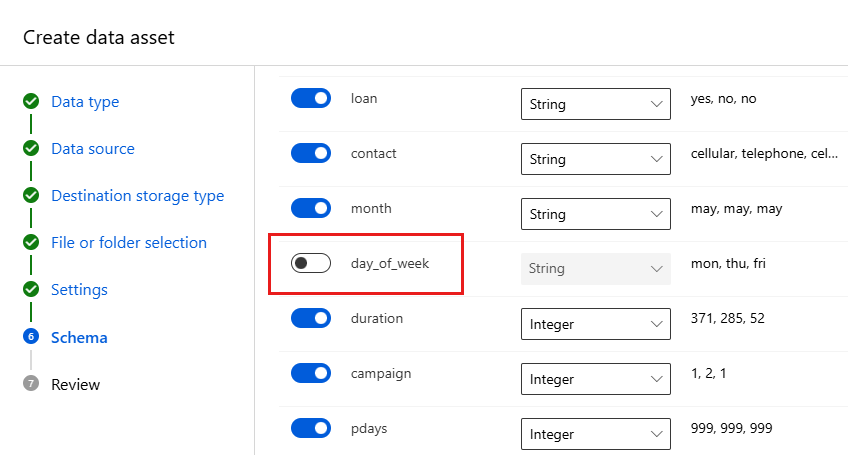
En el formulario Revisar, compruebe la información y, a continuación, seleccione Crear.
Seleccione el conjunto de datos de la lista.
Revise los datos seleccionando el recurso de datos y examinando la pestaña vista previa. Asegúrese de que no incluir day_of_week y seleccione Cerrar.
Seleccione Siguiente para continuar con la configuración de la tarea.
Configurar trabajo
Una vez cargados y configurados los datos, puede configurar el experimento. Este programa de instalación incluye tareas de diseño de experimentos, como la selección del tamaño del entorno de proceso y la especificación de la columna que se quiere predecir.
Rellene el formulario Configuración de tareas de la manera siguiente:
Seleccione y (String) como columna de destino, que es lo que desea predecir. Esta columna indica si el cliente se suscribió a un depósito a plazo o no.
Seleccione View additional configuration settings (Ver opciones de configuración adicionales) y rellene los campos como se indica a continuación. Esta configuración es para controlar mejor el trabajo de entrenamiento. De lo contrario, los valores predeterminados se aplican en función de la selección y los datos del experimento.
Configuraciones adicionales Descripción Valor para el tutorial Métrica principal Métrica de evaluación usada para medir el algoritmo de aprendizaje automático. AUCWeighted Explicación del mejor modelo Muestra automáticamente la posible explicación relativa al mejor modelo creado mediante ML automatizado. Habilitar Modelos bloqueados Algoritmos que desea excluir del trabajo de entrenamiento. Ninguno Seleccione Guardar.
En Validar y probar:
- Para el Tipo de validación, seleccione validación cruzada de k iteraciones.
- En Número de validaciones cruzadas, seleccione 2.
Seleccione Siguiente.
Seleccione clúster de proceso como tipo de proceso.
Un destino de proceso es un entorno de recursos locales o en la nube que se usa para ejecutar el script de entrenamiento o para hospedar la implementación de un servicio. Para este experimento, puede probar un proceso sin servidor basado en la nube (versión preliminar) o crear su propio proceso basado en la nube.
Nota:
Para usar un proceso sin servidor, habilite la característica en vista previa (GB), seleccione Sin servidor y omita este procedimiento.
Para crear su propio destino de proceso, en Seleccionar tipo de proceso, seleccione Clúster de proceso para configurar el destino de proceso.
Rellene el formulario Máquina virtual para configurar el proceso. Seleccione Nuevo.
Campo Descripción Valor para el tutorial Ubicación La región desde la que desea ejecutar la máquina Oeste de EE. UU. 2 Nivel de máquina virtual Seleccione qué prioridad debe tener el experimento. Dedicado Tipo de máquina virtual Seleccione el tipo de máquina virtual del proceso. CPU (Unidad central de procesamiento) Tamaño de la máquina virtual Seleccione el tamaño de la máquina virtual para el proceso. Se proporciona una lista de los tamaños recomendados en función de los datos y el tipo de experimento. Standard_DS12_V2 Seleccione Siguiente para ir al formulario Configuración avanzada.
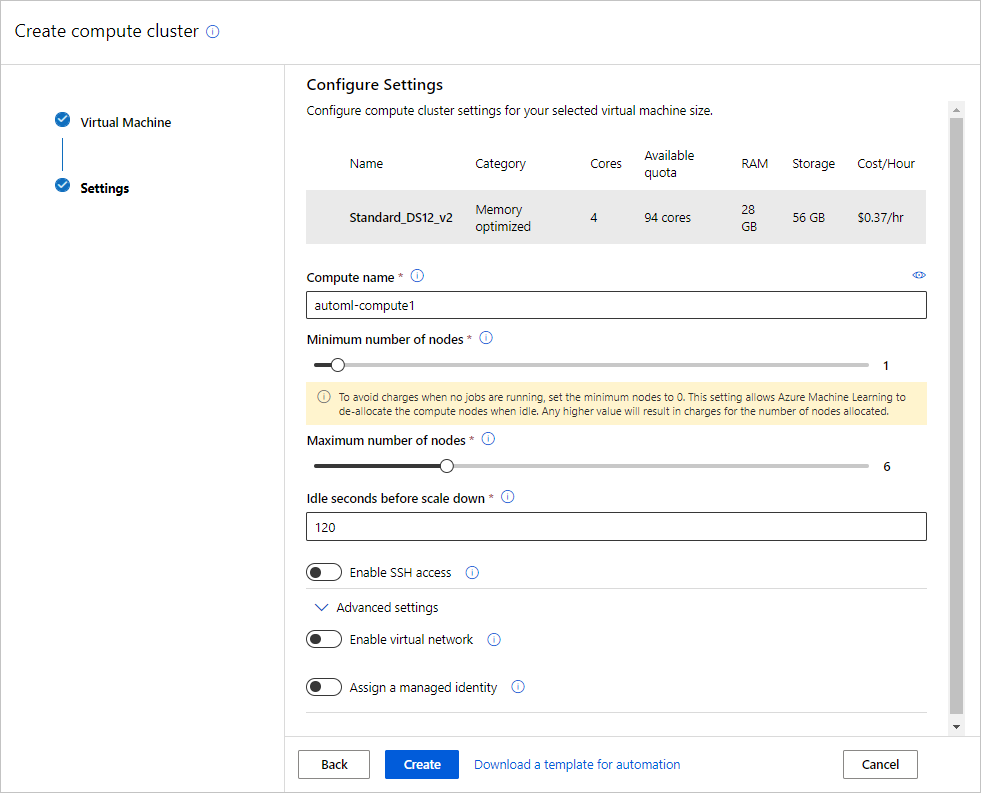
Campo Descripción Valor para el tutorial Nombre del proceso Un nombre único que identifique el contexto del proceso. automl-compute Nodos mín./máx. Para generar perfiles de datos, debe especificar uno o más nodos. Número mínimo de nodos: 1
Número máximo de nodos: 6Segundos de inactividad antes de la reducción vertical Tiempo de inactividad antes de que el clúster se reduzca verticalmente de manera automática hasta el número mínimo de nodos. 120 (valor predeterminado) Configuración avanzada Valores para configurar y autorizar una red virtual para el experimento. Ninguno Seleccione Crear.
La creación de un proceso puede tardar unos minutos en completarse.
Después de la creación, seleccione el nuevo destino de proceso de la lista. Seleccione Siguiente.
Seleccione Enviar trabajo de entrenamiento para ejecutar el experimento. La pantalla Información general se abre con el Estado en la parte superior mientras comienza la preparación del experimento. Este estado se actualiza a medida que el experimento progresa. También aparecen notificaciones en Estudio para informarle del estado de su experimento.

Importante
La preparación necesita de 10 a 15 minutos en preparar la ejecución del experimento. Una vez que se ejecuta, se tarda de 2 a 3 minutos más para cada iteración.
En producción, probablemente puede descansar un poco. Pero para este tutorial, puede empezar a explorar los algoritmos probados en la pestaña Modelos a medida que se completan mientras los demás continúan ejecutándose.
Exploración de modelos
Vaya a la pestaña Models y trabajos secundarios para ver los algoritmos (modelos) probados. De manera predeterminada, el trabajo ordena los modelos por puntuación de métrica a medida que se completan. Para este tutorial, el modelo con la mayor puntuación según la métrica AUCWeighted elegida aparece en la parte superior de la lista.
Mientras espera a que terminen todos los modelos del experimento, seleccione Algorithm name (Nombre de algoritmo) de un modelo completado para explorar los detalles de rendimiento. Seleccione las pestañas Información general y Métricas para obtener información sobre el trabajo.
La siguiente animación ve las propiedades, las métricas y los gráficos de rendimiento del modelo seleccionado.

Ver explicaciones del modelo
Mientras espera a que terminen los modelos, puede echar un vistazo a las explicaciones de estos y ver qué características de datos (sin o con diseño) han influido en las predicciones de un modelo determinado.
Estas explicaciones del modelo se pueden generar a petición. El panel de explicaciones del modelo que forma parte de la pestaña Explicaciones (versión preliminar) resume estas explicaciones.
Para generar explicaciones del modelo:
En los vínculos de navegación de la parte superior de la página, seleccione el nombre del trabajo para volver a la pantalla Modelos.
Seleccione la pestaña Modelos y trabajos secundarios.
En este tutorial, seleccione el primer modelo MaxAbsScaler, LightGBM.
Seleccione Explicar modelo. A la derecha aparece el panel Explicar modelo.
Seleccione el tipo de proceso y, a continuación, seleccione la instancia o el clúster: automl-compute que creó anteriormente. Este proceso inicia un trabajo secundario para generar las explicaciones del modelo.
Seleccione Crear. Aparece un mensaje de operación correcta en verde.
Nota:
El trabajo de la explicación tarda entre dos y cinco minutos en terminar.
Seleccione Explicaciones (vista previa). Esta pestaña se rellena una vez completada la ejecución de la explicación.
A la izquierda, expanda el panel. En Características, seleccione la fila que indica sin procesar.
Seleccione la pestaña Agregar importancia de la característica. Este gráfico muestra qué características de datos han influido en las predicciones del modelo seleccionado.
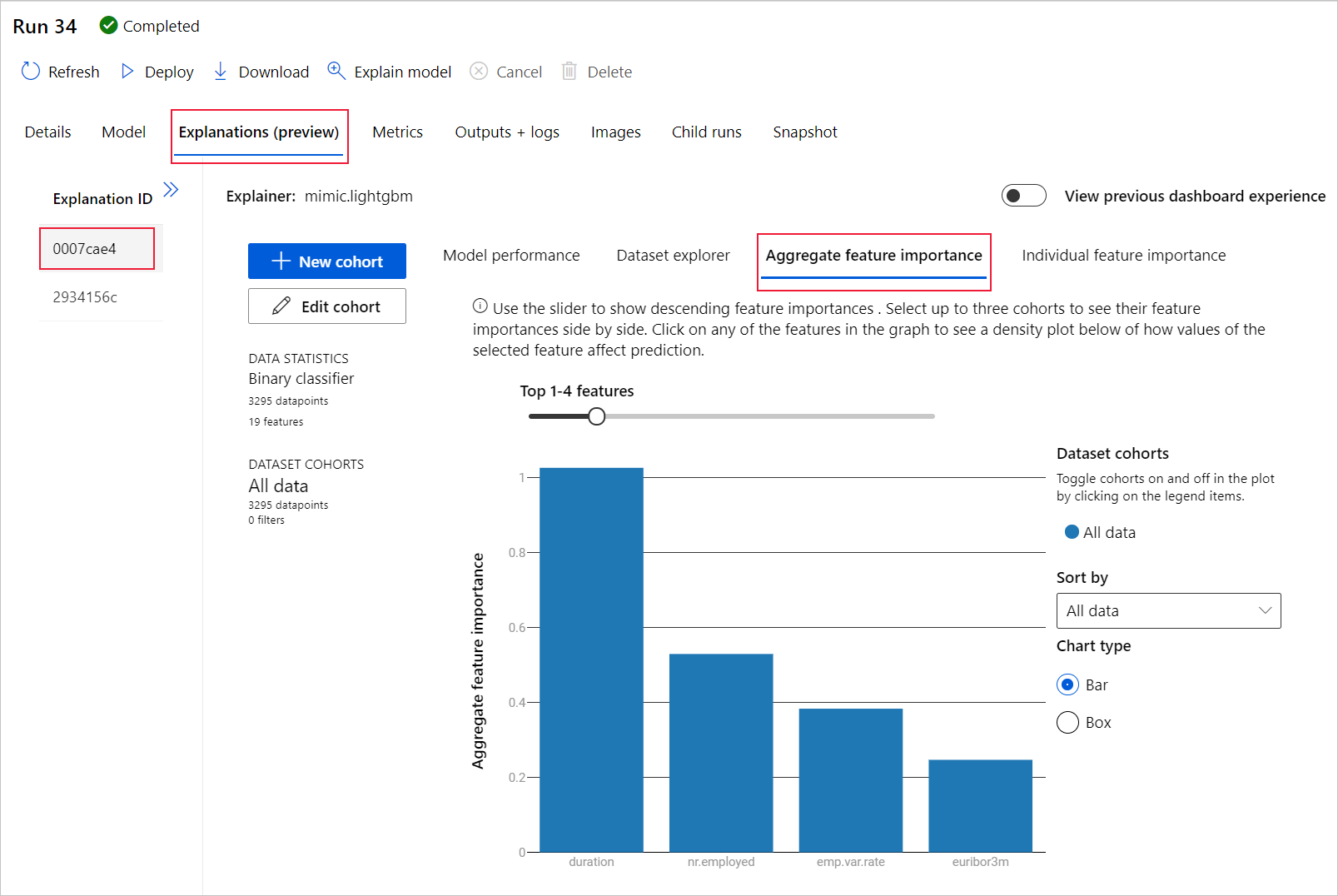
En este ejemplo, la duración parece haber influido más en las predicciones de este modelo.

Implementación del mejor modelo
La interfaz del aprendizaje automático automatizado permite implementar el mejor modelo como un servicio web. La implementación es la integración del modelo para que pueda predecir datos nuevos e identificar posibles áreas de oportunidad. En este experimento, la implementación em un servicio web significa que la institución financiera tiene ahora una solución web iterativa y escalable para identificar posibles clientes de depósitos a plazo fijo.
Compruebe si la ejecución del experimento ha finalizado. Para ello, seleccione el nombre del trabajo en la parte superior de la pantalla para volver a la página del trabajo primario. Se muestra un estado Completed (Completado) en la esquina superior izquierda de la pantalla.
Una vez completada la ejecución del experimento, la página Detalles se rellena con una sección Mejor resumen del modelo. En el contexto de este experimento, VotingEnsemble se considera el mejor modelo, según la métrica AUCWeighted.
Implemente este modelo. La implementación tarda unos 20 minutos en completarse. El proceso de implementación conlleva varios pasos, como el registro del modelo, la generación de recursos y su configuración para el servicio web.
Seleccione VotingEnsemble para abrir la página específica del modelo.
Seleccione Implementar>Servicio web.
Rellene el panel Deploy Model (Implementar modelo) como se indica a continuación:
Campo Valor Nombre my-automl-deploy Descripción Implementación de mi primer experimento de aprendizaje automático automatizado Compute type (Tipo de proceso) Seleccione Azure Container Instance Enable authentication (Habilitar autenticación) Deshabilitar. Use custom deployment assets (Usar recursos de implementación personalizados) Deshabilitar. Permite que se generen automáticamente el archivo de controlador predeterminado (script de puntuación) y el archivo de entorno. En este ejemplo, use los valores predeterminados que se proporcionan en el menú Avanzado.
Seleccione Implementar.
Aparece un mensaje de operación correcta en verde en la parte superior de la pantalla Trabajo. En el panel Resumen del modelo, aparece un mensaje de estado en Estado de implementación. Seleccione Refresh (Actualizar) periódicamente para comprobar el estado de la implementación.
Tiene un servicio web operativo para generar predicciones.
Continúe con Contenido relacionado para obtener más información sobre el consumo del nuevo servicio web y para probar las predicciones con la compatibilidad con Azure Machine Learning incorporada en Power BI.
Limpieza de recursos
Los archivos de implementación son mayores que los archivos de datos y del experimento, por lo que cuesta más almacenarlos. Si desea conservar el área de trabajo y los archivos del experimento, elimine solo los archivos de implementación para minimizar costos en su cuenta. Elimine todo el grupo de recursos completo si no planea usar ninguno de los archivos.
Eliminación de la instancia de implementación
Elimine solo de la instancia de implementación de Azure Machine Learning en https://ml.azure.com/.
Vaya a Azure Machine Learning. Vaya al área de trabajo y en el panel Recursos, seleccione Puntos de conexión.
Seleccione la implementación que desea eliminar y seleccione Eliminar.
Seleccione Continuar.
Eliminar el grupo de recursos
Importante
Los recursos que creó pueden usarse como requisitos previos para otros tutoriales y artículos de procedimientos de Azure Machine Learning.
Si no va a usar ninguno de los recursos que ha creado, elimínelos para no incurrir en cargos:
En Azure Portal, en el cuadro de búsqueda, escriba Grupos de recursos y selecciónelo en los resultados.
En la lista, seleccione el grupo de recursos que creó.
En la página Información general, seleccione Eliminar grupo de recursos.
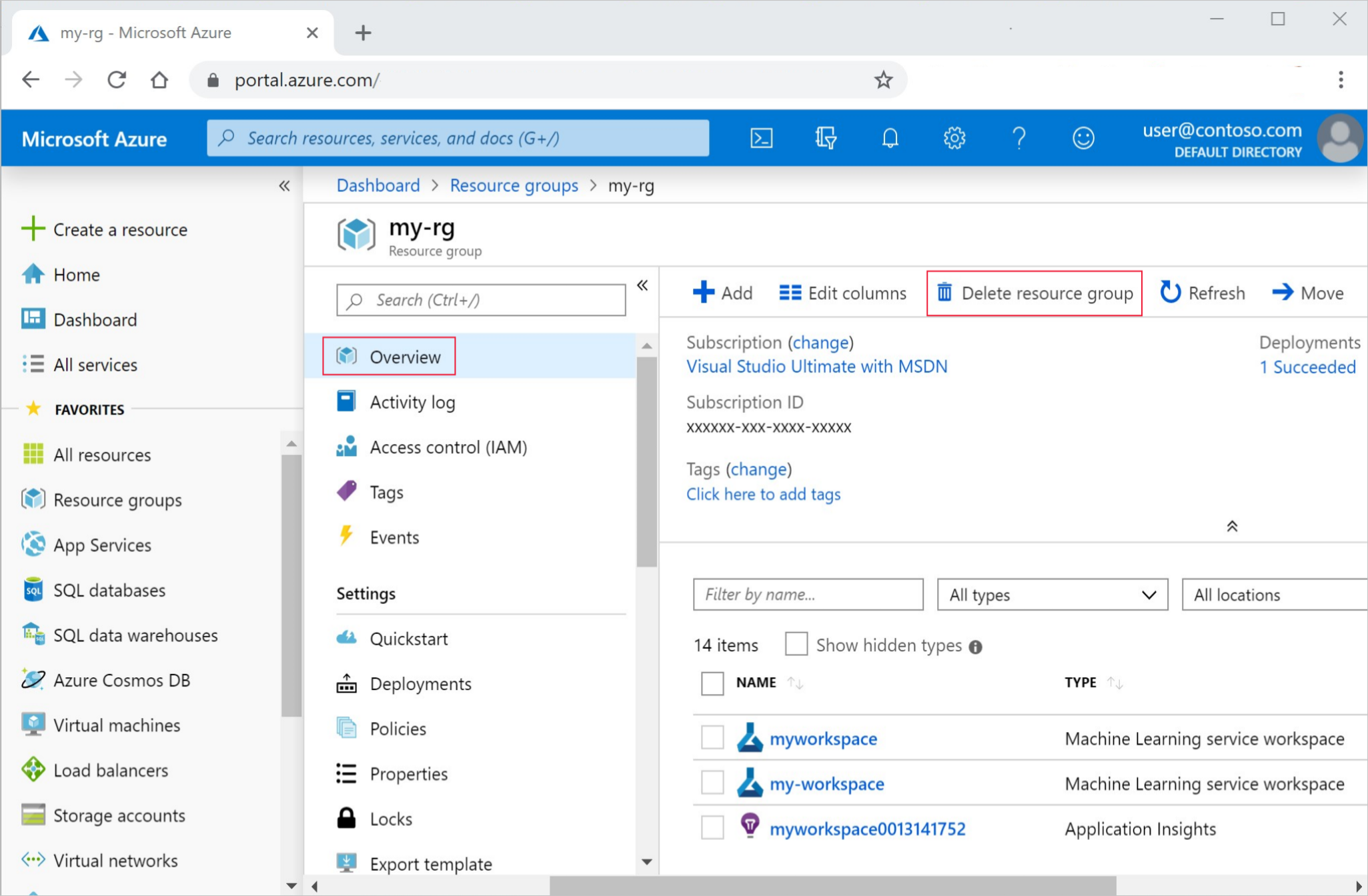
Escriba el nombre del grupo de recursos. A continuación, seleccione Eliminar.
Contenido relacionado
En este tutorial ha usado la interfaz de aprendizaje automático automatizado de Azure Machine Learning para crear e implementar un modelo de clasificación. Para obtener más información y los pasos siguientes, consulte estos recursos:
- Más información acerca del aprendizaje automático automatizado.
- Obtenga información sobre las métricas y gráficos de clasificación en el artículo: Evaluación de los resultados del experimento de aprendizaje automático automatizado.
- Más información sobre cómo configurar AutoML para NLP.
Pruebe también el aprendizaje automático automatizado para estos otros tipos de modelos:
- Para obtener un ejemplo de previsión sin código, consulte Tutorial: Previsión de la demanda con aprendizaje automático automatizado sin código en Estudio de Azure Machine Learning.
- Para ver un primer ejemplo de código de un modelo de detección de objetos, consulte Tutorial: Entrenamiento de un modelo de detección de objetos con AutoML y Python.