Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este inicio rápido, aprenderá a usar un recurso GeoCatalog de Microsoft Planetary Computer Pro en Azure Batch para procesar datos geoespaciales a escala.
Azure Batch es un servicio de programación de trabajos basado en la nube que permite ejecutar cargas de trabajo paralelas y de alto rendimiento (HPC) a gran escala. Al combinar Azure Batch con Microsoft Planetary Computer Pro, puede hacer lo siguiente:
- Procesamiento de grandes volúmenes de datos geoespaciales en paralelo en varios nodos de proceso
- Autenticación segura en las API de GeoCatalog mediante identidades administradas
- Escalar o reducir la potencia de procesamiento en función de las necesidades de carga de trabajo
- Automatización de canalizaciones de datos geoespaciales sin administrar la infraestructura
En este inicio rápido se muestra cómo configurar un grupo de Batch con una identidad administrada asignada por el usuario, configurar permisos para acceder a GeoCatalog y ejecutar trabajos que consultan la API de STAC.
Sugerencia
Para obtener información general sobre las opciones de desarrollo de aplicaciones con Microsoft Planetary Computer Pro, consulte Conexión y compilación de aplicaciones con los datos.
Prerrequisitos
Antes de comenzar, asegúrese de cumplir los siguientes requisitos para completar este inicio rápido:
- Una cuenta de Azure con una suscripción activa. Use el vínculo Crear una cuenta de forma gratuita.
- Un recurso de Microsoft Planetary Computer Pro GeoCatalog.
Una máquina Linux con las siguientes herramientas instaladas:
- Azure CLI
-
perlpaquete.
Crear una cuenta de Batch
Cree un grupo de recursos:
az group create \
--name spatiobatchdemo \
--location uksouth
Cree una cuenta de almacenamiento:
az storage account create \
--resource-group spatiobatchdemo \
--name spatiobatchstorage \
--location uksouth \
--sku Standard_LRS
Asigne al Storage Blob Data Contributor usuario actual a la cuenta de almacenamiento:
az role assignment create \
--role "Storage Blob Data Contributor" \
--assignee $(az account show --query user.name -o tsv) \
--scope $(az storage account show --name spatiobatchstorage --resource-group spatiobatchdemo --query id -o tsv)
Cree una cuenta de Batch:
az batch account create \
--name spatiobatch \
--storage-account spatiobatchstorage \
--resource-group spatiobatchdemo \
--location uksouth
Importante
Asegúrese de tener suficiente cuota para crear un grupo de nodos informáticos. Si no tiene cuota suficiente, puede solicitar un aumento siguiendo las instrucciones de la documentación sobre cuotas y límites de Azure Batch .
Inicie sesión en la nueva cuenta de Batch ejecutando el siguiente comando:
az batch account login \
--name spatiobatch \
--resource-group spatiobatchdemo \
--shared-key-auth
Una vez que autentique su cuenta con Batch, los comandos posteriores az batch de esta sesión usarán la cuenta de Batch que usted creó.
Cree una identidad administrada asignada por el usuario:
az identity create \
--name spatiobatchidentity \
--resource-group spatiobatchdemo
Cree un grupo de nodos de proceso mediante Azure Portal:
- En Azure Portal, vaya a la cuenta de Batch y seleccione Grupos:

- Seleccione + Agregar para crear un grupo y seleccione Asignado por el usuario como identidad del grupo:
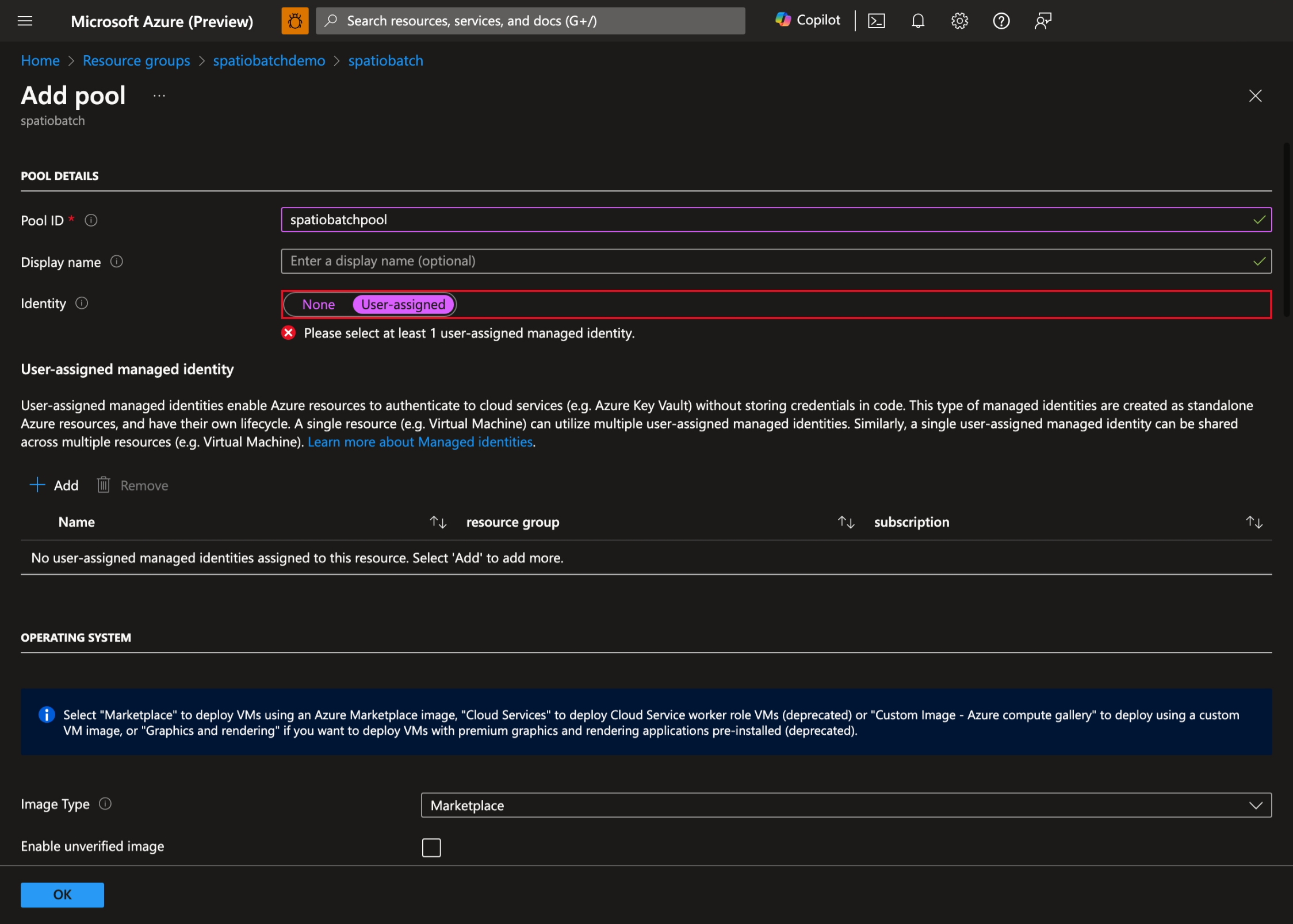
- Seleccione la identidad administrada asignada por el usuario que creó anteriormente:
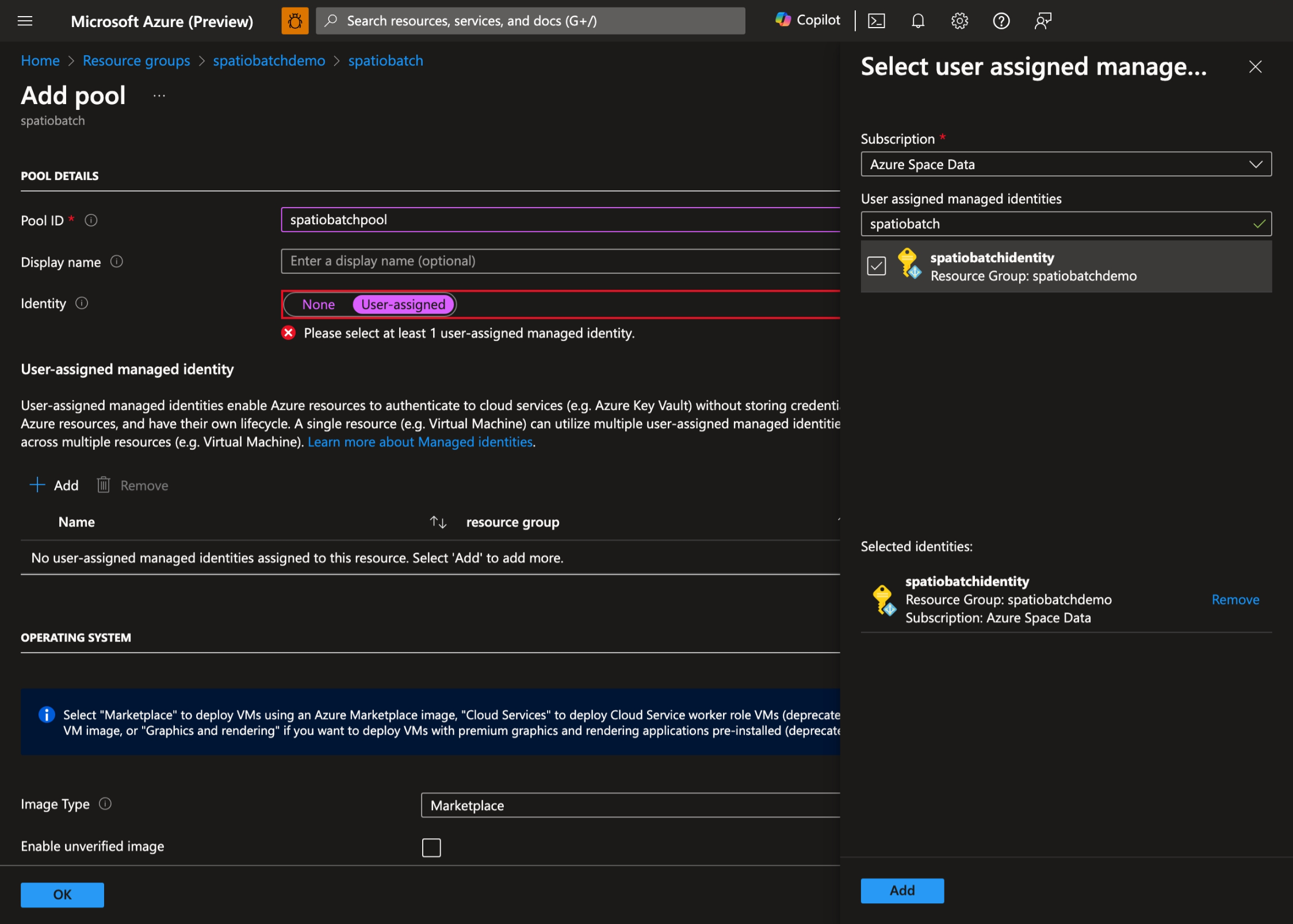
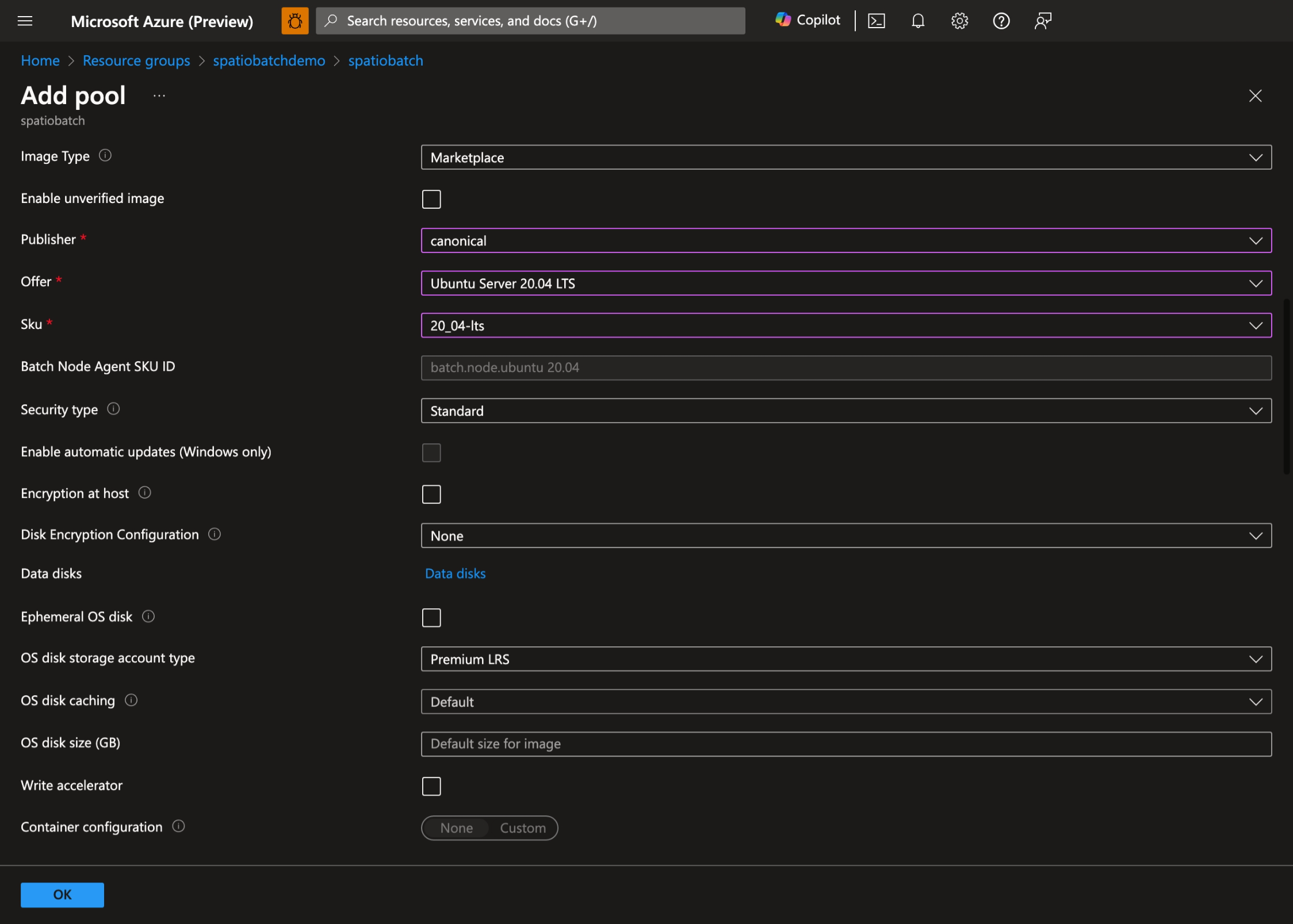
- Seleccione el sistema operativo y el tamaño de máquina virtual preferidos. En esta demostración, usamos Ubuntu Server 20.04 LTS:
- Habilite la Tarea Iniciar, establezca la siguiente Línea de comandos:
bash -c "apt-get update && apt-get install jq python3-pip -y && curl -sL https://aka.ms/InstallAzureCLIDeb | bash"y establezca Nivel de elevación en Usuario automático del grupo, Administrador: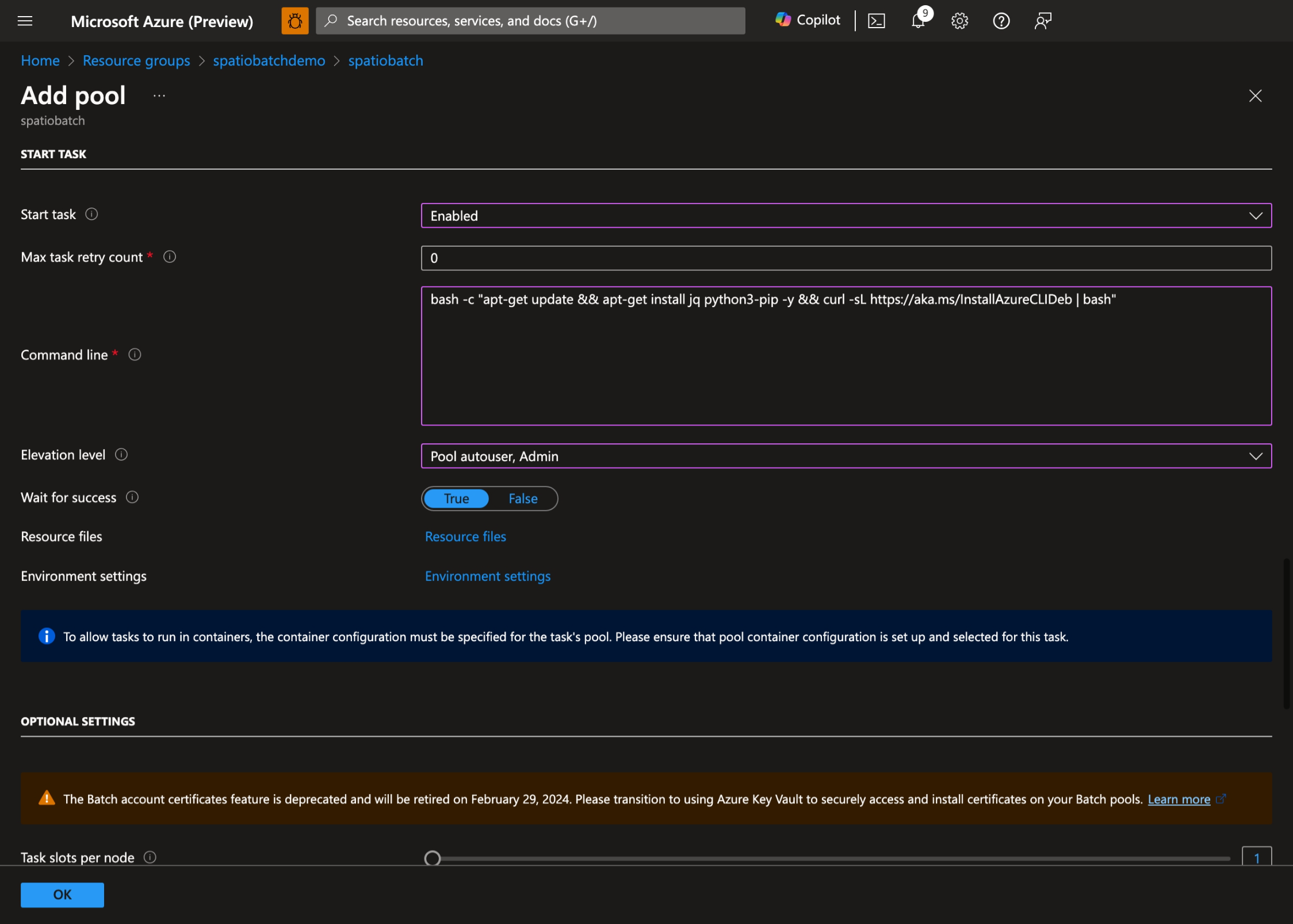
- Seleccione Aceptar para crear el grupo.





Asignar permisos a la identidad administrada
Debe proporcionar acceso a la identidad administrada a GeoCatalog. Vaya a GeoCatalog, seleccione Control de acceso (IAM) y seleccione Agregar asignación de roles:

Seleccione el rol adecuado en función de sus necesidades, GeoCatalog Administrator o GeoCatalog Reader, y seleccione Siguiente:

Seleccione la identidad administrada que creó y, a continuación, seleccione Revisar y asignar.

Preparar el trabajo por lotes
Cree un contenedor en la cuenta de almacenamiento:
az storage container create \
--name scripts \
--account-name spatiobatchstorage
Cargue el script en el contenedor:
az storage blob upload \
--container-name scripts \
--file src/task.py \
--name task.py \
--account-name spatiobatchstorage
Ejecute los trabajos por lotes
Hay dos ejemplos en este inicio rápido: un script de Python y un script de Bash. Puede usar cualquiera de ellos para crear un trabajo.
Trabajo de script de Python
Para ejecutar el trabajo de script de Python, ejecute los siguientes comandos:
geocatalog_url="<geocatalog url>"
token_expiration=$(date -u -d "30 minutes" "+%Y-%m-%dT%H:%M:%SZ")
python_task_url=$(az storage blob generate-sas --account-name spatiobatchstorage --container-name scripts --name task.py --permissions r --expiry $token_expiration --auth-mode login --as-user --full-uri -o tsv)
cat src/pythonjob.json | perl -pe "s,##PYTHON_TASK_URL##,$python_task_url,g" | perl -pe "s,##GEOCATALOG_URL##,$geocatalog_url,g" | az batch job create --json-file /dev/stdin
El trabajo de Python ejecuta el siguiente script de Python:
import json
from os import environ
import requests
from azure.identity import DefaultAzureCredential
MPCPRO_APP_ID = "https://geocatalog.spatio.azure.com"
credential = DefaultAzureCredential()
access_token = credential.get_token(f"{MPCPRO_APP_ID}/.default")
geocatalog_url = environ["GEOCATALOG_URL"]
response = requests.get(
f"{geocatalog_url}/stac/collections",
headers={"Authorization": "Bearer " + access_token.token},
params={"api-version": "2025-04-30-preview"},
)
print(json.dumps(response.json(), indent=2))
Que usa DefaultAzureCredential para autenticarse con la identidad administrada y recupera las colecciones de GeoCatalog. Para obtener los resultados del trabajo, ejecute el siguiente comando:
az batch task file download \
--job-id pythonjob1 \
--task-id task1 \
--file-path "stdout.txt" \
--destination /dev/stdout
Trabajo de Bash
Para ejecutar el trabajo de script de Bash, ejecute los siguientes comandos:
geocatalog_url="<geocatalog url>"
cat src/bashjob.json | perl -pe "s,##GEOCATALOG_URL##,$geocatalog_url,g" | az batch job create --json-file /dev/stdin
El trabajo de Bash ejecuta el siguiente script de Bash:
az login --identity --allow-no-subscriptions > /dev/null
token=$(az account get-access-token --resource https://geocatalog.spatio.azure.com --query accessToken --output tsv)
curl --header \"Authorization: Bearer $token\" $GEOCATALOG_URL/stac/collections | jq
Que usa az login --identity para autenticarse con la identidad administrada y recupera las colecciones de GeoCatalog. Para obtener los resultados del trabajo, ejecute el siguiente comando:
az batch task file download \
--job-id bashjob1 \
--task-id task1 \
--file-path "stdout.txt" \
--destination /dev/stdout
Contenido relacionado
- Conectar y desarrollar aplicaciones con tus datos
- Configuración de la autenticación de aplicaciones para Microsoft Planetary Computer Pro
- Compilación de una aplicación web con Microsoft Planetary Computer Pro
- Uso del Explorador de Microsoft Planetary Computer Pro
- Administrar el acceso a Microsoft Planetary Computer Pro
- Configuración de identidades administradas en grupos de Batch
- Copia aplicaciones y datos a nodos de grupo
- Desplegar aplicaciones en nodos de cómputo con paquetes de aplicaciones de Batch
- Creación y uso de archivos de recursos