Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Los agentes de inteligencia artificial transforman la forma en que las aplicaciones interactúan con los datos mediante la combinación de modelos de lenguaje grande (LLM) con herramientas y bases de datos externas. Los agentes permiten la automatización de flujos de trabajo complejos, mejoran la precisión de la recuperación de información y facilitan las interfaces de lenguaje natural a las bases de datos.
En este artículo se explora cómo crear agentes de inteligencia artificial inteligentes que pueden buscar y analizar los datos en Azure Database for PostgreSQL. Le guía por la configuración, la implementación y las pruebas mediante el uso de un asistente de investigación legal como ejemplo.
¿Qué son los agentes de inteligencia artificial?
Los agentes de inteligencia artificial van más allá de bots de chat simples mediante la combinación de LLM con bases de datos y herramientas externas. A diferencia de los LLM independientes o los sistemas estándar de generación aumentada de recuperación (RAG), los agentes de IA pueden:
- Plan: divida las tareas complejas en pasos secuenciales más pequeños.
- Usar herramientas: Use APIs, ejecución de código y sistemas de búsqueda para recopilar información o realizar acciones.
- Percibir: comprenda y procese las entradas de varios orígenes de datos.
- Recuerde: Almacene y recuerde interacciones anteriores para mejorar la toma de decisiones.
Al conectar agentes de inteligencia artificial a bases de datos como Azure Database for PostgreSQL, los agentes pueden ofrecer respuestas más precisas y compatibles con el contexto en función de los datos. Los agentes de inteligencia artificial se extienden más allá de la conversación humana básica para realizar tareas basadas en lenguaje natural. Estas tareas tradicionalmente requerían lógica codificada. Sin embargo, los agentes pueden planear las tareas necesarias para ejecutarse en función del contexto proporcionado por el usuario.
Implementación de agentes de IA
La implementación de agentes de inteligencia artificial con Azure Database for PostgreSQL implica la integración de funcionalidades avanzadas de inteligencia artificial con funcionalidades de base de datos sólidas para crear sistemas inteligentes y con reconocimiento de contexto. Mediante el uso de herramientas como la búsqueda vectorial, las inserciones y el servicio de agente foundry, los desarrolladores pueden crear agentes que comprendan consultas de lenguaje natural, recuperen datos relevantes y proporcionen información útil.
En las secciones siguientes se describe el proceso paso a paso para configurar, configurar e implementar agentes de IA. Este proceso permite una interacción sin problemas entre los modelos de inteligencia artificial y la base de datos postgreSQL.
Marcos de trabajo
Varios marcos y herramientas pueden facilitar el desarrollo y la implementación de los agentes de inteligencia artificial. Todos estos marcos de trabajo admiten el uso de Azure Database for PostgreSQL como herramienta:
- Servicio del agente
- LangChain/LangGraph
- LlamaIndex
- Kernel semántico
- AutoGen
- API de asistentes de OpenAI
Ejemplo de implementación
En el ejemplo de este artículo se usa Agent Service para la planificación del agente, el uso de herramientas y la percepción. Usa Azure Database for PostgreSQL como herramienta para las funcionalidades de búsqueda semántica y base de datos vectoriales.
Las secciones siguientes le guían a través de la creación de un agente de INTELIGENCIA ARTIFICIAL que ayuda a los equipos legales a investigar casos relevantes para apoyar a sus clientes en el Estado de Washington. El agente:
- Acepta consultas en lenguaje natural sobre situaciones legales.
- Usa la búsqueda de vectores en Azure Database for PostgreSQL para encontrar precedentes de casos relevantes.
- Analiza y resume los hallazgos en un formato útil para profesionales legales.
Prerrequisitos
Habilite y configure las
azure_aiextensiones ypg_vector.Implementación de modelos
gpt-4o-miniytext-embedding-small.Instale Visual Studio Code.
Instale la extensión de Python .
Instale Python 3.11.x.
Instale la CLI de Azure (versión más reciente).
Nota:
Necesita la clave y el punto de conexión de los modelos implementados que ha creado para el agente.
Cómo empezar
Todos los conjuntos de datos de código y ejemplo están disponibles en este repositorio de GitHub.
Paso 1: Configuración de la búsqueda de vectores en Azure Database for PostgreSQL
En primer lugar, prepare la base de datos para almacenar y buscar datos de casos legales mediante incrustaciones de vectores.
Configuración del entorno
Si usa macOS y Bash, ejecute estos comandos:
python -m venv .pg-azure-ai
source .pg-azure-ai/bin/activate
pip install -r requirements.txt
Si usa Windows y PowerShell, ejecute estos comandos:
python -m venv .pg-azure-ai
.pg-azure-ai \Scripts\Activate.ps1
pip install -r requirements.txt
Si usa Windows y cmd.exe, ejecute estos comandos:
python -m venv .pg-azure-ai
.pg-azure-ai \Scripts\activate.bat
pip install -r requirements.txt
Configuración de las variables de entorno
Cree un .env archivo con sus credenciales:
AZURE_OPENAI_API_KEY=""
AZURE_OPENAI_ENDPOINT=""
EMBEDDING_MODEL_NAME=""
AZURE_PG_CONNECTION=""
Carga de documentos y vectores
El archivo de Python load_data/main.py sirve como punto de entrada central para cargar datos en Azure Database for PostgreSQL. El código procesa los datos de los casos de ejemplo, incluida la información sobre los casos en Washington.
El archivo main.py:
- Crea extensiones necesarias, configura la configuración de la API de OpenAI y administra las tablas de base de datos quitando las existentes y creando otras nuevas para almacenar datos de casos.
- Lee los datos de un archivo CSV e los inserta en una tabla temporal y, a continuación, los procesa y lo transfiere a la tabla de casos principal.
- Agrega una nueva columna para inserciones en la tabla de casos y genera inserciones para las opiniones de casos mediante la API de OpenAI. Almacena las inserciones en la nueva columna. El proceso de inserción tarda unos 3 a 5 minutos.
Para iniciar el proceso de carga de datos, ejecute el siguiente comando desde el load_data directorio :
python main.py
Este es el resultado de main.py:
Extensions created successfully
OpenAI connection established successfully
The case table was created successfully
Temp cases table created successfully
Data loaded into temp_cases_data table successfully
Data loaded into cases table successfully.
Adding Embeddings will take a while, around 3-5 mins.
Embeddings added successfully All Data loaded successfully!
Paso 2: Creación de una herramienta postgres para el agente
A continuación, configure las herramientas del agente de IA para recuperar datos de Postgres. A continuación, use el SDK del servicio de agente para conectar el agente de IA a la base de datos de Postgres.
Definición de una función para que la llame su agente
Comience con la definición de una función para que el agente llame mediante la descripción de su estructura y los parámetros necesarios en una docstring. Incluya todas las definiciones de función en un solo archivo legal_agent_tools.py. A continuación, puede importar el archivo en el script principal.
def vector_search_cases(vector_search_query: str, start_date: datetime ="1911-01-01", end_date: datetime ="2025-12-31", limit: int = 10) -> str:
"""
Fetches the case information in Washington State for the specified query.
:param query(str): The query to fetch cases specifically in Washington.
:type query: str
:param start_date: The start date for the search defaults to "1911-01-01"
:type start_date: datetime, optional
:param end_date: The end date for the search, defaults to "2025-12-31"
:type end_date: datetime, optional
:param limit: The maximum number of cases to fetch, defaults to 10
:type limit: int, optional
:return: Cases information as a JSON string.
:rtype: str
"""
db = create_engine(CONN_STR)
query = """
SELECT id, name, opinion,
opinions_vector <=> azure_openai.create_embeddings(
'text-embedding-3-small', %s)::vector as similarity
FROM cases
WHERE decision_date BETWEEN %s AND %s
ORDER BY similarity
LIMIT %s;
"""
# Fetch case information from the database
df = pd.read_sql(query, db, params=(vector_search_query,datetime.strptime(start_date, "%Y-%m-%d"), datetime.strptime(end_date, "%Y-%m-%d"),limit))
cases_json = json.dumps(df.to_json(orient="records"))
return cases_json
Paso 3: Creación y configuración del agente de IA con Postgres
Ahora, configure el agente de IA e intégrelo con la herramienta Postgres. El archivo de Python src/simple_postgres_and_ai_agent.py sirve como punto de entrada central para crear y usar el agente.
El archivo simple_postgres_and_ai_agent.py:
- Inicializa el agente en el proyecto de Foundry con un modelo específico.
- Agrega la herramienta Postgres para la búsqueda de vectores en la base de datos, durante la inicialización del agente.
- Configura un hilo de comunicación. Este hilo se utiliza para enviar mensajes al agente para su procesamiento.
- Procesa la consulta del usuario mediante el agente y las herramientas. El agente puede planear con herramientas para obtener la respuesta correcta. En este caso de uso, el agente llama a la herramienta Postgres basada en la firma de función y docstring para realizar una búsqueda vectorial y recuperar los datos pertinentes para responder a la pregunta.
- Muestra la respuesta del agente a la consulta del usuario.
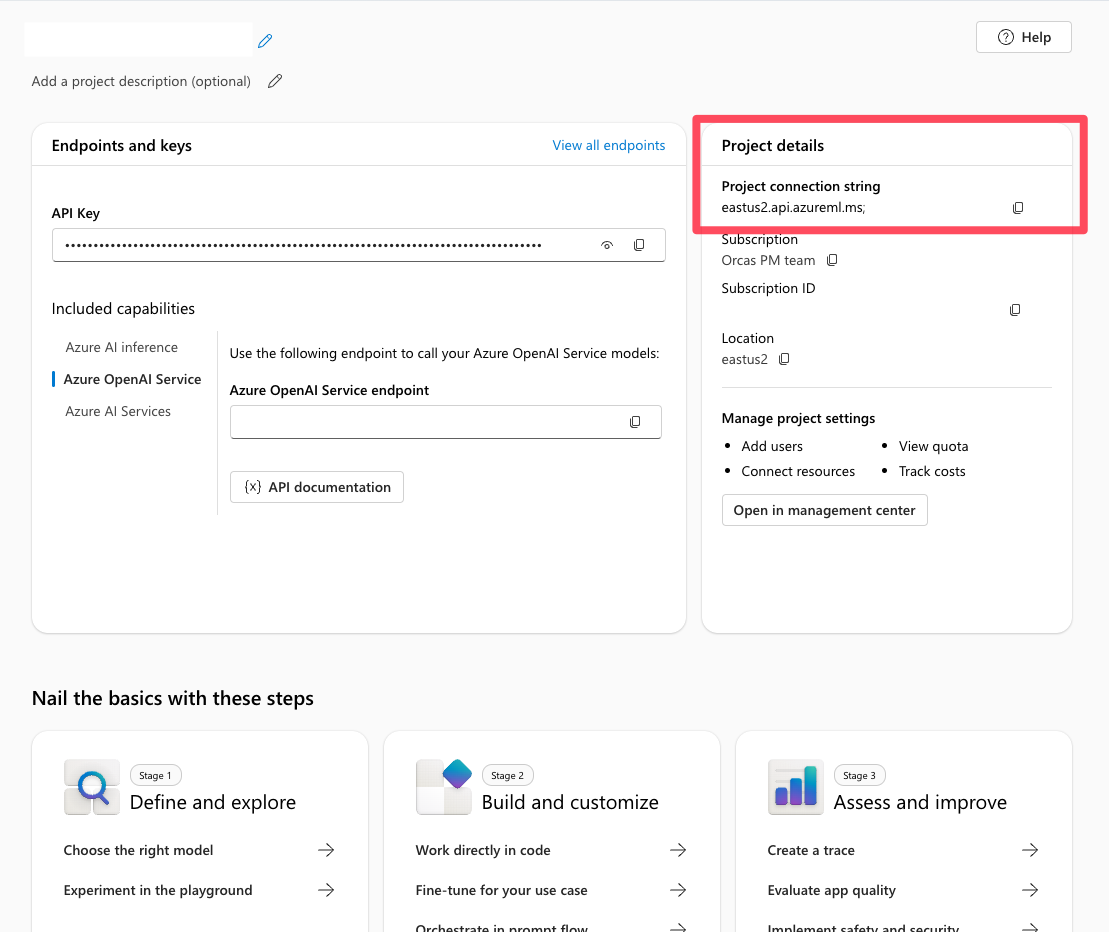
Búsqueda de la cadena de conexión del proyecto en Foundry
En su proyecto Foundry, encontrará la cadena de conexión de su proyecto en la página de resumen del proyecto. Utiliza esta cadena para conectar el proyecto al SDK de servicio de agente. Agregue esta cadena al .env archivo.
Configurar la conexión
Agregue estas variables al .env archivo en el directorio raíz:
PROJECT_CONNECTION_STRING=" "
MODEL_DEPLOYMENT_NAME="gpt-4o-mini"
AZURE_TRACING_GEN_AI_CONTENT_RECORDING_ENABLED="true"
### Create the agent with tool access
We created the agent in the Foundry project and added the Postgres tools needed to query the database. The code snippet below is an excerpt from the file [simple_postgres_and_ai_agent.py](https://github.com/Azure-Samples/postgres-agents/blob/main/azure-ai-agent-service/src/simple_postgres_and_ai_agent.py).
# Create a Foundry client
project_client = AIProjectClient.from_connection_string(
credential=DefaultAzureCredential(),
conn_str=os.environ["PROJECT_CONNECTION_STRING"],
)
# Initialize the agent toolset with user functions
functions = FunctionTool(user_functions)
toolset = ToolSet()
toolset.add(functions)
agent = project_client.agents.create_agent(
model= os.environ["MODEL_DEPLOYMENT_NAME"],
name="legal-cases-agent",
instructions= "You are a helpful legal assistant who can retrieve information about legal cases.",
toolset=toolset
)
Creación de un hilo de comunicación
Este fragmento de código muestra cómo crear un subproceso de agente y un mensaje, que el agente procesa en una ejecución:
# Create a thread for communication
thread = project_client.agents.create_thread()
# Create a message to thread
message = project_client.agents.create_message(
thread_id=thread.id,
role="user",
content="Water leaking into the apartment from the floor above. What are the prominent legal precedents in Washington regarding this problem in the last 10 years?"
)
Procesamiento de la solicitud
El siguiente fragmento de código crea una ejecución para que el agente procese el mensaje y use las herramientas adecuadas para proporcionar el mejor resultado.
Mediante el uso de las herramientas, el agente puede llamar a Postgres y la búsqueda de vectores en la consulta "Se filtra agua en el apartamento desde el piso de arriba" para recuperar los datos que necesita para responder mejor a la pregunta.
from pprint import pprint
# Create and process an agent run in the thread with tools
run = project_client.agents.create_and_process_run(
thread_id=thread.id,
agent_id=agent.id
)
# Fetch and log all messages
messages = project_client.agents.list_messages(thread_id=thread.id)
pprint(messages['data'][0]['content'][0]['text']['value'])
Ejecución del agente
Para ejecutar el agente, ejecute el siguiente comando desde el src directorio :
python simple_postgres_and_ai_agent.py
El agente genera un resultado similar mediante la herramienta Azure Database for PostgreSQL para acceder a los datos de casos guardados en la base de datos de Postgres.
Este es un fragmento de salida del agente:
1. Pham v. Corbett
Citation: Pham v. Corbett, No. 4237124
Summary: This case involved tenants who counterclaimed against their landlord for relocation assistance and breached the implied warranty of habitability due to severe maintenance issues, including water and sewage leaks. The trial court held that the landlord had breached the implied warranty and awarded damages to the tenants.
2. Hoover v. Warner
Citation: Hoover v. Warner, No. 6779281
Summary: The Warners appealed a ruling finding them liable for negligence and nuisance after their road grading project caused water drainage issues affecting Hoover's property. The trial court found substantial evidence supporting the claim that the Warners' actions impeded the natural water flow and damaged Hoover's property.
Paso 4: Prueba y depuración con el área de juegos del agente
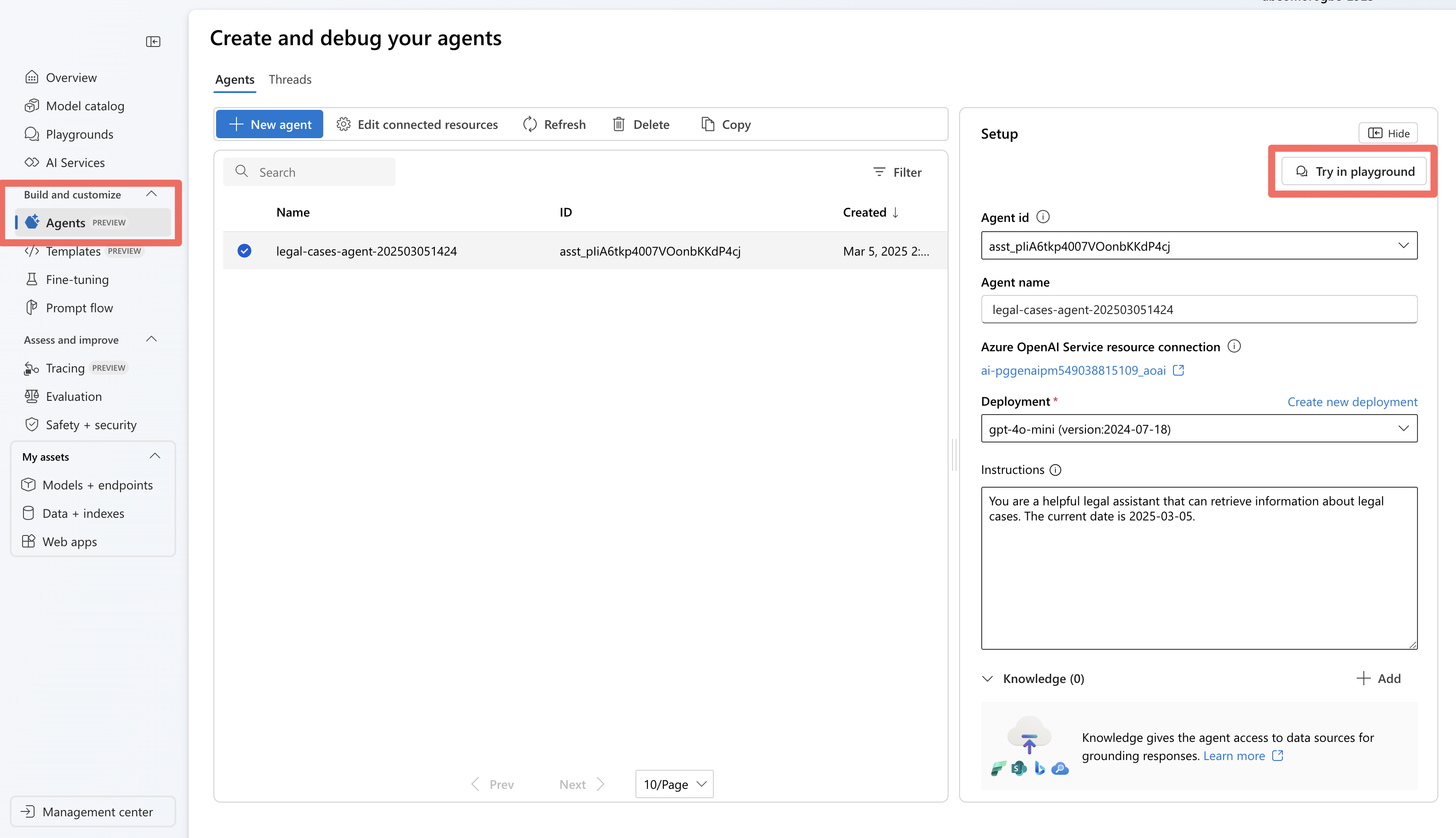
Después de ejecutar el agente mediante el SDK del servicio de agente, el agente se almacena en el proyecto. Puede experimentar con el agente en el área de juegos del agente:
En Foundry, vaya a la sección Agentes .
Busque el agente en la lista y selecciónelo para abrirlo.
Use la interfaz del área de juegos para probar varias consultas legales.
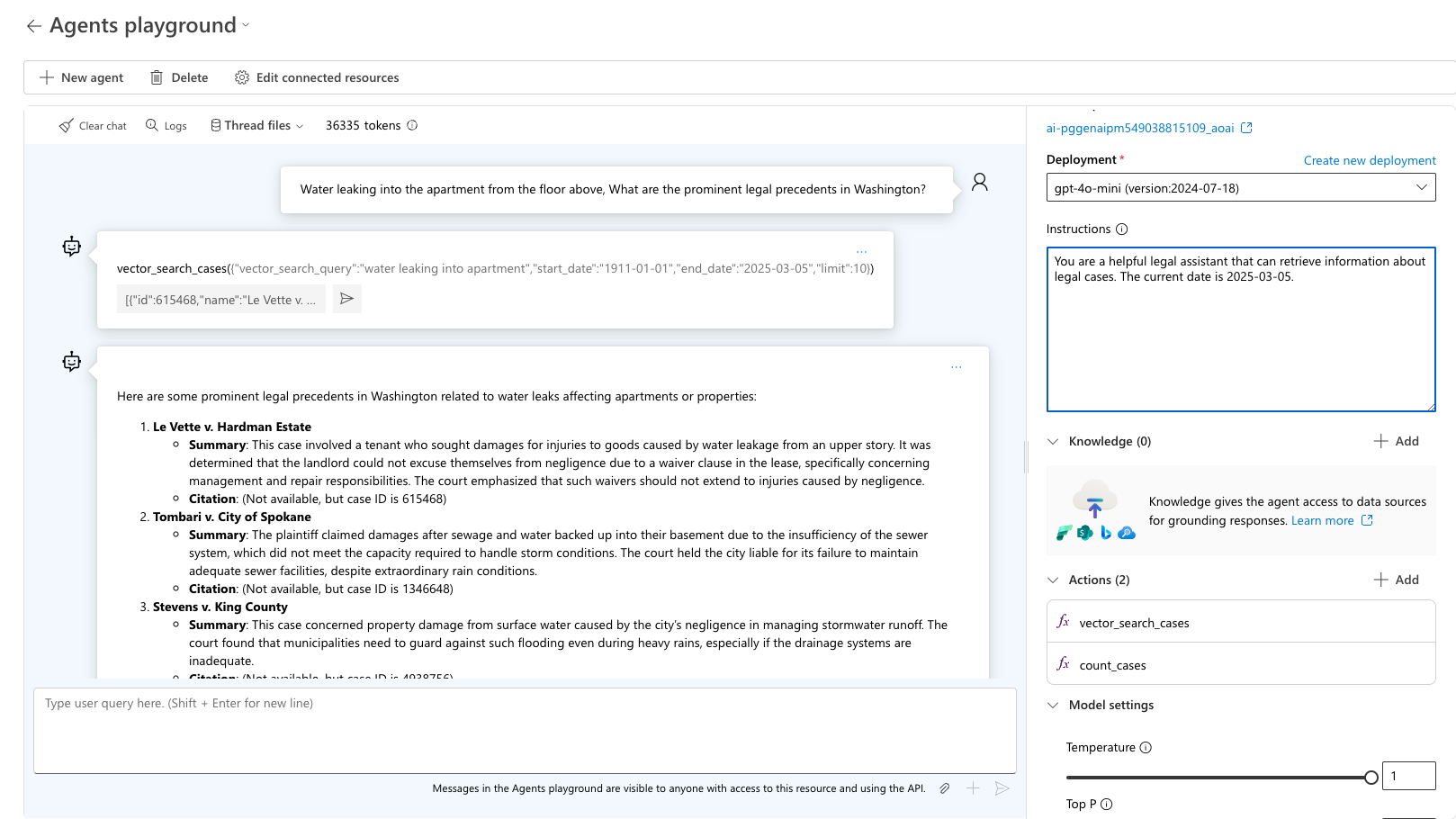
Pruebe la consulta "Agua filtrándose en el apartamento desde el piso de arriba, ¿Cuáles son los precedentes legales destacados en Washington?" El agente elige la herramienta adecuada para usar y pregunta por el resultado esperado de esa consulta. Use sample_vector_search_cases_output.json como salida de ejemplo.
Paso 5: Depuración con seguimiento de Foundry
Al desarrollar el agente con el SDK del Servicio de agente, puede depurar el agente con seguimiento. El seguimiento permite depurar las llamadas a herramientas como Postgres y ver cómo el agente organiza cada tarea.
En Foundry, vaya a Seguimiento.
Para crear un nuevo recurso de Application Insights, seleccione Crear nuevo. Para conectar un recurso existente, seleccione uno en el cuadro Nombre del recurso de Application Insights y, a continuación, seleccione Conectar.
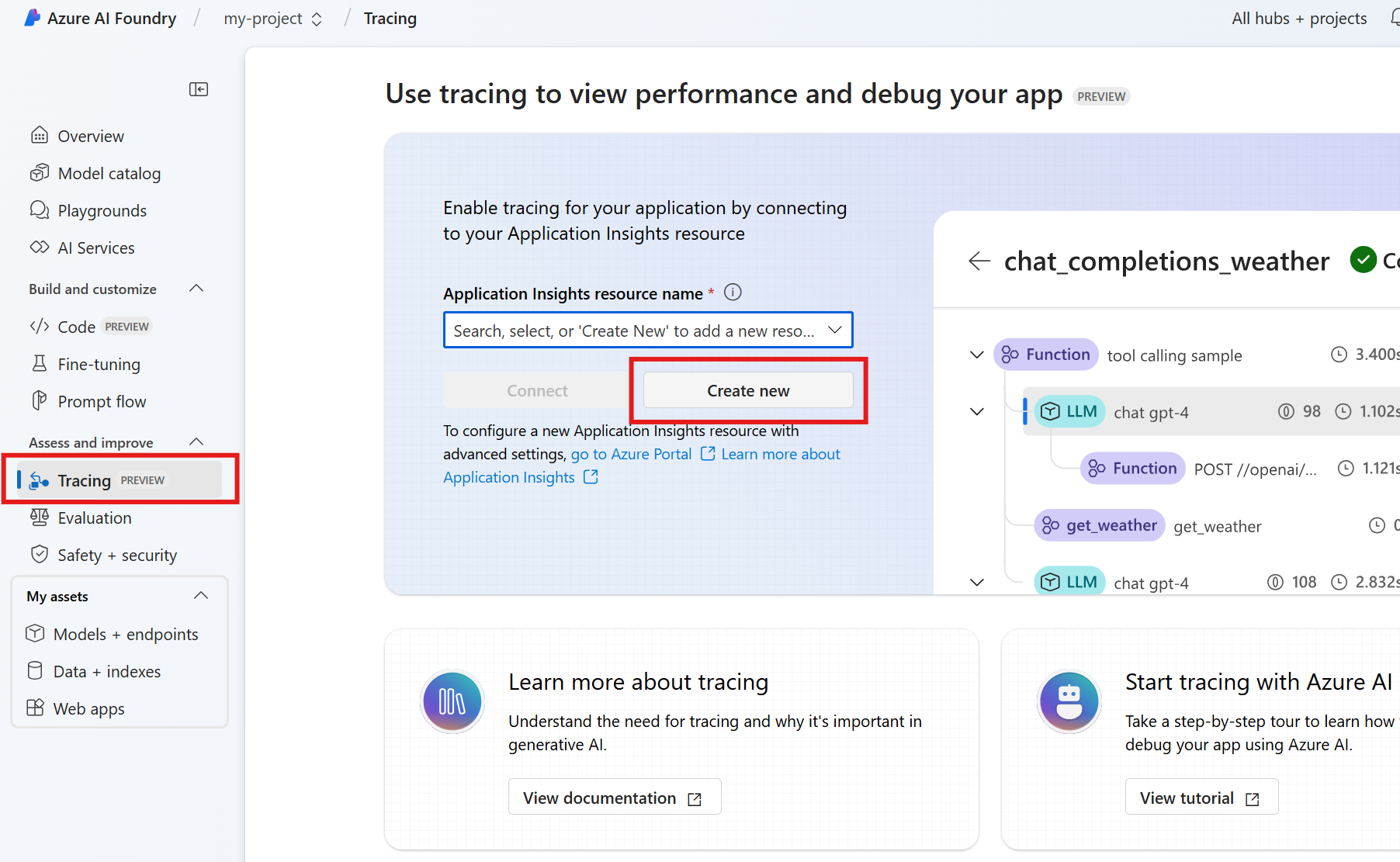
Vea trazas detalladas de las operaciones de su agente.
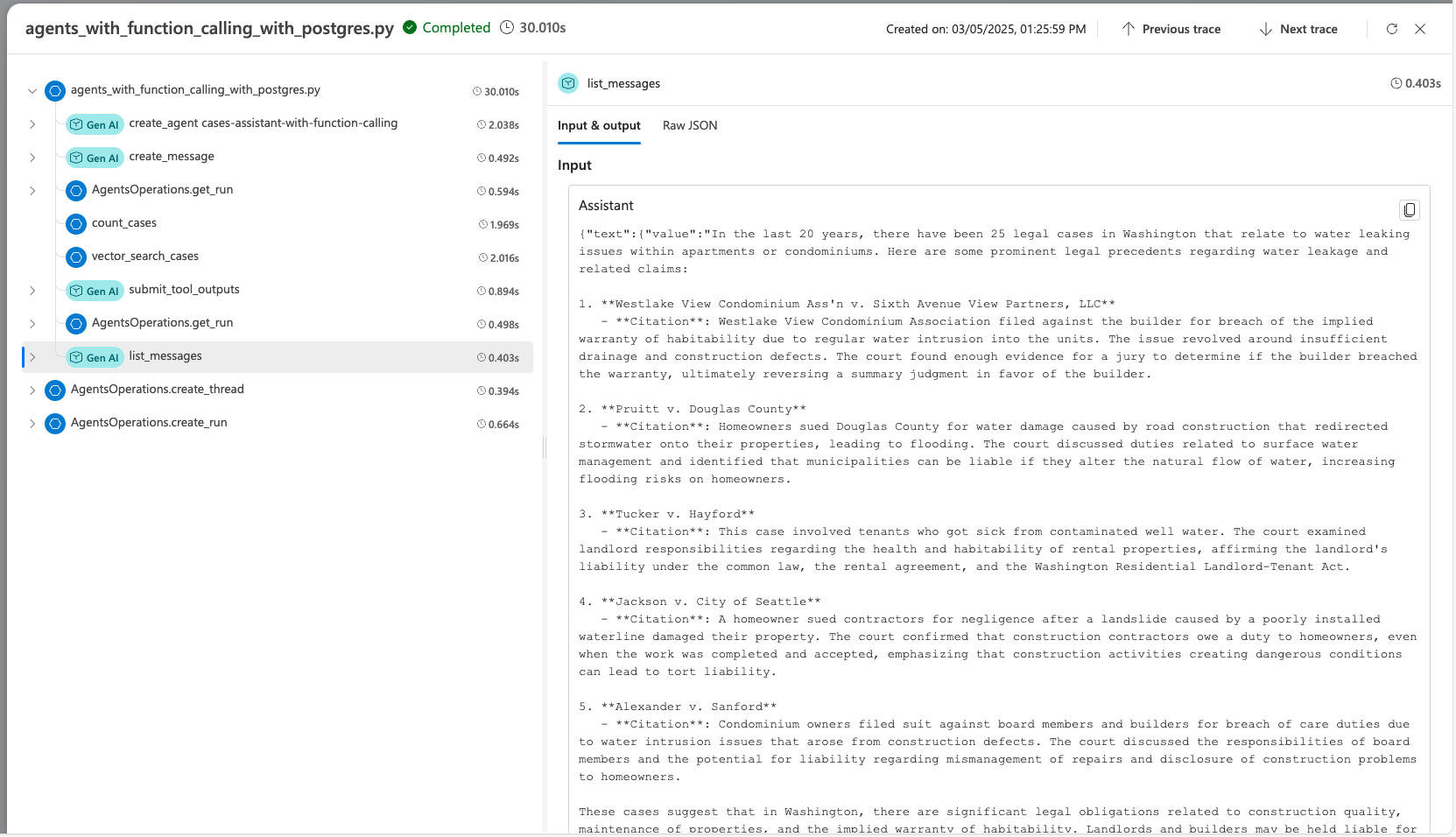
Obtenga más información sobre cómo configurar el seguimiento con el agente de IA y Postgres en el archivo advanced_postgres_and_ai_agent_with_tracing.py en GitHub.
Contenido relacionado
- Integraciones de Azure Database for PostgreSQL para aplicaciones de IA
- Usar LangChain con Azure Database para PostgreSQL
- Generación de incrustaciones de vectores con Azure OpenAI en Azure Database for PostgreSQL
- Extensión de Azure AI en Azure Database for PostgreSQL
- Creación de una búsqueda semántica con Azure Database for PostgreSQL y Azure OpenAI
- Habilitación y uso de pgvector en Azure Database for PostgreSQL