Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Azure Queue Storage es un servicio para almacenar y distribuir un gran número de mensajes. Queue Storage se usa normalmente para crear un trabajo pendiente del trabajo que se va a procesar de forma asincrónica. Proporciona una entrega de mensajes confiable para arquitecturas de aplicaciones acopladas de forma flexible. Un mensaje en cola puede tener un tamaño de hasta 64 KB y una cola puede contener millones de mensajes, hasta el límite de capacidad total de una cuenta de almacenamiento.
Cuando se usa Azure, la confiabilidad es una responsabilidad compartida. Microsoft proporciona una variedad de funcionalidades para admitir resistencia y recuperación. Es responsable de comprender cómo funcionan esas funcionalidades dentro de todos los servicios que usa y de seleccionar las funcionalidades que necesita para cumplir los objetivos empresariales y los objetivos de tiempo de actividad.
En este artículo se describe cómo hacer que Queue Storage sea resistente a una variedad de posibles interrupciones y problemas, incluidos errores transitorios, interrupciones de zona de disponibilidad y interrupciones de regiones. También se describe cómo puede usar copias de seguridad para recuperarse de otros tipos de problemas y se resalta cierta información clave sobre el acuerdo de nivel de servicio (SLA) de Queue Storage.
Nota:
Queue Storage forma parte de la plataforma Azure Storage. Algunas de las funcionalidades de Queue Storage son comunes en muchos servicios de Azure Storage.
Recomendaciones de implementación de producción para la confiabilidad
Para entornos de producción:
Habilite el almacenamiento con redundancia de zona (ZRS) para las cuentas de almacenamiento que contienen recursos de Queue Storage. ZRS proporciona una mayor disponibilidad mediante la replicación de los datos de forma sincrónica en varias zonas de disponibilidad de la región primaria. Una mayor disponibilidad ayuda a proteger las cuentas de almacenamiento frente a errores de zona de disponibilidad.
Si necesitase resistencia a interrupciones de regiones y la región primaria de la cuenta de almacenamiento se encontrase emparejada, considere la posibilidad de habilitar el almacenamiento con redundancia geográfica (GRS). GRS replica los datos de forma asincrónica en la región emparejada. En las regiones admitidas, es posible combinar la redundancia geográfica con redundancia de zona mediante el almacenamiento con redundancia de zona geográfica (GZRS).
Para los requisitos de mensajería avanzados, considere usar Azure Service Bus. Para obtener información sobre las diferencias entre Queue Storage y Service Bus, consulte Comparación de las colas de Azure Storage y las colas de Service Bus.
Introducción a la arquitectura de confiabilidad
Queue Storage funciona como un servicio de mensajería distribuida dentro de la infraestructura de la plataforma de Azure Storage. El servicio proporciona redundancia a través de varias copias de los datos de la cola y de mensajes. El modelo de redundancia específico depende de la configuración de la cuenta de almacenamiento.
El almacenamiento con redundancia local (LRS) replica los datos de las cuentas de almacenamiento en una o varias zonas de disponibilidad de Azure ubicadas en la región primaria de su elección. Aunque no hay ninguna opción para elegir la zona de disponibilidad preferida, Azure puede mover o expandir cuentas LRS entre zonas para mejorar el equilibrio de carga. No hay ninguna garantía de que los datos se distribuirán entre zonas. Para obtener más información sobre las zonas de disponibilidad, consulte ¿Qué son las zonas de disponibilidad?.

El almacenamiento con redundancia de zona (ZRS), el almacenamiento con redundancia geográfica (GRS) y el almacenamiento con redundancia de zona geográfica (GZRS) proporcionan protecciones adicionales. En este artículo se describen estas opciones al detalle.
Resistencia a errores transitorios
Los errores transitorios son errores breves e intermitentes en los componentes. Se producen con frecuencia en un entorno distribuido como la nube y son una parte normal de las operaciones. Los errores transitorios se corrigen después de un breve período de tiempo. Es importante que las aplicaciones puedan controlar errores transitorios, normalmente mediante el reintento de solicitudes afectadas.
Todas las aplicaciones hospedadas en la nube deben seguir las instrucciones de control de errores transitorios de Azure cuando se comunican con cualquier API, bases de datos y otros componentes hospedados en la nube. Para obtener más información, consulte Recomendaciones para controlar errores transitorios.
Queue Storage se usa normalmente en aplicaciones para ayudarles a controlar errores transitorios en otros componentes. Mediante el uso de mensajería asincrónica con un servicio como Queue Storage, las aplicaciones podrán recuperarse de errores transitorios gracias al reprocesamiento de mensajes más adelante. Para más información, consulte Introducción a la mensajería asincrónica.
Dentro del propio servicio, Queue Storage controla automáticamente los errores transitorios mediante varios mecanismos que proporcionan la plataforma de Azure Storage y las bibliotecas cliente. El servicio está diseñado para proporcionar funcionalidades resistentes de Message Queue Server incluso durante problemas temporales de infraestructura.
Las bibliotecas cliente de Queue Storage incluyen directivas de reintento integradas que controlan automáticamente errores transitorios comunes, como tiempos de espera de red, falta de disponibilidad temporal del servicio (HTTP 503) y respuestas de limitación (HTTP 429). Cuando la aplicación encuentre estas condiciones transitorias, las bibliotecas cliente reintentarán automáticamente las operaciones mediante estrategias de retroceso exponencial.
Para administrar los errores transitorios de forma eficaz mediante Queue Storage, realice las siguientes acciones:
Configure los tiempos de espera adecuados en el cliente de Queue Storage para equilibrar la capacidad de respuesta con resistencia a ralentizaciones temporales. Los tiempos de espera predeterminados en las bibliotecas cliente de Azure Storage suelen ser adecuados para la mayoría de los escenarios.
Implemente patrones de disyuntor en la aplicación al procesar mensajes de colas. Los patrones de cortacircuitos impiden fallos en cascada cuando los servicios aguas abajo experimentan problemas.
Use los tiempos de espera de visibilidad correctamente cuando la aplicación reciba mensajes. Los tiempos de espera de visibilidad garantizan que los mensajes estén disponibles para reintentos si la aplicación encontrase errores durante el procesamiento.
Para más información sobre la arquitectura de Azure Table Storage y cómo diseñar aplicaciones resistentes y a gran escala, consulte Lista de comprobación de rendimiento y escalabilidad para Queue Storage.
Resistencia a errores de zona de disponibilidad
Las zonas de disponibilidad son grupos físicamente independientes de centros de datos dentro de una región de Azure. Cuando una zona falla, los servicios pueden transferirse a una de las zonas restantes.
Azure Queue Storage tiene redundancia de zona cuando se implementa con la configuración de ZRS. A diferencia de LRS, ZRS garantiza que Azure replique de forma sincrónica los datos de la cola en varias zonas de disponibilidad. ZRS garantiza que sus datos sigan estando accesibles incluso si se produce un corte en una zona. ZRS garantiza que las colas sigan siendo accesibles incluso si una zona de disponibilidad completa deja de estar disponible. Todas las operaciones de escritura deben confirmarse en varias zonas antes de que se completen, lo que proporciona garantías de coherencia sólidas.
La redundancia de zona está habilitada en el nivel de cuenta de almacenamiento y se aplica a todos los recursos de Queue Storage de esa cuenta. No se pueden configurar colas individuales para distintos niveles de redundancia. La configuración se aplica a toda la cuenta de almacenamiento. Cuando una zona de disponibilidad experimenta una interrupción, Azure Storage enruta automáticamente las solicitudes a zonas correctas sin necesidad de intervención de la aplicación.

Requisitos
- Compatibilidad con regiones: Puede implementar cuentas de Azure Storage con redundancia de zona en cualquier región que admita zonas de disponibilidad.
- Tipos de cuenta de almacenamiento: Debe usar una cuenta de almacenamiento estándar de uso general v2 para habilitar ZRS para Queue Storage. Las cuentas de Premium Storage no admiten Queue Storage.
Cost
Cuando se habilita el almacenamiento con redundancia de zona (ZRS), se cobra una tarifa diferente a la del almacenamiento redundante local (LRS) debido a la replicación adicional y los gastos generales de almacenamiento.
Para obtener información detallada sobre los precios, consulte Precios de Queue Storage.
Configurar soporte de zonas de disponibilidad
Cree una cuenta de almacenamiento de ZRS y una cola siguiendo los pasos siguientes.
Cree una cuenta de almacenamiento y seleccione ZRS, GZRS o almacenamiento con redundancia de zona geográfica con acceso de lectura (RA-GZRS) como opción de redundancia durante la creación de la cuenta.
Cambiar el tipo de replicación. Para obtener información sobre cómo cambiar una cuenta de almacenamiento existente a almacenamiento con redundancia de zona (ZRS) y sobre las opciones y requisitos de configuración, consulte Cambiar la forma en que se replica una cuenta de almacenamiento.
Desactivar la redundancia de zona. Convierta las cuentas de ZRS de nuevo a una configuración no zonal, como el almacenamiento con redundancia local (LRS), utilizando el mismo proceso de cambio de configuración de redundancia.
Comportamiento cuando todas las zonas están en buen estado
En esta sección se describe qué esperar cuando una cuenta de Queue Storage está configurada para la redundancia de zona y todas las zonas de disponibilidad están operativas.
Enrutamiento del tráfico entre zonas: Azure Storage con almacenamiento con redundancia de zona (ZRS) distribuye automáticamente las solicitudes entre los clústeres de almacenamiento en varias zonas de disponibilidad. La distribución del tráfico es transparente para las aplicaciones y no requiere ninguna configuración del lado cliente.
Replicación de datos entre zonas: todas las operaciones de escritura en ZRS se replican de forma sincrónica en todas las zonas de disponibilidad dentro de la región. Al cargar o modificar datos, la operación no se considera completa hasta que los datos se hayan replicado correctamente en todas las zonas de disponibilidad. Esta replicación sincrónica garantiza una fuerte coherencia y cero pérdida de datos durante los errores de zona.
Comportamiento durante un fallo de zona
Cuando una zona de disponibilidad deja de estar disponible, Queue Storage controla automáticamente el proceso de conmutación por error al tomar las siguientes acciones.
- Detección y respuesta: Microsoft detecta automáticamente errores de zona e inicia procesos de recuperación. No se requiere ninguna acción del cliente para las cuentas de almacenamiento con redundancia de zona (ZRS). Si una zona deja de estar disponible, Azure lleva a cabo actualizaciones de red como el repunto del sistema de nombres de dominio (DNS).
- Notificación: Microsoft no le notifica automáticamente cuando una zona está inactiva. Sin embargo, puede usar Azure Resource Health para supervisar el estado de un recurso individual y puede configurar alertas de Resource Health para notificarle problemas. También puede usar Azure Service Health para comprender el estado general del servicio, incluidos los errores de zona, y puede configurar alertas de Service Health para notificarle problemas.
Solicitudes activas: Es posible que las solicitudes en curso se descarten durante el proceso de recuperación y se deban reintentar. Las aplicaciones deben implementar lógica de reintento para controlar estas interrupciones temporales.
Pérdida de datos esperada: No se produce ninguna pérdida de datos durante los errores de zona porque los datos se replican sincrónicamente en varias zonas antes de completar las operaciones de escritura.
Tiempo de inactividad previsto: es posible que se produzca un breve periodo de inactividad, normalmente de unos segundos, durante la recuperación automática, ya que el tráfico se redirige a zonas correctas. Cuando diseñe aplicaciones para ZRS, siga las prácticas de manejo de fallos transitorios, incluyendo la implementación de directivas de reintento con retroceso exponencial.
- Redireccionar el tráfico. Si una zona deja de estar disponible, Azure realiza actualizaciones de red, como el redireccionamiento del Sistema de nombres de dominio (DNS), para que las solicitudes se dirijan a las zonas de disponibilidad restantes que funcionan correctamente. El servicio mantiene una funcionalidad completa utilizando las zonas que permanecen operativas sin necesidad de intervención del cliente.
Recuperación de zona
Cuando se recupera la zona de disponibilidad con errores, Azure Storage restaura automáticamente las operaciones normales en todas las zonas de disponibilidad. El servicio garantiza automáticamente la coherencia de los datos mediante la sincronización de las operaciones que se produjeron durante el período de interrupción.
Prueba de fallos de zona
El usar el almacenamiento con redundancia de zona (ZRS), Azure Storage administrará automáticamente la replicación, el enrutamiento del tráfico y las respuestas ante caídas de zonas. Dado que esta característica está totalmente administrada, no es necesario iniciar ni validar los procesos de error de zona de disponibilidad.
Resistencia a errores en toda la región
Azure Storage, que incluye Azure Blob Storage, Azure Files, Azure Table Storage y Azure Queue Storage, ofrece una amplia gama de capacidades de redundancia geográfica y conmutación por error para adaptarse a diferentes requisitos.
Importante
El GRS solo funciona dentro de regiones emparejadas de Azure. Si la región de la cuenta de almacenamiento no está emparejada, considere la posibilidad de usar las soluciones personalizadas de varias regiones para lograr resistencia.
Almacenamiento con redundancia geográfica para regiones emparejadas
Azure Storage ofrece varios tipos de GRS en regiones emparejadas. Independientemente del tipo de GRS que utilice, los datos de la región secundaria siempre se replicarán mediante almacenamiento con redundancia local (LRS). Este enfoque proporciona protección contra fallos de hardware dentro de la región secundaria.
GRS proporciona soporte para conmutaciones por error planificadas y no planificadas a la región emparejada de Azure cuando se produce una interrupción en la región principal. GRS replica de forma asincrónica los datos de la región primaria a la región emparejada.
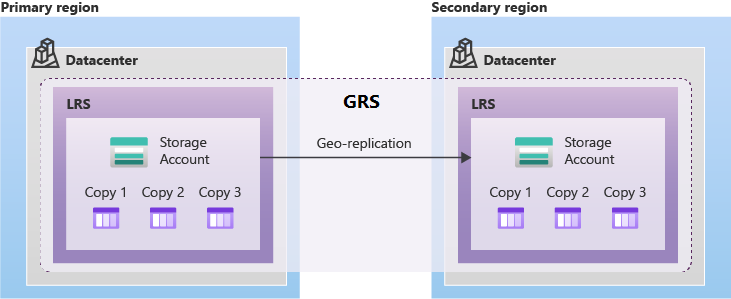
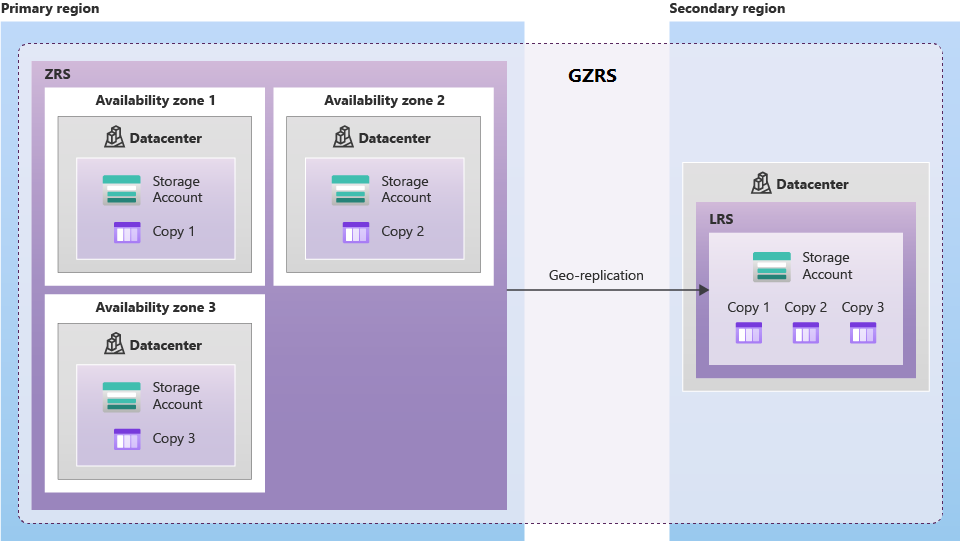
El almacenamiento con redundancia de zona geográfica (GZRS) replica los datos en varias zonas de disponibilidad de la región principal y en la región emparejada.


- El almacenamiento con redundancia geográfica con acceso de lectura (RA-GRS) y el almacenamiento con redundancia de zona geográfica con acceso de lectura (RA-GZRS) amplían el almacenamiento con redundancia geográfica (GRS) y el almacenamiento con redundancia de zona geográfica (GZRS), con la ventaja adicional del acceso de lectura al punto de conexión secundario. Estas opciones son idóneas y están diseñadas para obtener alta disponibilidad en aplicaciones críticas para la empresa. En el improbable caso de que el punto de conexión principal experimente una interrupción, las aplicaciones configuradas para el acceso de lectura a la región secundaria pueden seguir funcionando.
Tipos de conmutación por error
Azure Storage admite tres tipos de conmutación por error para distintos escenarios.
Conmutación por error no planeada administrada por el cliente: es responsable de iniciar la recuperación si hubiera un error de almacenamiento en toda la región principal.
Conmutación por error planeada administrada por el cliente: Usted es responsable de iniciar la recuperación si otra parte de su solución sufre un fallo en la región primaria y necesita trasladar toda su solución a la región secundaria. Use una conmutación por error planeada cuando el almacenamiento permanezca operativo en la región primaria, pero debe realizar una conmutación por error de toda la solución a una región secundaria, como para los simulacros de recuperación ante desastres diseñados para garantizar el cumplimiento de los requisitos de auditoría.
Conmutación por error administrada por Microsoft: en circunstancias excepcionales, Microsoft podría iniciar la conmutación por error para todas las cuentas de almacenamiento con redundancia geográfica (GRS) de una región. Sin embargo, la conmutación por error administrada por Microsoft es un último recurso y se espera que solo se realice después de un período prolongado de interrupción. No se debe confiar en el failover administrado por Microsoft.
Las cuentas de GRS pueden utilizar cualquiera de estos tipos de conmutación por error. No es necesario preconfigurar una cuenta de almacenamiento para usar ninguno de los tipos de conmutación por error con antelación.
Requisitos
Compatibilidad con regiones: Las configuraciones con redundancia geográfica de Azure Storage usan regiones emparejadas de Azure para la replicación de regiones secundarias. La región secundaria se determina automáticamente en función de la selección de la región principal y no se puede personalizar. Para obtener una lista completa de las regiones emparejadas de Azure, consulte Lista de regiones de Azure.
Si la región de la cuenta de almacenamiento no está emparejada, considere la posibilidad de usar las soluciones personalizadas de varias regiones para lograr resistencia.
- Tipos de cuenta de almacenamiento: El almacenamiento con redundancia geográfica (GRS) y la conmutación por error y la conmutación por recuperación iniciadas por el cliente están disponibles en todas las regiones emparejadas de Azure que admiten cuentas de Azure Storage de uso general v2.
Consideraciones
Al implementar Queue Storage en varias regiones, tenga en cuenta los siguientes factores importantes.
Latencia de replicación asincrónica: la replicación de datos en la región secundaria es asincrónica, lo que significa que hay un retraso entre cuando los datos se escriben en la región primaria y cuando estarán disponibles en la región secundaria. Este retraso podría provocar una posible pérdida de datos si se produjese un fallo en la región principal antes de que se repliquen los datos recientes. La pérdida de datos se mide mediante el objetivo de punto de recuperación (RPO). Espere que el retraso de replicación sea inferior a 15 minutos, pero este tiempo es una estimación y no se garantiza.
Compruebe la propiedad Última hora de sincronización para saber cuántos datos se podrían perder si su cuenta de almacenamiento sufriese una conmutación por error no planificada.
Acceso a la región secundaria: con las configuraciones de almacenamiento con redundancia geográfica (GRS) y almacenamiento con redundancia de zona geográfica (GZRS), la región secundaria no será accesible a las lecturas hasta que se produzca una conmutación por error.
Las configuraciones de almacenamiento con redundancia geográfica con acceso de lectura (RA-GRS) y almacenamiento con redundancia de zona geográfica con acceso de lectura (RA-GZRS) proporcionan acceso de lectura a la región secundaria durante las operaciones normales, pero debido a la latencia de replicación asincrónica, podrían devolver datos ligeramente obsoletos.
- Limitaciones de las características: algunas características de Azure Storage no son compatibles o tienen limitaciones cuando se utiliza almacenamiento con redundancia geográfica (GRS) o conmutación por error administrada por el cliente. Revise la compatibilidad de las característica antes de implementar la redundancia geográfica.
Cost
Las configuraciones de cuentas de Azure Storage multirregionales conllevan costes adicionales por la replicación entre regiones y el almacenamiento en la región secundaria. La transferencia de datos entre regiones de Azure se cobra en función de las tarifas estándar de ancho de banda entre regiones.
Para obtener información detallada sobre los precios, consulte Precios de Queue Storage.
Configuración de la compatibilidad con varias regiones
- Cree una nueva cuenta de almacenamiento con redundancia geográfica (GRS). Para crear una cuenta de GRS, consulte Creación de una cuenta de almacenamiento y seleccione GRS, almacenamiento con redundancia geográfica con acceso de lectura (RA-GRS), almacenamiento con redundancia de zona geográfica (GZRS) o almacenamiento con redundancia de zona geográfica con acceso de lectura (RA-GZRS) durante la creación de la cuenta.
Habilite la redundancia geográfica en una cuenta de almacenamiento existente. Para convertir una cuenta de almacenamiento existente en almacenamiento con redundancia geográfica (GRS), consulte Cambio de cómo se replica una cuenta de almacenamiento.
Advertencia
Una vez que su cuenta se haya reconfigurado para la redundancia geográfica, es posible que transcurra un tiempo considerable antes de que los datos existentes en la nueva región principal se copien por completo a la nueva región secundaria.
Para evitar una pérdida importante de datos, compruebe el valor de la propiedad Última hora de sincronización antes de iniciar una conmutación por error no planificada. Para evaluar la posible pérdida de datos, compare la última hora de sincronización con la última hora en que se escribieron los datos en la nueva región principal.
Deshabilite la redundancia geográfica. Convierta las cuentas de GRS en configuraciones de una sola región, como el almacenamiento con redundancia local (LRS) o el almacenamiento con redundancia local (ZRS) con el mismo proceso de cambio de configuración de redundancia.
Comportamiento cuando todas las regiones están en buen estado
En esta sección se describe qué esperar cuando una cuenta de almacenamiento está configurada para redundancia geográfica y todas las regiones están operativas.
Enrutamiento del tráfico entre regiones: Azure Storage utiliza un enfoque activo-pasivo en el que todas las operaciones de escritura y la mayoría de las operaciones de lectura se dirigen a la región principal.
En las configuraciones de almacenamiento con redundancia geográfica con acceso de lectura (RA-GRS) y almacenamiento con redundancia de zona geográfica con acceso de lectura (RA-GZRS), las aplicaciones pueden leer opcionalmente desde la región secundaria accediendo al punto de conexión secundario. Este enfoque requiere una configuración explícita de la aplicación y no es automática. Además, debido al retraso de replicación asincrónica, los datos de la región secundaria podrían estar ligeramente obsoletos.
Replicación de datos entre regiones: las operaciones de escritura se confirman primero en la región principal utilizando los siguientes tipos de redundancia configurados:
- Almacenamiento con redundancia local (LRS) para almacenamiento con redundancia geográfica (GRS) y RA-GRS
- Almacenamiento con redundancia de zona (ZRS) para el almacenamiento con redundancia de zona geográfica (GZRS) y RA-GZRS
Tras completarse con éxito en la región principal, los datos se replican de forma asíncrona en la región secundaria, donde se almacenan mediante LRS.
La naturaleza asíncrona de la replicación entre regiones significa que suele haber un retraso entre el momento en que los datos se escriben en la región principal y el momento en que están disponibles en la región secundaria. Supervise el tiempo de replicación utilizando la propiedad Última hora de sincronización.
Comportamiento durante una falla de región
En esta sección se describe qué esperar cuando una cuenta de almacenamiento está configurada para la redundancia geográfica y hay una interrupción en la región primaria.
Conmutación por error administrada por el cliente (no planificada): utilice una conmutación por error no planificada cuando el almacenamiento en la región principal no esté disponible.
Detección y respuesta: En el caso poco probable de que su cuenta de almacenamiento no esté disponible en la región primaria, puede considerar iniciar un failover no planeado administrado por el cliente. Para tomar esta decisión, tenga en cuenta los siguientes factores:
Si Azure Resource Health muestra problemas al acceder a la cuenta de almacenamiento en su región principal
Si Microsoft le recomienda realizar una conmutación por error a otra región
Advertencia
Una conmutación por error no planeada puede provocar la pérdida de datos. Antes de iniciar una conmutación por error administrada por el cliente, decida si la restauración del servicio justifica el riesgo de pérdida de datos.
Notificación: Microsoft no le notifica automáticamente cuando una región está inactiva. Sin embargo:
Puede usar Azure Resource Health para supervisar el estado de un recurso individual y puede configurar alertas de Resource Health para notificarle problemas.
Puede usar Azure Service Health para comprender el estado general del servicio, incluidos los errores de región, y puede configurar alertas de Service Health para notificarle problemas.
Solicitudes activas: Durante el proceso de conmutación por error, los puntos de conexión de la cuenta de almacenamiento principal y secundaria dejan de estar disponibles temporalmente para lecturas y escrituras. Las solicitudes activas podrían fallar, y las aplicaciones cliente deben intentar nuevamente después de que se complete la conmutación por error.
Pérdida de datos prevista: la pérdida de datos es habitual durante una conmutación por error no planificada debido al retraso en la replicación asíncrona, lo que significa que es posible que las escrituras recientes no se repliquen. Consulte la propiedad Última hora de sincronización para saber cuántos datos se podrían perder durante una conmutación por error no planificada. La pérdida de datos esperada se conoce a menudo como objetivo de punto de recuperación (RPO). Normalmente, puede esperar que el RPO sea inferior a 15 minutos, pero ese tiempo no está garantizado.
Tiempo de inactividad esperado: La cantidad de tiempo de inactividad esperado se conoce a menudo como objetivo de tiempo de recuperación (RTO). La conmutación por error administrada por el cliente se completa normalmente en un plazo de hasta 60 minutos, dependiendo del tamaño y la complejidad de la cuenta.
Reenrutamiento del tráfico: A medida que se completa la conmutación por error, Azure actualiza automáticamente los puntos de conexión de la cuenta de almacenamiento para que no sea necesario volver a configurar las aplicaciones. Si su aplicación mantiene entradas del Sistema de nombres de dominio (DNS) almacenadas en caché, puede que sea necesario borrar la caché para asegurarse de que la aplicación envíe el tráfico a la nueva región principal.
Configuración posterior a la conmutación por error: una vez completada una conmutación por error no planificada, su cuenta de almacenamiento en la región de destino utilizará el nivel de almacenamiento con redundancia local (LRS). Si necesitase volver a replicar geográficamente los datos, deberá volver a habilitar el almacenamiento con redundancia geográfica (GRS) y esperar a que los datos se repliquen en la nueva región secundaria.
Para obtener más información sobre cómo iniciar una conmutación por error administrada por el cliente, consulte Cómo funciona la conmutación por error administrada por el cliente (no planificada) e Iniciar una conmutación por error de una cuenta de almacenamiento.
Conmutación por error administrada por el cliente (planificada): utilice una conmutación por error planificada cuando el almacenamiento siga operativo en la región principal, pero necesite conmutar por error toda su solución a una región secundaria por otro motivo. Por ejemplo, otro servicio de Azure podría estar experimentando un problema y debe cambiar al uso de una región secundaria para toda la solución. O bien, puede usar una conmutación por error planeada para realizar un simulacro de recuperación ante desastres (DR) con fines de cumplimiento y auditoría.
Detección y respuesta: Usted es responsable de decidir conmutar por error. Normalmente, debe tomar esta decisión si necesita realizar una conmutación entre regiones, aunque su cuenta de almacenamiento esté en buen estado. Por ejemplo, puede desencadenar una conmutación por error cuando se produce una interrupción importante en otro componente de la aplicación que no se puede recuperar en la región principal.
Notificación: Microsoft no le notifica automáticamente cuando una región está inactiva. Sin embargo:
Puede usar Azure Resource Health para supervisar el estado de un recurso individual y puede configurar alertas de Resource Health para notificarle problemas.
Puede usar Azure Service Health para comprender el estado general del servicio, incluidos los errores de región, y puede configurar alertas de Service Health para notificarle problemas.
Solicitudes activas: Durante el proceso de conmutación por error, los puntos de conexión de la cuenta de almacenamiento principal y secundaria dejan de estar disponibles temporalmente para lecturas y escrituras. Las solicitudes activas podrían fallar, y las aplicaciones cliente deben intentar nuevamente después de que se complete la conmutación por error.
Pérdida de datos esperada: No se espera ninguna pérdida de datos porque el proceso de conmutación por error se completa solo después de sincronizar todos los datos, lo que da como resultado un RPO de cero.
Tiempo de inactividad esperado: La conmutación por error normalmente se completa en un plazo de 60 minutos, lo que significa que el tiempo de recuperación objetivo (RTO) esperado es de 60 minutos, en función del tamaño y la complejidad de la cuenta. Durante el proceso de conmutación por error, los puntos de conexión de la cuenta de almacenamiento principal y secundaria dejan de estar disponibles temporalmente para lecturas y escrituras.
Reenrutamiento del tráfico: A medida que se completa la conmutación por error, Azure actualiza automáticamente los puntos de conexión de la cuenta de almacenamiento para que no sea necesario volver a configurar las aplicaciones. Si su aplicación mantiene entradas DNS almacenadas en caché, puede que sea necesario borrar la caché para asegurarse de que la aplicación envíe tráfico a la nueva región principal.
Configuración posterior a la conmutación por error: Una vez completada una conmutación por error planeada, la cuenta de almacenamiento de la región de destino sigue siendo replicada geográficamente y permanece en el nivel GRS.
Para obtener más información sobre cómo iniciar una conmutación por error administrada por el cliente, consulte Cómo funciona la conmutación por error administrada por el cliente (planificada) e Iniciar una conmutación por error de una cuenta de almacenamiento.
Conmutación por error administrada por Microsoft: En el caso excepcional de un desastre importante en el que Microsoft determina que la región primaria es irrecuperable permanentemente, es posible que se inicie una conmutación automática por error a la región secundaria. Microsoft controla todo el proceso y no se requiere ninguna acción del cliente. El tiempo que transcurre antes de que ocurra un failover depende de la gravedad del desastre y del tiempo necesario para evaluar la situación.
Notificación: Microsoft no le notifica automáticamente cuando una región está inactiva. Sin embargo:
Puede usar Azure Resource Health para supervisar el estado de un recurso individual y puede configurar alertas de Resource Health para notificarle problemas.
Puede usar Azure Service Health para comprender el estado general del servicio, incluidos los errores de región, y puede configurar alertas de Service Health para notificarle problemas.
Importante
Utilice las opciones de conmutación por error administradas por el cliente para desarrollar, probar e implementar tus planes de recuperación ante desastres. No confíe en la conmutación por error administrada por Microsoft, que solo se puede utilizar en circunstancias extremas. Es probable que se haya iniciado una conmutación por error administrada por Microsoft para toda una región. No se puede iniciar para cuentas de almacenamiento individuales, suscripciones o clientes. La conmutación por error puede producirse en momentos diferentes para distintos servicios de Azure. Recomendamos que utilice la conmutación por error administrada por el cliente.
Recuperación de regiones
El proceso de conmutación por recuperación difiere significativamente entre los escenarios de conmutación por error administrados por Microsoft y los administrados por el cliente.
Conmutación por error administrada por el cliente (no planeada): después de una conmutación por error no planeada, la cuenta de almacenamiento se configura con almacenamiento con redundancia local (LRS). Para realizar una conmutación por error, es necesario restablecer la relación de almacenamiento con redundancia geográfica (GRS) y esperar a que se repliquen los datos.
Conmutación por error administrada por el cliente (planificada): después de una conmutación por error planificada, la cuenta de almacenamiento seguirá estando replicada geográficamente. Inicie otra conmutación por error administrada por el cliente para volver a la región principal original. Se aplican las mismas consideraciones de conmutación por error.
Conmutación por error administrada por Microsoft: si Microsoft iniciase una conmutación por error, es probable que se haya producido un desastre importante en la región principal y que esta no se pueda recuperar. Cualquier calendario o plan de recuperación dependerá del alcance del desastre regional y de los esfuerzos de recuperación. Debe supervisar las comunicaciones de Azure Service Health para más información.
Prueba de fallos de región
Simule fallos regionales para probar sus procedimientos de recuperación ante desastres.
Pruebas de conmutación por error planificadas: en el caso de las cuentas de almacenamiento con redundancia geográfica (GRS), es posible realizar operaciones de conmutación por error planificadas durante las ventanas de mantenimiento para probar el proceso completo de conmutación por error y conmutación por recuperación. La conmutación por error planificada no implica pérdida de datos, pero sí conlleva tiempo de inactividad tanto durante la conmutación por error como durante la conmutación por recuperación.
Pruebas de puntos de conexión secundarios: para el almacenamiento con redundancia geográfica con acceso de lectura (RA-GRS) y las configuraciones de almacenamiento con redundancia de zona geográfica con acceso de lectura (RA-GZRS), pruebe periódicamente las operaciones de lectura en el punto de conexión secundario para asegurarse de que la aplicación pueda leer correctamente los datos de la región secundaria.
Soluciones personalizadas de varias regiones para la resistencia
Las funcionalidades de conmutación por error entre regiones de Azure Storage podrían no ser adecuadas por los siguientes motivos:
La cuenta de almacenamiento está en una región no emparejada.
Los objetivos de tiempo de actividad empresarial no se satisfacen por el tiempo de recuperación o la pérdida de datos que proporciona las opciones de conmutación por error integradas.
Debe conmutar por error a una región que no esté emparejada con la región principal.
Necesita una configuración activa o activa entre regiones.
En esta sección se proporciona información general de alto nivel de algunos enfoques que se deben tener en cuenta. Una introducción completa de las topologías de implementación de varias regiones para Azure Storage está fuera del ámbito de este artículo.
Nota:
En el caso de los requisitos avanzados de varias regiones, considere la posibilidad de usar Service Bus en su lugar, lo que incluye compatibilidad con regiones no emparejadas.
Implemente Azure Storage en varias regiones utilizando cuentas de almacenamiento independientes en cada región. Este enfoque ofrece flexibilidad en la selección de regiones, la posibilidad de utilizar regiones no emparejadas y un control más granular sobre el momento de la replicación y la coherencia de los datos. Al implementar varias cuentas de almacenamiento entre regiones, es necesario configurar la replicación de datos entre regiones, implementar directivas de equilibrio de carga y conmutación por error y garantizar la coherencia de los datos entre regiones.
Este enfoque requiere que administre la distribución de mensajes, controle la sincronización de datos entre las colas de las distintas cuentas de almacenamiento e implemente la lógica de conmutación por error personalizada.
Copias de seguridad y restauración
Queue Storage no proporciona funcionalidades de copia de seguridad tradicionales, como la restauración a un momento dado (PITR). Esto se debe a que las colas están diseñadas para el almacenamiento transitorio de mensajes en lugar de la persistencia de datos a largo plazo. Normalmente, los mensajes se procesan y quitan de las colas durante las operaciones normales de la aplicación.
En escenarios que requieran durabilidad de mensajes más allá de las opciones de redundancia integradas, considere la posibilidad de implementar su propio registro de mensajes de nivel de aplicación o persistencia en un almacén de datos permanente, como Blob Storage o Azure SQL Database. Este enfoque le permite mantener el historial de mensajes mientras usa Queue Storage para su propósito previsto de almacenamiento temporal de búfer de mensajes y coordinación de procesamiento.
Acuerdo de nivel de servicio
El acuerdo de nivel de servicio (SLA) para Azure Storage describe la disponibilidad esperada del servicio y las condiciones que se deben cumplir para lograr esa expectativa de disponibilidad. El contrato de nivel de servicio de disponibilidad al que tiene derecho dependerá del nivel de almacenamiento y del tipo de replicación que utilice. Para obtener más información, consulte los SLAs for Online Services.