Disponibilidad de SAP HANA dentro de una región de Azure
En este artículo, se describen varios escenarios de disponibilidad para SAP HANA dentro de una región de Azure. Azure tiene muchas regiones repartidas por todo el mundo. Para obtener la lista de las regiones de Azure, consulte Regiones de Azure. Para implementar SAP HANA en máquinas virtuales dentro de una región de Azure, Microsoft ofrece la implementación de una única máquina virtual con una instancia de HANA. Para una mayor disponibilidad, puede implementar dos máquinas virtuales con dos instancias de HANA mediante un conjunto de escalado flexible con FD=1, zonas de disponibilidad o un conjunto de disponibilidad que use la replicación del sistema HANA para la disponibilidad.
En las regiones de Azure en las que se proporcionan zonas de disponibilidad, se incluyen varios centros de datos, cada uno con su propia fuente de energía, refrigeración e infraestructura de red. El propósito de ofrecer diferentes zonas dentro de una única región de Azure es habilitar la implementación de aplicaciones en dos o tres zonas de disponibilidad. Al distribuir la implementación de la aplicación entre zonas, cualquier problema de energía o de red que afecte a una infraestructura específica de zona de disponibilidad de Azure no interrumpiría completamente la funcionalidad de la aplicación dentro de la región de Azure. Aunque puede haber alguna capacidad reducida, como la posible pérdida de máquinas virtuales en una zona, las de las zonas restantes seguirán funcionando sin interrupción. Para configurar dos instancias de HANA en máquinas virtuales independientes que abarquen distintas zonas, tiene la opción de implementar máquinas virtuales mediante la opción de implementación de conjunto de escalado flexible con FD=1 o de zonas de disponibilidad.
Para una mayor disponibilidad dentro de una región, se recomienda implementar dos máquinas virtuales con dos instancias de HANA mediante un conjunto de disponibilidad. Un conjunto de disponibilidad de Azure es una funcionalidad de agrupación lógica que garantiza que los recursos de máquina virtual configurados en el conjunto de disponibilidad estén aislados entre sí cuando se implementan en un centro de datos de Azure. Azure garantiza que las máquinas virtuales colocados en un conjunto de disponibilidad se ejecuten en varios servidores físicos, grupos de proceso, unidades de almacenamiento y conmutadores de red. En determinada documentación de Azure, a esta configuración se le conoce como ubicaciones en diferentes dominios de actualización y error. Estas ubicaciones están normalmente dentro de un centro de datos de Azure. Suponiendo que los problemas de fuente de energía o de red afectaran al centro de datos que está implementando, toda la capacidad de una región de Azure resultaría afectada.
La ubicación de centros de datos que representan las zonas de disponibilidad de Azure es un equilibrio entre la entrega de latencia de red entre los servicios implementados en diferentes zonas que son aceptables para la mayoría de las aplicaciones y una determinada distancia entre los centros de datos. Idealmente, las catástrofes naturales no afectarían al suministro de energía y red, ni a la infraestructura de todas las zonas de disponibilidad de esta región. Sin embargo, como se ha demostrado en catástrofes naturales de gran alcance, las zonas de disponibilidad podrían no ser siempre capaces de proporcionar la disponibilidad deseada dentro de una región. Considérese, por ejemplo, el huracán María que alcanzó la isla de Puerto Rico el 20 de septiembre de 2017. Básicamente, el huracán causó un apagón casi en el 100 % de la isla de 145 km de superficie.
Escenario de una única máquina virtual
En un escenario de una única máquina virtual, se crea una máquina virtual de Azure para la instancia de SAP HANA. Se utiliza Azure Premium Storage para hospedar el disco del sistema operativo y todos los discos de datos. El Acuerdo de Nivel de Servicio de tiempo de actividad del 99,9 % de Azure y los Acuerdos de Nivel de Servicio de otros componentes de Azure son suficientes para cumplir sus Acuerdos de Nivel de Servicio de disponibilidad con sus clientes. En este escenario, no es necesario usar un conjunto de disponibilidad de Azure con máquinas virtuales que ejecutan la capa de DBMS. Usará dos características diferentes:
- Reinicio automático de máquinas virtuales de Azure (también conocido como reparación del servicio de Azure)
- Reinicio automático de SAP HANA
El reinicio automático de máquinas virtuales de Azure, o reparación del servicio, es una funcionalidad de Azure que opera en dos niveles:
- El host de servidor de Azure comprueba el mantenimiento de una máquina virtual hospedada en el host de servidor.
- El controlador de tejido de Azure supervisa el mantenimiento y la disponibilidad del host de servidor.
Una funcionalidad de comprobación de mantenimiento supervisa el mantenimiento de cada máquina virtual hospedada en un host de servidor de Azure. Si una máquina virtual entra en un estado incorrecto, el agente de host de Azure puede comenzar un reinicio de la máquina virtual para comprobar su mantenimiento. El controlador de tejido comprueba el mantenimiento del host mediante la comprobación de muchos parámetros diferentes que podrían indicar problemas con el hardware del host. También comprueba la accesibilidad del host a través de la red. Los indicios de problemas con el host pueden llevar a acciones como las siguientes:
- Si el host indica un estado de mantenimiento incorrecto, se desencadena el reinicio del host y de las máquinas virtuales que se ejecutaban en él.
- Si el host no tiene un estado correcto después de un reinicio correcto, se inicia una reimplementación de las máquinas virtuales que estaban originalmente en el nodo que ahora tiene un estado incorrecto en un servidor de host correcto. En este caso, el host original se marca como incorrecto. No se usará en las sucesivas implementaciones hasta que se elimine o sustituya.
- Si el host incorrecto tiene problemas durante el proceso de reinicio, se desencadena un reinicio inmediato de las máquinas virtuales en un host correcto.
Gracias a la supervisión del host y de las máquinas virtuales que proporciona Azure, las máquinas virtuales de Azure que experimentan problemas del host se reinician automáticamente en un host de Azure correcto.
Importante
La recuperación del servicio de Azure no reiniciará máquinas virtuales Linux donde el sistema operativo invitado se encuentre en estado de pánico del kernel. La configuración predeterminada de las versiones de Linux usadas comúnmente no reinicia automáticamente las máquinas virtuales o el servidor donde el kernel de Linux se encuentra en estado de pánico. En su lugar, prevé mantener el sistema operativo en estado de pánico del kernel para poder asociar el depurador de kernel y realizar un análisis. Para respetar ese comportamiento, Azure no reinicia automáticamente las máquinas virtuales con el sistema operativo invitado en ese estado. Se supone que dichos casos son muy poco frecuentes. Podría sobrescribir el comportamiento predeterminado para permitir el reinicio de la máquina virtual. Para cambiar el comportamiento predeterminado, habilite el parámetro "kernel.panic" en /etc/sysctl.conf. El tiempo especificado para este parámetro se expresa en segundos. Los valores comunes recomendados son esperar entre 20 y 30 segundos antes de desencadenar el reinicio a través de este parámetro. Para obtener más información, consulte sysctl.conf.
La segunda característica en la que se basa un escenario de este tipo, es el hecho de que el servicio HANA que se ejecuta en una máquina virtual reiniciada se inicia automáticamente tras el reinicio de la máquina virtual. El reinicio automático de servicios HANA se puede configurar mediante los servicios de guardia de los diferentes servicios HANA.
Este escenario de máquina virtual única se podría mejorar mediante la adición de un nodo de conmutación por error en frío a una configuración de SAP HANA. En la documentación de SAP HANA, esta configuración se conoce como conmutación automática por error del host. Esta configuración puede tener sentido en situaciones de implementación local donde el hardware del servidor está limitado y se dedica un único nodo del servidor como nodo de conmutación automática por error del host para un conjunto de hosts de producción. Sin embargo, en Azure, donde su infraestructura subyacente proporciona un servidor de destino correcto para el reinicio con éxito de una máquina virtual, no tiene sentido implementar la conmutación automática por error del host de SAP HANA. Debido a la recuperación del servicio de Azure, no hay una arquitectura de referencia que prevea un nodo en espera para la conmutación por error automática del host de HANA.
Caso especial de configuraciones de escalado horizontal de SAP HANA en Azure
Las arquitecturas de alta disponibilidad basadas en el nodo en espera o la replicación del sistema HANA se pueden encontrar en los siguientes documentos. En los casos en los que los nodos en espera o la alta disponibilidad de la replicación del sistema HANA no se usen en las configuraciones de escalabilidad horizontal de SAP HANA, puede confiar en las funcionalidades de recuperación del servicio de las máquinas virtuales de Azure y del reinicio automático de la instancia de SAP HANA una vez que la máquina virtual vuelva a funcionar.
- RedHat Enterprise Linux
- SUSE Linux Enterprise Server
Escenarios de disponibilidad con dos máquinas virtuales diferentes
Para garantizar la disponibilidad del sistema HANA dentro de una región específica, tiene la opción de configurar dos máquinas virtuales en las zonas de disponibilidad de la región o dentro de la región. Para lograr este objetivo, puede configurar las máquinas virtuales mediante la opción de implementación de conjunto de escalado flexible, zonas de disponibilidad o conjunto de disponibilidad. La configuración básica de Azure sería similar a la siguiente:
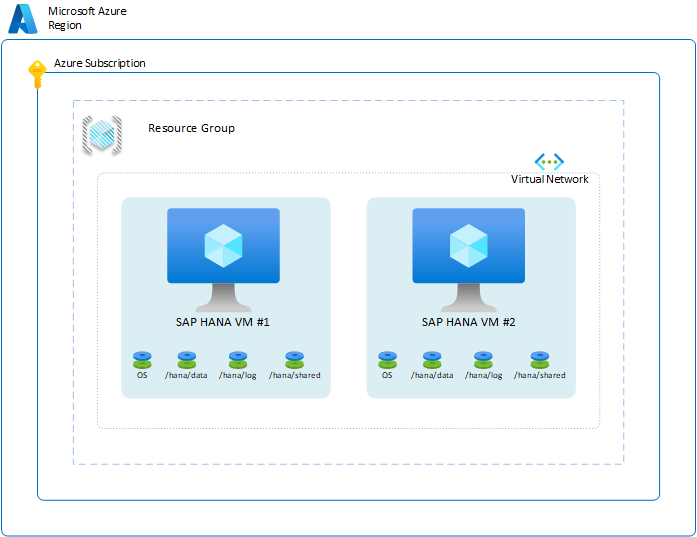
Para ilustrar los distintos escenarios de disponibilidad de SAP HANA, se han omitido algunas de las capas en el diagrama. El diagrama muestra solo las capas que representan máquinas virtuales, hosts, conjuntos de disponibilidad y regiones de Azure. Las instancias de Azure Virtual Network, los grupos de recursos y las suscripciones no influyen en los escenarios descritos en esta sección.
Replicación de copias de seguridad en una segunda máquina virtual
Una de las configuraciones más rudimentarias es utilizar copias de seguridad. En concreto, es posible que envíe copias de seguridad del registro de transacciones desde una máquina virtual a otra máquina virtual de Azure. Puede elegir el tipo de instancia de Azure Storage. En esta configuración, su responsabilidad consiste en crear un script para copiar en la segunda máquina virtual las copias de seguridad programadas realizadas en la primera. En caso de que sea necesario usar las instancias de la segunda máquina virtual, tendría que restaurar la copia de seguridad incremental o diferencial completa y las copias de seguridad del registro de transacciones en el punto que necesite.
La arquitectura tiene el siguiente aspecto:
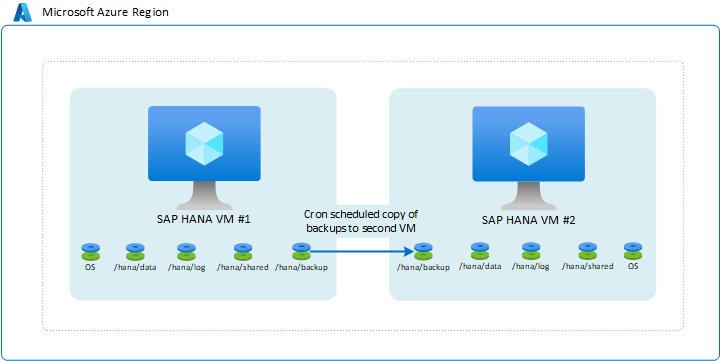
Esta configuración no es adecuada para conseguir grandes tiempos de objetivo de punto de recuperación (RPO) y objetivo de tiempo de recuperación (RTO). En especial, los tiempos de RTO resultarían afectados debido a la necesidad de restaurar completamente la base de datos mediante los archivos de copia de seguridad copiados. Sin embargo, esta configuración es útil para recuperarse de la eliminación de datos no intencionada en las instancias principales. Con ella, puede restaurar en cualquier momento a un punto en el tiempo determinado, extraer los datos e importar los datos eliminados en la instancia principal. De ahí que tenga sentido usar este método de copia de seguridad en combinación con otra funcionalidad de alta disponibilidad.
Mientras se copian las copias de seguridad, es posible que pueda usar una máquina virtual más pequeña que la principal en la que se ejecuta la instancia de SAP HANA. Tenga en cuenta que a las máquinas virtuales más pequeñas puede adjuntar un menor número de VHD. Consulte Tamaños de las máquinas virtuales Linux en Azure para ver los límites de los tipos de máquina virtual individual.
Replicación del sistema de SAP HANA sin conmutación automática por error
Los escenarios descritos en esta sección utilizan la replicación del sistema de SAP HANA. Para ver la documentación de SAP, consulte Replicación del sistema. Los escenarios sin conmutación automática por error no son comunes en configuraciones dentro de una región de Azure. Si bien una configuración sin conmutación automática por error evita la configuración de Pacemaker, le obliga a supervisar y a conmutar por error manualmente. Dado que también supone un esfuerzo, la mayoría de los clientes confía en su lugar en la recuperación del servicio de Azure. Solo existen algunos casos extremos en los que esta configuración podría resultar útil en términos de escenarios de error. O bien, en algunos casos, es posible que un cliente desee conseguir una mayor eficiencia.
Replicación del sistema de SAP HANA sin conmutación por error automática y sin datos precargados
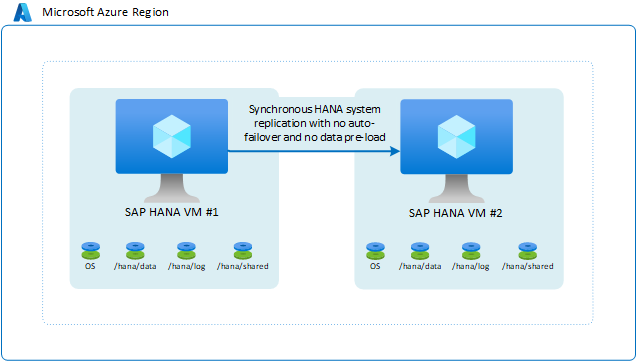
En este escenario, se usa la replicación del sistema de SAP HANA para mover datos de forma sincrónica para alcanzar un RPO de 0. Por otro lado, el RTO es suficientemente prolongado como para no necesitar la conmutación por error ni datos precargados en la memoria caché de la instancia de HANA. En este caso, es posible conseguir una mayor economía en la configuración mediante las acciones siguientes:
- Ejecute otra instancia de SAP HANA en la segunda máquina virtual. La instancia de SAP HANA en la segunda máquina virtual toma la mayor parte de la memoria de la máquina virtual. En caso de una conmutación por error a la segunda máquina virtual, deberá apagar la instancia SAP HANA en ejecución que tenga los datos totalmente cargados en la segunda máquina virtual, de forma que los datos replicados se puedan cargar en la caché de la instancia de HANA de destino en la segunda máquina virtual.
- Use una máquina virtual de menor tamaño en segunda máquina virtual. Si se produce una conmutación por error, habrá que realizar un paso adicional antes de la conmutación por error manual. En este paso, cambiará el tamaño de la máquina virtual al de la máquina virtual de origen.
El escenario se parecería a este:
Nota:
Incluso si no utiliza datos precargados en el destino de replicación del sistema de HANA, necesitará al menos 64 GB de memoria. También necesitará suficiente memoria además de 64 GB para mantener los datos del almacén de filas en la memoria de la instancia de destino.
Replicación del sistema de SAP HANA sin conmutación por error automática y con datos precargados
En este escenario, se cargan previamente los datos replicados en la instancia de HANA en la segunda máquina virtual. Esto elimina las dos ventajas de no usar datos precargados. En este caso, no puede ejecutar otro sistema SAP HANA en la segunda máquina virtual. Tampoco puede usar un tamaño de máquina virtual más pequeño. Por lo tanto, los clientes raramente implementan este escenario.
Replicación del sistema de SAP HANA con conmutación por error automática
En la configuración de disponibilidad estándar más habitual dentro de una región de Azure, dos máquinas virtuales de Azure que ejecutan Linux con alta disponibilidad tienen definido un clúster de conmutación por error. El clúster de Linux de alta disponibilidad se basa en el marco de Pacemaker con SLES o RHEL con un fencing device SLES o RHEL como ejemplo.
Desde una perspectiva de SAP HANA, el modo de replicación usado se sincroniza y se configura una conmutación por error automática. En la segunda máquina virtual, la instancia de SAP HANA actúa como un nodo en espera activa. El nodo en espera recibe una secuencia sincrónica de registros de cambios de la instancia principal de SAP HANA. A medida que las transacciones se confirman en la aplicación en el nodo principal de HANA, dicho nodo espera hasta que el nodo secundario de SAP HANA confirma que ha recibido el registro de confirmación. SAP HANA ofrece dos modos diferentes de replicación sincrónica. Para obtener más información y conocer las diferencias entre estos dos modos de replicación sincrónica, lea el artículo de SAP Replication modes for SAP HANA system replication (Modos de replicación en la replicación del sistema de SAP HANA).
La configuración general se parece a esta:
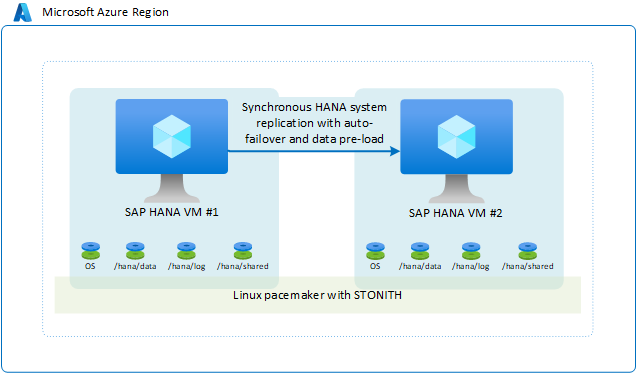
Es posible que elija esta solución porque le permite conseguir un RPO=0 y tiempos bajos de RTO. Configure la conectividad del cliente de SAP HANA de forma que use la dirección IP virtual para conectarse a la configuración de replicación del sistema de HANA. Dicha configuración elimina la necesidad de volver a configurar la aplicación en el caso de una conmutación por error al nodo secundario. En esta solución, las SKU de máquina virtual de Azure para la máquina virtual principal y la secundaria deben ser iguales.
Pasos siguientes
Para obtener instrucciones paso a paso sobre cómo configurar estas configuraciones en Azure, vea:
- Configuración de la replicación del sistema de SAP HANA en máquinas virtuales de Azure
- High Availability for SAP HANA using System Replication (Alta disponibilidad en SAP HANA mediante la replicación del sistema)
Para más información sobre la disponibilidad de SAP HANA entre regiones de Azure, consulte:
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de