Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Los perfiles de puntuación se usan para aumentar la clasificación de documentos coincidentes en función de los criterios. En este artículo, aprenderá a especificar y asignar un perfil de puntuación que aumente una puntuación de búsqueda en función de los parámetros que proporcione. Puede crear perfiles de puntuación basados en:
Campos ponderados, donde la optimización se basa en una coincidencia encontrada en un campo de cadena específico. Por ejemplo, si las coincidencias encontradas en un campo "Asunto" deben ser más relevantes que la misma coincidencia que se encuentra en un campo "Descripción".
Funciones para datos numéricos, entre las que se incluyen fechas, intervalos y coordenadas geográficas. También hay una función Etiquetas que funciona en un campo que proporciona una colección arbitraria de cadenas. Puede elegir este enfoque sobre los campos ponderados si desea aumentar una puntuación en función de si se encuentra una coincidencia en un campo de etiquetas.
Puede agregar un perfil de puntuación a un índice editando su definición JSON en Azure Portal o mediante programación a través de API como Create o Update Index REST o API equivalentes en cualquier SDK de Azure.
Prerrequisitos
Puede usar cualquier versión de API o paquete del SDK para los perfiles de puntuación en la búsqueda de palabras clave. En el caso de las búsquedas híbridas y vectoriales, use 2024-05-01-preview y 2024-07-01 API REST o paquetes del SDK de Azure que proporcionan paridad de características. Para la integración entre perfiles de puntuación y clasificador semántico, use 2025-05-01-preview y versiones posteriores.
Reglas para perfiles de puntuación
Debe tener un índice de búsqueda nuevo o existente con campos numéricos o de texto.
Puede usar perfiles de puntuación en la búsqueda de palabras clave, la búsqueda vectorial y la búsqueda híbrida. Sin embargo, los perfiles de puntuación solo se aplican a campos no vectores, por lo que asegúrese de que el índice tiene campos numéricos o de texto que se pueden aumentar o ponderar.
Puede tener hasta 100 perfiles de puntuación en un índice (consulte Límites de servicio), pero solo puede especificar un perfil cada vez en una consulta concreta.
Puede usar el clasificador semántico con perfiles de puntuación. Cuando entran en juego varias características de clasificación o relevancia, la clasificación semántica es el último paso. Cómo funciona la puntuación de búsqueda proporciona una ilustración.
Nota:
¿No está familiarizado con los conceptos de relevancia? Consulte Relevancia y puntuación en Búsqueda de Azure AI para más información. También puede ver este segmento de vídeo en YouTube para perfiles de puntuación con resultados clasificados por BM25.
Definición de perfil de puntuación
Un perfil de puntuación se denomina objeto definido en un esquema de índice. Un perfil de puntuación se compone de campos ponderados, funciones y parámetros.
En la siguiente definición se muestra un perfil simple denominado "geo". En este ejemplo se promueven los resultados que tengan el término de búsqueda en el campo hotelName. También se usa la función distance para dar prioridad a los resultados que están a menos de 10 kilómetros de la ubicación actual. Si alguien busca el término "inn" y este término forma parte del nombre del hotel, los documentos que incluyan hoteles con "inn" en un radio de 10 km de la ubicación actual aparecerán primero en los resultados de búsqueda.
"scoringProfiles": [
{
"name":"geo",
"text": {
"weights": {
"hotelName": 5
}
},
"functions": [
{
"type": "distance",
"boost": 5,
"fieldName": "location",
"interpolation": "logarithmic",
"distance": {
"referencePointParameter": "currentLocation",
"boostingDistance": 10
}
}
]
}
]
Para usar este perfil de puntuación, la consulta se formula para especificar el scoringProfile parámetro en la solicitud. Si usa la API REST, las consultas se especifican mediante solicitudes GET y POST. En el siguiente ejemplo, "currentLocation" tiene un delimitador de un solo guión (-). Va seguido de coordenadas de longitud y latitud, donde longitud es un valor negativo.
POST /indexes/hotels/docs&api-version=2024-07-01
{
"search": "inn",
"scoringProfile": "geo",
"scoringParameters": ["currentLocation--122.123,44.77233"]
}
Esta consulta busca el término "inn" y pasa la ubicación actual. Tenga en cuenta que esta consulta incluye otros parámetros, como scoringParameter. Los parámetros de consulta, incluido "scoringParameter", se describen en Buscar en documentos (API REST).
Consulte el ejemplo ampliado para el vector de búsqueda y la búsqueda híbrida y el ejemplo ampliado para la búsqueda de palabras clave para más escenarios.
Funcionamiento de la puntuación de búsqueda en Búsqueda de Azure AI
Los perfiles de puntuación complementan el algoritmo de puntuación predeterminado mediante el aumento de las puntuaciones de coincidencias que cumplen los criterios del perfil. Las funciones de puntuación se aplican a:
- Búsqueda de texto (palabra clave)
- Consultas vectoriales puras
- Consultas híbridas, con subconsultas de texto y vectoriales ejecutadas en paralelo
Para las consultas de texto independientes, los perfiles de puntuación identifican el máximo de 1 000 coincidencias en una búsqueda de clasificación BM25, y las 50 mejores se devuelven en los resultados.
En el caso de los vectores puros, la consulta es de solo vector, pero si los k-documentos coincidentes incluyen campos sin vector con contenido legible para personas, se aplica un perfil de puntuación. El perfil de puntuación revisa el conjunto de resultados potenciando los documentos que coinciden con los criterios del perfil.
Para las consultas de texto en una consulta híbrida, los perfiles de puntuación identifican el máximo de 1 000 coincidencias en una búsqueda de clasificación BM25. Sin embargo, una vez identificados esos 1 000 resultados, se restablece su orden original BM25 para que puedan volver a puntuarse junto con los resultados de los vectores en la ordenación final de Función de clasificación recíproca (RRF), en la que el perfil de puntuación (identificado como "ajuste final de potenciación de documentos" en la ilustración) se aplica a los resultados combinados, junto con ponderación de vectores y clasificación semántica como último paso.
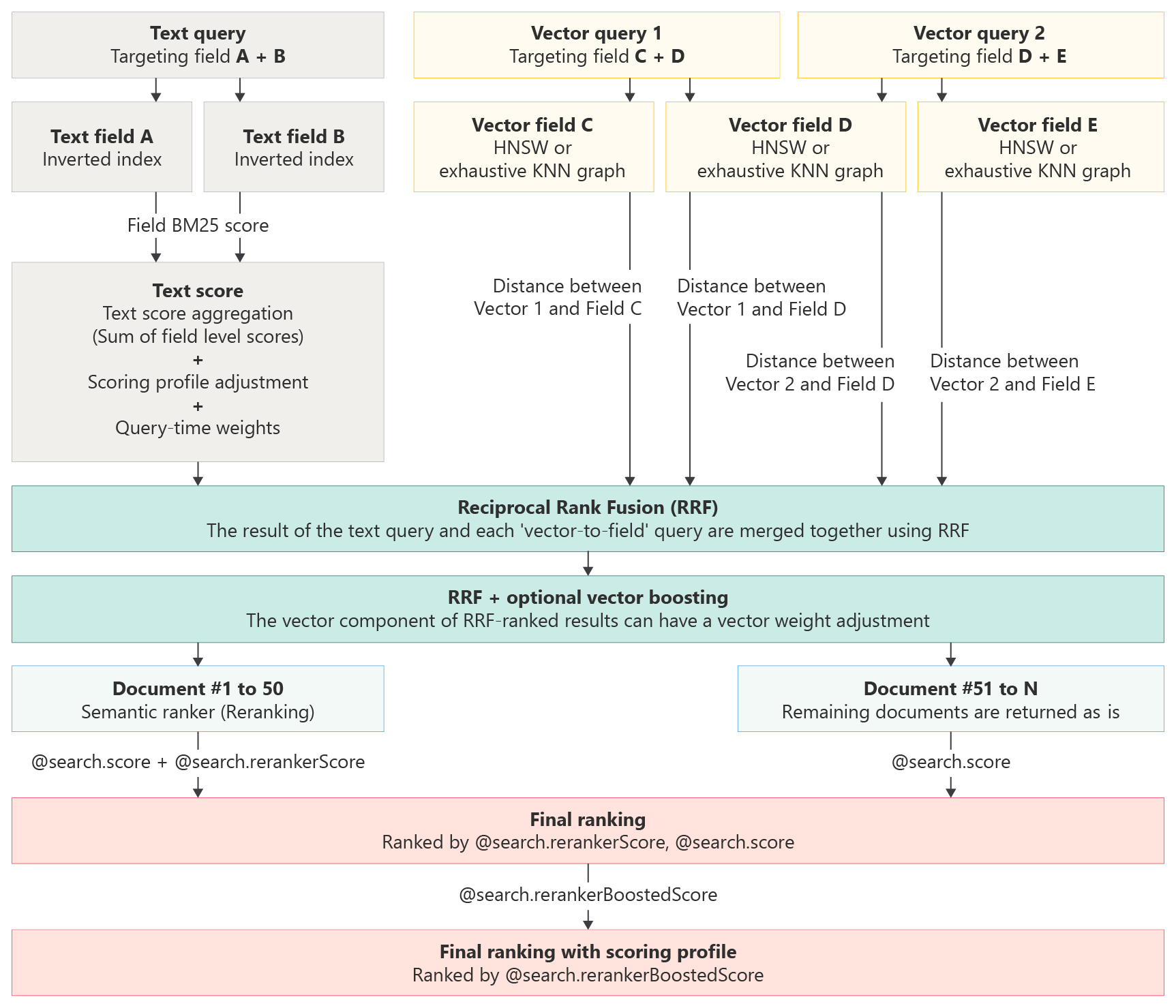
Agregar un perfil de puntuación a un índice de búsqueda
Comience con una definición de índice. Puede agregar y actualizar perfiles de puntuación en un índice existente sin tener que volver a generarlo. Use una solicitud Crear o actualizar índice para publicar una revisión.
Pegue la plantilla incluida en este artículo.
Proporcione un nombre que cumpla las convenciones de nomenclatura de Azure AI Search.
Especifique los criterios de aumento. Un único perfil puede contener campos ponderados de texto, funciones o ambos.
Debe trabajar de forma iterativa con un conjunto de datos que ayude a demostrar o desaprobar la eficacia de un perfil determinado.
Los perfiles de puntuación se pueden definir en Azure Portal como se muestra en la captura de pantalla siguiente, mediante programación por medio de API REST, o bien en los SDK de Azure, como la clase ScoringProfile del SDK de Azure para .NET.

Uso de campos ponderados de texto
Use campos ponderados de texto cuando el contexto de campo sea importante y las consultas incluyan campos de cadena searchable. Por ejemplo, si una consulta incluye el término "airport", es posible que quiera que "airport" en el campo Description tenga más peso que en HotelName.
Los campos ponderados son pares nombre-valor que constan de un campo searchable y un número positivo que se usa como multiplicador. Si la puntuación de campo original de HotelName es 3, la puntuación aumentada para ese campo se convierte en 6, lo que contribuye a una puntuación general más alta para el propio documento primario.
"scoringProfiles": [
{
"name": "boostSearchTerms",
"text": {
"weights": {
"HotelName": 2,
"Description": 5
}
}
}
]
Usar funciones
Use funciones cuando las ponderaciones relativas simples sean insuficientes o no se apliquen, como en el caso de la distancia y la actualización, que son cálculos con datos numéricos. Puede especificar varias funciones por perfil de puntuación. Para más información sobre los tipos de datos de EDM usados en Azure AI Search, consulte Tipos de datos admitidos.
| Función | Descripción | Casos de uso |
|---|---|---|
| distancia | Realice el aumento por proximidad o ubicación geográfica. Esta función solo puede usarse con campos Edm.GeographyPoint . |
Se usa para escenarios "buscar cerca de mí". |
| actualización | Aumente por valores de un campo datetime (Edm.DateTimeOffset). Establezca boostingDuration para especificar un valor que represente un intervalo de tiempo durante el que se produce el aumento. |
Úselo cuando quiera realizar el aumento por fechas más recientes o más antiguas. Clasifique elementos como eventos del calendario con fechas futuras, de manera que los elementos más cercanos al presente tengan una clasificación más alta que aquellos más alejados en el futuro. Un extremo del intervalo se fija a la hora actual. Para aumentar un intervalo de horas en el pasado, use un valor boostingDuration positivo. Para aumentar un intervalo de horas en el futuro, use un valor boostingDuration negativo. |
| magnitud | Modifique las clasificaciones según el intervalo de valores de un campo numérico. El valor debe ser un número entero o un número de punto flotante. En cuanto a las clasificaciones por estrellas de 1 a 4, esto equivaldría a 1. Para los márgenes superiores al 50%, esto equivaldría a 50. Esta función solo puede usarse con campos Edm.Double y Edm.Int. Para la función magnitude, puede invertir el rango, de mayor a menor, si quiere el patrón inverso (por ejemplo, aumentar los artículos de precio inferior más que los de precio superior). Dado un intervalo de precios de 100 $ a 1 $, establezca boostingRangeStart en 100 y boostingRangeEnd en 1 para potenciar los elementos de menor precio. |
Úselo cuando quiera realizar el aumento por margen de beneficio, clasificaciones, recuentos de clics, número de descargas, precio más alto, precio más bajo o recuento de descargas. Cuando dos elementos son pertinentes, en primer lugar se mostrará el elemento con la clasificación superior. |
| etiqueta | Realiza el aumento por las etiquetas comunes a los documentos de búsqueda y las cadenas de consulta. Las etiquetas se proporcionan en un objeto tagsParameter. Esta función solo puede usarse con campos de búsqueda de tipo Edm.String y Collection(Edm.String). |
Úselo cuando tenga campos de etiqueta. Si una etiqueta determinada de la lista es en sí misma una lista delimitada por comas, puede usar un normalizador de texto en el campo para quitar las comas en el momento de la consulta (asignación del carácter de coma a un espacio). Este enfoque "aplanará" la lista para que todos los términos sean una sola cadena larga de términos delimitados por comas. |
Reglas de uso de funciones
- Las funciones solo se pueden aplicar a campos con atributos
filterable. - El tipo de la función ("freshness", "magnitude", "distance", "tag") debe estar en minúsculas.
- Las funciones no pueden incluir valores nulos ni estar vacías.
- Las funciones solo pueden tener un campo único por cada definición de función. Para usar la magnitud dos veces en el mismo perfil, proporcione dos magnitudes de definiciones, una para cada campo.
Plantilla
En esta sección se muestra la sintaxis y la plantilla de perfiles de puntuación. Para obtener una descripción de las propiedades, consulte la referencia de la API REST.
"scoringProfiles": [
{
"name": "name of scoring profile",
"text": (optional, only applies to searchable fields) {
"weights": {
"searchable_field_name": relative_weight_value (positive #'s),
...
}
},
"functions": (optional) [
{
"type": "magnitude | freshness | distance | tag",
"boost": # (positive number used as multiplier for raw score != 1),
"fieldName": "(...)",
"interpolation": "constant | linear (default) | quadratic | logarithmic",
"magnitude": {
"boostingRangeStart": #,
"boostingRangeEnd": #,
"constantBoostBeyondRange": true | false (default)
}
// ( - or -)
"freshness": {
"boostingDuration": "..." (value representing timespan over which boosting occurs)
}
// ( - or -)
"distance": {
"referencePointParameter": "...", (parameter to be passed in queries to use as reference location)
"boostingDistance": # (the distance in kilometers from the reference location where the boosting range ends)
}
// ( - or -)
"tag": {
"tagsParameter": "..."(parameter to be passed in queries to specify a list of tags to compare against target field)
}
}
],
"functionAggregation": (optional, applies only when functions are specified) "sum (default) | average | minimum | maximum | firstMatching"
}
],
"defaultScoringProfile": (optional) "...",
Establecer interpolaciones
Las interpolaciones establecen la forma de la pendiente usada para la puntuación. Dado que la puntuación es de alta a baja, la pendiente siempre disminuye, pero la interpolación determina la curva de la pendiente descendente. Es posible usar las siguientes interpolaciones:
| Interpolación | Descripción |
|---|---|
linear |
En los elementos que están dentro del intervalo máximo y mínimo, la potenciación se aplica en un grado que va decreciendo de manera constante. Lineal es la interpolación predeterminada de un perfil de puntuación. |
constant |
En los elementos que se encuentran dentro del intervalo de inicio y finalización, se aplica una potenciación constante a los resultados de la clasificación. |
quadratic |
En comparación con una interpolación lineal que tiene una potenciación en reducción constante, Cuadrática provoca inicialmente una reducción a un ritmo inferior y, a continuación, a medida que se aproxima el final del intervalo, se reduce a un intervalo muy superior. Esta opción de interpolación no se permite en funciones de puntuación de etiquetas. |
logarithmic |
En comparación con una interpolación lineal que tiene una potenciación en reducción constante, Logarítmica provoca inicialmente una reducción a un ritmo superior y, a continuación, a medida que se aproxima el final del intervalo, se reduce a un intervalo muy inferior. Esta opción de interpolación no se permite en funciones de puntuación de etiquetas. |

Establecer boostingDuration para la función de actualización
boostingDuration es un atributo de la función freshness. Se usa para establecer un período de caducidad después del que se detendrá la potenciación de un documento determinado. Por ejemplo, para potenciar una línea de productos o marca durante un período de promoción de 10 días, debe especificar el período de 10 días como "P10D" para dichos documentos.
boostingDuration debe tener el formato de un valor "dayTimeDuration" XSD (subconjunto restringido de un valor de duración ISO 8601). El patrón para esto es: "P[nD][T[nH][nM][nS]]".
La tabla siguiente proporciona varios ejemplos.
| Duración | boostingDuration |
|---|---|
| 1 día | "P1D" |
| 2 días, 12 horas | "P2DT12H" |
| 15 minutos | "PT15M" |
| 30 días, 5 horas, 10 minutos y 6,334 segundos | "P30DT5H10M6.334S" |
Para obtener más ejemplos, consulte Esquema XML: tipos de datos (sitio web de W3.org).
Ejemplo ampliado para el vector de búsqueda y la búsqueda híbrida
Consulte esta entrada de blog y este cuaderno para ver una demostración del uso de perfiles de puntuación y la mejora de documentos en escenarios vectoriales y de IA generativa.
Ejemplo ampliado para la búsqueda de palabras clave
En el ejemplo siguiente se muestra el esquema de un índice con dos perfiles de puntuación (boostGenre, newAndHighlyRated). Las consultas sobre este índice que incluyen cualquiera de los perfiles como parámetro de consulta usará el perfil para puntuar el conjunto de resultados.
El perfil boostGenre usa campos de texto ponderados, lo que aumenta las coincidencias que se encuentran en los campos albumTitle, genre y artistName. Los campos se aumentan en 1,5, 5 y 2 respectivamente. ¿Por qué se aumenta el género mucho mayor que los demás? Si la búsqueda se realiza sobre los datos que son algo homogéneos (como sucede con "género" en musicstoreindex), es posible que necesite una varianza mayor en los pesos relativos. Por ejemplo, en musicstoreindex, "rock" aparece como género y en las descripciones de género expresadas de forma idéntica. Si desea que el género supere en ponderación a la descripción del género, el campo del género necesitará una ponderación relativa mucho mayor.
{
"name": "musicstoreindex",
"fields": [
{ "name": "key", "type": "Edm.String", "key": true },
{ "name": "albumTitle", "type": "Edm.String" },
{ "name": "albumUrl", "type": "Edm.String", "filterable": false },
{ "name": "genre", "type": "Edm.String" },
{ "name": "genreDescription", "type": "Edm.String", "filterable": false },
{ "name": "artistName", "type": "Edm.String" },
{ "name": "orderableOnline", "type": "Edm.Boolean" },
{ "name": "rating", "type": "Edm.Int32" },
{ "name": "tags", "type": "Collection(Edm.String)" },
{ "name": "price", "type": "Edm.Double", "filterable": false },
{ "name": "margin", "type": "Edm.Int32", "retrievable": false },
{ "name": "inventory", "type": "Edm.Int32" },
{ "name": "lastUpdated", "type": "Edm.DateTimeOffset" }
],
"scoringProfiles": [
{
"name": "boostGenre",
"text": {
"weights": {
"albumTitle": 1.5,
"genre": 5,
"artistName": 2
}
}
},
{
"name": "newAndHighlyRated",
"functions": [
{
"type": "freshness",
"fieldName": "lastUpdated",
"boost": 10,
"interpolation": "quadratic",
"freshness": {
"boostingDuration": "P365D"
}
},
{
"type": "magnitude",
"fieldName": "rating",
"boost": 10,
"interpolation": "linear",
"magnitude": {
"boostingRangeStart": 1,
"boostingRangeEnd": 5,
"constantBoostBeyondRange": false
}
}
]
}
],
"suggesters": [
{
"name": "sg",
"searchMode": "analyzingInfixMatching",
"sourceFields": [ "albumTitle", "artistName" ]
}
]
}