Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En Búsqueda de Azure AI, si tiene un índice vectorial, en este artículo se explica cómo:
En este artículo se usa REST para ilustrarlo. Después de comprender el flujo de trabajo básico, continúe con los ejemplos de código del SDK de Azure en el repositorio azure-search-vector-samples , que proporciona soluciones de un extremo a otro que incluyen consultas vectoriales.
También puede usar el Explorador de búsqueda en Azure Portal.
Requisitos previos
Un servicio Azure AI Search en cualquier región y de cualquier nivel.
Índice vectorial. Busque una
vectorSearchsección en el índice para confirmar su presencia.De manera opcional, agregue un vectorizador al índice para la conversión integrada de texto a vector o de imagen a vector durante las consultas.
Visual Studio Code con un cliente de REST y datos de ejemplo si desea ejecutar estos ejemplos por su cuenta. Para empezar a trabajar con el cliente REST, consulte Inicio rápido: Búsqueda de texto completo mediante REST.
Conversión de una entrada de cadena de consulta en un vector
Para consultar un campo vectorial, la propia consulta debe ser un vector.
Un enfoque para convertir la cadena de consulta de texto de un usuario en su representación vectorial es llamar a una biblioteca o API de inserción en el código de la aplicación. Como procedimiento recomendado, use siempre los mismos modelos de inserción usados para generar inserciones en los documentos de origen. Puede encontrar ejemplos de código que muestran cómo generar incrustaciones en el repositorio azure-search-vector-samples .
Un segundo enfoque consiste en usar la vectorización integrada, ahora disponible con carácter general, para que Azure AI Search controle las entradas y salidas de vectorización de consulta.
Este es un ejemplo de API de REST de una cadena de consulta enviada a una implementación de un modelo de inserción de Azure OpenAI:
POST https://{{openai-service-name}}.openai.azure.com/openai/deployments/{{openai-deployment-name}}/embeddings?api-version={{openai-api-version}}
Content-Type: application/json
api-key: {{admin-api-key}}
{
"input": "what azure services support generative AI'"
}
La respuesta esperada es 202 para una llamada correcta al modelo implementado.
El embedding campo del cuerpo de la respuesta es la representación vectorial de la cadena inputde consulta . Con fines de prueba, copiaría el valor de la embedding matriz en vectorQueries.vector en una solicitud de consulta mediante la sintaxis que se muestra en las siguientes secciones.
La respuesta real a esta llamada POST al modelo implementado incluye 1536 incrustaciones. Para mejorar la legibilidad, en este ejemplo solo se muestran los primeros vectores.
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.009171937,
0.018715322,
...
-0.0016804502
]
}
],
"model": "ada",
"usage": {
"prompt_tokens": 7,
"total_tokens": 7
}
}
En este enfoque, el código de la aplicación es responsable de conectarse a un modelo, generar inserciones y controlar la respuesta.
Solicitud de consulta vectorial
En esta sección se muestra la estructura básica de una consulta vectorial. Puede usar Azure Portal, las API de REST o los SDK de Azure para formular una consulta vectorial.
Si migra desde 2023-07-01-Preview, hay cambios importantes. Para obtener más información, consulte Actualización a la API REST más reciente.
2024-07-01 es la versión estable de la API REST de Search POST. Esta versión admite:
vectorQuerieses la construcción para vector de búsqueda.vectorQueries.kindse establece envectorpara una matriz vectorial o entextsi la entrada es una cadena y si usted tiene un vectorizador.vectorQueries.vectores la consulta (una representación vectorial del texto o una imagen).vectorQueries.exhaustive(opcional) invoca el KNN exhaustivo en el momento de la consulta, incluso si el campo está indexado para HNSW.vectorQueries.fields(opcional) tiene como destino campos específicos para la ejecución de consultas (hasta 10 por consulta).vectorQueries.weight(opcional) especifica el peso relativo de cada consulta vectorial incluida en las operaciones de búsqueda. Para obtener más información, consulte Ponderación de vectores.vectorQueries.kes el número de coincidencias que se van a devolver.
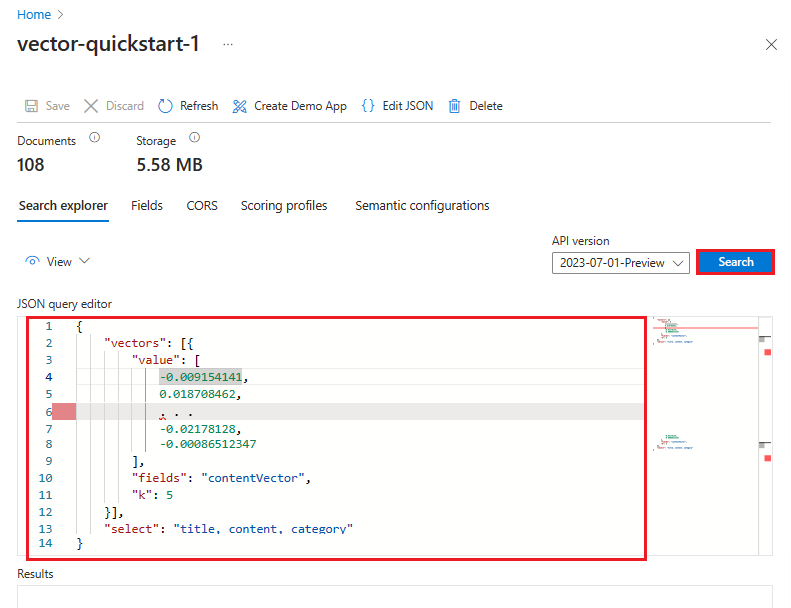
En el ejemplo siguiente, el vector es una representación de esta cadena: "what Azure services support full text search". La consulta tiene como destino el contentVector campo y devuelve k los resultados. El vector real tiene 1536 incrustaciones, que se recortan en este ejemplo para mejorar la legibilidad.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2024-07-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector",
"weight": 0.5,
"k": 5
}
]
}
Respuesta de consulta vectorial
En Búsqueda de Azure AI, las respuestas de consulta constan de todos los campos retrievable de manera predeterminada. Sin embargo, es habitual limitar los resultados de búsqueda a un subconjunto de campos retrievable al enumerarlos en una instrucción select.
En una consulta vectorial, considere detenidamente si necesita campos vectoriales en una respuesta. Los campos vectoriales no son legibles por el usuario, por lo que si está insertando una respuesta a una página web, debe elegir campos no vectores que representen el resultado. Por ejemplo, si la consulta se ejecuta en contentVector, podría devolver content en su lugar.
Si desea campos vectoriales en el resultado, este es un ejemplo de la estructura de respuesta. contentVector es una matriz de cadenas de incrustaciones, que se recortan en este ejemplo para mejorar la legibilidad. La puntuación de búsqueda indica relevancia. Se incluyen otros campos no vectoriales para el contexto.
{
"@odata.count": 3,
"value": [
{
"@search.score": 0.80025613,
"title": "Azure Search",
"category": "AI + Machine Learning",
"contentVector": [
-0.0018343845,
0.017952163,
0.0025753193,
...
]
},
{
"@search.score": 0.78856903,
"title": "Azure Application Insights",
"category": "Management + Governance",
"contentVector": [
-0.016821077,
0.0037742127,
0.016136652,
...
]
},
{
"@search.score": 0.78650564,
"title": "Azure Media Services",
"category": "Media",
"contentVector": [
-0.025449317,
0.0038463024,
-0.02488436,
...
]
}
]
}
Puntos clave:
kdetermina cuántos resultados vecinos más cercanos se devuelven, en este caso, tres. Las consultas vectoriales siempre devuelvenkresultados, suponiendo que existen al menoskdocumentos, incluso si algunos documentos tienen mala similitud. Esto se debe a que el algoritmo encuentra loskvecinos más cercanos al vector de consulta.El algoritmo de búsqueda vectorial determina el
@search.score.Los campos de los resultados de la búsqueda son todos campos
retrievableo campos de una cláusulaselect. Durante la ejecución de la consulta vectorial, la coincidencia se realiza solo en los datos vectoriales. Sin embargo, una respuesta puede incluir cualquier camporetrievableen un índice. Dado que no hay forma de decodificar un resultado de un campo vectorial, la inclusión de campos de texto no vectoriales es útil para hacer sus valores legibles para los humanos.
Varios campos vectoriales
Puede establecer la vectorQueries.fields propiedad en varios campos vectoriales. La consulta vectorial se ejecuta en cada campo vectorial que proporcione en la lista de fields. Puede especificar hasta 10 campos.
Al consultar varios campos vectoriales, asegúrese de que cada uno contiene incrustaciones del mismo modelo de inserción. La consulta también debe generarse a partir del mismo modelo de inserción.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2024-07-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector, titleVector",
"k": 5
}
]
}
Consultas de varios vectores
El vector de búsqueda de varias consultas envía varias consultas a través de varios campos vectoriales en el índice de búsqueda. Este tipo de consulta se usa normalmente con modelos como CLIP para la búsqueda bidireccional, donde el mismo modelo puede vectorizar texto e imágenes.
En el ejemplo de consulta siguiente se busca similitud tanto en myImageVector como en myTextVector, pero se envían dos incrustaciones de consulta respectivas, cada una ejecutándose en paralelo. El resultado de esta consulta se puntua mediante la fusión de clasificación recíproca (RRF).
vectorQueriesproporciona una matriz de consultas vectoriales.vectorcontiene los vectores de imagen y los vectores de texto en el índice de búsqueda. Cada instancia es una consulta independiente.fieldsespecifica el campo vectorial que se va a establecer como destino.kes el número de coincidencias de vecino más próximo que se van a incluir en los resultados.
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"fields": "myimagevector",
"k": 5
},
{
"kind": "vector"
"vector": [
-0.002222222,
0.018708462,
-0.013770515,
. . .
],
"fields": "mytextvector",
"k": 5
}
]
}
Los índices de búsqueda no pueden almacenar imágenes. Suponiendo que el índice incluye un campo para el archivo de imagen, los resultados de la búsqueda incluirían una combinación de texto e imágenes.
Consulta con vectorización integrada
En esta sección se muestra una consulta vectorial que invoca la vectorización integrada para convertir una consulta de texto o imagen en un vector. Se recomienda la API de REST estable 2024-07-01, el Explorador de búsqueda o los paquetes más recientes del SDK de Azure para esta característica.
Un requisito previo es un índice de búsqueda que tiene un vectorizador configurado y asignado a un campo vectorial. El vectorizador proporciona información de conexión a un modelo de inserción que se usa en el momento de la consulta.
El Explorador de búsqueda admite la vectorización integrada en el momento de la consulta. Si el índice contiene campos vectoriales y tiene un vectorizador, puede usar la conversión de texto a vector integrada.
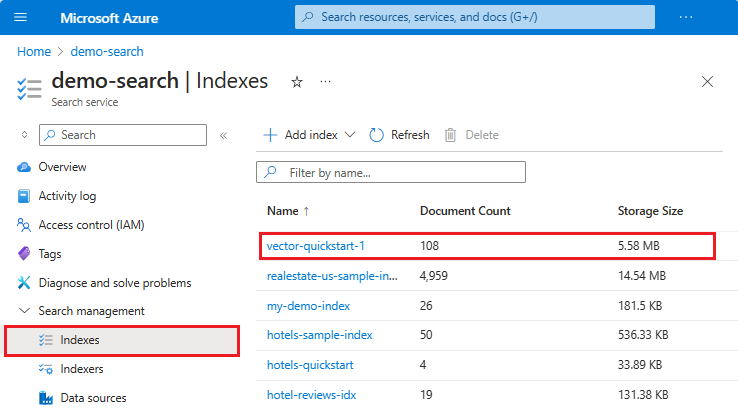
Inicie sesión en Azure Portal y busque su servicio de búsqueda.
En el menú de la izquierda, seleccione Administración de búsqueda>Índices, y, a continuación, seleccione su índice.
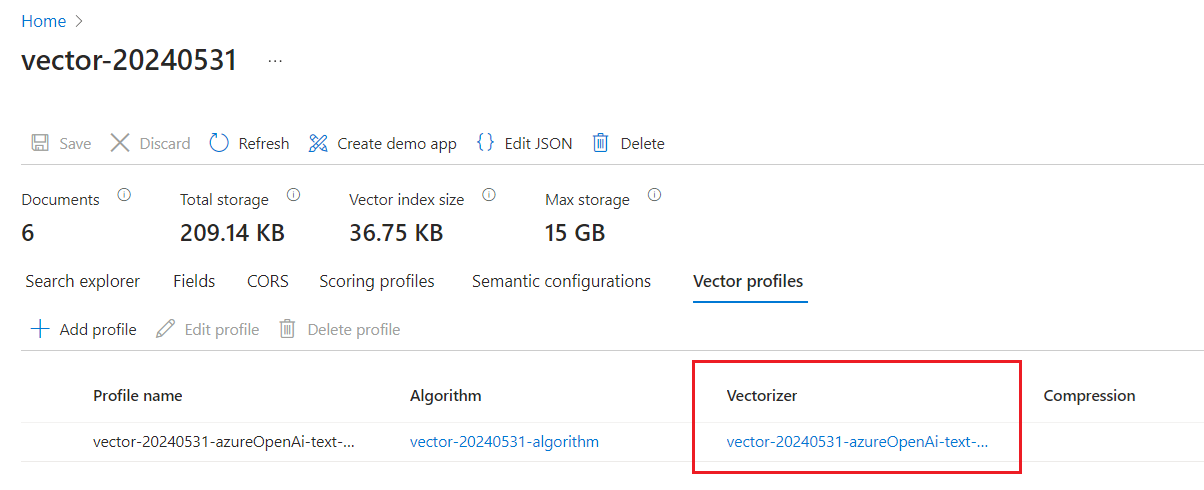
Seleccione la pestaña Perfiles de vector para confirmar que tiene un vectorizador.
Seleccione la pestaña Explorador de búsqueda . Con la vista de consulta predeterminada, puede escribir una cadena de texto en la barra de búsqueda. El vectorizador integrado convierte la cadena en un vector, realiza la búsqueda y devuelve resultados.
Como alternativa, puede seleccionar Ver>vista JSON para ver o modificar la consulta. Si los vectores están presentes, el Explorador de búsqueda configura automáticamente una consulta vectorial. Puede usar la vista JSON para seleccionar campos para usarlos en la búsqueda y la respuesta, agregar filtros y construir consultas más avanzadas, como consultas híbridas. Para ver un ejemplo de JSON, seleccione la pestaña API rest de esta sección.
Número de resultados clasificados en una respuesta de consulta vectorial
Una consulta vectorial especifica el parámetro k, que determina cuántas coincidencias se devuelven en los resultados. El motor de búsqueda siempre devuelve un número k de coincidencias. Si k es mayor que el número de documentos del índice, el número de documentos determina el límite superior de lo que se puede devolver.
Si está familiarizado con la búsqueda de texto completo, sabe esperar cero resultados si el índice no contiene un término o frase. Sin embargo, en la búsqueda vectorial, la operación de búsqueda identifica los vecinos más cercanos y siempre devuelve k resultados, incluso si los vecinos más cercanos no son tan similares. Es posible obtener resultados para consultas sin sentido o fuera del tema, especialmente si no usa avisos para establecer límites. Los resultados menos relevantes tienen una puntuación de similitud peor, pero siguen siendo los vectores "más próximos" si no hay nada más cerca. Por lo tanto, una respuesta sin resultados significativos todavía puede devolver k resultados, pero la puntuación de similitud de cada resultado sería baja.
Un enfoque híbrido que incluye la búsqueda de texto completo puede mitigar este problema. Otra solución consiste en establecer un umbral mínimo en la puntuación de búsqueda, pero solo si la consulta es una consulta de vector único puro. Las consultas híbridas no son propicias para los umbrales mínimos porque los rangos de RRF son mucho más pequeños y volátiles.
Los parámetros de consulta que afectan al recuento de resultados incluyen:
"k": nresultados para consultas de solo vector."top": nresultados de consultas híbridas que incluyen unsearchparámetro.
Ambos k y top son opcionales. Cuando no se especifica, el número predeterminado de resultados en una respuesta es 50. Puede configurar top y skip para navegar por más resultados o cambiar el valor predeterminado.
Algoritmos de clasificación usados en una consulta vectorial
La clasificación de los resultados se calcula mediante:
- Métrica de similitud.
- RRF si hay varios conjuntos de resultados de búsqueda.
Métrica de similitud
Métrica de similitud especificada en la sección de índice vectorSearch para una consulta de solo vector. Los valores válidos son cosine, euclidean y dotProduct.
Los modelos de inserción de Azure OpenAI usan similitud de coseno, por lo que si usa modelos de inserción de Azure OpenAI, cosine es la métrica recomendada. Otras métricas de clasificación admitidas incluyen euclidean y dotProduct.
RRF
Se crean varios conjuntos si la consulta tiene como destino varios campos vectoriales, ejecuta varias consultas vectoriales en paralelo o es un híbrido de búsqueda de vectores y texto completo, con o sin clasificación semántica.
Durante la ejecución de la consulta, una consulta vectorial solo puede tener como destino un índice de vector interno. Para varios campos vectoriales y varias consultas vectoriales, el motor de búsqueda genera varias consultas que tienen como destino los índices vectoriales respectivos de cada campo. La salida es un conjunto de resultados clasificados para cada consulta, que se fusionan mediante RRF. Para obtener más información, consulte Puntuación de relevancia mediante la fusión de clasificación recíproca.
Ponderación de vectores
Agregue un parámetro de consulta weight para especificar los pesos relativos de cada consulta vectorial incluida en las operaciones de búsqueda. Este valor se usa al combinar los resultados de varias listas de clasificación generadas por dos o más consultas vectoriales en la misma solicitud, o desde la parte vectorial de una consulta híbrida.
El valor predeterminado es 1.0 y el valor debe ser un número positivo mayor que cero.
Los pesos se usan al calcular las puntuaciones de RRF de cada documento. El cálculo es un multiplicador del weight valor con respecto a la puntuación de clasificación del documento dentro de su conjunto de resultados respectivo.
El ejemplo siguiente es una consulta híbrida con dos cadenas de consulta vectoriales y una cadena de texto. Los pesos se asignan a las consultas vectoriales. La primera consulta es 0,5 o la mitad del peso, lo que reduce su importancia en la solicitud. La segunda consulta vectorial es el doble de importante.
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-07-01
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my_first_vector_field",
"k": 10,
"weight": 0.5
},
{
"kind": "vector",
"vector": [4.0, 5.0, 6.0],
"fields": "my_second_vector_field",
"k": 10,
"weight": 2.0
}
],
"search": "hello world"
}
La ponderación de vectores solo se aplica a los vectores. La consulta de texto de este ejemplo, "hello world", tiene un peso neutro implícito de 1,0. Sin embargo, en una consulta híbrida, puede aumentar o disminuir la importancia de los campos de texto estableciendo maxTextRecallSize.
Establezca límites para excluir los resultados con puntuaciones bajas (vista previa)
Dado que la búsqueda de vecino más próximo siempre devuelve los vecinos k solicitados, es posible obtener varias coincidencias de puntuación baja como parte de cumplir el requisito de número de k en los resultados de búsqueda. Para excluir los resultados de búsqueda de baja puntuación, puede agregar un threshold parámetro de consulta que filtre los resultados en función de una puntuación mínima. El filtrado se produce antes de fusionar los resultados de diferentes conjuntos de recuperación.
Este parámetro todavía está en versión preliminar. Se recomienda la versión de la API REST 2024-05-01-preview .
En este ejemplo, todas las coincidencias que tienen una puntuación inferior a 0,8 se excluyen de los resultados de búsqueda vectorial, incluso si el número de resultados está por debajo kde .
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my-cosine-field",
"threshold": {
"kind": "vectorSimilarity",
"value": 0.8
}
}
]
}
MaxTextSizeRecall para la búsqueda híbrida (vista previa)
Las consultas vectoriales se suelen usar en construcciones híbridas que incluyen campos no vectores. Si detecta que los resultados clasificados por BM25 están representados por encima o por debajo de lo que deberían en los resultados de una consulta híbrida, puede establecer maxTextRecallSize para aumentar o reducir los resultados clasificados por BM25 proporcionados para la clasificación híbrida.
Solo puede establecer esta propiedad en solicitudes híbridas que incluyan tanto los componentes search como vectorQueries.
Este parámetro todavía está en versión preliminar. Se recomienda la versión de la API REST 2024-05-01-preview .
Para obtener más información, vea Establecer maxTextRecallSize: Creación de una consulta híbrida.
Pasos siguientes
Como paso siguiente, revise los ejemplos de código de consulta vectorial en Python, C# o JavaScript.