Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Para garantizar la ingesta de datos completa e ininterrumpida en el servicio Microsoft Sentinel, realice un seguimiento del estado, la conectividad y el rendimiento de los conectores de datos.
Las características siguientes le permiten realizar esta supervisión desde Microsoft Sentinel:
Libro de supervisión del estado de recopilación de datos: este libro proporciona monitores adicionales, detecta anomalías y proporciona información sobre el estado de ingesta de datos del área de trabajo. Puede usar la lógica del libro para supervisar el estado general de los datos ingeridos y crear vistas personalizadas y alertas basadas en reglas.
Tabla de datos SentinelHealth (versión preliminar): la consulta de esta tabla proporciona información sobre los desfases de estado, como los eventos de error más recientes por conector o los conectores con cambios de estados correctos a estados con error, que puede usar para crear alertas y otras acciones automatizadas. La tabla de datos SentinelHealth solo se admite actualmente para conectores de datos concretos.
Importante
La tabla de datos SentinelHealth se encuentra actualmente en VERSIÓN PRELIMINAR. Consulte Términos de uso complementarios para las Versiones preliminares de Microsoft Azure para conocer los términos legales adicionales que se aplican a las características de Azure que se encuentran en la versión beta, en versión preliminar o que todavía no se han publicado para que estén disponibles con carácter general.
Vea el mantenimiento y el estado de los sistemas SAP conectados: revise la información de estado de los sistemas SAP en el conector de datos de SAP y use una plantilla de regla de alerta para obtener información sobre el estado de la recopilación de datos del agente de SAP.
Uso del libro de supervisión de estado
Para empezar, instale el libro Supervisión del estado de la recopilación de datos desde el Centro de contenido y vea o cree una copia de la plantilla desde la sección Libros de Microsoft Sentinel.
Para Microsoft Sentinel en Azure Portal, en Administración de contenido, seleccione Centro de contenido.
Para Microsoft Sentinel en el Portal de Defender, seleccione Microsoft Sentinel>Administración de contenidos >Centro de contenido.En el Centro de contenidos, escriba estado en la barra de búsqueda y seleccione Supervisión del estado de conectores de datos entre los resultados.
Seleccione Instalar en el panel de detalles. Cuando vea un mensaje de notificación que indica que el libro está instalado, o si en lugar de Instalar, ve Configuración, continúe con el paso siguiente.
En Microsoft Sentinel, en Administración de amenazas, seleccione Libros.
En la página Libros, seleccione la pestaña Plantillas, escriba estado en la barra de búsqueda y seleccione Supervisión del estado de recopilación de datos entre los resultados.
Seleccione Ver plantilla para usar el libro tal cual, o bien seleccione Guardar para crear una copia modificable del libro. Cuando se cree la copia, seleccione Ver libro guardado.
Una vez dentro del libro, seleccione primero la suscripción y el área de trabajo que desea ver y, a continuación, defina el intervalo de tiempo para filtrar los datos según sus necesidades. Use el conmutador de alternancia Mostrar ayuda para mostrar la explicación en contexto del libro.
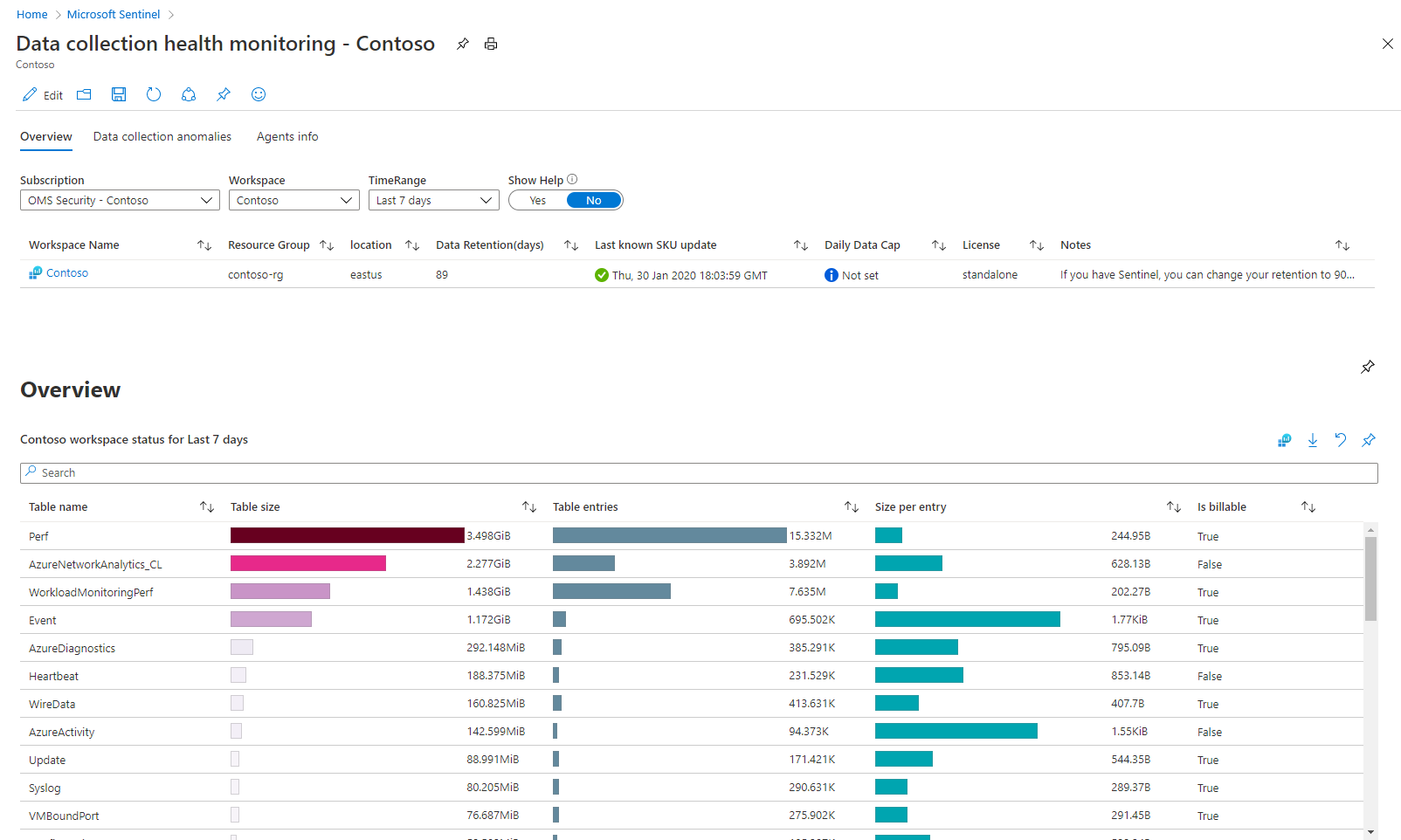

Hay tres secciones con pestañas en este libro:
En la pestaña Información general se muestra el estado general de la ingesta de datos en el área de trabajo seleccionada: medidas de volumen, tasas de EPS y hora de recepción del último registro.
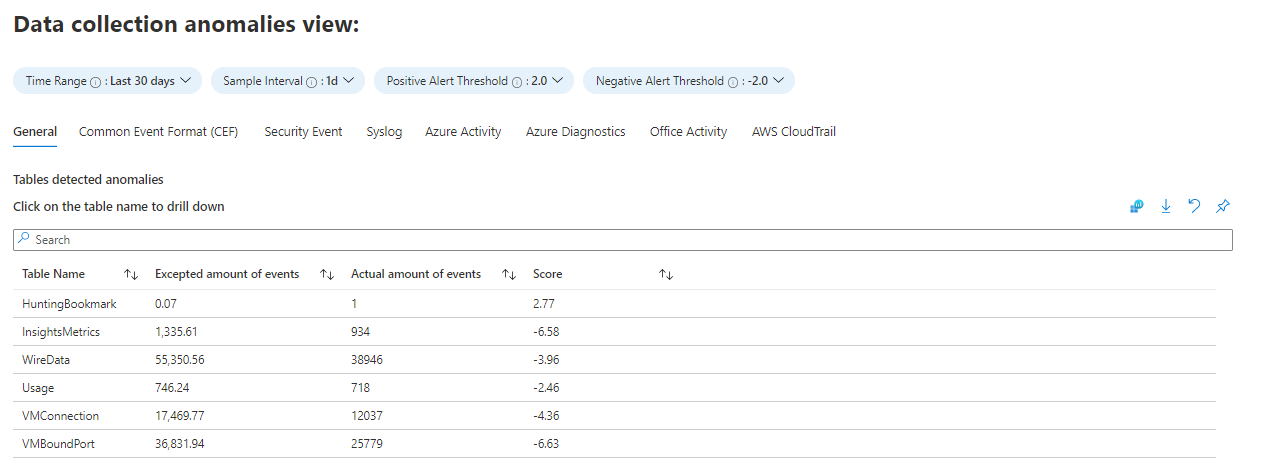
La pestaña Data collection anomalies (Anomalías de recopilación de datos) lo ayudará a detectar anomalías en el proceso de recopilación de datos, por tabla y origen de datos. Cada pestaña presenta anomalías para una tabla determinada (la pestaña General incluye una colección de tablas). Las anomalías se calculan mediante la función series_decompose_anomalies() , que devuelve una puntuación de las anomalías. Más información sobre esta función. Establezca los siguientes parámetros para la función que se va a evaluar:
AnomaliesTimeRange: este selector de tiempo se aplica solo a la vista de las anomalías de la recopilación de datos.
SampleInterval: el intervalo de tiempo para el cual se muestrean los datos. La puntuación de las anomalías se calcula solo en los datos del último intervalo.
PositiveAlertThreshold: este valor define el umbral de puntuación de anomalías positiva. Acepta valores decimales.
NegativeAlertThreshold: este valor define el umbral de puntuación de anomalías negativa. Acepta valores decimales.
En la pestaña Información del agente se muestra información sobre el estado de los agentes instalados en las distintas máquinas, ya sea una máquina virtual de Azure, otra máquina virtual en la nube o una máquina virtual local o física. Supervise la ubicación del sistema, el estado de latido y la latencia, la memoria disponible y el espacio en disco y las operaciones del agente.
En esta sección, debe seleccionar la pestaña que describe el entorno de las máquinas: elija la pestaña Máquinas administradas por Azure si quiere ver solo las máquinas administradas por Azure Arc; elija la pestaña Todas las máquinas para ver las máquinas administradas y que no son de Azure con el agente de Azure Monitor instalado.



Uso de la tabla de datos SentinelHealth (versión preliminar pública)
Para obtener datos de mantenimiento del conector de datos de la tabla de datos SentinelHealth, primero debe activar la característica de mantenimiento de Microsoft Sentinel para el área de trabajo. Para obtener más información, consulte Activar la supervisión de estado para Microsoft Sentinel.
Una vez que active la característica de mantenimiento, la tabla de datos SentinelHealth se crea en el primer evento de éxito o error generado para los conectores de datos.
Conectores de datos admitidos
La tabla de datos SentinelHealth solo se admite actualmente para los conectores de datos siguientes:
- Amazon Web Services (CloudTrail y S3)
- Dynamics 365
- Office 365
- Microsoft Defender para punto de conexión
- Inteligencia sobre amenazas: TAXII
- Plataformas de inteligencia sobre amenazas
- Cualquier conector basado en Codeless Connector Framework
Descripción de los eventos de la tabla SentinelHealth
Los siguientes tipos de eventos de mantenimiento se registran en la tabla SentinelHealth:
Cambio de estado de captura de datos. Se registra una vez por hora, siempre y cuando el estado de un conector de datos permanezca estable, con eventos continuos de éxito o de error. Mientras el estado de un conector de datos no cambie, la supervisión solo funciona cada hora para evitar la auditoría redundante y reducir el tamaño de la tabla. Si el estado del conector de datos tiene errores continuos, se incluyen detalles adicionales sobre los errores en la columna ExtendedProperties.
Si el estado del conector de datos cambia, ya sea de correcto a error, de error a correcto o tiene cambios en los motivos del error, el evento se registra inmediatamente para permitir que el equipo tome medidas proactivas e inmediatas.
Los errores potencialmente transitorios, como la limitación del servicio de origen, solo se registran después de haber continuado durante más de 60 minutos. Estos 60 minutos permiten a Microsoft Sentinel superar un problema transitorio en el back-end y ponerse al día con los datos, sin necesidad de ninguna acción del usuario. Los errores que definitivamente no son transitorios se registran de manera inmediata.
Resumen de errores. Se registra una vez por hora, por conector y por área de trabajo, con un resumen de errores agregado. Los eventos de resumen de errores solo se crean cuando el conector ha experimentado errores de sondeo durante la hora determinada. Contienen detalles adicionales proporcionados en la columna ExtendedProperties, como el período de tiempo durante el que se ha consultado la plataforma de origen del conector y una lista exclusiva de los errores detectados durante el período de tiempo.
Para más información, vea Esquema de columnas de la tabla SentinelHealth.
Ejecución de consultas para detectar desfases de estado
Cree consultas en la tabla SentinelHealth para ayudarle a detectar desfases de estado en los conectores de datos. Por ejemplo:
Detectar los eventos de error más recientes por conector:
SentinelHealth
| where TimeGenerated > ago(3d)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId
| where Status == 'Failure'
Detectar conectores con cambios de estado de error a correcto:
let latestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| project TimeGenerated, SentinelResourceName, SentinelResourceId, LastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
let nextTolatestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| join kind = leftanti (latestStatus) on SentinelResourceName, SentinelResourceId, TimeGenerated
| project TimeGenerated, SentinelResourceName, SentinelResourceId, NextToLastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
latestStatus
| join kind=inner (nextTolatestStatus) on SentinelResourceName, SentinelResourceId
| where NextToLastStatus == 'Failure' and LastStatus == 'Success'
Detectar conectores con cambios de estado correcto a estado con error:
let latestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| project TimeGenerated, SentinelResourceName, SentinelResourceId, LastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
let nextTolatestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| join kind = leftanti (latestStatus) on SentinelResourceName, SentinelResourceId, TimeGenerated
| project TimeGenerated, SentinelResourceName, SentinelResourceId, NextToLastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
latestStatus
| join kind=inner (nextTolatestStatus) on SentinelResourceName, SentinelResourceId
| where NextToLastStatus == 'Success' and LastStatus == 'Failure'
Vea más información sobre los siguientes elementos usados en los ejemplos anteriores, en la documentación de Kusto:
- Operador let
- Operador where
- Operador project
- resumir operador
- unir operador
- función ago()
- función de agregación arg_max()
Para más información sobre KQL, consulte Introducción al Lenguaje de consulta Kusto (KQL).
Otros recursos:
Configuración de alertas y acciones automatizadas para problemas de estado
Aunque puede usar las reglas de análisis de Microsoft Sentinel para configurar la automatización en los registros de Microsoft Sentinel, si quiere recibir una notificación y tomar medidas inmediatas para los desfases de estado en los conectores de datos, se recomienda usar reglas de alerta de Azure Monitor.
Por ejemplo:
En una regla de alertas de Azure Monitor, seleccione el área de trabajo de Microsoft Sentinel como ámbito de la regla y Búsqueda de registros personalizada como primera condición.
Personalice la lógica de alerta según sea necesario, como la frecuencia o la duración de la búsqueda y, después, use consultas para buscar los desfases de estado.
Para las acciones de regla, seleccione un grupo de acciones existente o cree uno según sea necesario para configurar notificaciones de inserción u otras acciones automatizadas, como desencadenar una aplicación lógica, un webhook o una función de Azure en el sistema.
Para más información, vea Información general sobre las alertas en Microsoft Azure y Registro de alertas de Azure Monitor.
Pasos siguientes
- Descubra qué son las auditorías y el seguimiento de estado en Microsoft Sentinel.
- Activación de la auditoría y seguimiento de estado en Microsoft Sentinel.
- Supervisión del estado de las reglas de automatización y los cuadernos de estrategias.
- Supervisión del estado y la integridad de las reglas de análisis.
- Consulte más información sobre los esquemas de las tablas SentinelHealth y SentinelAudit.