Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Este artículo explica cómo puede mejorar el rendimiento de los recursos compartidos de archivos Azure del sistema de archivos de red (NFS).
Se aplica a
| Modelo de administración | Modelo de facturación | Nivel multimedia | Redundancia | Pequeñas y Medianas Empresas (PYME) | NFS |
|---|---|---|---|---|---|
| Microsoft.Storage | Aprovisionado v2 | HDD (estándar) | Local (LRS) |
|
|
| Microsoft.Storage | Aprovisionado v2 | HDD (estándar) | Zona (ZRS) |
|
|
| Microsoft.Storage | Aprovisionado v2 | HDD (estándar) | Geo (GRS) |
|
|
| Microsoft.Storage | Aprovisionado v2 | HDD (estándar) | GeoZone (GZRS) |
|
|
| Microsoft.Storage | Aprovisionado v1 | SSD (Premium) | Local (LRS) |
|
|
| Microsoft.Storage | Aprovisionado v1 | SSD (Premium) | Zona (ZRS) |
|
|
| Microsoft.Storage | Pago por uso | HDD (estándar) | Local (LRS) |
|
|
| Microsoft.Storage | Pago por uso | HDD (estándar) | Zona (ZRS) |
|
|
| Microsoft.Storage | Pago por uso | HDD (estándar) | Geo (GRS) |
|
|
| Microsoft.Storage | Pago por uso | HDD (estándar) | GeoZone (GZRS) |
|
|
Aumento del tamaño de la lectura anticipada para mejorar el rendimiento de lectura
El parámetro del kernel read_ahead_kb en Linux representa la cantidad de datos que deben "leerse de forma anticipada" o capturarse previamente durante una operación de lectura secuencial. Las versiones del kernel de Linux anteriores a la 5.4 establecen el valor de lectura anticipada en el equivalente a 15 veces el del sistema de archivos montado rsize, que representa la opción de montaje del lado del cliente para el tamaño del búfer de lectura. Esto establece el valor de lectura anticipada lo suficientemente alto como para mejorar el rendimiento de lectura secuencial del cliente en la mayoría de los casos.
Sin embargo, a partir de la versión 5.4 del kernel de Linux, el cliente NFS de Linux usa un valor predeterminado de read_ahead_kb de 128 KiB. Este valor pequeño puede reducir la cantidad de rendimiento de lectura para archivos grandes. Los clientes que actualizan desde versiones de Linux con el mayor valor de lectura anticipada a las versiones con el valor predeterminado de 128 KiB podrían experimentar una disminución en el rendimiento de lectura secuencial.
En el caso de los kernels de Linux 5.4 o posteriores, se recomienda establecer de forma persistente el valor de read_ahead_kb en 15 MiB para mejorar el rendimiento.
Para cambiar este valor, establezca el tamaño de lectura anticipada agregando una regla en udev, un administrador de dispositivos del kernel de Linux. Siga estos pasos:
En un editor de texto, cree el archivo /etc/udev/rules.d/99-nfs.rules escribiendo y guardando el texto siguiente:
SUBSYSTEM=="bdi" \ , ACTION=="add" \ , PROGRAM="/usr/bin/awk -v bdi=$kernel 'BEGIN{ret=1} {if ($4 == bdi) {ret=0}} END{exit ret}' /proc/fs/nfsfs/volumes" \ , ATTR{read_ahead_kb}="15360"En una consola, aplique la regla udev ejecutando el comando udevadm como superusuario y vuelva a cargar los archivos de reglas y otras bases de datos. Solo tiene que ejecutar este comando una vez para que udev sea consciente del nuevo archivo.
sudo udevadm control --reload
NFS nconnect
NFS nconnect es una opción de montaje del lado cliente para recursos compartidos de archivos NFS que permite usar varias conexiones TCP entre el cliente y el recurso compartido de archivos NFS.
Ventajas
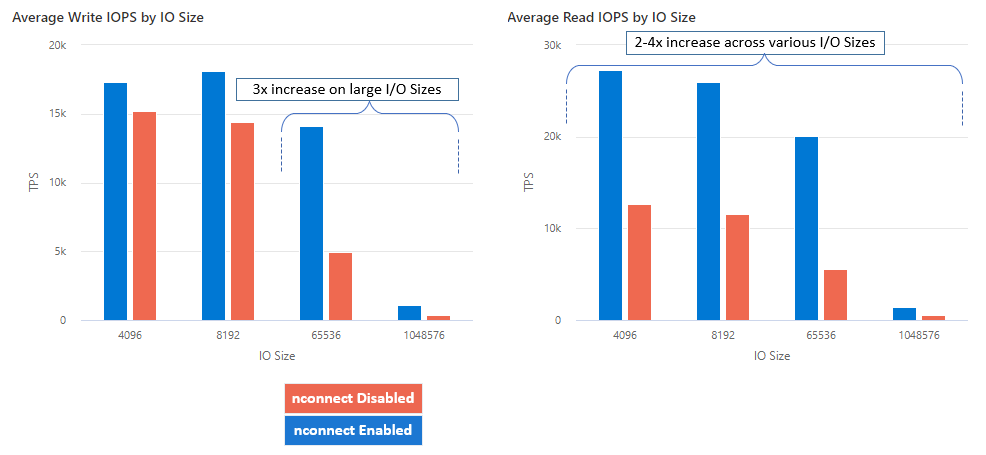
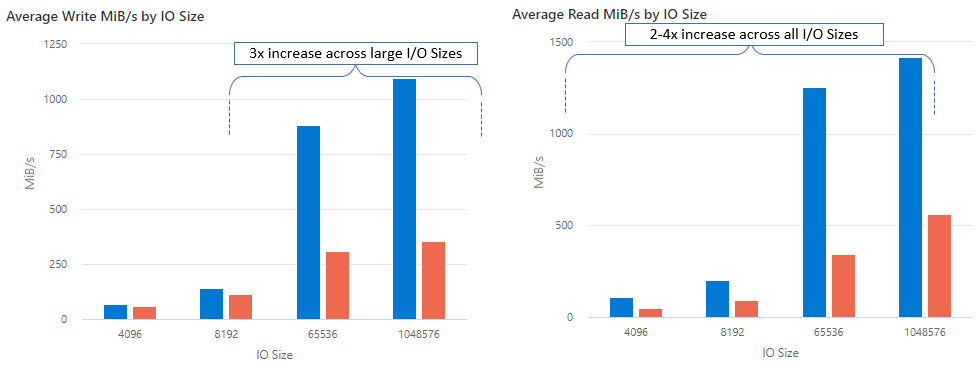
Con nconnect, puede aumentar el rendimiento a escala mediante menos máquinas cliente para reducir el costo total de propiedad (TCO). La característica nconnect aumenta el rendimiento mediante el uso de varios canales TCP en una o varias NIC, mediante uno o varios clientes. Sin nconnect, necesitaría aproximadamente 20 máquinas cliente para lograr los límites de escala de ancho de banda (10 GiB/s) ofrecidos por el mayor tamaño de aprovisionamiento del recurso compartido de archivos SSD. Con nconnect, puede lograr esos límites usando solo 6-7 clientes, lo que reduce los costos de proceso en casi 70% al tiempo que proporciona mejoras significativas en las operaciones de E/S por segundo (IOPS) y el rendimiento a escala. Vea la siguiente tabla.
| Métrica (operación) | Tamaño de E/S | Mejora del rendimiento |
|---|---|---|
| IOPS (escritura) | 64 KiB, 1024 KiB | 3x |
| IOPS (lectura) | Todos los tamaños de E/S | 2-4x |
| Rendimiento (escritura) | 64 KiB, 1024 KiB | 3x |
| Rendimiento (lectura) | Todos los tamaños de E/S | 2-4x |
Requisitos previos
- Las distribuciones más recientes de Linux son totalmente compatibles con nconnect. En el caso de las distribuciones anteriores de Linux, asegúrese de que la versión del kernel de Linux es 5.3 o posterior.
- La configuración por montaje solo se admite cuando se usa un único recurso compartido de archivos por cuenta de almacenamiento a través de un punto de conexión privado.
Impacto en el rendimiento
Hemos logrado los siguientes resultados de rendimiento al usar la opción de montaje nconnect con recursos compartidos de archivos de Azure NFS en clientes Linux a escala. Para obtener más información sobre cómo logramos estos resultados, consulte Configuración de pruebas de rendimiento.
Recomendaciones
Siga estas recomendaciones para obtener los mejores resultados de nconnect.
Establezcanconnect=4.
Aunque Azure Files admite la configuración de nconnect hasta el valor máximo de 16, se recomienda configurar las opciones de montaje con el valor óptimo de nconnect=4. Actualmente, no se obtienen beneficios que superen cuatro canales en la implementación de nconnect de Azure Files. De hecho, superar cuatro canales en un único recurso compartido de archivos de Azure de un solo cliente podría afectar negativamente al rendimiento debido a la saturación de la red TCP.
Ajustar el tamaño de las máquinas virtuales cuidadosamente
En función de los requisitos de carga de trabajo, es importante ajustar correctamente el tamaño de las máquinas virtuales cliente para evitar que su ancho de banda de red esperado restrinda. No necesita varios controladores de interfaz de red (NIC) para lograr el rendimiento de red esperado. Aunque es habitual usar máquinas virtuales de uso general con Azure Files, hay varios tipos de máquinas virtuales disponibles en función de las necesidades de la carga de trabajo y la disponibilidad de las regiones. Para más información, consulte Selector de máquinas virtuales de Azure.
Mantener la profundidad de la cola menor o igual que 64
La profundidad de la cola es el número de solicitudes de E/S pendientes que un recurso de almacenamiento puede atender. No recomendamos superar la profundidad de cola óptima de 64, ya que no se obtendrán más mejoras de rendimiento. Para obtener más información, vea Profundidad de la cola.
Configuración por montaje
Si una carga de trabajo requiere montar varios recursos compartidos con una o varias cuentas de almacenamiento con una configuración de nconnect diferente de un solo cliente, no podemos garantizar que esa configuración se conserve al montar en el punto de conexión público. La configuración por montaje solo se admite cuando se usa un único recurso compartido de archivos de Azure por cuenta de almacenamiento a través del punto de conexión privado, como se describe en escenario 1.
Escenario 1: por configuración de montaje a través del punto de conexión privado con varias cuentas de almacenamiento (compatibles)
- StorageAccount.file.core.windows.net = 10.10.10.10
- StorageAccount2.file.core.windows.net = 10.10.10.11
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount2.file.core.windows.net:/StorageAccount2/FileShare1
Escenario 2: por configuración de montaje a través del punto de conexión público (no compatible)
- StorageAccount.file.core.windows.net = 52.239.238.8
- StorageAccount2.file.core.windows.net = 52.239.238.7
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare2Mount StorageAccount2.file.core.windows.net:/StorageAccount2/FileShare1
Nota:
Incluso si la cuenta de almacenamiento se resuelve en una dirección IP diferente, no podemos garantizar que la dirección persista porque los puntos de conexión públicos no son direcciones estáticas.
Escenario 3: por configuración de montaje a través de un punto de conexión privado con varios recursos compartidos en una sola cuenta de almacenamiento (no compatible)
- StorageAccount.file.core.windows.net = 10.10.10.10
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare2Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare3
Configuración de prueba de rendimiento
Usamos los siguientes recursos y herramientas de pruebas comparativas para lograr y medir los resultados descritos en este artículo.
- Cliente único: máquina virtual de Azure (serie DSv4) con una sola NIC
- Sistema operativo: Linux (Ubuntu 20.40)
-
Almacenamiento NFS: Recurso compartido de archivos SSD (aprovisionado 30 TiB, set
nconnect=4)
| Tamaño | vCPU | Memoria | Almacenamiento temporal (SSD) | Discos de datos máx. | Nº máx. NIC | Ancho de banda de red esperado |
|---|---|---|---|---|---|---|
| Standard_D16_v4 | 16 | 64 GiB | Solo almacenamiento remoto | 32 | 8 | 12 500 Mbps |
Pruebas y herramientas de pruebas comparativas
Usamos Flexible I/O Tester (FIO), una herramienta de E/S de disco libre y de código abierto que se usa tanto para pruebas comparativas como para comprobación del esfuerzo y el hardware. Para instalar FIO, siga la sección Paquetes binarios que aparece en el archivo README de FIO para instalar la versión correspondiente a la plataforma que prefiera.
Aunque estas pruebas se centran en patrones de acceso de E/S aleatorios, obtendrá resultados similares al usar E/S secuencial.
IOPS elevadas: lecturas del 100 %
Tamaño de E/S de 4 k - lectura aleatoria - profundidad de 64 colas
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=4k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Tamaño de E/S de 8 k - lectura aleatoria - profundidad de 64 colas
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=8k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Alto rendimiento: 100 % de lecturas
Tamaño de E/S de 64 KiB: lectura aleatoria: profundidad de 64 colas
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=64k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Tamaño de E/S de 1024 KiB: 100% lectura aleatoria: profundidad de 64 colas
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=1024k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
IOPS elevadas: 100 % de escrituras
Tamaño de E/S de 4 KiB: 100% escritura aleatoria: profundidad de 64 colas
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=4k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Tamaño de E/S de 8 KiB: 100% escritura aleatoria: profundidad de 64 colas
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=8k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Alto rendimiento: 100 % de escrituras
Tamaño de E/S de 64 KiB: 100% escritura aleatoria: profundidad de 64 colas
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=64k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Tamaño de E/S de 1024 KiB: 100% escritura aleatoria: profundidad de 64 colas
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=1024k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Consideraciones de rendimiento para nconnect
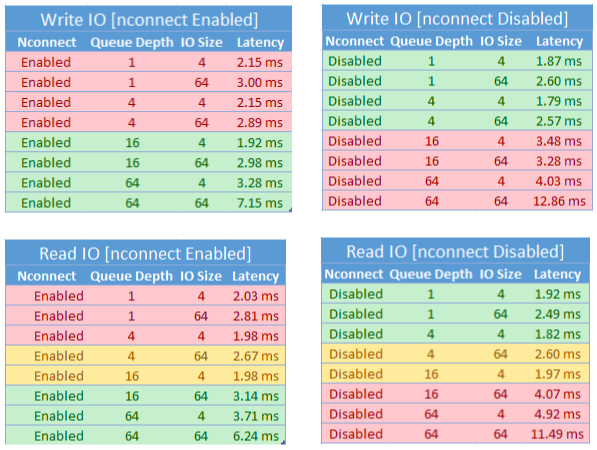
Al usar la opción de montaje de nconnect, debe evaluar detenidamente las cargas de trabajo que tienen las siguientes características:
- Cargas de trabajo de escritura sensibles a la latencia que son un único subproceso o usan una profundidad de cola baja (menos de 16)
- Cargas de trabajo de lectura confidenciales de latencia que son un único subproceso o usan una profundidad de cola baja en combinación con tamaños de E/S más pequeños
No todas las cargas de trabajo requieren rendimiento de alta escala en todo el sistema o de IOPS. En el caso de cargas de trabajo de escala más pequeñas, es posible que no tenga sentido usar nconnect. Use la tabla siguiente para decidir si nconnect es ventajoso para la carga de trabajo. Los escenarios resaltados en verde son recomendables, mientras que los resaltados en rojo no lo son. Los escenarios resaltados en amarillo son neutros.