Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se describen algunos patrones adecuados para su uso con soluciones de Table service. Además, verá cómo puede abordar de manera práctica algunos de los problemas, y las ventajas e inconvenientes descritos en otros artículos de diseño de Table Storage. En el diagrama siguiente se resumen las relaciones entre los distintos patrones:

La asignación de patrones anterior resalta algunas relaciones entre patrones (azules) y antipatrones (naranja) que se documentan en esta guía. Existen muchos otros patrones que merece la pena tener en cuenta. Por ejemplo, uno de los escenarios clave de Table Service es almacenar el patrón de vistas materializadas desde Segregación de responsabilidades de consultas de comandos (CQRS).
Patrón de índice secundario dentro de la partición
Almacene varias copias de cada entidad con diferentes valores RowKey (en la misma partición) para habilitar búsquedas rápidas y eficaces y ordenaciones alternativas mediante el uso de diferentes valores RowKey. Las actualizaciones entre copias se pueden mantener coherentes mediante transacciones de grupo de entidades (ETE).
Contexto y problema
Table service indexa automáticamente entidades mediante los valores PartitionKey y RowKey. Esto permite que una aplicación cliente recupere una entidad eficazmente con estos valores. Por ejemplo, si se usa la estructura de tabla que se muestra a continuación, una aplicación cliente puede usar una consulta puntual para recuperar una entidad de empleado individual mediante el nombre del departamento y el identificador del empleado (los valores PartitionKey y RowKey). Un cliente también puede recuperar las entidades ordenadas por identificador de empleado dentro de cada departamento.
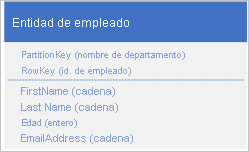
Si desea ser capaz de encontrar una entidad de empleado basada en el valor de otra propiedad, como la dirección de correo electrónico, debe usar un examen de la partición menos eficiente para encontrar a coincidencia. Esto se debe a que Table service no proporciona índices secundarios. Además, no hay ninguna opción para solicitar una lista de empleados ordenados en un orden diferente a RowKey .
Solución
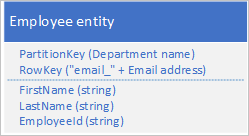
Para solucionar la falta de índices secundarios, puede almacenar varias copias de cada entidad con cada copia mediante un valor RowKey diferente. Si almacena una entidad con las estructuras que se muestran a continuación, puede recuperar eficazmente las entidades de empleado en función de un identificador de empleado o de dirección de correo electrónico. Los valores de prefijo de RowKey, "empid" y "email", permiten consultar un solo empleado o un intervalo de empleados mediante un intervalo de direcciones de correo electrónico o identificadores de empleado.

Los dos criterios de filtro siguientes (uno de búsqueda por identificador de empleado y uno de búsqueda por dirección de correo electrónico) especifican consultas de punto:
- $filter=(PartitionKey eq 'Sales') y (RowKey eq 'empid_000223')
- $filter=(PartitionKey eq 'Sales') y (RowKey eq 'email_jonesj@contoso.com')
Si consulta un intervalo de entidades de empleado, puede especificar un intervalo ordenado por identificador de empleado o un intervalo ordenado por dirección de correo electrónico mediante la consulta de entidades con el prefijo adecuado en RowKey.
Para buscar todos los empleados del departamento de ventas con un identificador de empleado en el intervalo de 000100 a 000199 use: $filter=(PartitionKey eq 'Sales') y (RowKey ge 'empid_000100') y (RowKey le 'empid_000199').
Para buscar todos los empleados del departamento de ventas con una dirección de correo electrónico que empiece por la letra 'a' use: $filter=(PartitionKey eq 'Sales') y (RowKey ge 'email_a') y (RowKey lt 'email_b')
La sintaxis de filtro usada en los ejemplos anteriores corresponde a la API de REST de Table service. Para más información, consulte Entidades de consulta.
Problemas y consideraciones
Tenga en cuenta los puntos siguientes al decidir cómo implementar este patrón:
El almacenamiento en tablas es relativamente barato, por lo que la sobrecarga de costos de almacenamiento de datos duplicados no debe ser una preocupación importante. Sin embargo, debe evaluar siempre el costo del diseño según los requisitos de almacenamiento previstos y solo agregar entidades duplicadas para admitir las consultas que ejecutará la aplicación cliente.
Dado que las entidades de índice secundario se almacenan en la misma partición que las entidades originales, debe asegurarse de que no superen los objetivos de escalabilidad para una partición individual.
Puede mantener la coherencia de las entidades duplicadas utilizando EGT para actualizar las dos copias de la entidad de forma atómica. Esto implica que debe almacenar todas las copias de una entidad en la misma partición. Para más información, consulte la sección Uso de transacciones de grupos de entidades.
El valor que se usa RowKey debe ser único para cada entidad. Considere la posibilidad de usar valores de clave compuestos.
Al rellenar los valores numéricos de RowKey (por ejemplo, el identificador de empleado 000223) es posible corregir los criterios de ordenación y filtrado en función de los límites inferior y superior.
No es necesario duplicar todas las propiedades de su entidad. Por ejemplo, si las consultas que realizan búsquedas en las entidades mediante la dirección de correo electrónico de RowKey nunca necesitan la edad del empleado, dichas entidades podrían tener la siguiente estructura:
Normalmente es mejor almacenar los datos duplicados y asegurarse de que puede recuperar todos los datos que necesita con una sola consulta que usar una consulta para buscar una entidad y otra para buscar los datos necesarios.
Cuándo usar este patrón
Utilice este patrón cuando la aplicación cliente necesite recuperar entidades mediante una serie de claves diferentes, cuando el cliente necesite recuperar entidades de diferentes criterios de ordenación y cuando pueda identificar cada entidad mediante una serie de valores únicos. Sin embargo, debe asegurarse de no superar los límites de escalabilidad de partición al realizar búsquedas de entidad utilizando los diferentes valores RowKey .
Orientación y patrones relacionados
Los patrones y las directrices siguientes también pueden ser importantes a la hora de implementar este patrón:
- Patrón de índice secundario entre particiones
- Patrón de clave compuesta
- Transacciones de grupo de entidad
- Trabajar con tipos de entidad heterogéneos
Patrón de índice secundario entre particiones
Almacene varias copias de cada entidad con distintos valores de RowKey diferentes en particiones independientes o en tablas independientes para habilitar la realización de búsquedas rápidas y eficaces y órdenes alternativos utilizando valores RowKey diferentes.
Contexto y problema
Table service indexa automáticamente entidades mediante los valores PartitionKey y RowKey. Esto permite que una aplicación cliente recupere una entidad eficazmente con estos valores. Por ejemplo, si se usa la estructura de tabla que se muestra a continuación, una aplicación cliente puede usar una consulta puntual para recuperar una entidad de empleado individual mediante el nombre del departamento y el identificador del empleado (los valores PartitionKey y RowKey). Un cliente también puede recuperar las entidades ordenadas por identificador de empleado dentro de cada departamento.
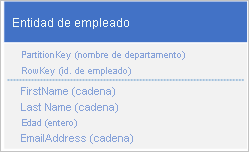
Si desea ser capaz de encontrar una entidad de empleado basada en el valor de otra propiedad, como la dirección de correo electrónico, debe usar un examen de la partición menos eficiente para encontrar a coincidencia. Esto se debe a que Table service no proporciona índices secundarios. Además, no hay ninguna opción para solicitar una lista de empleados ordenados en un orden diferente a RowKey .
Prevé un gran volumen de transacciones en estas entidades y quier minimizar el riesgo de que Table service limite a su cliente.
Solución
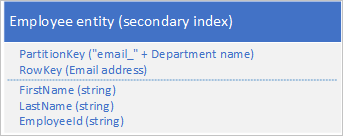
Para evitar la falta de índices secundarios, puede almacenar varias copias de cada entidad con cada copia con valores PartitionKey y RowKey diferentes. Si almacena una entidad con las estructuras que se muestran a continuación, puede recuperar eficazmente las entidades de empleado en función de un identificador de empleado o de dirección de correo electrónico. Los valores de prefijo de PartitionKey, "empid" y "email" le permiten identificar qué índice desea utilizar para una consulta.

Los dos criterios de filtro siguientes (uno de búsqueda por identificador de empleado y uno de búsqueda por dirección de correo electrónico) especifican consultas de punto:
- $filter=(PartitionKey eq 'empid_Sales') y (RowKey eq '000223')
- $filter=(PartitionKey eq 'email_Sales') y (RowKey eq 'jonesj@contoso.com')
Si consulta un intervalo de entidades de empleado, puede especificar un intervalo ordenado por identificador de empleado o un intervalo ordenado por dirección de correo electrónico mediante la consulta de entidades con el prefijo adecuado en RowKey.
- Para buscar todos los empleados del departamento de ventas con un identificador de empleado en el intervalo de 000100 a 000199 clasificados en orden de identificador de empleado, use: $filter=(PartitionKey eq 'empid_Sales') y (RowKey ge '000100') y (RowKey le '000199').
- Para buscar todos los empleados del departamento de ventas con una dirección de correo electrónico que empiece por 'a' ordenados en el orden de dirección de correo electrónico, use: $filter=(PartitionKey eq 'email_Sales') y (RowKey ge 'a') y (RowKey lt 'b')
La sintaxis de filtro usada en los ejemplos anteriores corresponde a la API de REST de Table service. Para más información, consulte Entidades de consulta.
Problemas y consideraciones
Tenga en cuenta los puntos siguientes al decidir cómo implementar este patrón:
Puede mantener las entidades duplicadas coherentes entre sí en última instancia con el patrón de transacciones coherentes en última instancia para conservar las entidades de índice principal y secundaria.
El almacenamiento en tablas es relativamente barato, por lo que la sobrecarga de costos de almacenamiento de datos duplicados no debe ser una preocupación importante. Sin embargo, debe evaluar siempre el costo del diseño según los requisitos de almacenamiento previstos y solo agregar entidades duplicadas para admitir las consultas que ejecutará la aplicación cliente.
El valor que se usa RowKey debe ser único para cada entidad. Considere la posibilidad de usar valores de clave compuestos.
Al rellenar los valores numéricos de RowKey (por ejemplo, el identificador de empleado 000223) es posible corregir los criterios de ordenación y filtrado en función de los límites inferior y superior.
No es necesario duplicar todas las propiedades de su entidad. Por ejemplo, si las consultas que realizan búsquedas en las entidades mediante la dirección de correo electrónico de RowKey nunca necesitan la edad del empleado, dichas entidades podrían tener la siguiente estructura:
Normalmente es mejor almacenar los datos duplicados y asegurarse de que puede recuperar todos los datos que necesita con una sola consulta que usar una consulta para buscar una entidad mediante el índice secundario y otra para buscar los datos necesarios en el índice principal.
Cuándo usar este patrón
Utilice este patrón cuando la aplicación cliente necesite recuperar entidades mediante una serie de claves diferentes, cuando el cliente necesite recuperar entidades de diferentes criterios de ordenación y cuando pueda identificar cada entidad mediante una serie de valores únicos. Utilice este patrón cuando desee no exceder los límites de escalabilidad de la partición al realizar búsquedas de entidades que usen los diferentes valores RowKey .
Orientación y patrones relacionados
Los patrones y las directrices siguientes también pueden ser importantes a la hora de implementar este patrón:
- Patrón final coherente de transacciones
- Patrón de índice secundario dentro de la partición
- Patrón de clave compuesta
- Transacciones de grupo de entidad
- Trabajar con tipos de entidad heterogéneos
Patrón final coherente de transacciones
Habilitar el comportamiento final coherente a través de límites de partición o los límites del sistema de almacenamiento mediante el uso de las colas de Azure.
Contexto y problema
Los EGT permiten transacciones atómicas a través de varias entidades que comparten la misma clave de partición. Por motivos de escalabilidad y rendimiento, puede decidir almacenar entidades con requisitos de coherencia en particiones independientes o en un sistema de almacenamiento independiente: en este escenario, no puede utilizar EGT para mantener la coherencia. Por ejemplo, podría tener un requisito de mantener la coherencia eventual entre:
- Entidades almacenadas en dos particiones diferentes de la misma tabla, en tablas diferentes y en diferentes cuentas de almacenamiento.
- Una entidad almacenada en Table service y un blob almacenado en Blob service.
- Una entidad almacenada en Table service y un archivo en un sistema de archivos.
- Una entidad almacenada en Table service, pero indexada con el servicio Azure Cognitive Search.
Solución
Mediante el uso de las colas de Azure, puede implementar una solución que ofrece coherencia final entre dos o más particiones o sistemas de almacenamiento. Para ilustrar este enfoque, suponga que tiene un requisito para poder almacenar entidades de empleado antiguas. Las entidades de empleado antiguas rara vez se consultan y deben excluirse de las actividades relacionadas con los empleados actuales. Para implementar este requisito, almacene los empleados activos en la tabla Current y los empleados antiguos en la tabla Archive. Para archivar un empleado, es preciso eliminar la entidad de la tabla Current y agregarla a la tabla Archive, pero no se puede usar una EGT para realizar estas dos operaciones. Para evitar el riesgo de que un error provoque la aparición de una entidad en las dos tablas o en ninguna, la operación de almacenamiento debe ser coherente con el tiempo. En el diagrama de secuencia siguiente se describen los pasos de esta operación. En el texto siguiente se proporcionan más detalles para las rutas de excepción.
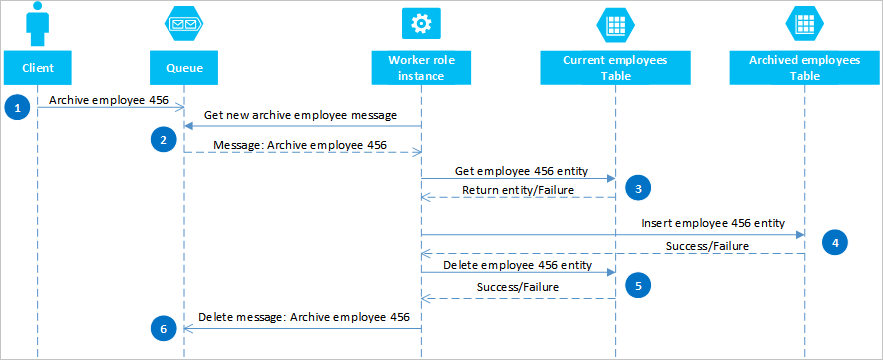
Un cliente inicia la operación de almacenamiento mediante la colocación de un mensaje en una cola de Azure, en este ejemplo para archivar el empleado #456. Un rol de trabajador sondea la cola de mensajes nuevos; si encuentra alguno, lee el mensaje y deja una copia oculta en la cola. A continuación, el rol de trabajo busca una copia de la entidad en la tabla Current, inserta una copia en la tabla Archive y, seguidamente, elimina la original de la tabla Current. Por último, si no ha habido errores en los pasos anteriores, el rol de trabajador elimina el mensaje oculto de la cola.
En este ejemplo, el paso 4 inserta el empleado en la tabla Archivo . Puede añadir al empleado a un blob en Blob service o un archivo en un sistema de archivos.
Recuperación de errores
Es importante que las operaciones de los pasos 4 y 5 sean idempotentes, por si el rol de trabajo necesita reiniciar la operación de archivo. Si va a utilizar Table service para el paso 4, debe utilizar una operación de "insertar o reemplazar"; en el paso 5 debe usar una operación de "eliminar si existe" en la biblioteca de cliente que vaya a usar. Si está utilizando otro sistema de almacenamiento, debe utilizar una operación idempotente adecuada.
Si el rol de trabajo no completa el paso 6, después de un tiempo de expiración el mensaje volverá a aparecer en la cola listo para que el rol de trabajo intente volver a procesarlo. El rol de trabajador puede comprobar cuántas veces se ha leído un mensaje de la cola y, si es necesario, marcarlo como mensaje "dudoso" para investigarlo mediante el envío a una cola independiente. Para obtener más información acerca de cómo leer mensajes de la cola y comprobar el número de eliminaciones de cola, consulte Obtener mensajes.
Algunos errores de Table service y Queue service son errores transitorios y la aplicación cliente debe incluir una lógica de reintento adecuada para controlarlos.
Problemas y consideraciones
Tenga en cuenta los puntos siguientes al decidir cómo implementar este patrón:
- Esta solución no permite el aislamiento de las transacciones. Por ejemplo, un cliente pudo leer las tablas Current y Archive cuando el rol de trabajo estaba entre los pasos 4 y 5, y tener una vista incoherente de los datos. Los datos serán coherentes con el tiempo.
- Debe asegurarse de que los pasos 4 y 5 sean idempotentes para garantizar la coherencia.
- Puede escalar la solución mediante el uso de varias colas e instancias de rol de trabajador.
Cuándo usar este patrón
Utilice este patrón cuando desee garantizar la coherencia eventual entre las entidades que existen en diferentes particiones o tablas. Puede extender este patrón para garantizar la coherencia eventual de las operaciones en Table service y Blob service, y otros orígenes de datos de almacenamiento que no sean de Azure, tales como bases de datos o el sistema de archivos.
Orientación y patrones relacionados
Los patrones y las directrices siguientes también pueden ser importantes a la hora de implementar este patrón:
- Transacciones de grupo de entidad
- Combinar o reemplazar
Nota:
Si el aislamiento de transacciones es importante para su solución, considere la posibilidad de volver a diseñar las tablas para poder utilizar EGT.
Patrón de entidades de índice
Mantenga entidades de índice para poder efectuar búsquedas eficaces que devuelvan listas de entidades.
Contexto y problema
Table service indexa automáticamente entidades mediante los valores PartitionKey y RowKey. Esto permite que una aplicación cliente recupere una entidad eficazmente mediante una consulta de punto. Por ejemplo, si se usa la estructura de tabla que se muestra a continuación, una aplicación cliente puede recuperar de manera eficiente una entidad de empleado individual mediante el nombre del departamento y el identificador de empleado (los valores PartitionKey y RowKey).

Si también desea poder recuperar una lista de las entidades employee en función del valor de otra propiedad no exclusiva, por ejemplo, su apellido, debe utilizar un examen de partición menos eficaz para buscar coincidencias en lugar de utilizar un índice para buscarlas directamente. Esto se debe a que Table service no proporciona índices secundarios.
Solución
Para habilitar la búsqueda por apellido con la estructura de entidad mostrada anteriormente, debe mantener listas de identificadores de empleado. Si quiere recuperar las entidades "employee" con un apellido determinado, como Jones, debe encontrar primero la lista de identificadores de empleado para los empleados con Jones como apellido y, después, recuperar las entidades "employee". Hay tres opciones principales para almacenar las listas de identificadores de empleado:
- Utilice Blob Storage.
- Cree entidades de índice en la misma partición que las entidades employee.
- Cree entidades de índice en una tabla o una partición independiente.
Opción n.º 1: Uso de Blob Storage
Para la primera opción, creará un blob para cada apellido único y, en cada almacén de blobs, una lista de valores PartitionKey (departamento) y RowKey (identificador de empleado) para los empleados que tienen ese apellido. Al agregar o eliminar a un empleado debe asegurarse de que el contenido del blob relevante es coherente con las entidades employee.
Opción n.º 2: Creación de entidades de índice en la misma partición
Para la segunda opción, utilice las entidades de índice que almacenan los datos siguientes:
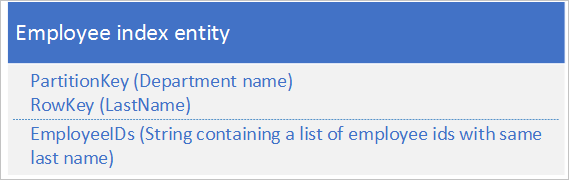
La propiedad EmployeeIDs contiene una lista de identificadores de empleado para los empleados cuyo apellido está almacenado en RowKey.
Los siguientes pasos describen el proceso que debe seguir al agregar un nuevo empleado si utiliza la segunda opción. En este ejemplo, agregamos un empleado con el identificador 000152 y el apellido Jones en el departamento de ventas:
- Recupere la entidad de índice con el valor PartitionKey "Sales" y el valor RowKey "Jones". Guarde el valor ETag de esta entidad para usar en el paso 2.
- Cree una transacción de grupo de entidad (es decir, una operación por lotes) que inserte la nueva entidad de empleado (valor PartitionKey "Sales" y valor RowKey "000152") y actualice la entidad de índice (valor PartitionKey "Sales" y valor RowKey "Jones") agregando el nuevo identificador de empleado a la lista del campo EmployeeIDs. Para obtener información sobre EGT, consulte la sección Transacciones de grupo de entidad (EGT).
- Si la transacción de grupo de entidad falla debido a un error de simultaneidad optimista (alguien ha modificado la entidad de índice), necesitará comenzar de nuevo en el paso 1.
Puede usar un enfoque similar a la eliminación de un empleado si utiliza la segunda opción. Cambiar el apellido de un empleado es ligeramente más complejo porque necesitará ejecutar una transacción de grupo de entidad que actualice tres entidades: la entidad employee, la entidad de índice para el apellido antiguo y la entidad de índice para el nombre nuevo. Debe recuperar cada entidad antes de realizar cambios para recuperar los valores de ETag que puede utilizar para realizar las actualizaciones mediante la simultaneidad optimista.
Los siguientes pasos describen el proceso que debe llevar a cabo cuando se necesita buscar todos los empleados con un apellido determinado en un departamento si utiliza la segunda opción. En este ejemplo se buscan todos los empleados con el apellido Jones en el departamento de ventas:
- Recupere la entidad de índice con el valor PartitionKey "Sales" y el valor RowKey "Jones".
- Analice la lista de identificadores de empleado en el campo EmployeeIDs.
- Si necesita información adicional sobre cada uno de los empleados (por ejemplo, sus direcciones de correo electrónico), recupere cada una de las entidades de empleado mediante los valores PartitionKey "Sales" y RowKey de la lista de empleados que obtuvo en el paso 2.
Opción n.º 3: Creación de entidades de índice en una tabla o partición independiente
Para la tercera opción, utilice las entidades de índice que almacenan los datos siguientes:

La propiedad EmployeeDetails contiene una lista de identificadores de empleados y pares de nombres de departamentos para los empleados cuyo apellido está almacenado en RowKey.
Con la tercera opción, no puede utilizar EGT para mantener la coherencia porque las entidades del índice están en una partición distinta que las entidades employee. Asegúrese de que las entidades de índice son coherentes finalmente con las entidades "employee".
Problemas y consideraciones
Tenga en cuenta los puntos siguientes al decidir cómo implementar este patrón:
- Esta solución requiere al menos dos consultas para recuperar las entidades coincidentes: una para consultar las entidades de índice con el fin de obtener la lista de valores RowKey y, luego, las consultas para recuperar cada entidad de la lista.
- Dado que una entidad individual tiene un tamaño máximo de 1 MB, la opción n.º 2 y la opción n.º 3 de la solución dan por hecho que la lista de identificadores de empleado de cualquier apellido determinado nunca es mayor que 1 MB. Si es probable que la lista de identificadores de empleado tenga un tamaño superior a 1 MB, use la opción n.º 1 y almacene los datos del índice en Blob Storage.
- Si utiliza la opción 2 (el uso de EGT para controlar la adición y eliminación de empleados, y el cambio de los apellidos de un empleado), debe evaluar si el volumen de transacciones se aproximará a los límites de escalabilidad de una partición determinada. Si este es el caso, debe considerar una solución coherente (opción nº1 o nº3) que utilice colas para controlar las solicitudes de actualización y le permita almacenar entidades de índice en una partición independiente de las entidades employee.
- La opción nº2 en esta solución da por hecho que desea buscar por apellido dentro de un departamento: por ejemplo, desea recuperar una lista de empleados que tienen un apellido Jones del departamento de ventas. Si desea buscar todos los empleados con apellido Jones en toda la organización, utilice opción nº1 o la opción nº3.
- Puede implementar una solución basada en cola que ofrezca coherencia eventual (consulte Patrón final coherente de transacciones para más información).
Cuándo usar este patrón
Use este patrón cuando quiera buscar un conjunto de entidades que compartan un valor de propiedad común, como todos los empleados con el apellido Jones.
Orientación y patrones relacionados
Los patrones y las directrices siguientes también pueden ser importantes a la hora de implementar este patrón:
- Patrón de clave compuesta
- Patrón final coherente de transacciones
- Transacciones de grupo de entidad
- Trabajar con tipos de entidad heterogéneos
Patrón de desnormalización
Combine datos relacionados entre sí en una sola entidad para recuperar todos los datos que necesita con una consulta de punto único.
Contexto y problema
En una base de datos relacional, normalmente normaliza datos para eliminar datos duplicados resultantes en las consultas que recuperan datos de varias tablas. Si normaliza los datos de tablas de Azure, debe realizar varias acciones de ida y vuelta desde el cliente al servidor para recuperar los datos relacionados. Por ejemplo, con la estructura de tabla que se muestra a continuación, se necesitan dos recorridos de ida y vuelta para recuperar los detalles de un departamento: uno para capturar la entidad de departamento que incluye el identificador del administrador y, después, otra solicitud para capturar los detalles del administrador de una entidad de empleado.

Solución
En lugar de almacenar los datos en dos entidades independientes, desnormalice los datos y conserve una copia de los detalles del administrador en la entidad department. Por ejemplo:
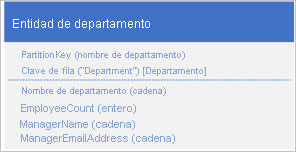
Ahora con las entidades de departamento almacenadas con estas propiedades, puede recuperar todos los detalles que necesita acerca de un departamento mediante una consulta de punto.
Problemas y consideraciones
Tenga en cuenta los puntos siguientes al decidir cómo implementar este patrón:
- Hay algunos costes de sobrecarga asociados al almacenamiento de datos dos veces. La ventaja de rendimiento (procedente de menos solicitudes al servicio de almacenamiento) normalmente es más importante que el aumento marginal en los costes de almacenamiento (y este coste se compensa parcialmente con una reducción en el número de transacciones que se requieren para capturar los detalles de un departamento).
- Debe mantener la coherencia de las dos entidades que almacenan información acerca de los administradores. Puede controlar el problema de coherencia utilizando EGT para actualizar varias entidades en una única transacción atómica: en este caso, la entidad department y la entidad employee del administrador de departamento se almacenan en la misma partición.
Cuándo usar este patrón
Utilice este patrón cuando necesite buscar información relacionada con frecuencia. Este patrón reduce el número de consultas que el cliente debe realizar para recuperar los datos que necesita.
Orientación y patrones relacionados
Los patrones y las directrices siguientes también pueden ser importantes a la hora de implementar este patrón:
- Patrón de clave compuesta
- Transacciones de grupo de entidad
- Trabajar con tipos de entidad heterogéneos
Patrón de clave compuesta
Use valores RowKey compuestos para permitir a los clientes buscar datos relacionados con una consulta de punto único.
Contexto y problema
En una base de datos relacional, resulta natural usar combinaciones en las consultas para devolver datos relacionados al cliente en una sola consulta. Por ejemplo, podría usar el identificador de empleado para buscar una lista de entidades relacionadas que contengan datos de rendimiento y revisión de ese empleado.
Supongamos que está almacenando entidades employee en Table service utilizando la siguiente estructura:
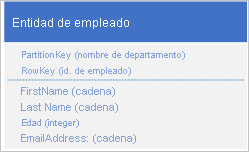
También necesita almacenar datos históricos relacionados con las revisiones y el rendimiento de cada año que el empleado ha trabajado para su organización y necesitará tener acceso a esta información por año. Una opción consiste en crear otra tabla que almacene las entidades con la estructura siguiente:
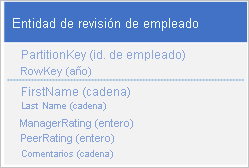
Observe que con este enfoque puede decidir duplicar parte de la información (por ejemplo, nombre y apellidos) en la nueva entidad, lo que le permite recuperar los datos con una única solicitud. Sin embargo, no puede mantener la homogeneidad porque no puede utilizar un EGT para actualizar las dos entidades de forma atómica.
Solución
Almacene un nuevo tipo de entidad en la tabla original mediante entidades con la estructura siguiente:

Observe que RowKey es ahora una clave compuesta formada por el identificador del empleado y el año de los datos de revisión, lo que le permite recuperar los datos de rendimiento y revisión del empleado con una única solicitud para una única entidad.
El ejemplo siguiente describe cómo se pueden recuperar todos los datos de revisión para un empleado concreto (como employee 000123 en el departamento de ventas):
$filter=(PartitionKey eq "Sales") y (RowKey ge "empid_000123") y (RowKey lt "000123_2012")&$select=RowKey,Manager Rating,Peer Rating,Comments
Problemas y consideraciones
Tenga en cuenta los puntos siguientes al decidir cómo implementar este patrón:
- Debe usar un carácter separador adecuado que facilite el análisis del valor RowKey: por ejemplo, 000123_2012.
- También almacena esta entidad en la misma partición que otras entidades que contienen datos relacionados correspondientes al mismo empleado, lo que significa que puede usar EGT para mantener una coherencia segura.
- Debe considerar la frecuencia con la que consultará los datos para determinar si este patrón es adecuado. Por ejemplo, si tendrá acceso a los datos de revisión con poca frecuencia y a menudo a los datos de empleados principales debe guardarlos como entidades independientes.
Cuándo usar este patrón
Utilice este patrón cuando necesite almacenar una o más entidades relacionadas que consulte con frecuencia.
Orientación y patrones relacionados
Los patrones y las directrices siguientes también pueden ser importantes a la hora de implementar este patrón:
- Transacciones de grupo de entidad
- Trabajar con tipos de entidad heterogéneos
- Patrón final coherente de transacciones
Patrón final del registro
Recupere las entidades n agregadas recientemente a una partición utilizando un valor RowKey que se ordene en orden de fecha y hora inverso.
Contexto y problema
Un requisito común es ser capaz de recuperar las entidades creadas más recientemente, por ejemplo, las diez reclamaciones de gastos más recientes enviadas por un empleado. Las consultas de tabla admiten una operación de consulta $top para devolver las primeras entidades n de un conjunto: no hay ninguna operación de consulta equivalente para devolver las últimas entidades n en un conjunto.
Solución
Almacene las entidades mediante un valor RowKey que ordene naturalmente en orden inverso de fecha y hora de modo que la entrada más reciente sea siempre la primera de la tabla.
Por ejemplo, para poder recuperar las diez reclamaciones de gastos más recientes enviadas por un empleado, puede usar un valor de marca inversa derivado de la fecha y hora actuales. El siguiente ejemplo de código de C# muestra una forma de crear un valor de "marcas invertidas" adecuado para un valor RowKey que ordene de más reciente a más antiguo:
string invertedTicks = string.Format("{0:D19}", DateTime.MaxValue.Ticks - DateTime.UtcNow.Ticks);
Puede volver al valor de fecha y hora utilizando el código siguiente:
DateTime dt = new DateTime(DateTime.MaxValue.Ticks - Int64.Parse(invertedTicks));
La consulta de la tabla tiene este aspecto:
https://myaccount.table.core.windows.net/EmployeeExpense(PartitionKey='empid')?$top=10
Problemas y consideraciones
Tenga en cuenta los puntos siguientes al decidir cómo implementar este patrón:
- Debe rellenar el valor de tic inverso con ceros a la izquierda para asegurarse de que el valor de cadena se ordene según lo esperado.
- Debe ser consciente de los objetivos de escalabilidad en el nivel de una partición. Tenga cuidado de no crear particiones en la zona activa.
Cuándo usar este patrón
Utilice este patrón cuando necesite tener acceso a entidades en orden inverso de fecha y hora o cuando se necesite tener acceso a las entidades que haya agregado más recientemente.
Orientación y patrones relacionados
Los patrones y las directrices siguientes también pueden ser importantes a la hora de implementar este patrón:
Patrón de eliminación de gran volumen
Habilite la eliminación de un gran volumen de entidades mediante el almacenamiento de todas las entidades para su eliminación simultánea en su propia tabla independiente; elimine las entidades mediante la eliminación de la tabla.
Contexto y problema
Muchas aplicaciones eliminarán datos antiguos que ya no necesita que estén disponibles para una aplicación cliente o que la aplicación haya archivado en otro medio de almacenamiento. Normalmente se identifican estos datos por una fecha: por ejemplo, tiene un requisito para eliminar registros de todas las solicitudes de inicio de sesión que tengan más de 60 días.
Un diseño posible es utilizar la fecha y hora de la solicitud de inicio de sesión en el valor RowKey:
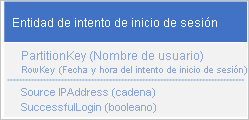
Este enfoque evita los problemas de las particiones porque la aplicación puede insertar y eliminar entidades de inicio de sesión para cada usuario en una partición independiente. Sin embargo, este enfoque puede ser costoso y lento si tiene un gran número de entidades porque primero debe realizar un recorrido de tabla para identificar todas las entidades que desea eliminar y, a continuación, debe eliminar cada entidad antigua. Puede reducir el número de viajes de ida y vuelta al servidor necesarios para eliminar las entidades antiguas almacenando por lotes varias solicitudes de eliminación en EGT.
Solución
Utilice una tabla independiente para cada día de intentos de inicio de sesión. Puede usar el diseño de la entidad anterior para evitar problemas cuando se insertan entidades y eliminar entidades anteriores ahora es simplemente una cuestión de eliminar una tabla todos los días (una operación de almacenamiento único) en lugar de buscar y eliminar cientos de miles de entidades de inicio de sesión individuales cada día.
Problemas y consideraciones
Tenga en cuenta los puntos siguientes al decidir cómo implementar este patrón:
- ¿Su diseño admite otras formas de uso por parte de su aplicación de los datos como la búsqueda de entidades específicas, vinculación con otros datos o generar información de agregado?
- ¿Evita el diseño problemas cuando se insertan nuevas entidades?
- Espere un retraso si desea reutilizar el mismo nombre de tabla después de eliminarlo. Es mejor utilizar siempre nombres de tabla únicos.
- Esperar ciertas limitaciones cuando utilice primero una tabla nueva mientras Table service aprende los patrones de acceso y distribuye las particiones entre los nodos. Debe considerar la frecuencia con la que necesita crear nuevas tablas.
Cuándo usar este patrón
Utilice este patrón cuando tenga un gran volumen de entidades que deba eliminar al mismo tiempo.
Orientación y patrones relacionados
Los patrones y las directrices siguientes también pueden ser importantes a la hora de implementar este patrón:
- Transacciones de grupo de entidad
- Modificación de entidades
Patrón de serie de datos
Almacene una serie de datos completa en una sola entidad para minimizar el número de solicitudes que realice.
Contexto y problema
Un escenario común para una aplicación es almacenar una serie de datos que normalmente necesite recuperar al mismo tiempo. Por ejemplo, la aplicación podría registrar el número de mensajes de MI que envía cada hora cada empleado y, a continuación, utilizar esta información para trazar cuántos mensajes envió cada usuario durante las 24 horas anteriores. Un diseño podría ser almacenar 24 entidades para cada empleado:
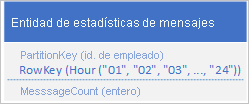
Con este diseño, puede localizar y actualizar fácilmente la entidad que se va a actualizar para cada empleado, siempre que la aplicación necesite actualizar el valor de recuento de mensajes. Sin embargo, para recuperar la información para trazar un gráfico de la actividad durante las 24 horas anteriores, debe recuperar 24 entidades.
Solución
Utilice el siguiente diseño con una propiedad independiente para almacenar el número de mensajes de cada hora:
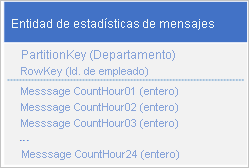
Con este diseño, puede utilizar una operación de combinación para actualizar el número de mensajes de un empleado para una hora concreta. Ahora puede recuperar toda la información que necesita para trazar el gráfico mediante una solicitud para una entidad única.
Problemas y consideraciones
Tenga en cuenta los puntos siguientes al decidir cómo implementar este patrón:
- Si la serie de datos completa no cabe en una única entidad (una entidad puede tener hasta 252 propiedades), utilice un almacén de datos alternativo, como un blob.
- Si tiene varios clientes actualizando una entidad simultáneamente, deberá utilizar el ETag para implementar la simultaneidad optimista. Si tiene muchos clientes, puede experimentar un alto nivel de contención.
Cuándo usar este patrón
Utilice este patrón cuando necesite actualizar y recuperar una serie de datos asociada con una entidad individual.
Orientación y patrones relacionados
Los patrones y las directrices siguientes también pueden ser importantes a la hora de implementar este patrón:
- Patrón de entidades de gran tamaño
- Combinar o reemplazar
- Patrón final coherente de transacciones (si va a almacenar la serie de datos en un blob)
Patrón de entidades amplio
Use varias entidades físicas para almacenar entidades lógicas con más de 252 propiedades.
Contexto y problema
Una entidad individual no puede tener más de 252 propiedades (excepto las propiedades del sistema obligatorias) y no puede almacenar más de 1 MB de datos en total. En una base de datos relacional, normalmente se encontrará con límites en el tamaño de una fila de ida y vuelta al agregar una nueva tabla e imponer una relación de 1 a 1 entre ellas.
Solución
Con Table service, puede almacenar varias entidades para representar un objeto único de gran empresa con más de 252 propiedades. Por ejemplo, si desea almacenar un recuento del número de mensajes de mensajería instantánea enviados por cada empleado durante los últimos 365 días, podría utilizar el siguiente diseño que usa dos entidades con distintos esquemas:

Si necesita realizar un cambio que requiere la actualización de ambas entidades para mantenerlas sincronizadas entre sí puede utilizar un EGT. De lo contrario, puede utilizar una única operación de combinación para actualizar el número de mensajes para un día concreto. Para recuperar todos los datos de un empleado individual debe recuperar ambas entidades, lo que puede hacer con dos solicitudes eficaces que se usan un valor PartitionKey y RowKey.
Problemas y consideraciones
Tenga en cuenta los puntos siguientes al decidir cómo implementar este patrón:
- Recuperar una entidad lógica completa implica al menos dos transacciones de almacenamiento: una para recuperar cada entidad física.
Cuándo usar este patrón
Utilice este patrón cuando necesite almacenar entidades cuyo tamaño o número de propiedades supere los límites de una entidad individual en Table service.
Orientación y patrones relacionados
Los patrones y las directrices siguientes también pueden ser importantes a la hora de implementar este patrón:
- Transacciones de grupo de entidad
- Combinar o reemplazar
Patrón de entidades de gran tamaño
Use Blob Storage para almacenar valores de propiedad de gran tamaño.
Contexto y problema
Una entidad individual no puede almacenar más de 1 MB de datos en total. Si una o varias de sus propiedades almacenan valores que provocan que el tamaño total de la entidad supere este valor, no puede almacenar toda la entidad en Table service.
Solución
Si la entidad supera 1 MB de tamaño porque una o más propiedades contienen una gran cantidad de datos, puede almacenar datos en Blob service y, a continuación, almacenar la dirección del blob en una propiedad de la entidad. Por ejemplo, puede almacenar la foto de un empleado en Blob Storage y almacenar un vínculo a la foto en la propiedad Photo de la entidad employee:

Problemas y consideraciones
Tenga en cuenta los puntos siguientes al decidir cómo implementar este patrón:
- Para mantener la coherencia eventual entre la entidad de Table service y los datos de Blob service, utilice el patrón final coherente de transacciones para mantener las entidades.
- Recuperar una entidad completa implica al menos dos transacciones de almacenamiento: una para recuperar la entidad y otra para recuperar los datos del blob.
Cuándo usar este patrón
Utilice este patrón cuando necesite almacenar entidades cuyo tamaño supere los límites para una entidad individual en Table service.
Orientación y patrones relacionados
Los patrones y las directrices siguientes también pueden ser importantes a la hora de implementar este patrón:
Antipatrón de anteponer/anexar
Aumente la escalabilidad cuando tenga un alto volumen de inserciones al repartir estas en varias particiones.
Contexto y problema
Anteponer o anexar las entidades a las entidades almacenadas normalmente provoca en la aplicación la adición de nuevas entidades a la primera o última partición de una secuencia de particiones. En este caso, todas las inserciones en un momento determinado están teniendo lugar en la misma partición, creando un punto de conflicto que impide que Table service efectúe el equilibrio de cargas en varios nodos, provocando posiblemente que la aplicación alcance los objetivos de escalabilidad de la partición. Por ejemplo, si tiene una aplicación que registra el acceso a la red y a recursos por parte de los empleados, una estructura de entidad como la mostrada a continuación podría provocar que la partición de la hora actual se convierta en un punto de conflicto si el volumen de transacciones alcanza el objetivo de escalabilidad de una partición individual:

Solución
La siguiente estructura de una entidad alternativa evita puntos de conflicto en una partición determinada a medida que la aplicación registra eventos:

Observe en este ejemplo que tanto PartitionKey como RowKey son claves compuestas. PartitionKey usa tanto el departamento como el identificador de empleado para distribuir el registro entre varias particiones.
Problemas y consideraciones
Tenga en cuenta los puntos siguientes al decidir cómo implementar este patrón:
- ¿Admite la estructura de clave alternativa que evita la creación de particiones activas en inserciones eficazmente las consultas que realiza la aplicación cliente?
- ¿El volumen de transacciones previstas significa que es probable alcanzar los objetivos de escalabilidad para una partición individual y estar limitada por el servicio de almacenamiento?
Cuándo usar este patrón
Evite el antipatrón anteponer/anexar cuando es posible que el volumen de transacciones provoque una limitación por parte del servicio de almacenamiento cuando acceda a una partición activa.
Orientación y patrones relacionados
Los patrones y las directrices siguientes también pueden ser importantes a la hora de implementar este patrón:
Antipatrón de datos de registro
Normalmente, debe utilizar Blob service en lugar de Table service para almacenar los datos de registro.
Contexto y problema
Un caso de uso común para los datos del registro es recuperar una selección de entradas de registro para un intervalo de fecha y hora específico: por ejemplo, desea buscar todos los mensajes de error y críticos que ha registrado la aplicación entre las 15:04 y las 15:06 en una fecha concreta. No desea utilizar la fecha y hora del mensaje del registro para determinar la partición en la que se guardan las entidades del registro: esto da como resultado una partición activa porque en un momento dado, todas las entidades de registro compartirán el mismo valor PartitionKey (consulte la sección Anteponer o anexar antipatrón). Por ejemplo, el siguiente esquema de entidad para un mensaje de registro produce una partición activa debido a que la aplicación escribe todos los mensajes de registro en la partición en la fecha y la hora actuales:
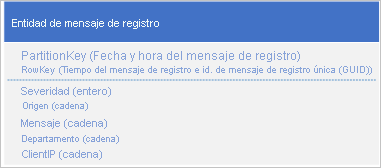
En este ejemplo, RowKey incluye la fecha y hora del mensaje del registro para garantizar que los mensajes de registro se almacenan ordenados por fecha y hora, e incluye un identificador de mensaje en caso de que varios mensajes de registro compartan la misma fecha y hora.
Otro enfoque consiste en utilizar un valor PartitionKey que garantice que la aplicación escriba los mensajes en un intervalo de particiones. Por ejemplo, si el origen del mensaje de registro proporciona una manera de distribuir los mensajes entre muchas particiones, podría utilizar el siguiente esquema de entidad:
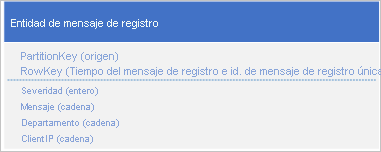
Sin embargo, el problema con este esquema es que para recuperar todos los mensajes de registro de un intervalo de tiempo específico debe buscar todas las particiones de la tabla.
Solución
En la sección anterior se resaltó el problema de intentar utilizar Table service para almacenar las entradas del registro y se sugirieron dos diseños no satisfactorios. Una solución provocó una partición activa con el riesgo de obtener un bajo rendimiento de escritura de mensajes de registro; la otra solución ocasionó un bajo rendimiento de consultas debido a la necesidad de examinar cada partición de la tabla para recuperar los mensajes de registro de un intervalo de tiempo específico. Blob Storage ofrece una mejor solución para este tipo de escenario y así es como almacena Azure Storage Analytics los datos de registro que recopila.
En esta sección se describe cómo almacena Storage Analytics los datos de registro en Blob Storage para ilustrar este método de almacenamiento de datos que se suele consultar por intervalo.
Storage Analytics almacena los mensajes de registro en un formato delimitado en varios blobs. El formato delimitado facilita a una aplicación cliente analizar los datos del mensaje de registro.
Storage Analytics utiliza una convención de nomenclatura para los blobs que le permite localizar el blob (o blobs) que contienen los mensajes de registro que está buscando. Por ejemplo, un blob denominado "queue/2014/07/31/1800/000001.log" contiene los mensajes de registro relacionados con el servicio de cola con hora de inicio a las 18:00 del 31 de julio de 2014. El "000001" indica que se trata del primer archivo de registro de este período. Storage Analytics también registra las marcas de tiempo del primer y último mensaje de registro almacenados en el archivo como parte de los metadatos del blob. La API de Blob Storage le permite buscar blobs en un contenedor basándose en un prefijo de nombre: para encontrar todos los blobs que contienen datos de registro de cola con hora de inicio a las 18:00, puede usar el prefijo "cola/2014/07/31/1800".
Storage Analytics almacena en búfer los mensajes de registro internamente y, a continuación, periódicamente actualiza el blob adecuado o crea uno nuevo con el último lote de entradas de registro. Esto reduce el número de escrituras que se debe realizar en Blob service.
Si está implementando una solución similar en su propia aplicación, debe considerar cómo administrar el equilibrio entre la fiabilidad (escribir cada entrada de registro en Blob Storage según se van produciendo) y el coste y la escalabilidad (almacenamiento en búfer de las actualizaciones en su aplicación y escribirlos en Blob Storage por lotes).
Problemas y consideraciones
Tenga en cuenta los siguientes puntos cuando decida cómo almacenar los datos del registro:
- Si crea un diseño de tabla que evite posibles particiones activas, observará que no tiene acceso a los datos del registro de forma eficaz.
- Para procesar los datos de registro, un cliente a menudo necesita cargar muchos registros.
- Aunque a menudo se estructuran de datos del registro, Blob Storage puede ser una solución mejor.
Consideraciones de implementación
En esta sección se describen algunas de las consideraciones a tener en cuenta al implementar los modelos descritos en las secciones anteriores. En la mayor parte de esta sección se utilizan ejemplos escritos en C# que utilizan la biblioteca de clientes de Storage (versión 4.3.0 en el momento de escribir).
Recuperación de entidades
Como se describe en la sección Diseño para consultas, la consulta más eficaz es una puntual. Sin embargo, en algunos casos puede que necesite recuperar varias entidades. En esta sección se describen algunos enfoques comunes para recuperar entidades mediante la biblioteca de clientes de Storage.
Ejecutar una consulta de punto mediante la biblioteca de clientes de Storage
La manera más sencilla de ejecutar una consulta puntual es usar el método GetEntityAsync, como se muestra en el siguiente fragmento de código de C# que recupera una entidad con el valor PartitionKey "Sales" y el valor RowKey "212":
EmployeeEntity employee = await employeeTable.GetEntityAsync<EmployeeEntity>("Sales", "212");
Observe cómo este ejemplo espera que la entidad que recupera sea del tipo EmployeeEntity.
Recuperar varias entidades con LINQ
Puede usar LINQ para recuperar varias entidades del servicio Table cuando se trabaja con la biblioteca estándar de Table de Microsoft Azure Cosmos DB.
dotnet add package Azure.Data.Tables
Para hacer que los siguientes ejemplos funcionen, deberá incluir espacios de nombres:
using System.Linq;
using Azure.Data.Tables
La recuperación de varias entidades se puede conseguir al especificar una consulta con una cláusula filter. Para evitar un examen de tabla, debe incluir siempre el valor PartitionKey en la cláusula filter y, si es posible, el valor RowKey para evitar exámenes de tablas y de particiones. Table service admite un conjunto limitado de operadores de comparación (mayor que, mayor o igual que, menor que, menor o igual que, igual y no igual a) para utilizar en la cláusula filter.
En el ejemplo siguiente, employeeTable es un objeto TableClient. Este ejemplo busca todos los empleados cuyo apellido empieza por "B" (suponiendo que RowKey almacene el apellido) del departamento de ventas (suponiendo que PartitionKey almacene el nombre del departamento):
var employees = employeeTable.Query<EmployeeEntity>(e => (e.PartitionKey == "Sales" && e.RowKey.CompareTo("B") >= 0 && e.RowKey.CompareTo("C") < 0));
Observe que la consulta especifica un valor RowKey y un valor PartitionKey para asegurar un mejor rendimiento.
El ejemplo código siguiente muestra una función equivalente sin usar la sintaxis de LINQ:
var employees = employeeTable.Query<EmployeeEntity>(filter: $"PartitionKey eq 'Sales' and RowKey ge 'B' and RowKey lt 'C'");
Nota:
Los métodos Query de ejemplo incluyen las tres condiciones de filtro.
Recuperar una gran cantidad de entidades de una consulta
Una consulta óptima devuelve una entidad individual basada en un valor PartitionKey y un valor RowKey. Sin embargo, en algunos escenarios puede tener el requisito de devolver varias entidades de la misma partición o incluso de varias particiones.
Siempre se debe probar a fondo el rendimiento de la aplicación en estas situaciones.
Una consulta en Table service puede devolver un máximo de 1.000 entidades al mismo tiempo y se puede ejecutar durante un máximo de cinco segundos. Si el conjunto de resultados contiene más de 1.000 entidades, si la consulta no se completa antes de cinco segundos, o si la consulta cruza el límite de partición, Table service devuelve un token de continuación para habilitar la aplicación cliente para solicitar el siguiente conjunto de entidades. Para más información sobre el funcionamiento de los tokens de continuación, consulte Tiempo de espera de consulta y paginación.
Si utiliza la biblioteca cliente de Azure Tables, puede controlar automáticamente los tokens de continuación cuando devuelve entidades del servicio de Tabla. El siguiente ejemplo de código de C# que utiliza la biblioteca cliente maneja automáticamente tokens de continuación si el servicio de Tabla los devuelve en una respuesta:
var employees = employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'")
foreach (var emp in employees)
{
// ...
}
También puede especificar el número máximo de entidades que se devuelven por página. El siguiente ejemplo muestra cómo consultar entidades con maxPerPage:
var employees = employeeTable.Query<EmployeeEntity>(maxPerPage: 10);
// Iterate the Pageable object by page
foreach (var page in employees.AsPages())
{
// Iterate the entities returned for this page
foreach (var emp in page.Values)
{
// ...
}
}
En escenarios más avanzados, es posible que desee almacenar el token de continuación devuelto desde el servicio para que el código controle exactamente cuándo se capturan las páginas siguientes. En el ejemplo siguiente se muestra un escenario básico de cómo se puede capturar y aplicar el token a los resultados paginados:
string continuationToken = null;
bool moreResultsAvailable = true;
while (moreResultsAvailable)
{
var page = employeeTable
.Query<EmployeeEntity>()
.AsPages(continuationToken, pageSizeHint: 10)
.FirstOrDefault(); // pageSizeHint limits the number of results in a single page, so we only enumerate the first page
if (page == null)
break;
// Get the continuation token from the page
// Note: This value can be stored so that the next page query can be executed later
continuationToken = page.ContinuationToken;
var pageResults = page.Values;
moreResultsAvailable = pageResults.Any() && continuationToken != null;
// Iterate the results for this page
foreach (var result in pageResults)
{
// ...
}
}
Mediante el uso de tokens de continuación explícitamente, puede controlar cuando recupera la aplicación el siguiente segmento de datos. Por ejemplo, si la aplicación cliente permite a los usuarios desplazarse por las entidades que se almacenan en una tabla, un usuario puede decidir no desplazarse a través de todas las entidades recuperadas por la consulta, por lo que la aplicación solo usaría un token de continuación para recuperar el siguiente segmento cuando el usuario hubiese terminado la paginación a través de todas las entidades en el segmento actual. Este enfoque tiene varias ventajas:
- Le permite limitar la cantidad de datos que desea recuperar Table service y desplazarse a través de la red.
- Le permite realizar E/S asincrónicas en. NET.
- Le permite serializar el token de continuación en un almacenamiento persistente para que pueda continuar en caso de un bloqueo de la aplicación.
Nota:
Normalmente, un token de continuación devuelve un segmento que contiene 1.000 entidades, aunque pueden ser menos. Esto también sucede si se limita el número de entradas que devuelve una consulta mediante el uso de Take para devolver las n primeras entidades que cumplen los criterios de búsqueda: Table service puede devolver un segmento que contenga menos de n entidades, junto con un token de continuación que permita recuperar las entidades restantes.
Proyección de servidor
Una sola entidad puede tener hasta 255 propiedades y ocupar hasta 1 MB. Al consultar la tabla y recuperar las entidades, puede que no necesite todas las propiedades y puede evitar la transferencia de datos innecesariamente (para ayudar a reducir la latencia y el coste). Puede usar proyección de servidor para transferir solo las propiedades que necesita. En el ejemplo siguiente se recupera solo la propiedad Email (junto con PartitionKey, RowKey, Timestamp y ETag) de las entidades seleccionadas por la consulta.
var subsetResults = query{
for employee in employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'") do
select employee.Email
}
foreach (var e in subsetResults)
{
Console.WriteLine("RowKey: {0}, EmployeeEmail: {1}", e.RowKey, e.Email);
}
Observe que el valor RowKey está disponible incluso no se incluyó en la lista de propiedades a recuperar.
Modificación de entidades
La biblioteca de clientes de Storage le permite modificar las entidades almacenadas en el servicio de tabla, insertando, eliminando y actualizando entidades. Puede usar EGT para procesar por lotes varias operaciones de inserción, actualización y eliminación conjuntamente para reducir el número de viajes de ida y vuelta requeridos y mejorar el rendimiento de la solución.
Entre las excepciones que se producen cuando la biblioteca de clientes de Storage ejecuta un EGT normalmente se incluyen el índice de la entidad que ha provocado el error del lote. Esto resulta útil cuando se depura código que usa EGT.
También debe considerar cómo afecta su diseño a la forma en que la aplicación cliente trata las operaciones de simultaneidad y actualización.
Administrar la simultaneidad
De forma predeterminada, Table service implementa comprobaciones de simultaneidad optimista en el nivel de entidades individuales para las operaciones Insertar, Combinar y Eliminar, aunque es posible que un cliente fuerce a Table service a omitir estas comprobaciones. Para más información sobre cómo Table service administra la simultaneidad, consulte Administración de la simultaneidad en Microsoft Azure Storage.
Combinar o reemplazar
El método Replace de la clase TableOperation siempre reemplaza toda la entidad en Table service. Si no incluye una propiedad en la solicitud cuando esa propiedad existe en la entidad almacenada, la solicitud quita esa propiedad de la entidad almacenada. A menos que desee quitar una propiedad de forma explícita de entidad almacenada, debe incluir todas las propiedades en la solicitud.
Puede utilizar el método Merge de la clase TableOperation para reducir la cantidad de datos que envía a Table service si desea actualizar una entidad. El método Merge reemplaza cualquier propiedad de la entidad almacenada por valores de propiedad de la entidad que se incluyen en la solicitud, pero deja intactas las propiedades de la entidad almacenada no incluidas en la solicitud. Esto es útil si tiene entidades de gran tamaño y solo tiene que actualizar un pequeño número de propiedades en una solicitud.
Nota:
Los métodos Replace y Merge generarán un error si la entidad no existe. Como alternativa, puede usar los métodos InsertOrReplace e InsertOrMerge, que crean una nueva entidad si todavía no existe.
Trabajar con tipos de entidad heterogéneos
Table service es un almacenamiento de tablas sin esquema, lo que significa que una sola tabla puede almacenar entidades de varios tipos, lo que proporciona gran flexibilidad en el diseño. En el ejemplo siguiente se muestra una tabla que almacena entidades de empleado y de departamento:
| PartitionKey | RowKey | Timestamp | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||
| |||||||||||
|
|||||||||||
|
Cada entidad aún debe tener valores PartitionKey, RowKey y Timestamp, pero puede tener cualquier conjunto de propiedades. Además, no hay nada que indique el tipo de una entidad a menos que elija almacenar esa información en algún lugar. Hay dos opciones para identificar el tipo de entidad:
- Anteponer el tipo de entidad al valor RowKey (o posiblemente a PartitionKey). Por ejemplo, EMPLOYEE_000123 o DEPARTMENT_SALES como valores RowKey.
- Utilice una propiedad independiente para registrar el tipo de entidad como se muestra en la tabla siguiente.
| PartitionKey | RowKey | Timestamp | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||
| |||||||||||||
|
|||||||||||||
|
La primera opción, anteponer el tipo de entidad a RowKey, resulta útil si existe la posibilidad de que dos entidades de tipos diferentes tengan el mismo valor de clave. También agrupa las entidades del mismo tipo juntas en la partición.
Las técnicas que se describen en esta sección están especialmente relacionadas con el tema Relaciones de herencia, que ya ha aparecido en esta guía, en la sección Modelado de relaciones.
Nota:
Considere la posibilidad de incluir un número de versión en el valor de tipo de entidad para permitir a las aplicaciones de cliente evolucionar objetos POCO y trabajar con distintas versiones.
En el resto de esta sección se describen algunas de las características de la biblioteca de clientes de Storage que facilitan el trabajo con varios tipos de entidad en la misma tabla.
Recuperar tipos de entidad heterogéneos
Si utiliza la biblioteca cliente de Tabla, tiene tres opciones para trabajar con varios tipos de entidad.
Si conoce el tipo de la entidad que se almacena con un valor concreto RowKey y PartitionKey, podrá especificar el tipo de entidad al recuperar la entidad, como se muestra en los dos ejemplos anteriores que recuperan entidades de tipo EmployeeEntity: Ejecutar una consulta de punto mediante la biblioteca de clientes de Storage y Recuperar varias entidades con LINQ.
La segunda opción es usar el tipo TableEntity (un contenedor de propiedades), en lugar de un tipo concreto de entidad POCO (esta opción también puede mejorar el rendimiento, ya que no es preciso serializar y deserializar la entidad de los tipos .NET). Potencialmente, el siguiente código de C# recupera varias entidades de distintos tipos de la tabla, pero devuelve todas las entidades como instancias de TableEntity. A continuación, usa la propiedad EntityType para determinar el tipo de cada entidad:
Pageable<TableEntity> entities = employeeTable.Query<TableEntity>(x =>
x.PartitionKey == "Sales" && x.RowKey.CompareTo("B") >= 0 && x.RowKey.CompareTo("F") <= 0)
foreach (var entity in entities)
{
if (entity.GetString("EntityType") == "Employee")
{
// use entityTypeProperty, RowKey, PartitionKey, Etag, and Timestamp
}
}
Para recuperar otras propiedades, debe utilizar el método GetString en la entidad de la clase TableEntity.
Modificar tipos de entidad heterogéneos
No es necesario conocer el tipo de una entidad para eliminarla, y siempre sabe el tipo de una entidad al insertarla. Sin embargo, puede usar el tipo TableEntity para actualizar una entidad sin conocer su tipo y sin utilizar una clase de entidad POCO. En el código de ejemplo siguiente se recupera una entidad individual y comprueba que la propiedad EmployeeCount existe antes de actualizarla.
var result = employeeTable.GetEntity<TableEntity>(partitionKey, rowKey);
TableEntity department = result.Value;
if (department.GetInt32("EmployeeCount") == null)
{
throw new InvalidOperationException("Invalid entity, EmployeeCount property not found.");
}
employeeTable.UpdateEntity(department, ETag.All, TableUpdateMode.Merge);
Control de acceso con firmas de acceso compartido
Puede utilizar tokens de firma de acceso compartido (SAS) para permitir a las aplicaciones cliente modificar y consultar entidades de tabla sin necesidad de incluir la clave de la cuenta de almacenamiento en el código. Normalmente, hay tres ventajas principales de utilizar SAS en su aplicación:
- No es necesario distribuir la clave de la cuenta de almacenamiento a una plataforma no segura (por ejemplo, un dispositivo móvil) para permitir que ese dispositivo acceda y modifique entidades en Table service.
- Puede descargar parte del trabajo que realizan los roles de web y trabajador en la administración de las entidades en dispositivos cliente como los equipos de usuario final y los dispositivos móviles.
- Puede asignar un conjunto de permisos restringido y con limitación de tiempo a un cliente (por ejemplo, para permitir el acceso de solo lectura a recursos específicos).
Para más información sobre el uso de tokens de SAS con Table service, consulte Uso de Firmas de acceso compartido (SAS).
Sin embargo, todavía debe generar los tokens SAS que concedan una aplicación cliente a las entidades en Table service: debe hacerlo en un entorno que tenga acceso seguro a las claves de cuenta de almacenamiento. Normalmente, se utiliza un rol web o de trabajador para generar los tokens SAS y entregarlos a las aplicaciones cliente que necesitan tener acceso a las entidades. Dado que todavía hay una sobrecarga implicada en la generación y entrega tokens SAS a los clientes, debería considerar cómo reducir mejor esta sobrecarga, especialmente en escenarios de gran volumen.
Es posible generar un token SAS que conceda acceso a un subconjunto de las entidades de una tabla. De forma predeterminada, se crea un token SAS para toda la tabla, pero también es posible especificar que el token SAS conceda acceso a un intervalo de valores PartitionKey o a un intervalo de valores PartitionKey y RowKey. Puede elegir generar tokens de SAS para usuarios individuales del sistema, de forma que el token de SAS de cada usuario solo les permita acceder a sus propias entidades en Table service.
Operaciones asincrónicas y paralelas
En caso de que reparta las solicitudes entre varias particiones, puede mejorar el rendimiento y la capacidad de respuesta del cliente mediante consultas asincrónicas o paralelas. Por ejemplo, podría tener dos o más instancias de rol de trabajo con acceso a las tablas en paralelo. Podría tiene roles de trabajador individual responsables de determinados conjuntos de particiones, o simplemente tener varias instancias de rol de trabajo, cada una de ellas con acceso a todas las particiones de una tabla.
Dentro de una instancia de cliente, puede mejorar el rendimiento mediante la ejecución de operaciones de almacenamiento de forma asincrónica. La biblioteca de clientes de Storage facilita la escritura de modificaciones y consultas asíncronas. Por ejemplo, puede comenzar con el método sincrónico que recupera todas las entidades de una partición como se muestra en el siguiente código de C#:
private static void ManyEntitiesQuery(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = employeeTable.Query<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
Este código puede se modificar fácilmente para que la consulta se ejecute de forma asincrónica del modo siguiente:
private static async Task ManyEntitiesQueryAsync(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = await employeeTable.QueryAsync<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
En este ejemplo asincrónico, puede ver los cambios siguientes desde la versión sincrónica:
- La firma del método incluye ahora el modificador async y devuelve una instancia de Tarea.
- En lugar de llamar al método Query para recuperar los resultados, ahora el método llama al método QueryAsync y usa el modificador await para recuperar resultados de forma asincrónica.
La aplicación cliente puede llamar a este método varias veces (con valores diferentes en el parámetro department ) y cada consulta se ejecutará en un subproceso independiente.
También puede insertar, actualizar y eliminar entidades de forma asincrónica. En el ejemplo de C# siguiente se muestra un método sencillo y sincrónico para insertar o reemplazar una entidad de empleado:
private static void SimpleEmployeeUpsert(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = employeeTable.UpdateEntity(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Status);
}
Este código se puede modificar fácilmente para que la actualización se ejecute de forma asincrónica del modo siguiente:
private static async Task SimpleEmployeeUpsertAsync(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = await employeeTable.UpdateEntityAsync(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Result.Status);
}
En este ejemplo asincrónico, puede ver los cambios siguientes desde la versión sincrónica:
- La firma del método incluye ahora el modificador async y devuelve una instancia de Tarea.
- En lugar de llamar al método Execute para actualizar la entidad, el método llama al método ExecuteAsync y usa el modificador await para recuperar resultados de forma asincrónica.
La aplicación cliente puede llamar a varios métodos asincrónicos como este, y cada invocación de método se ejecutará en un subproceso independiente.