Tutorial: Document Intelligence con servicios de Azure AI
Documento de inteligencia de Azure AI es uno de los servicios de Azure AI y permite crear una aplicación de procesamiento de datos automatizado mediante la tecnología de aprendizaje automático. En este tutorial, aprenderá a enriquecer fácilmente los datos en Azure Synapse Analytics. Utilizará Document Intelligence para analizar los formularios y documentos, extraer texto y datos, y devolver una salida JSON estructurada. Obtendrá rápidamente resultados precisos a la medida de su contenido específico sin necesidad de una intervención manual excesiva o una amplia experiencia en ciencia de datos.
En este tutorial se muestra cómo usar Document Intelligence con SynapseML para:
- Extraer texto y diseño de un documento determinado
- Detectar y extraer datos de recibos
- Detectar y extraer datos de tarjetas de presentación
- Detectar y extraer datos de facturas
- Detectar y extraer datos de documentos de identificación
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Requisitos previos
- Necesitará un área de trabajo de Azure Synapse Analytics con una cuenta de almacenamiento de Azure Data Lake Storage Gen2 que esté configurada como almacenamiento predeterminado. Asegúrese de que es el colaborador de datos de Storage Blob en el sistema de archivos de Data Lake Storage Gen2 con el que trabaja.
- Grupo de Spark en el área de trabajo de Azure Synapse Analytics. Para más información, consulte el artículo sobre creación de un grupo de Spark en Azure Synapse.
- Haber completado los pasos de configuración previos que se detallan en el tutorial Configuración de servicios de Azure AI en Azure Synapse.
Introducción
Abra Synapse Studio y cree un nuevo cuaderno. Para empezar, importe SynapseML.
import synapse.ml
from synapse.ml.cognitive import *
Configuración de Document Intelligence
Use la instancia de Document Intelligence que configuró en los pasos de configuración previa.
ai_service_name = "<Your linked service for Document Intelligence>"
Análisis de diseño
Extrae texto e información del diseño de un documento determinado. El documento de entrada debe ser de uno de los tipos de contenido admitidos: "application/pdf", "image/jpeg", "image/png" o "image/tiff".
Entrada de ejemplo

from pyspark.sql.functions import col, flatten, regexp_replace, explode, create_map, lit
imageDf = spark.createDataFrame([
("<replace with your file path>/layout.jpg",)
], ["source",])
analyzeLayout = (AnalyzeLayout()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("layout")
.setConcurrency(5))
display(analyzeLayout
.transform(imageDf)
.withColumn("lines", flatten(col("layout.analyzeResult.readResults.lines")))
.withColumn("readLayout", col("lines.text"))
.withColumn("tables", flatten(col("layout.analyzeResult.pageResults.tables")))
.withColumn("cells", flatten(col("tables.cells")))
.withColumn("pageLayout", col("cells.text"))
.select("source", "readLayout", "pageLayout"))
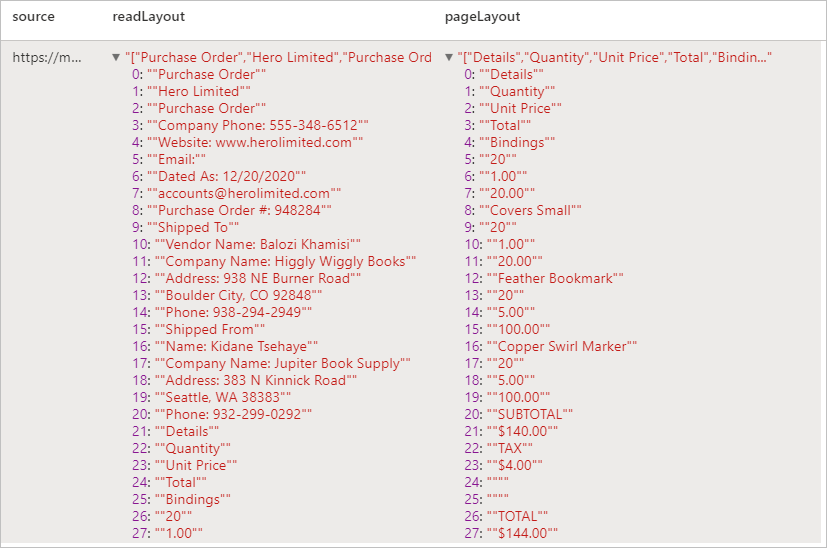
Resultados esperados
Análisis de recibos
Detecta y extrae datos de los recibos mediante el reconocimiento óptico de caracteres (OCR) y nuestro modelo de recibo, lo que le permite extraer fácilmente datos estructurados de los recibos como el nombre del comerciante, el número de teléfono del comerciante, la fecha de transacción, el total de transacciones, etc.
Entrada de ejemplo

imageDf2 = spark.createDataFrame([
("<replace with your file path>/receipt1.png",)
], ["image",])
analyzeReceipts = (AnalyzeReceipts()
.setLinkedService(ai_service_name)
.setImageUrlCol("image")
.setOutputCol("parsed_document")
.setConcurrency(5))
results = analyzeReceipts.transform(imageDf2).cache()
display(results.select("image", "parsed_document"))
Resultados esperados

Análisis de tarjetas de presentación
Detecta y extrae datos de tarjetas de presentación mediante el reconocimiento óptico de caracteres (OCR) y nuestro modelo de tarjeta de presentación, lo que le permite extraer fácilmente datos estructurados de las tarjetas de presentación, como nombres de contacto, nombres de empresa, números de teléfono, correos electrónicos, etc.
Entrada de ejemplo

imageDf3 = spark.createDataFrame([
("<replace with your file path>/business_card.jpg",)
], ["source",])
analyzeBusinessCards = (AnalyzeBusinessCards()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("businessCards")
.setConcurrency(5))
display(analyzeBusinessCards
.transform(imageDf3)
.withColumn("documents", explode(col("businessCards.analyzeResult.documentResults.fields")))
.select("source", "documents"))
Resultados esperados

Análisis de facturas
Detecta y extrae datos de facturas mediante el reconocimiento óptico de caracteres (OCR) y nuestros modelos de aprendizaje profundo de la comprensión de facturas, lo que le permite extraer fácilmente datos estructurados de las facturas como cliente, proveedor, identificador de factura, fecha de vencimiento de factura, total, importe de factura debido, importe de impuestos, dirección de envío, dirección de facturación, artículos en línea y mucho más.
Entrada de ejemplo

imageDf4 = spark.createDataFrame([
("<replace with your file path>/invoice.png",)
], ["source",])
analyzeInvoices = (AnalyzeInvoices()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("invoices")
.setConcurrency(5))
display(analyzeInvoices
.transform(imageDf4)
.withColumn("documents", explode(col("invoices.analyzeResult.documentResults.fields")))
.select("source", "documents"))
Resultados esperados

Análisis de documentos de identificación
Detecta y extrae datos de documentos de identificación mediante el reconocimiento óptico de caracteres (OCR) y nuestro modelo de documento de identificación, lo que le permite extraer fácilmente datos estructurados de los documentos de identificación, como el nombre, el apellido, la fecha de nacimiento, el número de documento, etc.
Entrada de ejemplo

imageDf5 = spark.createDataFrame([
("<replace with your file path>/id.jpg",)
], ["source",])
analyzeIDDocuments = (AnalyzeIDDocuments()
.setLinkedService(ai_service_name)
.setImageUrlCol("source")
.setOutputCol("ids")
.setConcurrency(5))
display(analyzeIDDocuments
.transform(imageDf5)
.withColumn("documents", explode(col("ids.analyzeResult.documentResults.fields")))
.select("source", "documents"))
Resultados esperados

Limpieza de recursos
Para asegurarse de que se cierra la instancia de Spark, finalice todas las sesiones (cuadernos) conectadas. El grupo se cierra cuando se alcanza el tiempo de inactividad especificado en el grupo de Apache Spark. También puede decidir finalizar la sesión en la barra de estado en la parte superior derecha del cuaderno.
