Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
El área de trabajo de Azure Synapse Analytics permite crear dos tipos de bases de datos sobre un lago de datos de Spark:
- Bases de datos de lagos donde puede definir tablas sobre datos de lago mediante cuadernos de Apache Spark, plantillas de bases de datos o Microsoft Dataverse (anteriormente Common Data Service). Estas tablas se pueden consultar mediante el lenguaje T-SQL (Transact-SQL) mediante el grupo de SQL sin servidor.
- Bases de datos SQL donde puede definir sus propias bases de datos y tablas directamente mediante el grupo de SQL sin servidor. Puede usar T-SQL CREATE DATABASE, CREATE EXTERNAL TABLE para definir los objetos y agregar vistas adicionales de SQL, procedimientos y funciones insertadas de valores de tablas sobre las tablas.
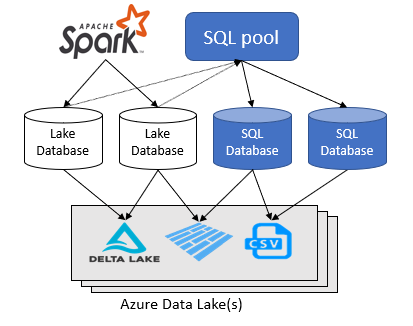
Este artículo se centra en las bases de datos de lago de un grupo de SQL sin servidor en Azure Synapse Analytics.
Azure Synapse Analytics permite crear bases de datos de lago y tablas mediante Spark o el diseñador de bases de datos y, a continuación, analizar los datos de las bases de datos del lago mediante el grupo de SQL sin servidor. Las bases de datos de lago y las tablas (parquet o CSV con respaldo) que se crean en los grupos de Apache Spark, las plantillas de base de datos de lagoo Dataverse están disponibles automáticamente para realizar consultas con el motor del grupo de SQL sin servidor. Las bases de datos y tablas del lago que se modifican están disponibles en el grupo de SQL sin servidor después de algún tiempo. Hay un retraso hasta que los cambios realizados en Spark o el diseñador de bases de datos aparecen en sin servidor.
Administración de la base de datos de lago
Para administrar bases de datos de lago creadas por Spark, puede usar grupos de Apache Spark o diseñador de bases de datos. Por ejemplo, puede crear o eliminar una base de datos de lago mediante un trabajo de grupo de Spark. No se puede crear una base de datos de lago ni los objetos de esta mediante el grupo de SQL sin servidor.
La base de datos default de Spark, también estará disponible en el contexto del grupo de SQL sin servidor como una base de datos de lago llamada default.
Nota:
No se puede crear un lago ni una base de datos SQL en el grupo de SQL sin servidor con el mismo nombre.
Las tablas de las bases de datos de lago no se pueden modificar desde un grupo de SQL sin servidor. Use el diseñador de bases de datos o grupos de Apache Spark para modificar una base de datos de lago. El grupo de SQL sin servidor permite realizar los siguientes cambios en una base de datos de lago mediante comandos T-SQL:
- Agregar, modificar y quitar vistas, procedimientos, funciones de valores de tabla insertadas en una base de datos de lago.
- Agregue y quite usuarios de Microsoft Entra con ámbito de base de datos.
- Agregar o quitar usuarios de base de datos de Microsoft Entra en el rol db_datareader. Los usuarios de la base de datos de Microsoft Entra en el rol de db_datareader tienen permiso para leer todas las tablas de la base de datos lake, pero no pueden leer datos de otras bases de datos.
Modelo de seguridad
Las bases de datos y tablas del lago están protegidas en dos niveles:
- La capa de almacenamiento subyacente mediante la asignación a los usuarios de Microsoft Entra de una de las siguientes opciones:
- Control de acceso basado en roles de Azure (RBAC de Azure)
- Rol de control de acceso basado en atributos de Azure (Azure ABAC)
- Permisos de lista de control de acceso (ACL)
- La capa de SQL en la que puede definir un usuario de Microsoft Entra y conceder permisos de SQL para
SELECTdatos de tablas que hacen referencia a los datos del lago.
Modelo de seguridad de lago
El acceso a los archivos de base de datos del lago se controla mediante los permisos de lago en la capa de almacenamiento. Solo los usuarios de Microsoft Entra pueden usar tablas en las bases de datos del lago y acceder a los datos del lago mediante sus propias identidades.
Puede conceder acceso a los datos subyacentes usados para las tablas externas a una entidad de seguridad como, por ejemplo, un usuario, una aplicación de Microsoft Entra con una entidad de servicio asignada o un grupo de seguridad. Para el acceso a datos, conceda los permisos siguientes:
- Conceda el permiso
read (R)a los archivos (por ejemplo, a los archivos de datos subyacentes de la tabla). - Conceda el permiso
execute (X)en la carpeta donde se almacenan los archivos y en cada carpeta primaria hasta la raíz. Puede obtener más información sobre estos permisos en Listas de control de acceso (ACL).
Por ejemplo, en https://<storage-name>.dfs.core.windows.net/<fs>/synapse/workspaces/<synapse_ws>/warehouse/mytestdb.db/myparquettable/, las entidades de seguridad necesitan:
- permisos
execute (X)en todas las carpetas a partir de<fs>enmyparquettable. - permisos
read (R)enmyparquettabley en los archivos dentro de esa carpeta, para poder leer una tabla de una base de datos (sincronizada u original).
Si una entidad de seguridad requiere la capacidad de crear objetos o quitar objetos en una base de datos, se requieren permisos de write (W) adicionales en las carpetas y los archivos de la carpeta almacenamiento. La modificación de objetos de una base de datos no es posible desde el grupo de SQL sin servidor, solo desde grupos de Spark o el diseñador de bases de datos.
Modelo de seguridad de SQL
El área de trabajo de Azure Synapse proporciona un punto de conexión de T-SQL que le permite consultar la base de datos de lago mediante el grupo de SQL sin servidor. Además del acceso a los datos, la interfaz SQL permite controlar quién puede acceder a las tablas. Debe permitir que un usuario acceda a las bases de datos de lago compartidas mediante el grupo de SQL sin servidor. Hay dos tipos de usuarios que pueden acceder a las bases de datos del lago:
- Administradores: asigne el rol de área de trabajo Administrador de Synapse SQL o el rol sysadmin en el nivel de servidor dentro del grupo de SQL sin servidor. Este rol tiene control total sobre todas las bases de datos. Los roles Administrador de Synapse y Administrador de Synapse SQL también tienen todos los permisos en todos los objetos del grupo de SQL sin servidor de forma predeterminada.
- Lectores del área de trabajo: conceda los permisos de nivel de servidor GRANT CONNECT ANY DATABASE y GRANT SELECT ALL USER SECURABLES en un grupo de SQL sin servidor a un inicio de sesión que permita que el inicio de sesión acceda y lea cualquier base de datos. Esta podría ser una buena opción para asignar acceso de lector o no administrador a un usuario.
- Lectores de base de datos: cree usuarios de base de datos de Microsoft Entra ID en la base de datos lake y agréguelos al rol db_datareader, lo que les permite leer datos en la base de datos del lago.
Obtenga más información sobre establecer el control de acceso en bases de datos compartidas.
Objetos SQL personalizados en bases de datos de lago
Las bases de datos de lago permiten la creación de objetos T-SQL personalizados, como esquemas, procedimientos, vistas y funciones insertadas de valores de tabla (iTVF). Para crear objetos SQL personalizados, DEBE crear un esquema en el que colocará los objetos. Los objetos SQL personalizados no se pueden colocar en dbo esquema porque está reservado para las tablas de lago definidas en Spark, el diseñador de bases de datos o Dataverse.
Importante
Debe crear un esquema SQL personalizado en el que colocará los objetos SQL. Los objetos SQL personalizados no se pueden colocar en el esquema de dbo. El esquema dbo está reservado para las tablas de lago creadas originalmente en Spark o el diseñador de bases de datos.
Ejemplos
Creación de un lector de bases de datos SQL en la base de datos de lago
En este ejemplo, agregamos un usuario de Microsoft Entra en la base de datos lake que puede leer datos a través de tablas compartidas. Los usuarios se agregan a la base de datos del lago mediante el grupo de SQL sin servidor. A continuación, asigne el usuario al rol db_datareader para que pueda leer los datos.
CREATE USER [customuser@contoso.com] FROM EXTERNAL PROVIDER;
GO
ALTER ROLE db_datareader
ADD MEMBER [customuser@contoso.com];
Creación de un lector de datos de nivel de área de trabajo
Un inicio de sesión con los permisos GRANT CONNECT ANY DATABASE y GRANT SELECT ALL USER SECURABLES podrá leer todas las tablas mediante el grupo de SQL sin servidor, pero no podrá crear bases de datos SQL ni modificar los objetos que contengan.
CREATE LOGIN [wsdatareader@contoso.com] FROM EXTERNAL PROVIDER
GRANT CONNECT ANY DATABASE TO [wsdatareader@contoso.com]
GRANT SELECT ALL USER SECURABLES TO [wsdatareader@contoso.com]
Este script le permite crear usuarios sin privilegios de administrador que puedan leer cualquier tabla en las bases de datos de Lake.
Creación y conexión a una base de datos de Spark con un grupo de SQL sin servidor
En primer lugar, cree una base de datos de Spark denominada mytestlakedb con un clúster de Spark que ya creó en el área de trabajo. Puede lograrlo, por ejemplo, mediante un cuaderno C# de Spark con la siguiente instrucción .NET para Spark:
spark.sql("CREATE DATABASE mytestlakedb")
Después de un breve retraso, puede ver la base de datos de lago del grupo de SQL sin servidor. Por ejemplo, ejecute la siguiente instrucción desde el grupo de SQL sin servidor.
SELECT * FROM sys.databases;
Compruebe que mytestlakedb se incluye en los resultados.
Creación de objetos SQL personalizados en una base de datos de lago
En el ejemplo siguiente se muestra cómo crear una vista personalizada, un procedimiento y una función insertada de valor de tabla (iTVF) en el esquema reports:
CREATE SCHEMA reports
GO
CREATE OR ALTER VIEW reports.GreenReport
AS SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
GO
CREATE OR ALTER PROCEDURE reports.GreenReportSummary
AS BEGIN
SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
END
GO
CREATE OR ALTER FUNCTION reports.GreenDataReportMonthly(@year int)
RETURNS TABLE
RETURN ( SELECT puYear = @year, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
WHERE puYear = @year
GROUP BY puMonth )
GO
Contenido relacionado
- Metadatos compartidos de Azure Synapse Analytics
- Tablas de metadatos compartidos de Azure Synapse Analytics
- Inicio rápido: creación de una nueva base de datos de lago mediante plantillas de base de datos
- Tutorial: Uso de un grupo de SQL sin servidor con Power BI Desktop y creación de un informe
- Sincronización de Apache Spark para las definiciones de tablas externas de Azure Synapse en un grupo de SQL sin servidor
- Tutorial: Exploración y análisis de lagos de datos con un grupo de SQL sin servidor