Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Sugerencia
Microsoft Fabric Data Warehouse es un almacenamiento relacional de escala empresarial en una base de lago de datos, con una arquitectura lista para el futuro, inteligencia artificial integrada y nuevas características. Si no está familiarizado con el almacenamiento de datos, comience con Fabric Data Warehouse. Las cargas de trabajo del grupo de SQL dedicadas pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
La función OPENROWSET(BULK...) permite acceder a archivos en Azure Storage.
La función OPENROWSET lee el contenido de un origen de datos remoto (por ejemplo, un archivo) y devuelve el contenido como un conjunto de filas. En el recurso del grupo de SQL sin servidor, para acceder al proveedor de conjuntos de filas BULK de OPENROWSET se llama a la función OPENROWSET y se especifica la opción BULK.
Se puede hacer referencia a la función OPENROWSET en la cláusula FROM de una consulta como si fuera un nombre de tabla OPENROWSET. Admite operaciones masivas a través de un proveedor integrado BULK que permite que los datos se lean y se devuelvan en forma de conjunto de filas.
Nota
La función OPENROWSET no se admite en el grupo dedicado de SQL.
Origen de datos
La función OPENROWSET de Synapse SQL lee el contenido de los archivos de un origen de datos. El origen de datos es una cuenta de almacenamiento de Azure a la que se puede hacer referencia explícitamente en la función OPENROWSET o se puede deducir dinámicamente a partir de la dirección URL de los archivos que quiera leer.
La función OPENROWSET puede contener opcionalmente un parámetro DATA_SOURCE para especificar el origen de datos que contiene los archivos.
OPENROWSETsinDATA_SOURCEse puede usar para leer directamente el contenido de los archivos desde la ubicación de la dirección URL especificada como opciónBULK:SELECT * FROM OPENROWSET(BULK 'http://<storage account>.dfs.core.windows.net/container/folder/*.parquet', FORMAT = 'PARQUET') AS [file]
Se trata de una manera rápida y sencilla de leer el contenido de los archivos sin necesidad de preconfiguración. Esta opción le permite usar la opción de autenticación básica para acceder al almacenamiento (acceso directo de Microsoft Entra para inicios de sesión de Microsoft Entra y tokens de SAS para inicios de sesión de SQL).
OPENROWSETconDATA_SOURCEse puede usar para tener acceso a los archivos de la cuenta de almacenamiento especificada:SELECT * FROM OPENROWSET(BULK '/folder/*.parquet', DATA_SOURCE='storage', --> Root URL is in LOCATION of DATA SOURCE FORMAT = 'PARQUET') AS [file]Esta opción le permite configurar la ubicación de la cuenta de almacenamiento en el origen de datos y especificar el método de autenticación que debe usarse para tener acceso al almacenamiento.
Importante
OPENROWSETsinDATA_SOURCEproporciona una forma rápida y sencilla de acceder a los archivos de almacenamiento, pero ofrece opciones de autenticación limitadas. Por ejemplo, las entidades de seguridad de Microsoft Entra pueden acceder a los archivos solo mediante su identidad de Microsoft Entra o archivos disponibles públicamente. Si necesita opciones de autenticación más eficaces, use la opciónDATA_SOURCEy defina las credenciales que quiera usar para tener acceso al almacenamiento.
Seguridad
Un usuario de base de datos debe tener permiso de ADMINISTER BULK OPERATIONS para utilizar la función OPENROWSET.
El administrador de almacenamiento también debe permitir que un usuario tenga acceso a los archivos proporcionando un token de SAS válido o habilitando la entidad de seguridad de Microsoft Entra para tener acceso a los archivos de almacenamiento. Obtenga más información sobre el control de acceso de almacenamiento en este artículo.
OPENROWSET usa las siguientes reglas para determinar cómo autenticarse en el almacenamiento:
- En
OPENROWSETsinDATA_SOURCEel mecanismo de autenticación depende del tipo de autor de llamada.- Cualquier usuario puede utilizar
OPENROWSETsinDATA_SOURCEpara leer los archivos disponibles públicamente en Azure Storage. - Los inicios de sesión de Microsoft Entra solo pueden acceder a los archivos protegidos mediante su propia identidad de Microsoft Entra si Azure Storage permite al usuario de Microsoft Entra acceder a los archivos subyacentes (por ejemplo, si el autor de la llamada tiene permiso de
Storage Readeren Azure Storage). - Los inicios de sesión de SQL también pueden usar
OPENROWSETsinDATA_SOURCEpara tener acceso a los archivos disponibles públicamente, a los archivos protegidos mediante el token de SAS o a la identidad administrada del área de trabajo Synapse. Debe crear credenciales con ámbito en el servidor para permitir el acceso a los archivos de almacenamiento.
- Cualquier usuario puede utilizar
- En
OPENROWSETconDATA_SOURCE, el mecanismo de autenticación se define en la credencial con ámbito en la base de datos asignada al origen de datos al que se hace referencia. Esta opción permite acceder al almacenamiento disponible públicamente o acceder al almacenamiento mediante el token de SAS, la identidad administrada del área de trabajo o la identidad del autor de llamada de Microsoft Entra (si el autor de llamada es la entidad de seguridad de Microsoft Entra). SiDATA_SOURCEhace referencia a una instancia de Azure Storage que no sea pública, deberá crear una credencial cuyo ámbito sea la base de datos y hacer referencia a ella enDATA SOURCEpara permitir el acceso a los archivos de almacenamiento.
El autor de llamada debe tener permiso de REFERENCES en la credencial para usarla para autenticarse en el almacenamiento.
Sintaxis
--OPENROWSET syntax for reading Parquet or Delta Lake files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT= ['PARQUET' | 'DELTA'] }
)
[WITH ( {'column_name' 'column_type' }) ]
[AS] table_alias(column_alias,...n)
--OPENROWSET syntax for reading delimited text files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT = 'CSV'
[ <bulk_options> ]
[ , <reject_options> ] }
)
WITH ( {'column_name' 'column_type' [ 'column_ordinal' | 'json_path'] })
[AS] table_alias(column_alias,...n)
<bulk_options> ::=
[ , FIELDTERMINATOR = 'char' ]
[ , ROWTERMINATOR = 'char' ]
[ , ESCAPECHAR = 'char' ]
[ , FIRSTROW = 'first_row' ]
[ , FIELDQUOTE = 'quote_characters' ]
[ , DATA_COMPRESSION = 'data_compression_method' ]
[ , PARSER_VERSION = 'parser_version' ]
[ , HEADER_ROW = { TRUE | FALSE } ]
[ , DATAFILETYPE = { 'char' | 'widechar' } ]
[ , CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ , ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}' ]
<reject_options> ::=
{
| MAXERRORS = reject_value,
| ERRORFILE_DATA_SOURCE = <data source name>,
| ERRORFILE_LOCATION = '/REJECT_Directory'
}
Argumentos
Hay tres opciones para los archivos de entrada que contienen los datos de destino para realizar consultas. Los valores válidos son:
"CSV": incluye cualquier archivo de texto delimitado con separadores de filas o columnas. Se puede usar cualquier carácter como separador de campo, como TSV: FIELDTERMINATOR = pestaña.
"PARQUET": archivo binario en formato Parquet.
"DELTA": conjunto de archivos Parquet organizados en formato Delta Lake (versión preliminar).
Los valores con espacios en blanco no son válidos. Por ejemplo, "CSV" no es un valor válido.
"unstructured_data_path"
El elemento unstructured_data_path que establece una ruta de acceso a los datos puede ser una ruta de acceso relativa o absoluta:
- La ruta de acceso absoluta con el formato
\<prefix>://\<storage_account_path>/\<storage_path>permite que un usuario lea directamente los archivos. - Ruta de acceso relativa con el formato
<storage_path>que se debe usar con el parámetroDATA_SOURCEy describe el patrón de archivo en la ubicación <storage_account_path> definida enEXTERNAL DATA SOURCE.
A continuación, encontrará los valores pertinentes de la <ruta de acceso de la cuenta de almacenamiento> que se vincularán a su origen de datos externo concreto.
| Origen de datos externo | Prefijo | Ruta de acceso a la cuenta de almacenamiento |
|---|---|---|
| Azure Blob Storage | http[s] | <storage_account>.blob.core.windows.net/path/file |
| Azure Blob Storage | wasb[s] | <container>@<storage_account>.blob.core.windows.net/path/file |
| Azure Data Lake Store Gen1 | http[s] | <storage_account>.azuredatalakestore.net/webhdfs/v1 |
| Azure Data Lake Store Gen2 | http[s] | <storage_account>.dfs.core.windows.net/path/file |
| Azure Data Lake Store Gen2 | abfs[s] | <file_system>@<account_name.dfs.core.windows.net/path/file> |
"<ruta_almacenamiento>"
Especifica una ruta de acceso en el almacenamiento que apunta a la carpeta o archivo que desea leer. Si la ruta de acceso apunta a un contenedor o a una carpeta, se leerán todos los archivos de ese contenedor o carpeta. No se incluirán los archivos de las subcarpetas.
Puede usar caracteres comodín si el destino son varios archivos o carpetas. Se permite el uso de varios caracteres comodín no consecutivos.
A continuación se muestra un ejemplo en el que se leen todos los archivos csv que comienzan por population de todas las carpetas a partir de /csv/population:
https://sqlondemandstorage.blob.core.windows.net/csv/population*/population*.csv
Si especifica que el elemento unstructured_data_path sea una carpeta, una consulta del grupo de SQL sin servidor recupera los archivos de esa carpeta.
Puede indicar al grupo de SQL sin servidor que pase por las carpetas; para ello, especifique /* al final de la ruta de acceso, como en el ejemplo: https://sqlondemandstorage.blob.core.windows.net/csv/population/**
Nota
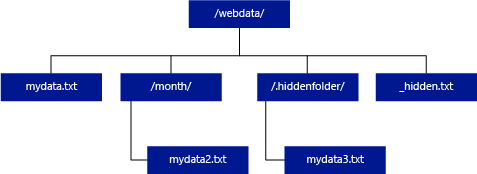
A diferencia de Hadoop y PolyBase, el grupo de SQL sin servidor no devuelve subcarpetas a menos que especifique /** al final de la ruta de acceso. Al igual que Hadoop y PolyBase, no devuelve archivos cuyo nombre comienza por un carácter de subrayado (_) o un punto (.).
En el ejemplo siguiente, si unstructured_data_path = https://mystorageaccount.dfs.core.windows.net/webdata/, una consulta del grupo de SQL sin servidor devolverá filas de mydata.txt. No devolverá mydata2. txt y mydata3. txt porque se encuentran en una subcarpeta.
[WITH ( {'column_name' 'column_type' [ 'column_ordinal'] }) ]
La cláusula WITH le permite especificar las columnas que desea leer de los archivos.
En el caso de los archivos de datos con la extensión .csv, para leer todas las columnas, especifique los nombres de columna y sus tipos de datos. Si desea un subconjunto de columnas, use números ordinales para seleccionar las columnas en los archivos de datos de origen por ordinal. Las columnas se enlazarán por la designación ordinal. Si se usa HEADER_ROW = TRUE, el enlace de columna se realiza por nombre de columna, no por posición ordinal.
Sugerencia
También puede omitir la cláusula WITH para los archivos .csv. Los tipos de datos se infieren automáticamente a partir del contenido del archivo. Puede usar el argumento HEADER_ROW para especificar que existe una fila de encabezado, en cuyo caso los nombres de columna se leerán de ella. Para más información, consulte Detección automática del esquema.
En el caso de los archivos con formato Parquet o Delta Lake, especifique nombres de columna que coincidan con los de los archivos de datos de origen. Las columnas se enlazan por nombre y distinguen mayúsculas de minúsculas. Si se omite la cláusula WITH, se devolverán todas las columnas de los archivos con formato Parquet.
Importante
Los nombres de columna de los archivos con formato Parquet y Delta Lake distinguen mayúsculas de minúsculas. Si especifica el nombre de columna con un tratamiento de distinción de mayúsculas y minúsculas diferente del que se hace en los archivos, se devolverán valores
NULLpara esa columna.
column_name = Nombre de la columna de salida. Si se especifica, este nombre reemplaza el nombre de columna del archivo de origen fuente y el nombre de columna especificado en la ruta de acceso JSON, en caso de que haya. Si no se proporciona json_path, se agregará automáticamente como "$.column_name". Compruebe el comportamiento del argumento json_path.
column_type = Tipo de datos de la columna de salida. La conversión implícita del tipo de datos tendrá lugar aquí.
column_ordinal = Número ordinal de la columna en los archivos de origen. Este argumento se omite para los archivos con formato Parquet, ya que el enlace se realiza por nombre. En el ejemplo siguiente se devuelve una segunda columna solo desde un archivo .csv:
WITH (
--[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2 2
--[year] smallint,
--[population] bigint
)
json_path = ruta de acceso de JSON para la columna o propiedad anidada. El modo de ruta de acceso predeterminado es lax.
Nota
En el modo strict, la consulta generará un error si la ruta de acceso especificada no existe. En el modo lax, la consulta se realizará correctamente y la expresión de la ruta de acceso de JSON se evaluará como NULL.
<opciones masivas>
FIELDTERMINATOR ='field_terminator'
Especifica el terminador de campo que se va a usar. El terminador de campo predeterminado es una coma (",").
ROWTERMINATOR ='row_terminator'`
Especifica el terminador de fila que se va a usar. Si no se especifica ningún terminador de fila, se usará uno de los terminadores predeterminados. Los terminadores predeterminados para PARSER_VERSION = "1.0" son \r\n, \n y \r. Los terminadores predeterminados para PARSER_VERSION = "2.0" son \r\n y \n.
Nota
Si usa PARSER_VERSION="1.0" y especifica \n (nueva línea) como terminador de fila, se antepondrá automáticamente el carácter \r (retorno de carro) como prefijo, lo que genera el terminador de fila \r\n.
ESCAPE_CHAR = "char"
Especifica el carácter del archivo que se usa como carácter de escape de sí mismo y de todos los valores de delimitador del archivo. Si el carácter de escape va seguido de un valor distinto de sí mismo o de cualquiera de los valores de delimitador, se quita al leer el valor.
El parámetro ESCAPECHAR se aplicará independientemente de que FIELDQUOTE esté habilitado o no. No se utilizará como carácter de escape el carácter de comillas. El carácter de comillas se debe escapar con otro carácter de comillas. El carácter de comillas solo puede aparecer dentro del valor de la columna si el valor se encapsula entre caracteres de comillas.
FIRSTROW = "first_row"
Especifica el número de la primera fila que se va a cargar. El valor predeterminado es 1, e indica la primera fila del archivo de datos especificado. Los números de fila vienen determinados por el recuento de terminadores de fila. FIRSTROW está en base 1.
FIELDQUOTE = "field_quote"
Especifica un carácter que se usará como carácter de comillas en el archivo CSV. Si no se especifica, se usará el carácter de comillas (").
DATA_COMPRESSION = "data_compression_method"
Especifica el método de compresión. Solo se admite en PARSER_VERSION='1.0'. Se admite el siguiente método de compresión:
- GZIP
PARSER_VERSION = "parser_version"
Especifica la versión del analizador que se utilizará al leer archivos. Las versiones del analizador de archivos .csv admitidas actualmente son 1.0 y 2.0:
- PARSER_VERSION = "1.0"
- PARSER_VERSION = "2.0"
La versión 1.0 del analizador de CSV es la predeterminada y tiene gran cantidad de características. La versión 2.0 se centra en el rendimiento y no admite todas las opciones y codificaciones.
Detalles de la versión 1.0 del analizador de CSV:
- Las siguientes opciones no se admiten: HEADER_ROW.
- Los terminadores predeterminados son \r\n, \n y \r.
- Si especifica \n (nueva línea) como terminador de fila, se agregará automáticamente el carácter \r (retorno de carro) como prefijo, lo que genera un terminador de fila \r\n.
Detalles de la versión 2.0 del analizador de CSV:
- No se admiten todos los tipos de datos.
- La longitud máxima de la columna es 8000 caracteres.
- El límite máximo de tamaño de fila es de 8 MB.
- Las siguientes opciones no se admiten: DATA_COMPRESSION.
- La cadena vacía entre comillas ("") se interpreta como una cadena vacía.
- No se respeta la opción DATEFORMAT SET.
- Formato admitido para el tipo de datos DATE: AAAA-MM-DD
- Formato admitido para el tipo de datos TIME: HH:MM:SS[.fracciones de segundos]
- Formato admitido para DATETIME2 tipo de datos: AAAA-MM-DD HH:MM:SS[.fracciones segundos]
- Los terminadores predeterminados son \r\n y \n.
HEADER_ROW = { TRUE | FALSE }
Especifica si un archivo .csv contiene una fila de encabezado. El valor predeterminado es FALSE. Se admite en PARSER_VERSION='2.0'. Si es TRUE, los nombres de columna se leerán de la primera fila según el argumento FIRSTROW. Si es TRUE y el esquema se especifica mediante WITH, el enlace de los nombres de columna se realizará por nombre de columna, no por posiciones ordinales.
DATAFILETYPE = { 'char' | 'widechar' }
Especifica que se usa la codificación char para archivos UTF8 y widechar para archivos UTF16.
CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' }
Especifica la página de códigos de los datos incluidos en el archivo de datos. El valor predeterminado es 65001 (codificación UTF-8). Obtenga más información sobre esta opción aquí.
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}'
Esta opción deshabilitará la comprobación de modificación de archivos durante la ejecución de la consulta y leerá los archivos que se actualizan mientras se ejecuta la consulta. Esta opción es útil cuando tiene que leer archivos de solo anexión que se anexan mientras se ejecuta la consulta. En los archivos anexables, el contenido existente no se actualiza y solo se agregan nuevas filas. Por lo tanto, se reduce la probabilidad de resultados incorrectos en comparación con los archivos actualizables. Esta opción podría permitirle leer los archivos anexados con frecuencia sin necesidad de administrar los errores. Consulte más información en la sección Consulta de archivos anexables.
Opciones de Reject
Nota
La característica de filas rechazadas está en versión preliminar pública. Tenga en cuenta que la característica de filas rechazadas funciona para archivos de texto delimitados y PARSER_VERSION 1.0.
Puede especificar los parámetros de rechazo que determinan la forma en que el servicio manejará los registros desfasados que recupera de la fuente de datos externa. Un registro de datos se considera "desfasado" si los tipos de datos reales no coinciden con las definiciones de columna de la tabla externa.
Si no se especifican ni se cambian los valores de rechazo, el servicio utiliza los valores predeterminados. El servicio usará las opciones de rechazo para determinar el número de filas que se pueden rechazar antes de que se produce un error en la consulta real. La consulta devolverá resultados (parciales) hasta que se supere el umbral de rechazo. Después, se produce un error con el mensaje de error correspondiente.
MAXERRORS = reject_value
Especifica el número de filas que se pueden rechazar antes de que se produzca un error en la consulta. MAXERRORS debe ser un número entero entre 0 y 2 147 483 647.
ERRORFILE_DATA_SOURCE = origen de datos
Especifica el origen de datos donde se deben escribir las filas rechazadas y el archivo de error correspondiente.
ERRORFILE_LOCATION = Ubicación del directorio
Especifica el directorio dentro de DATA_SOURCE, o ERROR_FILE_DATASOURCE si se especifica, en el que deben escribirse las filas rechazadas y el archivo de errores correspondientes. Si la ruta de acceso especificada no existe, el servicio creará una en su nombre. Se crea un directorio secundario con el nombre “rejectedrows”. El carácter “” garantiza que se escape el directorio para otro procesamiento de datos, a menos que se mencione explícitamente en el parámetro de ubicación. En este directorio hay una carpeta que se crea según la hora de envío de la carga con el formato AñoMesDía_HoraMinutoSegundo_Id.Instrucción (Ej. 20180330-173205-559EE7D2-196D-400A-806D-3BF5D007F891). Puede usar el identificador de instrucción para correlacionar la carpeta con la consulta que la generó. En esta carpeta, se escriben dos archivos: el archivo error.json y el archivo de datos.
El archivo error.json contiene una matriz json con los errores encontrados relacionados con las filas rechazadas. Cada elemento que representa un error contiene los siguientes atributos:
| Atributo | Descripción |
|---|---|
| Error | Motivo por el que se rechaza la fila. |
| Row | Número ordinal de la fila rechazada en el archivo. |
| Columna | Número ordinal de la columna rechazada. |
| Value | Valor de la columna rechazada. Si el valor tiene más de cien caracteres, solo se mostrarán los cien primeros. |
| Archivo | Ruta de acceso al archivo al que pertenece la fila. |
Análisis de texto delimitado rápido
Hay dos versiones de analizador de texto delimitado que se pueden usar. La versión 1.0 del analizador de archivos .csv es la predeterminada y cuenta con numerosas características, mientras que la versión 2.0 se basa en el rendimiento. La mejora en el rendimiento de la versión 2.0 del analizador se debe al uso de técnicas avanzadas de análisis y subprocesos múltiples. La diferencia de velocidad será mayor cuanto mayor sea el tamaño del archivo.
Detección automática del esquema
Puede consultar fácilmente archivos con formato .csv y Parquet sin necesidad de conocer o especificar el esquema; para ello, omita la cláusula WITH. Los nombres de columna y los tipos de datos se inferirán de los archivos.
Los archivos con formato Parquet contienen metadatos de columna que se leerán; las asignaciones de tipo se encuentran en Asignación de tipos para Parquet. Consulte Lectura de archivos Parquet sin esquema específico para ver ejemplos.
En el caso de los archivos .csv, los nombres de columna se leen de la fila de encabezado. Se puede especificar si existe la fila de encabezado mediante el argumento HEADER_ROW. Si HEADER_ROW = FALSE, se usarán los nombres de columna genéricos: C1, C2, ... Cn, donde n es el número de columnas del archivo. Los tipos de datos se inferirán de las primeras 100 filas de datos. Consulte Lectura de archivos .csv sin esquema específico para ejemplos.
Tenga en cuenta que, si lee varios archivos a la vez, el esquema se inferirá del primer servicio de archivos que se obtenga del almacenamiento. Esto puede significar que algunas de las columnas esperadas estén omitidas, y todo porque el archivo utilizado por el servicio para definir el esquema no contenía estas columnas. En ese caso, use la cláusula OPENROWSET WITH.
Importante
A veces no se puede inferir el tipo de datos adecuado por la falta de información; en este caso, se usa un tipo de datos mayor en su lugar. Esto aporta un rendimiento extra y es especialmente importante para las columnas de caracteres que se infieren, como varchar (8000). Para obtener un rendimiento óptimo, consulte Comprobación de los tipos de datos inferidos y Uso del tipo de datos adecuado.
Asignación de tipos para Parquet
Los archivos Parquet y Delta Lake contienen descripciones de tipos para cada columna. En la tabla siguiente se describe cómo se asignan los tipos de Parquet a los tipos nativos de SQL.
| Tipo de Parquet | Tipo lógico de Parquet (anotación) | Tipo de datos de SQL |
|---|---|---|
| BOOLEAN | bit | |
| BINARY/BYTE_ARRAY | varbinary | |
| DOUBLE | FLOAT | |
| FLOAT | real | |
| INT32 | int | |
| INT64 | bigint | |
| INT96 | datetime2 | |
| FIXED_LEN_BYTE_ARRAY | binary | |
| BINARY | UTF8 | varchar *(Intercalación UTF8) |
| BINARY | STRING | varchar *(Intercalación UTF8) |
| BINARY | ENUM | varchar *(Intercalación UTF8) |
| FIXED_LEN_BYTE_ARRAY | UUID | UNIQUEIDENTIFIER |
| BINARY | DECIMAL | Decimal |
| BINARY | JSON | varchar(8000) *(intercalación UTF8) |
| BINARY | BSON | No compatible |
| FIXED_LEN_BYTE_ARRAY | DECIMAL | Decimal |
| BYTE_ARRAY | INTERVAL | No compatible |
| INT32 | INT(8, verdadero) | SMALLINT |
| INT32 | INT(16, verdadero) | SMALLINT |
| INT32 | INT(32, true) | int |
| INT32 | INT(8, falso) | TINYINT |
| INT32 | INT(16, falso) | int |
| INT32 | INT(32, false) | bigint |
| INT32 | DATE | date |
| INT32 | DECIMAL | Decimal |
| INT32 | TIEMPO (MILISEGUNDOS) | time |
| INT64 | INT(64, verdadero) | bigint |
| INT64 | INT(64, falso) | decimal(20,0) |
| INT64 | DECIMAL | Decimal |
| INT64 | TIME (MICROS) | time |
| INT64 | TIEMPO (NANOS) | No compatible |
| INT64 | TIMESTAMP (normalizado a utc) (MILLIS / MICROS) | datetime2 |
| INT64 | TIMESTAMP (no normalizado a utc) (MILLIS / MICROS) | bigint: asegúrese de ajustar bigint explícitamente el valor con el desplazamiento de zona horaria antes de convertirlo en un valor datetime. |
| INT64 | TIMESTAMP (NANOS) | No compatible |
| Tipo complejo | LISTA | varchar(8000), serializado en JSON |
| Tipo complejo | MAP | varchar(8000), serializado en JSON |
Ejemplos
Lectura de archivos .csv sin esquema específico
En el ejemplo siguiente se lee un archivo .csv que contiene una fila de encabezado sin especificar nombres de columna ni tipos de datos:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE) as [r]
En el ejemplo siguiente se lee un archivo .csv que no contiene una fila de encabezado sin especificar nombres de columna ni tipos de datos:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0') as [r]
Lectura de archivos Parquet sin especificar el esquema
En el ejemplo siguiente se devuelven todas las columnas de la primera fila del conjunto de datos del censo en formato Parquet y sin especificar los nombres de columna ni los tipos de datos:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
) AS [r]
Lectura de archivos Delta Lake sin especificar el esquema
En el ejemplo siguiente se devuelven todas las columnas de la primera fila del conjunto de datos del censo en formato Delta Lake y sin especificar los nombres de columna ni los tipos de datos:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='DELTA'
) AS [r]
Lectura de columnas específicas de un archivo .csv
En el ejemplo siguiente se devuelven solo dos columnas con los números ordinales 1 y 4 de los archivos population*.csv. Al no haber fila de encabezado en los archivos, empieza a leer desde la primera línea:
SELECT
*
FROM OPENROWSET(
BULK 'https://sqlondemandstorage.blob.core.windows.net/csv/population/population*.csv',
FORMAT = 'CSV',
FIRSTROW = 1
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2 1,
[population] bigint 4
) AS [r]
Lectura de columnas específicas de un archivo Parquet
En el ejemplo siguiente se devuelven solo dos columnas de la primera fila del conjunto de datos del censo, con formato Parquet:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
[stateName] VARCHAR (50),
[population] bigint
) AS [r]
Especificación de columnas mediante rutas de acceso JSON
En el ejemplo siguiente se muestra cómo usar expresiones de ruta de acceso de JSON en una cláusula WITH y se muestra la diferencia entre los modos de ruta de acceso strict y lax:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
--lax path mode samples
[stateName] VARCHAR (50), -- this one works as column name casing is valid - it targets the same column as the next one
[stateName_explicit_path] VARCHAR (50) '$.stateName', -- this one works as column name casing is valid
[COUNTYNAME] VARCHAR (50), -- STATEname column will contain NULLs only because of wrong casing - it targets the same column as the next one
[countyName_explicit_path] VARCHAR (50) '$.COUNTYNAME', -- STATEname column will contain NULLS only because of wrong casing and default path mode being lax
--strict path mode samples
[population] bigint 'strict $.population' -- this one works as column name casing is valid
--,[population2] bigint 'strict $.POPULATION' -- this one fails because of wrong casing and strict path mode
)
AS [r]
Especificar varios archivos o carpetas en la ruta de acceso BULK
En el ejemplo siguiente se muestra cómo puede usar varias rutas de acceso de archivo o carpeta en el parámetro BULK:
SELECT
TOP 10 *
FROM
OPENROWSET(
BULK (
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2000/*.parquet',
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2010/*.parquet'
),
FORMAT='PARQUET'
)
AS [r]
Pasos siguientes
Para ver más ejemplos, consulte el inicio rápido del almacenamiento de datos de consulta para aprender a usar OPENROWSET para leer los formatos de archivo CSV,PARQUET, DELTA LAKE y JSON. Consulte los procedimientos recomendados para lograr un rendimiento óptimo. También puede obtener información sobre cómo guardar los resultados de la consulta en Azure Storage mediante CETAS.