Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Tip
Microsoft Fabric Data Warehouse es un almacenamiento relacional de escala empresarial en una base de lago de datos, con una arquitectura lista para el futuro, inteligencia artificial integrada y nuevas características. Si no está familiarizado con el almacenamiento de datos, comience con Fabric Data Warehouse. Las cargas de trabajo del grupo de SQL dedicadas pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
En este artículo, aprenderá a consultar un único archivo .csv mediante el grupo de SQL sin servidor en Azure Synapse Analytics. Los archivos CSV pueden tener distintos formatos:
- Con y sin una fila de encabezado
- Valores delimitados por comas y tabulaciones
- Finales de línea al estilo de Windows y Unix
- Valores entre comillas y sin comillas, y caracteres de escape
A continuación se abordan todas las variaciones anteriores.
Ejemplo de inicio rápido
La función OPENROWSET permite leer el contenido del archivo CSV al proporcionar la dirección URL al archivo.
Leer un archivo CSV
La forma más fácil de ver el contenido de su archivo CSV es proporcionar la URL del archivo a la función OPENROWSET, especificar que es un archivo CSV con FORMAT y su versión 2.0 con PARSER_VERSION. Si el archivo está disponible públicamente o si la identidad de Microsoft Entra puede tener acceso a este archivo, debería poder ver el contenido del archivo mediante la consulta como la que se muestra en el ejemplo siguiente:
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2 ) as rows
La opción firstrow se utiliza para omitir la primera fila del archivo CSV, que representa el encabezado en este caso. Asegúrese de que puede tener acceso a este archivo. Si el archivo está protegido con la clave SAS o la identidad personalizada, tendría que configurar las credenciales a nivel de servidor para el inicio de sesión de SQL.
Importante
Si el archivo CSV contiene caracteres UTF-8, asegúrese de que usa una intercalación de base de datos UTF-8 (por ejemplo Latin1_General_100_CI_AS_SC_UTF8).
Una falta de coincidencia entre la codificación de texto del archivo y la intercalación podría producir errores de conversión inesperados.
Puede cambiar fácilmente la intercalación predeterminada de la base de datos actual mediante la siguiente instrucción T-SQL: alter database current collate Latin1_General_100_CI_AI_SC_UTF8.
Uso del origen de datos
En el ejemplo anterior se usa la ruta de acceso completa al archivo. Como alternativa, puede crear un origen de datos externo con la ubicación que apunta a la carpeta raíz del almacenamiento:
create external data source covid
with ( location = 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases' );
Una vez creado el origen de datos, puede usar ese origen de datos y la ruta de acceso relativa al archivo en la función OPENROWSET:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) as rows
Si un origen de datos está protegido con una clave SAS o una identidad personalizada, puede configurar el origen de datos con credenciales con ámbito de base de datos.
Especificación explícita del esquema
OPENROWSET permite especificar explícitamente qué columnas desea leer del archivo con la cláusula WITH:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) with (
date_rep date 1,
cases int 5,
geo_id varchar(6) 8
) as rows
Los números posteriores a un tipo de datos de la cláusula WITH representan el índice de la columna en el archivo CSV.
Importante
Si el archivo CSV contiene caracteres UTF-8, asegúrese de especificar explícitamente alguna intercalación UTF-8 (por ejemplo Latin1_General_100_CI_AS_SC_UTF8) para todas las columnas de WITH la cláusula o establezca alguna intercalación UTF-8 en el nivel de base de datos.
La falta de coincidencia entre la codificación de texto del archivo y la intercalación podría producir errores de conversión inesperados.
Puede cambiar fácilmente la intercalación predeterminada de la base de datos actual mediante la siguiente instrucción T-SQL: .
alter database current collate Latin1_General_100_CI_AI_SC_UTF8 Puede establecer fácilmente la intercalación en los tipos de columna mediante la siguiente definición: geo_id varchar(6) collate Latin1_General_100_CI_AI_SC_UTF8 8
En las secciones siguientes, puede ver cómo consultar varios tipos de archivos CSV.
Requisitos previos
El primer paso es crear la base de datos en la que se crearán las tablas. Luego, se inicializan los objetos, para lo que hay que ejecutar un script de instalación en esa base de datos. Este script de instalación creará los orígenes de datos, las credenciales con ámbito de base de datos y los formatos de archivo externos que se usan en estos ejemplos.
Nueva línea al estilo de Windows
La consulta siguiente muestra cómo leer un archivo CSV sin una fila de encabezado, con una nueva línea al estilo de Windows y columnas delimitadas por comas.
Vista previa del archivo:
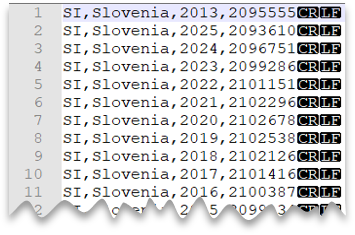
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Nueva línea al estilo de Unix
La consulta siguiente muestra cómo leer un archivo sin una fila de encabezado, con una nueva línea al estilo de Unix y columnas delimitadas por comas. Tenga en cuenta la ubicación diferente del archivo en comparación con los demás ejemplos.
Vista previa del archivo:
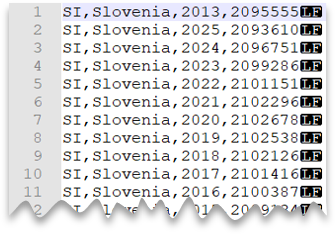
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Fila de encabezado
La consulta siguiente muestra cómo leer un archivo con una fila de encabezado, con una nueva línea al estilo de Unix y columnas delimitadas por comas. Tenga en cuenta la ubicación diferente del archivo en comparación con los demás ejemplos.
Vista previa del archivo:
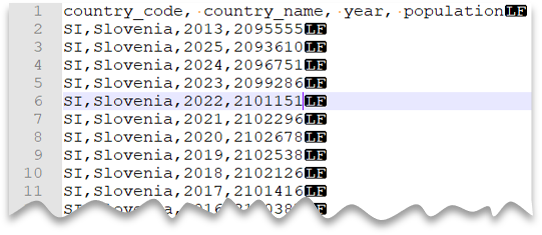
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
HEADER_ROW = TRUE
) AS [r]
La opción HEADER_ROW = TRUE provocará que se lean los nombres de columna de la fila de encabezado del archivo. Es excelente para fines de exploración cuando no está familiarizado con el contenido del archivo. Para obtener el mejor rendimiento, consulte la sección Uso de tipos de datos adecuados en Procedimientos recomendados. Además, puede leer más sobre la sintaxis de OPENROWSET aquí.
Carácter de comillas personalizado
La consulta siguiente muestra cómo leer un archivo con una fila de encabezado, con una nueva línea al estilo de Unix, columnas delimitadas por comas y valores entre comillas. Tenga en cuenta la ubicación diferente del archivo en comparación con los demás ejemplos.
Vista previa del archivo:
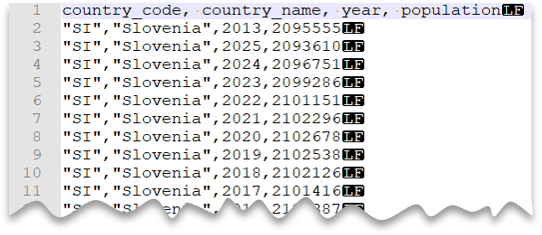
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
FIELDQUOTE = '"'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Nota
Esta consulta devolvería los mismos resultados si se omitiese el parámetro FIELDQUOTE, ya que el valor predeterminado de FIELDQUOTE es una comilla doble.
Caracteres de escape
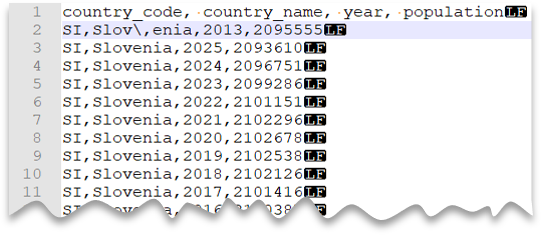
La consulta siguiente muestra cómo leer un archivo con una fila de encabezado, con una nueva línea al estilo de Unix, columnas delimitadas por comas y un carácter de escape usado para el delimitador de campos (coma) sin valores. Tenga en cuenta la ubicación diferente del archivo en comparación con los demás ejemplos.
Vista previa del archivo:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
ESCAPECHAR = '\\'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Nota
Esta consulta produciría un error si no se especifica ESCAPECHAR, ya que la coma de "Slov,enia" se trataría como delimitador de campo en lugar de formar parte del nombre de país o región. "Slov,enia" se consideraría como dos columnas. Por lo tanto, la fila en particular tendría una columna más que las demás filas y una columna más de la definida en la cláusula WITH.
Caracteres de comillas de escape
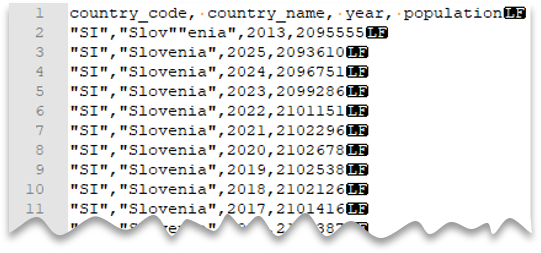
La consulta siguiente muestra cómo leer un archivo con una fila de encabezado, con una nueva línea al estilo de Unix, columnas delimitadas por comas y un carácter de comillas dobles de escape entre valores. Tenga en cuenta la ubicación diferente del archivo en comparación con los demás ejemplos.
Vista previa del archivo:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Nota
El carácter de comillas se debe escapar con otro carácter de comillas. El carácter de comillas solo puede aparecer dentro del valor de la columna si el valor se encapsula entre caracteres de comillas.
Archivos delimitados por tabulaciones
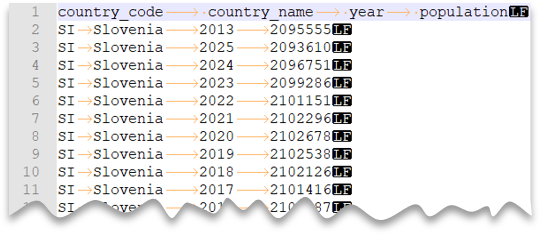
La consulta siguiente muestra cómo leer un archivo con una fila de encabezado, con una nueva línea al estilo de Unix y columnas delimitadas por tabulaciones. Tenga en cuenta la ubicación diferente del archivo en comparación con los demás ejemplos.
Vista previa del archivo:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-tsv/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR ='\t',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017
Devolver un subconjunto de columnas
Hasta ahora, ha especificado el esquema de archivos CSV mediante WITH y enumerando todas las columnas. Solo puede especificar las columnas que realmente necesita en la consulta mediante un número ordinal para cada columna necesaria. También omitirá las columnas que no sean de interés.
La consulta siguiente devuelve el número de nombres de país distintos incluidos en un archivo, especificando solo las columnas necesarias:
Nota
Eche un vistazo a la cláusula WITH en la consulta siguiente y observe que hay "2" (sin comillas) al final de la fila en la que se define la columna [country_name] . Significa que la columna [country_name] es la segunda columna del archivo. La consulta omitirá todas las columnas del archivo excepto la segunda.
SELECT
COUNT(DISTINCT country_name) AS countries
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
--[country_code] VARCHAR (5),
[country_name] VARCHAR (100) 2
--[year] smallint,
--[population] bigint
) AS [r]
Consulta de archivos anexables
Los archivos CSV que se usan en la consulta no deben cambiarse mientras se ejecuta la consulta. En una consulta de ejecución larga, el grupo de SQL puede reintentar lecturas, leer partes de los archivos o incluso leer el archivo varias veces. Los cambios en el contenido del archivo provocarían resultados incorrectos. Por lo tanto, el grupo de SQL genera un error en la consulta si detecta que cambia la hora de modificación de algún archivo durante la ejecución de la consulta.
En algunos escenarios, es posible que desee leer los archivos que se anexan constantemente. Para evitar los errores de consulta debidos a archivos que se anexan constantemente, puede permitir que la función OPENROWSET omita las lecturas potencialmente incoherentes mediante el valor ROWSET_OPTIONS.
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2,
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}') as rows
La opción de lectura ALLOW_INCONSISTENT_READS deshabilitará la comprobación de la hora de modificación de los archivos durante el ciclo de vida de la consulta y leerá lo que esté disponible en el archivo. En los archivos anexables, el contenido existente no se actualiza y solo se agregan nuevas filas. Por lo tanto, se reduce la probabilidad de resultados incorrectos en comparación con los archivos actualizables. Esta opción podría permitirle leer los archivos anexados con frecuencia sin necesidad de administrar los errores. En la mayoría de los escenarios, el grupo de SQL simplemente ignorará algunas filas que se añaden a los archivos durante la ejecución de la consulta.
Contenido relacionado
En los artículos siguientes obtendrá información sobre: