Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo, se muestra cómo depurar una aplicación que usa C++ Accelerated Massive Parallelism (C++ AMP) para aprovechar las ventajas de la unidad de procesamiento gráfico (GPU). Usa un programa de reducción en paralelo que suma una gran matriz de enteros. En este tutorial se ilustran las siguientes tareas:
- Inicio del depurador de GPU.
- Inspección de los subprocesos de GPU en la ventana Subprocesos de GPU.
- Uso de la ventana Pilas paralelas para observar simultáneamente las pilas de llamadas de varios subprocesos de GPU.
- Uso de la ventana Inspección paralela para inspeccionar los valores de una sola expresión en varios subprocesos al mismo tiempo.
- Señalización, congelación, descongelación y agrupación de subprocesos de GPU.
- Ejecución de todos los subprocesos de un mosaico en una ubicación específica en el código.
Prerrequisitos
Antes de empezar este tutorial:
Nota:
Los encabezados de C++ AMP están en desuso a partir de la versión 17.0 de Visual Studio 2022.
Si se incluyen encabezados AMP, se generarán errores de compilación. Defina _SILENCE_AMP_DEPRECATION_WARNINGS antes de incluir encabezados AMP para silenciar las advertencias.
- Consulte Información general sobre C++ AMP.
- Asegúrese de que se muestren los números de línea en el editor de texto. Para obtener más información, consulte Procedimientos: Visualización de los números de línea en el editor.
- Asegúrese de estar ejecutando al menos Windows 8 o Windows Server 2012 para apoyar la depuración en el emulador de software.
Nota:
Es posible que tu equipo muestre nombres o ubicaciones diferentes para algunos de los elementos de la interfaz de usuario de Visual Studio en las siguientes instrucciones. La edición de Visual Studio que se tenga y la configuración que se utilice determinan estos elementos. Para obtener más información, vea Personalizar el IDE.
Para crear el proyecto de ejemplo
Las instrucciones para crear un proyecto varían en función de la versión de Visual Studio que utilice. Asegúrese de que tiene seleccionada la versión correcta de la documentación encima de la tabla de contenido de esta página.
Creación del proyecto de ejemplo en Visual Studio
En la barra de menús, seleccione Archivo>Nuevo>Proyecto para abrir el cuadro de diálogo Crear nuevo proyecto.
En la parte superior del cuadro de diálogo, establezca Lenguaje en C++, establezca Plataforma en Windows y Tipo de proyecto en Consola.
En la lista filtrada de tipos de proyecto, seleccione Aplicación de consola y luego elija Siguiente. En la siguiente página, escriba
AMPMapReduceen el cuadro Nombre con el fin de especificar un nombre para el proyecto y especifique la ubicación del proyecto si quiere otra diferente.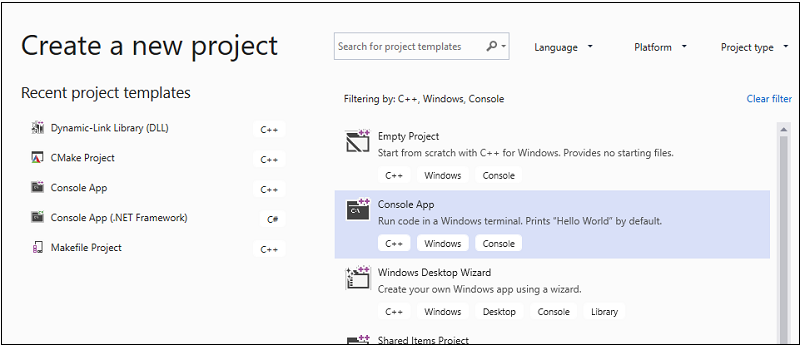
Haga clic en el botón Crear para crear el proyecto de cliente.
Siguiente:
Abra el archivo AMPMapReduce.cpp y reemplace el contenido por el código siguiente.
// AMPMapReduce.cpp defines the entry point for the program. // The program performs a parallel-sum reduction that computes the sum of an array of integers. #include <stdio.h> #include <tchar.h> #include <amp.h> const int BLOCK_DIM = 32; using namespace concurrency; void sum_kernel_tiled(tiled_index<BLOCK_DIM> t_idx, array<int, 1> &A, int stride_size) restrict(amp) { tile_static int localA[BLOCK_DIM]; index<1> globalIdx = t_idx.global * stride_size; index<1> localIdx = t_idx.local; localA[localIdx[0]] = A[globalIdx]; t_idx.barrier.wait(); // Aggregate all elements in one tile into the first element. for (int i = BLOCK_DIM / 2; i > 0; i /= 2) { if (localIdx[0] < i) { localA[localIdx[0]] += localA[localIdx[0] + i]; } t_idx.barrier.wait(); } if (localIdx[0] == 0) { A[globalIdx] = localA[0]; } } int size_after_padding(int n) { // The extent might have to be slightly bigger than num_stride to // be evenly divisible by BLOCK_DIM. You can do this by padding with zeros. // The calculation to do this is BLOCK_DIM * ceil(n / BLOCK_DIM) return ((n - 1) / BLOCK_DIM + 1) * BLOCK_DIM; } int reduction_sum_gpu_kernel(array<int, 1> input) { int len = input.extent[0]; //Tree-based reduction control that uses the CPU. for (int stride_size = 1; stride_size < len; stride_size *= BLOCK_DIM) { // Number of useful values in the array, given the current // stride size. int num_strides = len / stride_size; extent<1> e(size_after_padding(num_strides)); // The sum kernel that uses the GPU. parallel_for_each(extent<1>(e).tile<BLOCK_DIM>(), [&input, stride_size] (tiled_index<BLOCK_DIM> idx) restrict(amp) { sum_kernel_tiled(idx, input, stride_size); }); } array_view<int, 1> output = input.section(extent<1>(1)); return output[0]; } int cpu_sum(const std::vector<int> &arr) { int sum = 0; for (size_t i = 0; i < arr.size(); i++) { sum += arr[i]; } return sum; } std::vector<int> rand_vector(unsigned int size) { srand(2011); std::vector<int> vec(size); for (size_t i = 0; i < size; i++) { vec[i] = rand(); } return vec; } array<int, 1> vector_to_array(const std::vector<int> &vec) { array<int, 1> arr(vec.size()); copy(vec.begin(), vec.end(), arr); return arr; } int _tmain(int argc, _TCHAR* argv[]) { std::vector<int> vec = rand_vector(10000); array<int, 1> arr = vector_to_array(vec); int expected = cpu_sum(vec); int actual = reduction_sum_gpu_kernel(arr); bool passed = (expected == actual); if (!passed) { printf("Actual (GPU): %d, Expected (CPU): %d", actual, expected); } printf("sum: %s\n", passed ? "Passed!" : "Failed!"); getchar(); return 0; }En la barra de menús, pulse Archivo>Guardar todo.
En el Explorador de soluciones, abra el menú contextual de AMPMapReduce y, a continuación, elija Propiedades.
En el cuadro de diálogo Páginas de propiedades, en Propiedades de configuración, elija C/C++>Encabezados precompilados.
Para la propiedad Encabezado precompilado, seleccione No usar encabezados precompilados y, a continuación, elija el botón Aceptar.
En la barra de menús, elija Compilar>Compilar solución.
Depuración del código de CPU
En este procedimiento, usará el depurador local de Windows para asegurarse de que el código de CPU de esta aplicación sea correcto. El segmento del código de CPU de esta aplicación que es especialmente interesante es el bucle for de la función reduction_sum_gpu_kernel. Controla la reducción en paralelo basada en árbol que se ejecuta en la GPU.
Para depurar el código de la CPU
En el Explorador de soluciones, abra el menú contextual de AMPMapReduce y, a continuación, elija Propiedades.
En el cuadro de diálogo Páginas de propiedades, en Propiedades de configuración, elija Depuración. Compruebe que el Depurador local de Windows esté seleccionado en la lista Depurador para iniciar.
Vuelva al Editor de código.
Establezca puntos de interrupción en las líneas de código que se muestran en la ilustración siguiente (aproximadamente las líneas 67 y 70).

Puntos de interrupción de CPUEn la barra de menús, seleccione Depurar>Iniciar depuración.
En la ventana Variables locales, observe el valor de
stride_sizehasta que se alcanza el punto de interrupción en la línea 70.En la barra de menús, seleccione Depurar>Detener depuración.
Depuración del código de GPU
En esta sección, se muestra cómo depurar el código de GPU, que es el código contenido en la función sum_kernel_tiled. El código de GPU calcula la suma de enteros para cada "bloque" en paralelo.
Para depurar el código de GPU
En el Explorador de soluciones, abra el menú contextual de AMPMapReduce y, a continuación, elija Propiedades.
En el cuadro de diálogo Páginas de propiedades, en Propiedades de configuración, elija Depuración.
En la lista Depurador para iniciar, seleccione Depurador local de Windows.
En la lista Tipo de depurador, compruebe que esté seleccionada la opción Automático.
Automático es el valor predeterminado. En las versiones anteriores a Windows 10, Solo GPU es el valor necesario en lugar de Automático.
Elija el botón Aceptar .
Establezca un punto de interrupción en la línea 30, como se muestra en la ilustración siguiente.

Punto de interrupción de GPUEn la barra de menús, seleccione Depurar>Iniciar depuración. Los puntos de interrupción del código de CPU en las líneas 67 y 70 no se ejecutan durante la depuración de GPU porque esas líneas de código se ejecutan en la CPU.
Para usar la ventana de Subprocesos de GPU
Para abrir la ventana Subprocesos de GPU, en la barra de menús, elija Depurar>Windows>Subprocesos de GPU.
Puede inspeccionar el estado de los subprocesos de GPU en la ventana Subprocesos de GPU que aparece.
Acople la ventana Subprocesos de GPU a la parte inferior de Visual Studio. Elija el botón Expand Thread Switch (Botón Expandir subproceso) para mostrar el mosaico y los cuadros de texto de subproceso. La ventana Subprocesos de GPU muestra el número total de subprocesos de GPU activos y bloqueados, como se muestra en la ilustración siguiente.

Ventana Subprocesos de GPUSe asignan 313 mosaicos para este cálculo. Cada mosaico contiene 32 hilos. Dado que la depuración local de GPU se produce en un emulador de software, hay cuatro subprocesos de GPU activos. Los cuatro subprocesos ejecutan las instrucciones simultáneamente y luego pasan juntos a la siguiente instrucción.
En la ventana Subprocesos de GPU, hay cuatro subprocesos de GPU activos y 28 subprocesos de GPU bloqueados en la instrucción tile_barrier::wait definida aproximadamente en la línea 21 (
t_idx.barrier.wait();). Todos los 32 subprocesos de GPU pertenecen al primer mosaico,tile[0]. Una flecha señala la fila que contiene el subproceso actual. Para cambiar a otro subproceso, use uno de los métodos siguientes:En la ventana Subprocesos de GPU, en la fila del subproceso al que desea cambiar, abra el menú contextual y elija Cambiar a subproceso. Si la fila representa más de un subproceso, cambie al primer subproceso de acuerdo con las coordenadas del subproceso.
Escriba los valores de mosaico y subproceso en los cuadros de texto correspondientes y, a continuación, seleccione el botón Cambiar subproceso.
La ventana Pila de llamadas muestra la pila de llamadas del subproceso de GPU actual.
Para utilizar la ventana Pilas paralelas
Para abrir la ventana Pilas paralelas, en la barra de menús, elija Depurar>Windows>Pilas paralelas.
Puede usar la ventana Pilas paralelas para inspeccionar simultáneamente los marcos de pila de varios subprocesos de GPU.
Acople la ventana Pilas paralelas a la parte inferior de Visual Studio.
Asegúrese de que esté seleccionado Subprocesos en la lista de la esquina superior izquierda. En la ilustración siguiente, la ventana Pilas paralelas muestra una vista de la pila de llamadas centrada en los subprocesos de GPU que observó en la ventana Subprocesos de GPU.

Ventana Marcos paralelos32 subprocesos pasaron de
_kernel_stuba la instrucción lambda en la llamada de funciónparallel_for_eachy, a continuación, a la funciónsum_kernel_tiled, donde se produce la reducción en paralelo. 28 de los 32 subprocesos han progresado a la instruccióntile_barrier::waity permanecen bloqueados en la línea 22, mientras que los otros cuatro subprocesos permanecen activos en la funciónsum_kernel_tileden la línea 30.Puede inspeccionar las propiedades de un subproceso de GPU. Están disponibles en la ventana Subprocesos de GPU en el DataTip enriquecido de la ventana Pilas paralelas. Para verlas, mantenga el puntero sobre el marco de pila de
sum_kernel_tiled. La siguiente ilustración muestra el DataTip.
Información sobre datos de subprocesos de GPUPara más información sobre la ventana Pilas paralelas, consulte Uso de la ventana Pilas paralelas.
Para usar la ventana Observación paralela
Para abrir la ventana Inspección paralela, en la barra de menús, elija Depurar>Windows>Inspección paralela>Inspección paralela 1.
Puede usar la ventana Inspección paralela para inspeccionar los valores de una expresión en varios subprocesos.
Acople la ventana Inspección paralela 1 a la parte inferior de Visual Studio. Hay 32 filas en la tabla de la ventana Parallel Watch. Cada una corresponde a un subproceso de GPU que aparecía en la ventana Subprocesos de GPU y en la ventana Pilas paralelas. Ahora, puede escribir las expresiones cuyos valores quiera inspeccionar en todos los 32 subprocesos de GPU.
Seleccione el encabezado de columna Añadir observación, escriba
localIdxy, a continuación, elija la tecla Intro.Seleccione de nuevo el encabezado de columna Agregar Vigilancia, escriba
globalIdxy, a continuación, presione la tecla Intro.Seleccione de nuevo el encabezado de columna Agregar Vigilancia, escriba
localA[localIdx[0]]y, a continuación, presione la tecla Intro.Para ordenar por una expresión especificada, seleccione su encabezado de columna correspondiente.
Seleccione el encabezado de columna localA[localIdx[0]] para ordenar la columna. En la ilustración siguiente, se muestran los resultados de la ordenación por localA[localIdx[0]].

Resultados de la clasificaciónPara exportar el contenido en la ventana Inspección paralela a Excel, elija el botón Excel y, a continuación, elija Abrir en Excel. Si tiene Excel instalado en el equipo de desarrollo, el botón abre una hoja de cálculo de Excel que tiene el contenido.
En la esquina superior derecha de la ventana Inspección paralela, hay un control de filtro que puede usar para filtrar el contenido mediante expresiones booleanas. Escriba
localA[localIdx[0]] > 20000en el cuadro de texto del control de filtro y, a continuación, elija la tecla Entrar.La ventana ahora solo contiene subprocesos en los que el valor de
localA[localIdx[0]]es mayor que 20 000. El contenido sigue ordenado por la columnalocalA[localIdx[0]], que es la acción de ordenación que eligió anteriormente.
Marcado de hilos de GPU
Puede marcar subprocesos de GPU específicos en la ventana Subprocesos de GPU, la ventana Inspección paralela y la información sobre datos de la ventana Pilas paralelas. Si una fila de la ventana Subprocesos de GPU contiene más de un subproceso, marcar esa fila marcará todos los subprocesos contenidos en la fila.
Marcar subprocesos de GPU
Seleccione el encabezado de columna [Hilo] en la ventana Inspección paralela 1 para ordenar por índice de mosaico e índice de hilo.
En la barra de menús, elija Depurar>Continuar, lo que hace que los cuatro subprocesos activos avancen a la siguiente barrera (definida en la línea 32 del archivo AMPMapReduce.cpp).
Elija el símbolo de marca en el lado izquierdo de la fila que contiene los cuatro subprocesos que están activos ahora.
En la ilustración siguiente, se muestran los cuatro subprocesos activos marcados en la ventana Subprocesos de GPU.

Subprocesos activos en la ventana Subprocesos de GPULa ventana Inspección paralela y el DataTip de la ventana Pilas paralelas indican los hilos marcados.
Si quiere centrarse en los cuatro subprocesos que ha marcado, puede elegir mostrar solo los subprocesos marcados. Esto limita lo que aparece en las ventanas Subprocesos de GPU, Inspección paralela y Pilas paralelas.
Elija el botón Mostrar solo marcado en cualquiera de las ventanas o en la barra de herramientas Ubicación de depuración. En la ilustración siguiente, se muestra el botón Mostrar solo los marcados en la barra de herramientas Ubicación de depuración.

Botón Mostrar solo elementos marcadosAhora, las ventanas Subprocesos de GPU, Inspección paralela y Pilas paralelas solo muestran los subprocesos marcados.
Congelación y descongelación de subprocesos de GPU
Puede inmovilizar (suspender) y reanudar los subprocesos de GPU desde la ventana Subprocesos de GPU o la ventana Inspección paralela. Puede congelar y descongelar los hilos de la CPU del mismo modo; para obtener información, consulte Cómo utilizar la ventana de subprocesos.
Congelar y descongelar subprocesos de GPU
Elija el botón Mostrar solo los marcados para ver todas las conversaciones.
En la barra de menús, elija Depurar>Continuar.
Abra el menú contextual de la fila activa y, a continuación, elija Inmovilizar.
En la siguiente ilustración de la ventana Subprocesos de GPU, se muestra que los cuatro subprocesos están inmovilizados.

Subprocesos inmovilizados en la ventana Subprocesos de GPUDel mismo modo, la ventana Inspección paralela muestra que los cuatro subprocesos están congelados.
En la barra de menús, elija Depurar>Continuar para permitir que los cuatro subprocesos de GPU siguientes avancen más allá de la barrera de la línea 22 y alcancen el punto de interrupción de la línea 30. La ventana Subprocesos de GPU muestra que los cuatro subprocesos inmovilizados anteriormente permanecen inmovilizados y en estado activo.
En la barra de menús, elija Depurar y Continuar.
En la ventana Inspección paralela, también puede reanudar subprocesos individuales o varios subprocesos de GPU.
Agrupar subprocesos de GPU
En el menú contextual de uno de los subprocesos de la ventana Subprocesos de GPU, elija Agrupar por, Dirección.
Los subprocesos de la ventana Subprocesos de GPU se agrupan por dirección. La dirección corresponde a la instrucción en el desensamblaje de instrucciones donde se encuentra cada grupo de subprocesos. 24 hilos están en la línea 22, donde se ejecuta el método tile_barrier::wait. 12 subprocesos están en la instrucción para la barrera en la línea 32. Cuatro de estos subprocesos están marcados. Ocho subprocesos están en el punto de interrupción en la línea 30. Cuatro de estos subprocesos están congelados. En la ilustración siguiente, se muestran los subprocesos agrupados en la ventana Subprocesos de GPU.

Subprocesos agrupados en la ventana Subprocesos de GPUTambién puede realizar la operación Agrupar por abriendo el menú contextual de la cuadrícula de datos de la ventana Inspección paralela. Seleccione Agrupar por y, a continuación, elija el elemento de menú correspondiente a cómo desea agrupar los subprocesos.
Ejecución de todos los subprocesos en una ubicación específica en el código
Ejecute todos los subprocesos de un mosaico determinado en la línea que contiene el cursor mediante Ejecutar Tile actual hasta el cursor.
Ejecutar todos los subprocesos hasta la posición marcada por el cursor
En el menú contextual de los subprocesos inmovilizados, elija Reanudar.
En el Editor de código, coloque el cursor en la línea 30.
En el menú contextual del Editor de código, elija Ejecutar Tile actual hasta el cursor.
Los 24 subprocesos que estaban bloqueados anteriormente en la barrera de sincronización de la línea 21 han progresado hasta la línea 32. Se muestra en la ventana Subprocesos de GPU.
Consulte también
Introducción a C++ AMP
Depuración de código de GPU
Uso de la ventana Subprocesos de GPU
Cómo usar la ventana de Inspección Paralela
Análisis de código de C++ AMP con el Concurrency Visualizer