Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Desplazamiento a la derecha es la práctica de mover algunas pruebas más adelante en el proceso de DevOps para probar en producción. Las pruebas en producción usan implementaciones reales para validar y medir el comportamiento y el rendimiento de una aplicación en el entorno de producción.
Una manera en que los equipos de DevOps pueden mejorar la velocidad es con una estrategia de prueba de desplazamiento a la izquierda . El desplazamiento hacia la izquierda inserta la mayoría de las pruebas anteriormente en la canalización de DevOps, para reducir la cantidad de tiempo para que el código nuevo llegue a producción y funcione de forma confiable.
Pero aunque muchos tipos de pruebas, como las pruebas unitarias, pueden desplazarse fácilmente a la izquierda, algunas clases de pruebas no se pueden ejecutar sin implementar parte o toda una solución. La implementación en un servicio de control de calidad o almacenamiento provisional puede simular un entorno comparable, pero no hay ningún sustituto completo del entorno de producción. Los equipos encuentran que determinados tipos de pruebas deben producirse en producción.
Las pruebas en producción proporcionan:
- Amplitud y diversidad del entorno de producción.
- Carga de trabajo real del tráfico del cliente.
- Perfiles y comportamientos a medida que la demanda de producción evoluciona con el tiempo.
El entorno de producción sigue cambiando. Incluso si una aplicación no cambia, la infraestructura que se basa en los cambios constantemente. Las pruebas en producción validan el estado y la calidad de una implementación de producción determinada y del entorno de producción que cambia constantemente.
El cambio de derecha a prueba en producción es especialmente importante para los escenarios siguientes:
Implementaciones de microservicios
Las soluciones basadas en microservicios pueden tener un gran número de microservicios desarrollados, implementados y administrados de forma independiente. El cambio de las pruebas a la derecha es especialmente importante para estos proyectos, ya que diferentes versiones y configuraciones pueden llegar a producción de muchas maneras. Independientemente de la cobertura de pruebas de preproducción, es necesario probar la compatibilidad en producción.
Garantizar la calidad posterior a la implementación
La publicación en producción es solo la mitad de la entrega de software. La otra mitad garantiza la calidad a escala con una carga de trabajo real en producción. Dado que el entorno sigue cambiando, un equipo nunca se realiza con las pruebas en producción.
Los datos de prueba de producción son literalmente los resultados de la prueba de la carga de trabajo del cliente real. Las pruebas en producción incluyen la supervisión, las pruebas de conmutación por error y la inyección de errores. Esta prueba realiza un seguimiento de errores, excepciones, métricas de rendimiento y eventos de seguridad. La telemetría de prueba también ayuda a detectar anomalías.
Niveles de implementación
Para proteger el entorno de producción, los equipos pueden implementar cambios de forma progresiva y controlada mediante implementaciones basadas en niveles y marcas de características. Por ejemplo, es mejor detectar un error que impida que un comprador complete su compra cuando menos de 1% de clientes se encuentran en ese nivel de implementación, que después de cambiar a todos los clientes a la vez. El valor de la característica con errores detectados debe superar las pérdidas netas de esos errores, medida de forma significativa para la empresa determinada.
El primer nivel debe ser el tamaño más pequeño necesario para ejecutar el conjunto de integración estándar. Las pruebas pueden ser similares a las que ya se ejecutan anteriormente en la canalización en otros entornos, pero las pruebas validan que el comportamiento es el mismo en el entorno de producción. Este nivel identifica errores obvios, como configuraciones incorrectas, antes de que afecten a los clientes.
Una vez validado el nivel inicial, el siguiente nivel puede ampliarse para incluir un subconjunto de usuarios reales para la ejecución de pruebas. Si todo se ve bien, la implementación puede avanzar a través de niveles y pruebas adicionales hasta que todos los usuarios lo usen. La implementación completa no significa que se supere la prueba. El seguimiento de la telemetría es fundamental para las pruebas en producción.
Inyección de errores
Los equipos suelen emplear la inserción de errores y la ingeniería de caos para ver cómo se comporta un sistema en condiciones de error. Estos procedimientos ayudan a:
- Valide que los mecanismos de resistencia implementados funcionen realmente.
- Compruebe que un error de un subsistema está incluido en ese subsistema y no se aplica en cascada para producir una interrupción importante.
- Demuestre que el trabajo de reparación de un incidente anterior tiene el efecto deseado, sin tener que esperar a que se produzca otro incidente.
- Cree simulacros de entrenamiento más realistas para los ingenieros de sitio en directo para que puedan prepararse mejor para tratar los incidentes.
Se recomienda automatizar experimentos de inyección de errores, ya que son pruebas costosas que deben ejecutarse en sistemas que cambian constantemente.
La ingeniería de caos puede ser una herramienta eficaz, pero debe limitarse a entornos controlados que tienen poco o ningún impacto en el cliente.
Pruebas de conmutación por error
Una forma de inyección de errores es la prueba de conmutación por error para admitir la continuidad empresarial y la recuperación ante desastres (BCDR). Teams debe tener planes de conmutación por error para todos los servicios y subsistemas. Los planes deben incluir:
- Una explicación clara del impacto empresarial del servicio.
- Mapa de todas las dependencias en términos de plataforma, tecnología y personas que describen los planes bcDR.
- Documentación formal de los procedimientos de recuperación ante desastres.
- Cadencia para ejecutar periódicamente simulacros de recuperación ante desastres.
Pruebas de errores del disyuntor
Un mecanismo de disyuntor corta un componente determinado de un sistema más grande, normalmente para evitar que los errores de ese componente se extiendan fuera de sus límites. Puede desencadenar intencionadamente disyuntores para probar los escenarios siguientes:
Si una reserva funciona cuando se abre el disyuntor. La reserva podría funcionar con pruebas unitarias, pero la única manera de saber si se comportará según lo previsto en producción es insertar un error para desencadenarlo.
Si el disyuntor tiene el umbral de sensibilidad adecuado para abrirse cuando sea necesario. La inserción de errores puede forzar la latencia o desconectar las dependencias para observar la capacidad de respuesta del separador. Es importante comprobar no solo que se produzca el comportamiento correcto, sino que esto sucede lo suficientemente rápido.
Ejemplo: Prueba de un disyuntor de caché de Redis
Redis Cache mejora el rendimiento del producto al acelerar el acceso a los datos usados habitualmente. Considere un escenario que tome una dependencia no crítica en Redis. Si Redis deja de funcionar, el sistema debe seguir funcionando, ya que puede revertir al uso del origen de datos original para las solicitudes. Para confirmar que un error de Redis desencadena un disyuntor y que la reserva funciona en producción, ejecute periódicamente pruebas con estos comportamientos.
En el diagrama siguiente se muestran las pruebas para el comportamiento de reserva del disyuntor de Redis. El objetivo es asegurarse de que cuando se abra el separador, las llamadas en última instancia van a SQL.
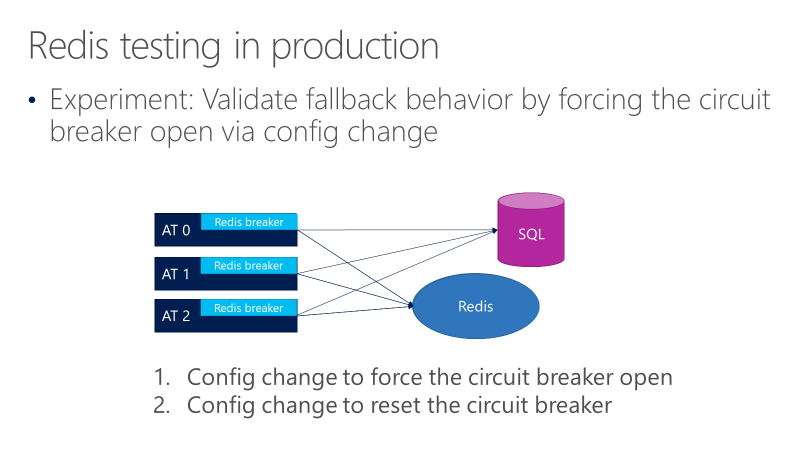
En el diagrama anterior se muestran tres AT, con los separadores delante de las llamadas a Redis. Una prueba obliga al disyuntor a abrirse a través de un cambio de configuración y, a continuación, observa si las llamadas van a SQL. A continuación, otra prueba comprueba el cambio de configuración opuesto, cerrando el disyuntor para confirmar que las llamadas vuelven a Redis.
Esta prueba valida que el comportamiento de reserva funciona cuando se abre el separador, pero no valida que la configuración del disyuntor abra el separador cuando debería. La prueba de ese comportamiento requiere simular errores reales.
Un agente de error puede introducir errores en las llamadas que van a Redis. En el diagrama siguiente se muestran las pruebas con inyección de errores.
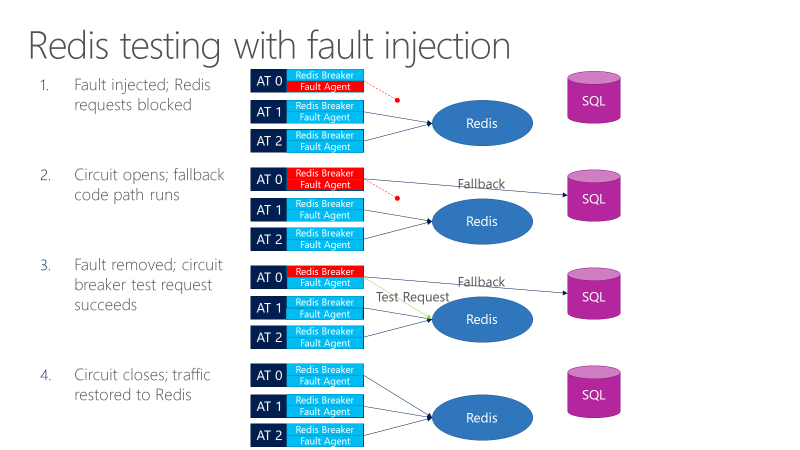
- El inyector de errores bloquea las solicitudes de Redis.
- Se abre el disyuntor y la prueba puede observar si funciona la reserva.
- El error se quita y el disyuntor envía una solicitud de prueba a Redis.
- Si la solicitud se realiza correctamente, las llamadas vuelven a Redis.
Otros pasos podrían probar la sensibilidad del separador, si el umbral es demasiado alto o demasiado bajo, y si otros tiempos de espera del sistema interfieren con el comportamiento del disyuntor.
En este ejemplo, si el separador no se abre o se cierra según lo previsto, podría provocar un incidente de sitio activo (LSI). Sin las pruebas de inyección de errores, es posible que el problema no se detecte, ya que es difícil realizar este tipo de pruebas en un entorno de laboratorio.
Pasos siguientes
- [Desplazamiento de las pruebas a la izquierda con pruebas unitarias]mayús-left
- ¿Qué son los microservicios?
- Ejecución de una conmutación por error de prueba (simulacro de recuperación ante desastres) en Azure
- Procedimientos de implementación seguros
- ¿Qué es la supervisión?
- ¿Qué es la ingeniería de plataformas?