Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Las pruebas ayudan a garantizar que el código funcione según lo esperado, pero el tiempo y el esfuerzo para crear pruebas quitan tiempo de otras tareas, como el desarrollo de funciones. Con este costo, es importante extraer el valor máximo de las pruebas. En este artículo se describen los principios de prueba de DevOps, centrándose en el valor de las pruebas unitarias y en una estrategia de pruebas 'shift-left'.
Los evaluadores dedicados solían escribir la mayoría de las pruebas y muchos desarrolladores de productos no aprendieron a escribir pruebas unitarias. Escribir pruebas puede parecer demasiado difícil o como demasiado trabajo. Puede haber dudas sobre si una estrategia de prueba unitaria funciona, malas experiencias con pruebas unitarias mal escritas o miedo a que las pruebas unitarias reemplacen las pruebas funcionales.

Para implementar una estrategia de prueba de DevOps, sea pragmática y céntrese en la creación de impulso. Aunque puede insistir en pruebas unitarias para código nuevo o código existente que se puede refactorizar de forma limpia, podría tener sentido que un código base heredado permita alguna dependencia. Si partes significativas del código del producto usan SQL, permitir que las pruebas unitarias dependan del proveedor de recursos SQL en lugar de simular esa capa podría ser un enfoque temporal para avanzar.
A medida que las organizaciones de DevOps maduran, resulta más fácil para el liderazgo mejorar los procesos. Aunque puede haber cierta resistencia al cambio, las organizaciones ágiles valoran los cambios que pagan claramente dividendos. Debe ser fácil vender la visión de las ejecuciones de pruebas más rápidas con menos errores, ya que significa más tiempo para invertir en el desarrollo de nuevas funciones y así generar nuevo valor.
Taxonomía de pruebas de DevOps
Definir una taxonomía de prueba es un aspecto importante del proceso de prueba de DevOps. Una taxonomía de prueba de DevOps clasifica las pruebas individuales por sus dependencias y el tiempo que tardan en ejecutarse. Los desarrolladores deben comprender los tipos adecuados de pruebas que se van a usar en diferentes escenarios y qué pruebas requieren diferentes partes del proceso. La mayoría de las organizaciones clasifican las pruebas en cuatro niveles:
- Las pruebas L0 y L1 son pruebas unitarias o pruebas que dependen del código del ensamblado bajo prueba y nada más. L0 es una amplia clase de pruebas unitarias rápidas y en memoria.
- L2 son pruebas funcionales que podrían requerir el ensamblado más otras dependencias, como SQL o el sistema de archivos.
- Las pruebas funcionales L3 se ejecutan en implementaciones de servicio que se pueden probar. Esta categoría de prueba requiere una implementación de servicio, pero podría utilizar stubs para las dependencias de servicio clave.
- Las pruebas L4 son una clase restringida de pruebas de integración que se ejecutan en producción. Las pruebas L4 requieren una implementación completa del producto.
Aunque sería ideal para que todas las pruebas se ejecuten en todo momento, no es factible. Teams puede seleccionar dónde se encuentra el proceso de DevOps para ejecutar cada prueba y usar estrategias de desplazamiento a la izquierda o de desplazamiento a la derecha para mover diferentes tipos de prueba anteriormente o posteriores en el proceso.
Por ejemplo, la expectativa podría ser que los desarrolladores siempre ejecuten pruebas L2 antes de hacer commit, una pull request falla automáticamente si falla la ejecución de pruebas L3, y la implementación podría bloquearse si fallan las pruebas L4. Las reglas específicas pueden variar de la organización a la organización, pero aplicar las expectativas de todos los equipos de una organización mueve a todos los usuarios hacia los mismos objetivos de visión de calidad.
Directrices de pruebas unitarias
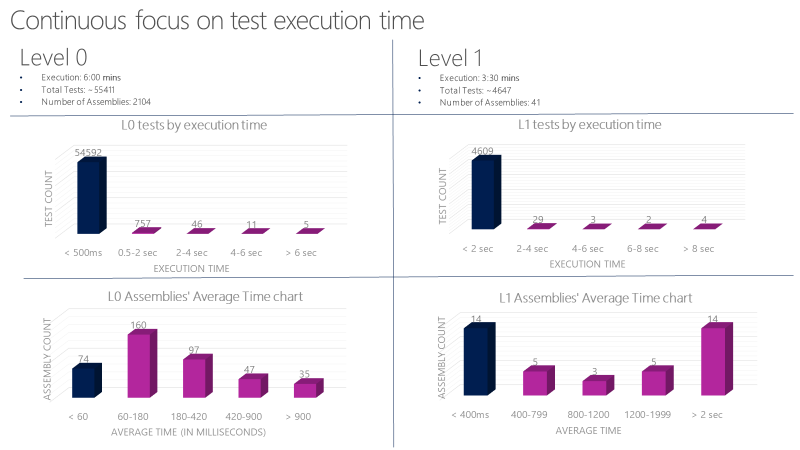
Establezca directrices estrictas para las pruebas unitarias L0 y L1. Estas pruebas deben ser muy rápidas y confiables. Por ejemplo, el tiempo medio de ejecución por prueba L0 en un ensamblado debe ser inferior a 60 milisegundos. El tiempo medio de ejecución por prueba L1 en un ensamblado debe ser inferior a 400 milisegundos. Ninguna prueba en este nivel debe superar los 2 segundos.
Un equipo de Microsoft ejecuta más de 60 000 pruebas unitarias en paralelo en menos de seis minutos. Su objetivo es reducir este tiempo a menos de un minuto. El equipo realiza un seguimiento del tiempo de ejecución de pruebas unitarias con herramientas como el siguiente gráfico, y reporta errores en las pruebas que superan el tiempo permitido.
Directrices de pruebas funcionales
Las pruebas funcionales deben ser independientes. El concepto clave de las pruebas L2 es el aislamiento. Las pruebas aisladas correctamente se pueden ejecutar de forma confiable en cualquier secuencia, ya que tienen control completo sobre el entorno en el que se ejecutan. El estado debe conocerse al principio de la prueba. Si una prueba creó datos y la dejó en la base de datos, podría dañar la ejecución de otra prueba que se basa en un estado de base de datos diferente.
Las pruebas heredadas que necesitan una identidad de usuario podrían haber llamado a los proveedores de autenticación externos para obtener la identidad. Esta práctica presenta varios desafíos. La dependencia externa podría no ser confiable o no disponible momentáneamente, lo que podría interrumpir la prueba. Esta práctica también infringe el principio de aislamiento de prueba, ya que una prueba podría cambiar el estado de una identidad, como el permiso, lo que da lugar a un estado predeterminado inesperado para otras pruebas. Para evitar estos problemas, considere invertir en soporte de identidad dentro del marco de pruebas.
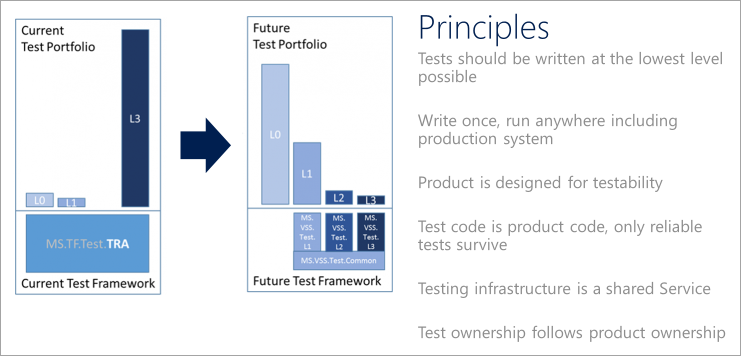
Principios de prueba de DevOps
Para ayudar a realizar la transición de una cartera de pruebas a procesos modernos de DevOps, articula una visión de calidad. Teams debe cumplir los siguientes principios de prueba al definir e implementar una estrategia de pruebas de DevOps.
Anticipar pruebas para realizarlas más temprano
Las pruebas pueden tardar mucho tiempo en ejecutarse. A medida que los proyectos se escalan, los números de prueba y los tipos aumentan considerablemente. Cuando los conjuntos de pruebas crecen para tardar horas o días en completarse, pueden empujar más lejos hasta que se ejecuten en el último momento. Los beneficios en la calidad del código que se obtienen al realizar pruebas no se perciben hasta mucho tiempo después de que el código es confirmado.
Las pruebas de larga duración también pueden producir errores que consumen mucho tiempo para investigar. Los equipos pueden desarrollar una tolerancia a los fracasos, especialmente al principio de los sprints. Esta tolerancia debilita el valor de las pruebas como información sobre la calidad del código base. Las pruebas extensas de último momento también agregan una imprevisibilidad a las expectativas al final del sprint, ya que se debe saldar una cantidad indeterminada de deuda técnica para lograr que el código sea enviable.
El objetivo de desplazar las pruebas hacia la izquierda es mejorar la calidad desde el inicio mediante la realización de tareas de prueba más temprano en el proceso. A través de una combinación de mejoras de pruebas y procesos, el desplazamiento a la izquierda reduce tanto el tiempo necesario para que las pruebas se ejecuten como el impacto de los errores más adelante en el ciclo. El desplazamiento a la izquierda garantiza que la mayoría de las pruebas se completan antes de que un cambio se combine en la rama principal.
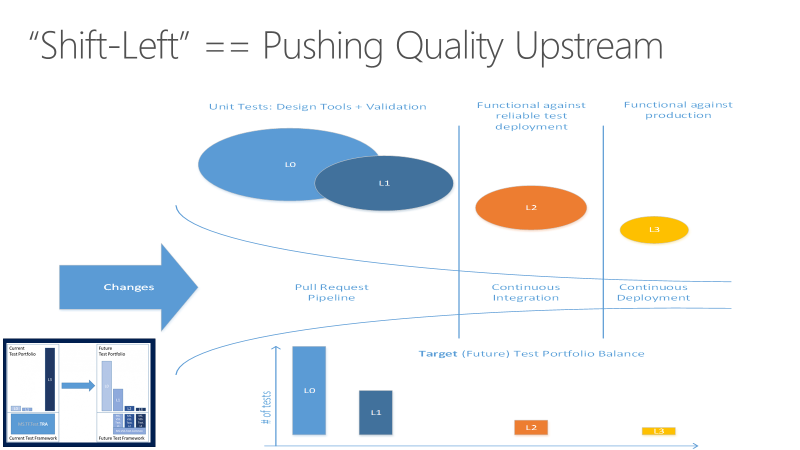
Además de trasladar ciertas responsabilidades de pruebas hacia el inicio para mejorar la calidad del código, los equipos pueden desplazar otros aspectos de las pruebas hacia el final del ciclo de DevOps para mejorar el producto final. Para obtener más información, consulte La estrategia de pruebas 'shift right' en producción.
Escribir pruebas en el nivel más bajo posible
Escriba más pruebas unitarias. Favorece las pruebas con las dependencias externas más pocas y se centra en ejecutar la mayoría de las pruebas como parte de la compilación. Considere un sistema de compilación paralelo que pueda ejecutar pruebas unitarias para un ensamblaje tan pronto como estén disponibles el ensamblaje y las pruebas asociadas. No es factible probar todos los aspectos de un servicio en este nivel, pero el principio es usar pruebas unitarias más ligeras si pueden producir los mismos resultados que las pruebas funcionales más pesadas.
Objetivo de la confiabilidad de las pruebas
Una prueba poco confiable es costosa para la organización de mantener. Esta prueba funciona directamente con el objetivo de eficiencia de ingeniería haciendo que sea difícil realizar cambios con confianza. Los desarrolladores deben poder realizar cambios en cualquier lugar y obtener rápidamente la confianza de que no se ha roto nada. Mantener un estándar alto para la fiabilidad. Desaconseja el uso de pruebas de IU, ya que tienden a no ser confiables.
Escritura de pruebas funcionales que se pueden ejecutar en cualquier lugar
Las pruebas pueden usar puntos de integración especializados diseñados específicamente para habilitar las pruebas. Una razón para esta práctica es la falta de capacidad de prueba en el propio producto. Desafortunadamente, las pruebas como estas suelen depender de conocimientos internos y usar detalles de implementación que no importan desde una perspectiva de prueba funcional. Estas pruebas se limitan a entornos que tienen los secretos y la configuración necesarios para ejecutar las pruebas, que generalmente excluyen las implementaciones de producción. Las pruebas funcionales solo deben usar la API pública del producto.
Diseñar productos para pruebas
Las organizaciones en un proceso de DevOps en maduración tienen una visión completa de lo que significa ofrecer un producto de calidad en una cadencia en la nube. Cambiar el equilibrio fuertemente a favor de las pruebas unitarias sobre las pruebas funcionales requiere que los equipos realicen opciones de diseño e implementación que admitan la capacidad de prueba. Hay diferentes ideas sobre lo que constituye código bien diseñado y bien implementado para la capacidad de prueba, al igual que hay diferentes estilos de codificación. El principio es que el diseño de la capacidad de prueba debe convertirse en una parte principal de la discusión sobre el diseño y la calidad del código.
Tratar el código de prueba como código de producto
Al indicar explícitamente que el código de prueba es código de producto, queda claro que la calidad del código de prueba es tan importante para el envío como el del código del producto. Teams debe tratar el código de prueba de la misma manera que tratan el código del producto y aplicar el mismo nivel de atención al diseño e implementación de pruebas y marcos de pruebas. Este esfuerzo es similar a la administración de la configuración y la infraestructura como código. Para ser completa, una revisión de código debe tener en cuenta el código de prueba y mantenerlo en los mismos estándares de calidad que el código del producto.
Uso de la infraestructura de prueba compartida
Facilite el uso de la infraestructura de pruebas para generar señales de calidad confiables. Vea las pruebas como un servicio compartido para todo el equipo. Almacene el código de las pruebas unitarias junto con el código del producto y compílelo con el producto. Las pruebas que se ejecutan como parte del proceso de compilación también deben ejecutarse en herramientas de desarrollo como Azure DevOps. Si las pruebas se pueden ejecutar en todos los entornos desde el desarrollo local a través de producción, tienen la misma confiabilidad que el código del producto.
Hacer que los propietarios de código sean responsables de las pruebas
El código de prueba debe residir junto al código del producto en un repositorio. Para que el código se pruebe a nivel de un componente, delegue la responsabilidad de las pruebas a la persona que escribe el código del componente. No confíe en otros usuarios para probar el componente.
Caso práctico: Desplazamiento hacia la izquierda con pruebas unitarias
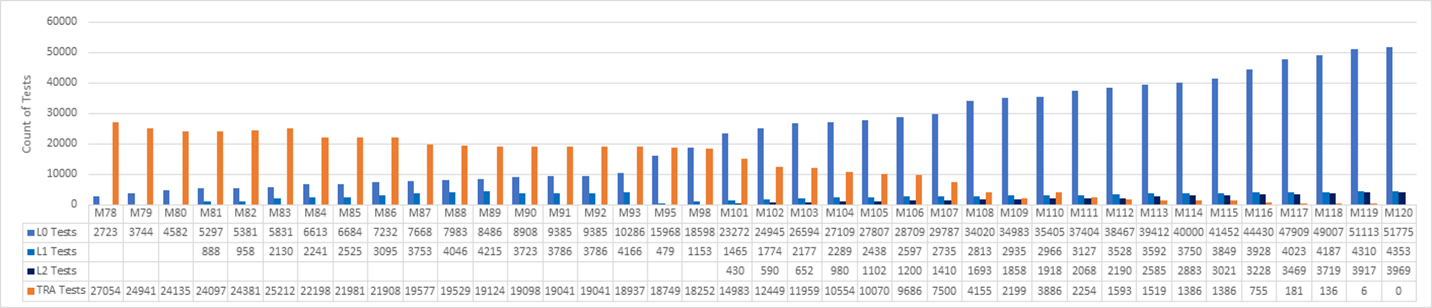
Un equipo de Microsoft decidió reemplazar sus conjuntos de pruebas heredadas por pruebas unitarias modernas dentro de DevOps y un proceso de cambio hacia la izquierda. El equipo ha realizado un seguimiento del progreso durante sprints cada tres semanas, como se muestra en el gráfico siguiente. El gráfico cubre los sprints 78-120, lo que representa 42 sprints a lo largo de 126 semanas, o aproximadamente dos años y medio de esfuerzo.
El equipo comenzó con 27K pruebas heredadas en la iteración 78 y alcanzó cero pruebas heredadas en la iteración 120. Un conjunto de pruebas unitarias L0 y L1 reemplazaron la mayoría de las pruebas funcionales antiguas. Las nuevas pruebas L2 reemplazaron algunas de las pruebas y muchas de las pruebas antiguas se eliminaron.
En un recorrido de software que tarda más de dos años en completarse, hay mucho que aprender del propio proceso. En general, el esfuerzo para rehacer completamente el sistema de pruebas a lo largo de dos años fue una inversión masiva. No todos los equipos de desarrollo trabajaron al mismo tiempo. Muchos equipos de toda la organización invirtieron tiempo en cada sprint y, en algunos sprints, fue la mayor parte de lo que el equipo hizo. Aunque es difícil medir el costo del cambio, era un requisito no negociable para los objetivos de calidad y rendimiento del equipo.
Cómo empezar
Al principio, el equipo dejó las pruebas funcionales antiguas, llamadas pruebas TRA, tal como estaban. El equipo quería que los desarrolladores compren la idea de escribir pruebas unitarias, especialmente para nuevas características. El objetivo era facilitar la creación de pruebas L0 y L1. El equipo necesitaba desarrollar esa capacidad en primer lugar y crear impulso.
En el gráfico anterior se muestra el recuento de pruebas unitarias que empiezan a aumentar al principio, ya que el equipo vio la ventaja de crear pruebas unitarias. Las pruebas unitarias eran más fáciles de mantener, más rápidas de ejecutar y tenían menos errores. Era fácil conseguir apoyo para ejecutar todas las pruebas unitarias dentro del flujo de pull request.
El equipo no se centró en escribir nuevas pruebas L2 hasta el sprint 101. Mientras tanto, el recuento de pruebas TRA descendió de 27,000 a 14,000 de Sprint 78 a Sprint 101. Las nuevas pruebas unitarias reemplazaron algunas de las pruebas TRA, pero muchas simplemente se eliminaron, según el análisis del equipo sobre su utilidad.
Las pruebas TRA saltaron de 2100 a 3800 en el sprint 110 porque se detectaron más pruebas en el árbol de origen y se agregaron al gráfico. Resultó que las pruebas siempre se habían estado ejecutando, pero no se hacía un seguimiento correcto. Esto no fue una crisis, pero era importante ser sinceros y revaluar cuando sea necesario.
Acelerando
Una vez que el equipo tenía una señal de integración continua (CI) que era extremadamente rápida y confiable, se convirtió en un indicador de confianza para la calidad del producto. En la captura de pantalla siguiente se muestra la solicitud de incorporación de cambios y el pipeline de CI en acción, así como el tiempo que tarda en completar las diversas fases.
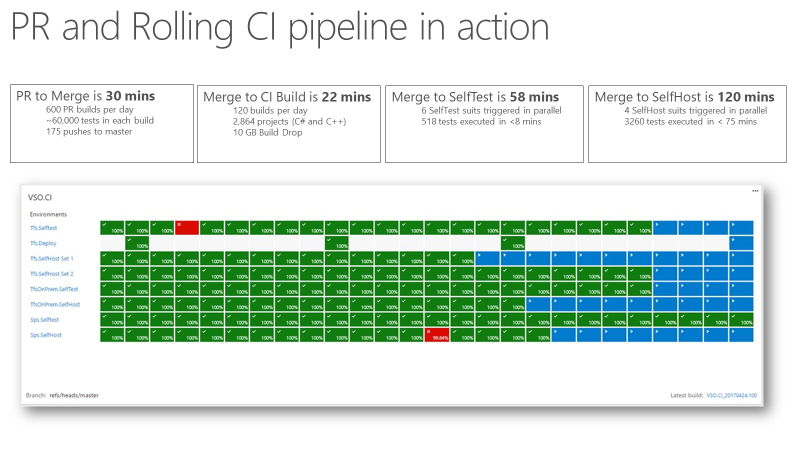
Un "pull request" tarda unos 30 minutos en fusionarse, lo que incluye ejecutar 60,000 pruebas unitarias. Desde la combinación de código hasta el proceso de integración continua (CI) pasan aproximadamente 22 minutos. La primera señal de calidad de CI, SelfTest, viene después de aproximadamente una hora. A continuación, la mayoría del producto se prueba con el cambio propuesto. En un plazo de dos horas desde Merge a SelfHost, se prueba todo el producto y el cambio está listo para entrar en producción.
Uso de métricas
El equipo realiza un seguimiento de una tarjeta de puntuación como en el siguiente ejemplo. A un nivel general, el cuadro de mandos realiza un seguimiento de dos tipos de métricas: salud financiera o deuda y velocidad.
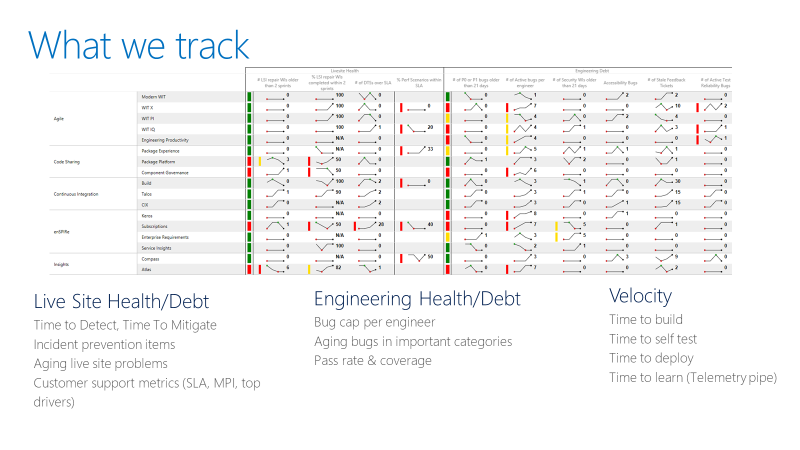
Para las métricas de salud del sitio en tiempo real, el equipo realiza un seguimiento del tiempo para detectar, el tiempo para mitigar y cuántos elementos de reparación maneja el equipo. Un elemento de reparación es el trabajo que el equipo identifica en una retrospectiva del sitio activo para evitar que se repitan incidentes similares. El cuadro de mandos también realiza un seguimiento de si los equipos cierran los elementos de reparación dentro de un período de tiempo razonable.
En el caso de las métricas de mantenimiento de ingeniería, el equipo realiza un seguimiento de los errores activos por desarrollador. Si un equipo tiene más de cinco errores por desarrollador, el equipo debe priorizar la corrección de esos errores antes del nuevo desarrollo de características. El equipo también realiza un seguimiento de los errores obsoletos en categorías especiales, como la seguridad.
Las métricas de velocidad de ingeniería miden la velocidad en diferentes partes de la canalización de integración continua y entrega continua (CI/CD). El objetivo general es aumentar la velocidad de la canalización de DevOps: comenzar con una idea, llevar el código a producción y recibir datos de los clientes de vuelta.