Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Sugerencia
Este contenido es un extracto del libro electrónico “Architecting Cloud Native .NET Applications for Azure” (Diseño de la arquitectura de aplicaciones .NET nativas en la nube para Azure), disponible en Documentos de .NET o como un PDF descargable y gratuito que se puede leer sin conexión.

Tras el cliente front-end, pasemos ahora a ver cómo se comunican los microservicios back-end entre sí.
Al crear una aplicación nativa de nube, nos interesa que sea consciente de cómo se comunican los servicios back-end entre sí. Lo ideal es que cuanta menos comunicación haya entre servicios, mejor. Sin embargo, no siempre es posible evitarlo, ya que los servicios back-end suelen depender los unos de otros para realizar operaciones.
Hay varios enfoques ampliamente aceptados para implementar la comunicación entre servicios. A menudo, el tipo de interacción de la comunicación será lo que determine cuál es el mejor enfoque.
Veamos los siguientes tipos de interacción:
Consulta: un microservicio que realiza una llamada requiere una respuesta del microservicio al que ha llamado (por ejemplo, "Oye, pásame la información de comprador de un identificador de cliente determinado").
Comando: un microservicio que realiza una llamada necesita que otro microservicio realice una acción, pero no requiere una respuesta (por ejemplo, "Oye, envía este pedido").
Evento: un microservicio (el publicador) genera un evento que indica que un estado ha cambiado o que se ha producido una acción. Otros microservicios (los suscriptores), que están interesados, pueden reaccionar al evento como corresponda. El publicador y los suscriptores no tienen conocimiento el uno de los otros.
Normalmente, los sistemas de microservicios usan una combinación de estos tipos de interacción al realizar operaciones que requieren la interacción entre servicios. Echemos un vistazo a cada uno de ellos y cómo implementarlos.
Consultas
Muchas veces, un microservicio podría necesitar consultar otro, lo que requiere una respuesta inmediata para completar una operación. Un microservicio de cesta de la compra puede necesitar información del producto y un precio para agregar un artículo a la cesta. Hay muchos enfoques para implementar operaciones de consulta.
Mensajería de solicitud-respuesta
Una opción para implementar este escenario es que el microservicio back-end que realiza la llamada realice solicitudes HTTP directas a los microservicios que necesita consultar (como se muestra en la figura 4-8).
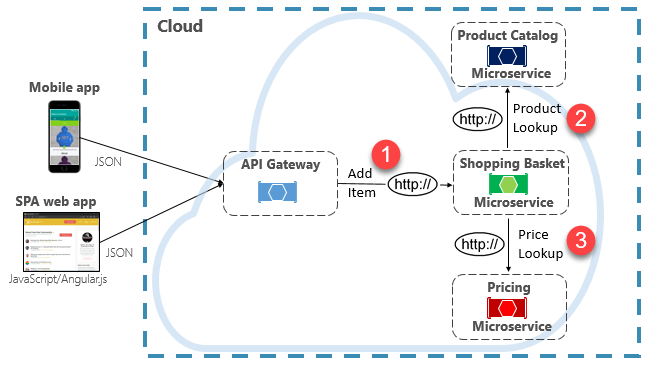
Figura 4-8. Comunicación HTTP directa
Aunque las llamadas HTTP directas entre microservicios son relativamente sencillas de implementar, conviene reducir esta práctica al mínimo. Para empezar, estas llamadas siempre son sincrónicas y bloquearán la operación hasta que se obtenga un resultado o se agote el tiempo de espera de la solicitud. Lo que antes eran servicios autocontenidos e independientes, capaces de evolucionar de forma independiente e implementar frecuentemente, ahora son servicios acoplados entre sí. A medida que aumenta el acoplamiento entre microservicios, sus ventajas arquitectónicas van disminuyendo.
La ejecución de una solicitud poco frecuente que realiza una única llamada HTTP directa a otro microservicio puede ser aceptable en algunos sistemas. Sin embargo, las llamadas de gran volumen que invocan llamadas HTTP directas a varios microservicios no son aconsejables. Pueden aumentar la latencia y afectar negativamente al rendimiento, la escalabilidad y la disponibilidad del sistema. Peor aún, una serie prolongada de comunicación HTTP directa puede desembocar en una concatenación profunda y compleja de llamadas a microservicios sincrónicos (como se muestra en la figura 4-9):
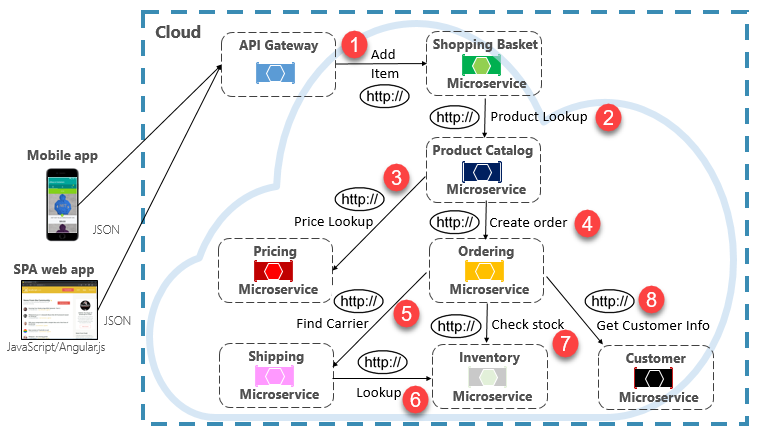
Figura 4-9. Concatenación de consultas HTTP
No resulta difícil imaginar el riesgo en el diseño que se trasluce en la imagen anterior. ¿Qué ocurre si se produce un error en el paso 3? ¿O en el paso 8? ¿Cómo nos recuperamos? ¿Qué ocurre si el paso 6 es lento porque el servicio subyacente está ocupado? ¿Cómo continuamos? Aun cuando todo funcione correctamente, pensemos en la latencia en que incurriría esta llamada, que sería la suma de la latencia de cada paso.
El enorme grado de acoplamiento de la imagen anterior sugiere que los servicios no se han modelado de forma óptima. Sería necesario que el equipo revisara su diseño.
Patrón Materialized View
Una opción popular para acabar con el acoplamiento de microservicios es el patrón de vista materializada. Con este patrón, un microservicio almacena su propia copia local y desnormalizada de los datos que pertenecen a otros servicios. En lugar de que el microservicio de cesta de la compra consulte los microservicios de catálogo de productos y precios, mantiene su propia copia local de esos datos. Este patrón elimina el acoplamiento innecesario y mejora el tiempo de confiabilidad y respuesta. Toda la operación se ejecuta dentro de un mismo proceso. Exploraremos este patrón y otras cuestiones relativas a los datos en el capítulo 5.
Patrón de agregador de servicio
Otra opción para acabar con el acoplamiento de microservicios es el microservicio de agregador, que se muestra de color púrpura en la figura 4-10.
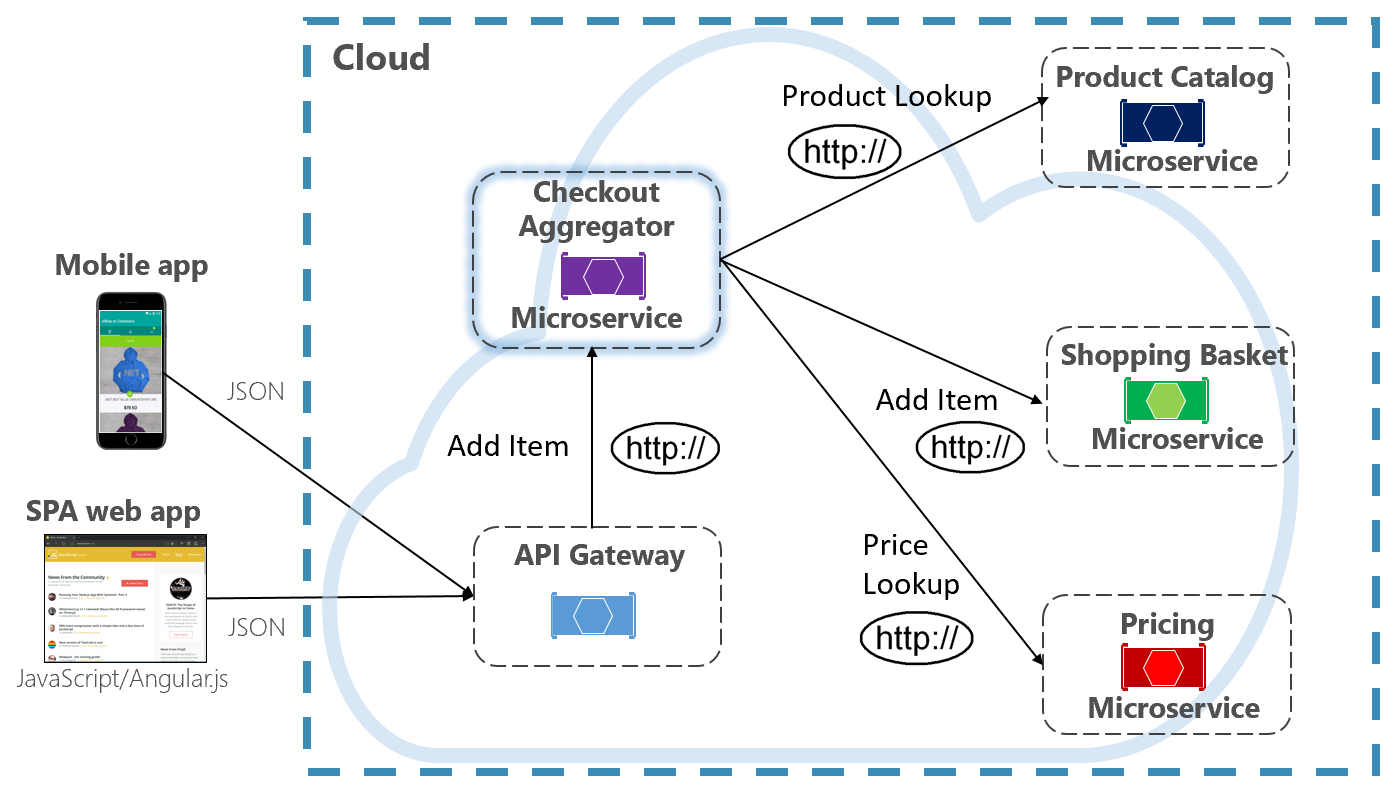
Figura 4-10. Microservicio de agregador
Este patrón aísla una operación que realiza llamadas a varios microservicios back-end, centralizando su lógica en un microservicio especializado. El microservicio de agregador de finalización de compra de la figura anterior (en color púrpura) organiza el flujo de trabajo para la operación de finalización de compra. Incluye llamadas a varios microservicios back-end en un orden secuenciado. Los datos del flujo de trabajo se agregan y se devuelven al autor de la llamada. Aunque sigue implementando llamadas HTTP directas, el microservicio de agregador reduce las dependencias directas entre los microservicios back-end.
Patrón de solicitud/respuesta
Otro enfoque para desacoplar mensajes HTTP sincrónicos es un patrón de solicitud/respuesta, que usa la comunicación de puesta en cola. La comunicación mediante una cola es siempre un canal unidireccional, con un productor que envía el mensaje y un consumidor que lo recibe. Con este patrón, se implementan una cola de solicitudes y una cola de respuestas (como se muestra en la figura 4-11).
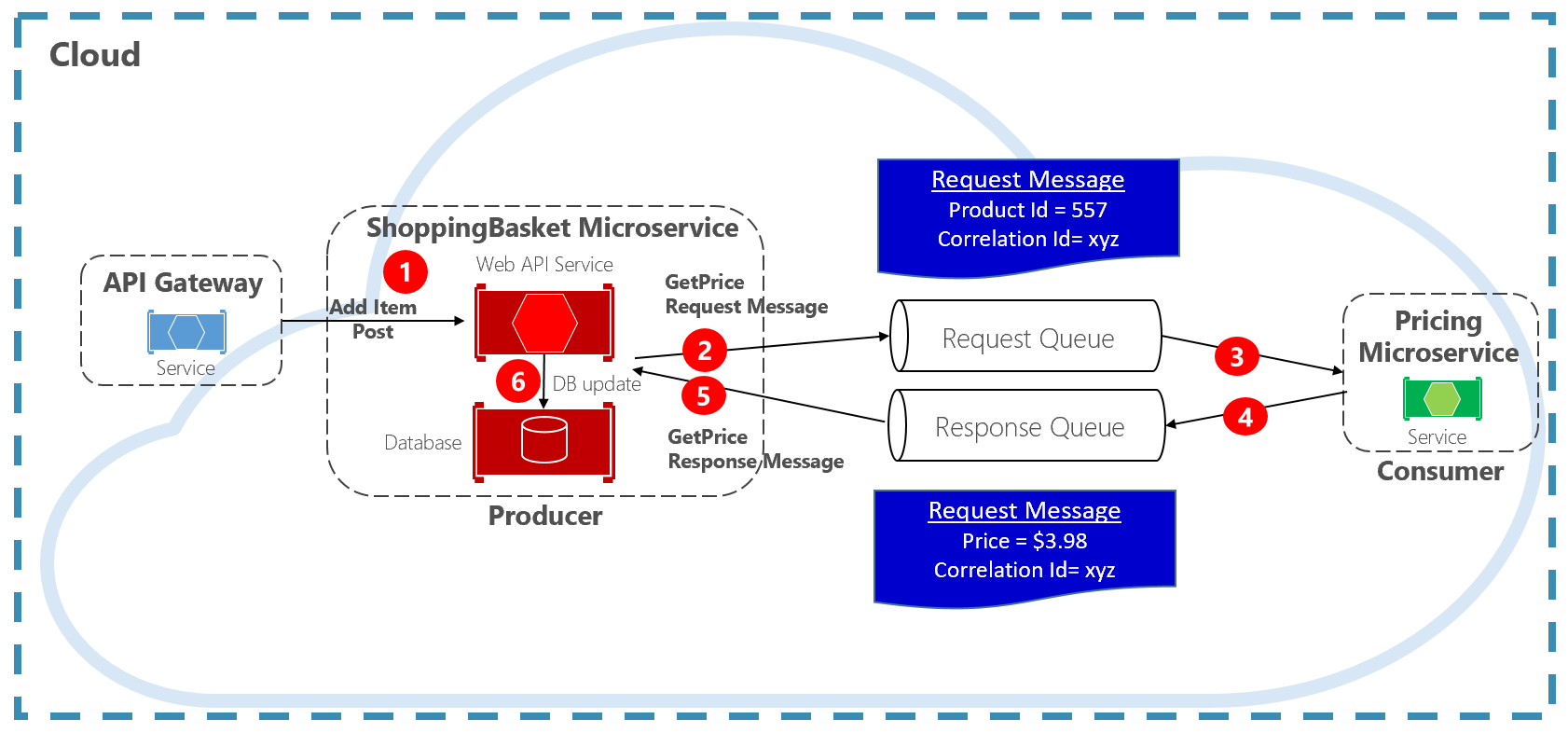
Figura 4-11. Patrón de solicitud/respuesta
Aquí, el productor del mensaje crea un mensaje basado en consultas que contiene un identificador de correlación único, y lo coloca en una cola de solicitudes. El servicio que consume quita el mensaje de la cola, lo procesa y coloca la respuesta en la cola de respuestas con el mismo identificador de correlación. El servicio productor quita el mensaje de la cola, lo coteja con el identificador de correlación y sigue procesando. Trataremos las colas en detalle en la sección siguiente.
Comandos
Otro tipo de interacción de comunicación es un comando. Un microservicio puede necesitar que otro microservicio realice una acción. El microservicio de pedidos puede necesitar que el microservicio de envíos cree el envío de un pedido aprobado. En la figura 4-12, un microservicio (el productor) envía un mensaje a otro microservicio (el consumidor), y le ordena que haga algo.
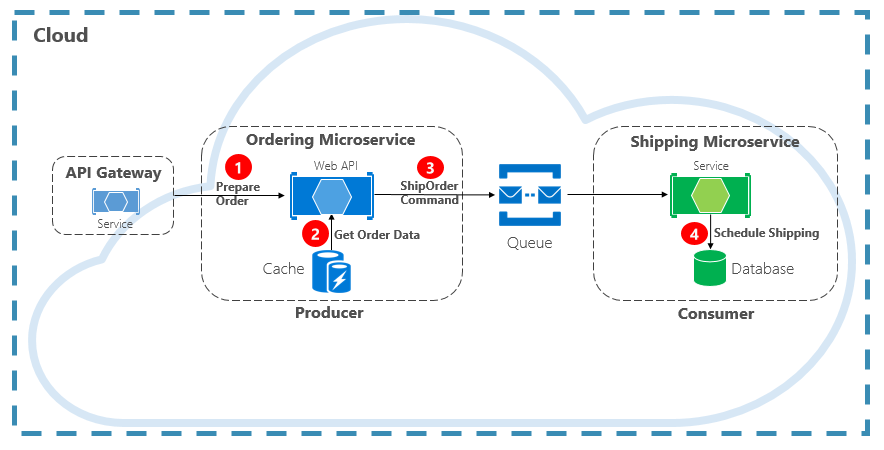
Figura 4-12. Interacción de comandos con una cola
La mayoría de las veces, el productor no requiere una respuesta y puede descartar el mensaje de manera autónoma. En caso de que sí se necesite una respuesta, el consumidor devuelve un mensaje independiente al productor en otro canal. La mejor forma de enviar un mensaje de comando es hacerlo de forma asincrónica con una cola de mensajes compatible con un agente de mensajes ligero. En el diagrama anterior, observe cómo una cola separa y desacopla ambos servicios.
Dado que muchas colas de mensajes pueden enviar el mismo mensaje más de una vez, conocida como entrega al menos una vez, el consumidor debe poder identificar y controlar estos escenarios correctamente mediante los patrones de procesamiento de mensajes idempotentes pertinentes.
Una cola de mensajes es una construcción intermedia a través de la cual un productor y consumidor pasan un mensaje. Las colas implementan un patrón de mensajería asincrónica de punto a punto. El productor sabe dónde se debe enviar un comando y lo enruta correctamente. La cola garantiza que un mensaje se procesa exactamente mediante una de las instancias de consumidor que leen el canal. En este escenario, tanto el servicio de productor como el de consumidor pueden escalar horizontalmente sin verse afectados entre sí. Además, las tecnologías pueden ser distintas en cada lado, lo que significa que podría haber un microservicio de Java que llame a un microservicio de Golang.
En el capítulo 1 vimos los servicios de respaldo. Los servicios de respaldo son recursos auxiliares de los que dependen los sistemas nativos de nube. Las colas de mensajes son servicios de respaldo. La nube de Azure admite dos tipos de colas de mensajes que los sistemas nativos de nube pueden consumir para implementar la mensajería de comandos: colas de Azure Storage y colas de Azure Service Bus.
Colas de Azure Storage
Las colas de Azure Storage ofrecen una infraestructura de colas sencilla que es rápida y asequible y que está respaldada por las cuentas de Azure Storage.
Las colas de Azure Storage incluyen un mecanismo de puesta en cola basado en REST con una mensajería confiable y persistente. Proporcionan un conjunto de características mínimo, pero son económicas y almacenan millones de mensajes. Su capacidad llega a los 500 TB. Un solo mensaje puede tener un tamaño máximo de 64 KB.
Se puede acceder a los mensajes desde cualquier lugar del mundo a través de llamadas autenticadas mediante HTTP o HTTPS. Las colas de Azure Storage pueden escalar horizontalmente a un gran número de clientes simultáneos para controlar los picos de tráfico.
Dicho esto, este servicio tiene sus limitaciones:
El orden de los mensajes no está garantizado.
Un mensaje se conserva solo siete días antes de que se quite automáticamente.
No existe compatibilidad con la administración de estados, la detección de duplicados o las transacciones.
En la figura 4-13 se muestra la jerarquía de colas de Azure Storage.
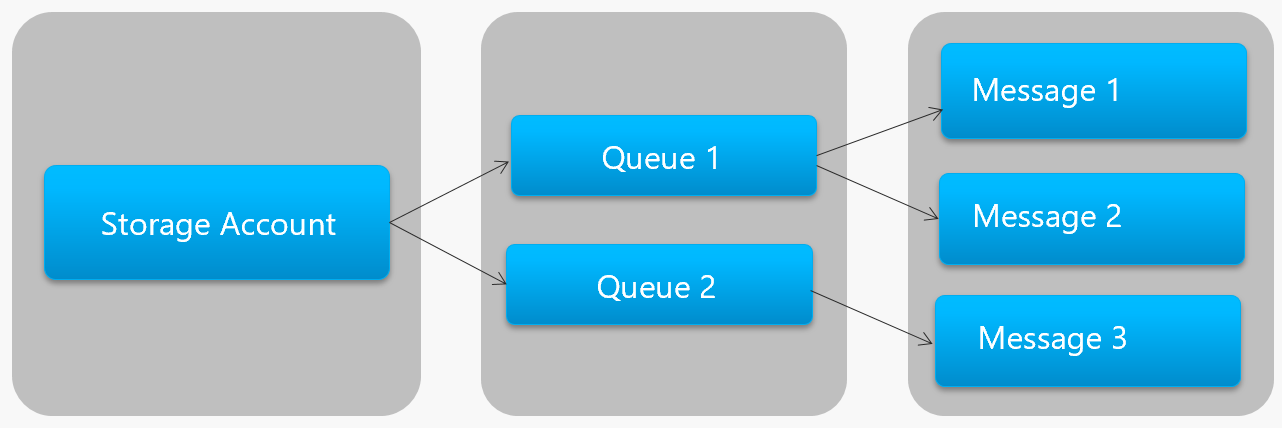
Figura 4-13. Jerarquía de colas de Azure Storage
En la imagen anterior, fíjese en cómo las colas de Storage almacenan los mensajes en la cuenta de Azure Storage subyacente.
Microsoft proporciona a los desarrolladores varias bibliotecas cliente y servidor para el procesamiento de colas de Storage. La mayoría de las plataformas principales son compatibles, incluidas .NET, JavaScript, Ruby, Python y Go. Los desarrolladores nunca deben comunicarse directamente con estas bibliotecas. Si lo hacen, el código del microservicio se acoplará estrechamente al servicio de colas de Azure Storage. Es mejor aislar los detalles de implementación de la API, incluir una capa de intermediación, o una API intermedia, que exponga operaciones genéricas y que encapsule la biblioteca en concreto. Este acoplamiento flexible permite cambiar un servicio de puesta en cola por otro sin tener que realizar cambios en el código del servicio principal.
Las colas de Azure Storage son una opción económica para implementar la mensajería de comandos en las aplicaciones nativas de nube, especialmente si el tamaño de una cola va a superar los 80 GB o basta con un conjunto de características simple. Solo se paga por el almacenamiento de los mensajes; no hay cargos fijos por hora.
Colas de Azure Service Bus
Si existen unos requisitos de mensajería más complejos, considere la posibilidad de usar colas de Azure Service Bus.
Azure Service Bus, que se cimenta en una infraestructura de mensajes muy sólida, admite un modelo de mensajería asincrónica. Los mensajes se almacenan de forma confiable en un agente (la cola) hasta que el consumidor los recibe. La cola garantiza una entrega de mensajes de tipo FIFO (el primero en entrar es el primero en salir), respetando el orden en el que los mensajes se agregaron a la cola.
El tamaño de un mensaje puede ser mucho mayor, hasta 256 KB. Los mensajes se conservan en la cola durante un período de tiempo ilimitado. Service Bus no solo admite llamadas basadas en HTTP, sino que también proporciona plena compatibilidad con el protocolo AMQP. AMQP es un estándar abierto entre proveedores que admite un protocolo binario y un mayor grado de confiabilidad.
Service Bus proporciona un amplio conjunto de características, incluida la compatibilidad con transacciones y una característica de detección de duplicados. La cola garantiza "una entrega como máximo" por mensaje. Descarta automáticamente un mensaje que ya se ha enviado. Si un productor tiene dudas, puede reenviar el mismo mensaje, y Service Bus solo procesará una copia. La detección de duplicados nos libera de tener que crear más infraestructura.
Dos características empresariales más son las particiones y las sesiones. Una cola de mensajes de Service Bus al uso se controla por medio de un único agente de mensajes y se almacena en un único almacén de mensajes. Sin embargo, con las particiones de Service Bus la cola de mensajes se reparte entre varios agentes de mensajes y varios almacenes de mensajes. El rendimiento general ya no está limitado por el rendimiento de un agente de mensajes o almacén de mensajería en concreto. Una interrupción temporal de un almacén de mensajería no hace que una cola particionada deje de estar disponible.
Las sesiones de Service Bus proporcionan una manera de agrupar mensajes relacionados. Imaginemos un escenario de flujo de trabajo en el que los mensajes se deben procesar juntos y la operación debe completarse al final. Para sacar partido de ellas, las sesiones deben habilitarse explícitamente en la cola, y cada mensaje relacionado debe contener el mismo identificador de sesión.
Pero esto hay algunas salvedades importantes: el tamaño de las colas de Service Bus está limitado a 80 GB, que es mucha menos capacidad que las colas de Storage. Además, las colas de Service Bus incurren en un coste base y un cargo por operación.
En la figura 4-14 se describe a grandes rasgos la arquitectura de una cola de Service Bus.
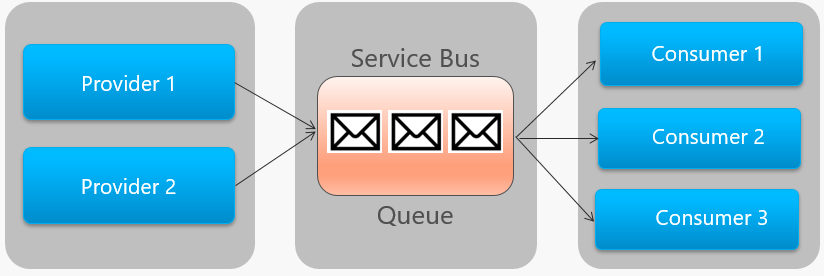
Figura 4-14. Cola de Service Bus
En la imagen anterior, observe la relación de punto a punto. Dos instancias del mismo proveedor ponen en cola mensajes en una misma cola de Service Bus. Solo una de las tres instancias de consumidor de la derecha consume cada mensaje. Analicemos ahora cómo implementar la mensajería cuando hay distintos consumidores interesados en el mismo mensaje.
Eventos
La cola de mensajes es una manera eficaz de implementar la comunicación, en la que un productor puede enviar de forma asincrónica un mensaje a un consumidor. Pero, ¿qué ocurre cuando muchos consumidores diferentes están interesados en el mismo mensaje? Una cola de mensajes dedicada para cada consumidor no escalaría bien y sería difícil de administrar.
Para abordar este escenario, pasaremos al tercer tipo de interacción de mensajes, el evento. Un microservicio anuncia que se ha producido una acción. Otros microservicios, si están interesados, reaccionan a la acción o al evento. Esto también se conoce como estilo arquitectónico controlado por eventos.
Los eventos consisten en un proceso de dos pasos. Ante un cambio de estado determinado, un microservicio publica un evento en un agente de mensajes, lo que hace que esté disponible para cualquier otro microservicio interesado. El microservicio interesado es notificado mediante la suscripción al evento en el agente de mensajes. Para implementar la comunicación basada en eventos se usa el patrón publicador/suscriptor.
En la figura 4-15 se muestra un microservicio de cesta de la compra que publica un evento y que tiene otros dos microservicios suscritos a él.
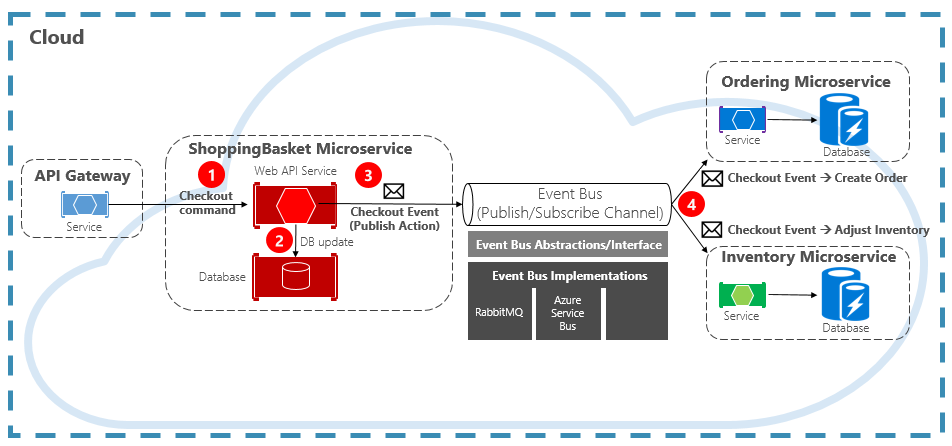
Figura 4-15. Mensajería controlada por eventos
Fíjese en el componente de bus de eventos que hay en el centro del canal de comunicación. Es una clase personalizada que encapsula el agente de mensajes y lo desacopla de la aplicación subyacente. Los microservicios de pedidos e inventario operan el evento de forma independiente sin tener conocimiento el uno del otro, ni tampoco del microservicio de cesta de la compra. Cuando el evento registrado se publica en el bus de eventos, actúan como corresponda.
Con los eventos, pasamos de la tecnología de puesta en cola a los temas. Un tema es similar a una cola, pero admite un patrón de mensajería de uno a varios. Un microservicio publica un mensaje. Varios microservicios de suscripción pueden decidir recibir ese mensaje y actuar en consecuencia. En la figura 4-16 se muestra una arquitectura de temas.
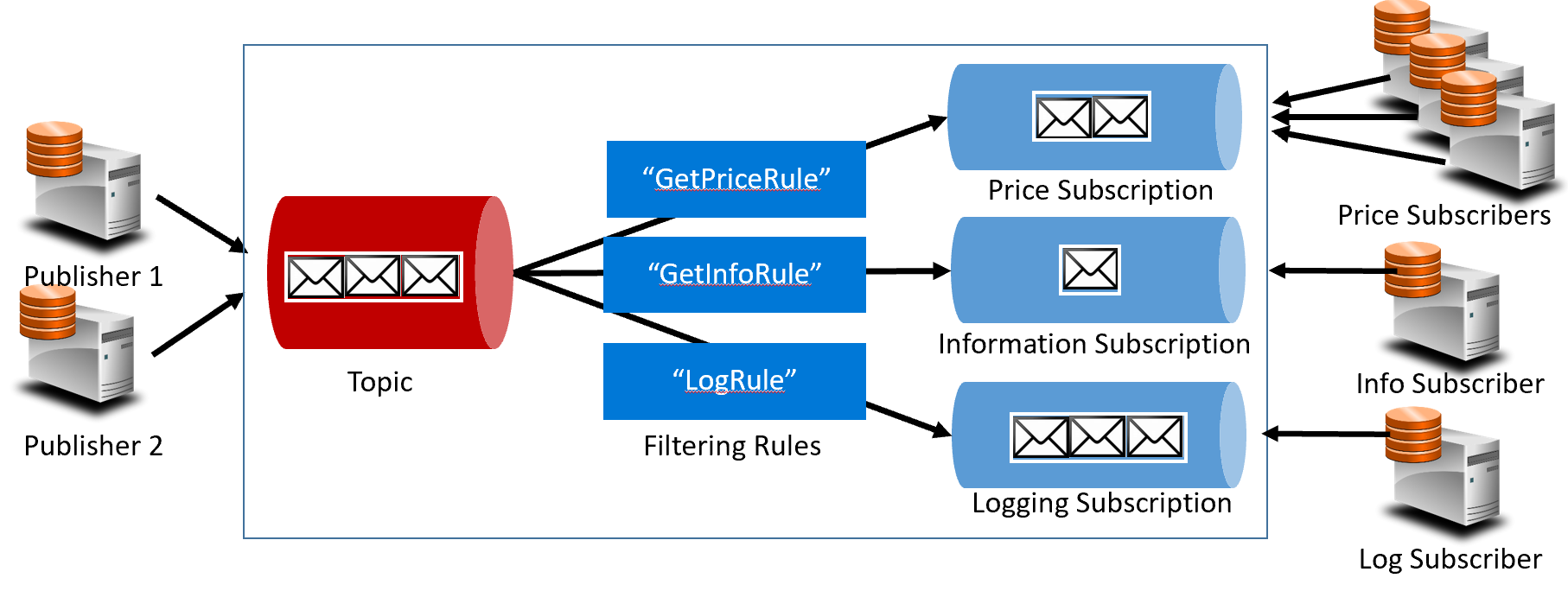
Figura 4-16. Arquitectura de temas
En la imagen anterior, los publicadores envían mensajes al tema. Al final, los suscriptores reciben mensajes de las suscripciones. En el medio, el tema reenvía mensajes a las suscripciones siguiendo un conjunto de reglas (los cuadros de color azul oscuro). Las reglas actúan como un filtro que reenvía mensajes específicos a una suscripción. Aquí, se enviaría un evento "GetPrice" a las suscripciones de precio y de registro, ya que la suscripción de registro ha elegido recibir todos los mensajes. También se enviaría un evento "GetInfo" a las suscripciones de información y de registro.
La nube de Azure admite dos servicios de temas diferentes: temas de Azure Service Bus y Azure Event Grid.
Temas de Azure Service Bus
Los temas de Azure Service Bus se basan en el mismo modelo sólido de mensajes asincrónicos que las colas de Azure Service Bus. Un tema puede recibir mensajes de varios publicadores independientes y enviar mensajes a hasta 2000 suscriptores. Las suscripciones se pueden agregar o quitar dinámicamente en tiempo de ejecución, sin detener el sistema ni volver a crear el tema.
Muchas características avanzadas de las colas de Azure Service Bus también están disponibles en los temas, como la compatibilidad con la detección de duplicados y las transacciones. Los temas de Service Bus se controlan de forma predeterminada mediante un único agente de mensajes y se almacenan en un único almacén de mensajes. Sin embargo, las particiones de Service Bus escalan los temas y permiten repartirlos entre muchos agentes de mensajes y almacenes de mensajes.
La entrega de mensajes programada etiqueta un mensaje con una hora específica para procesarlo. El mensaje no aparecerá en el tema antes de esa hora. El aplazamiento de mensajes permite aplazar la recuperación de un mensaje en un momento posterior. Ambos se suelen usar en escenarios de procesamiento de flujos de trabajo en los que las operaciones se procesan en un orden determinado. El procesamiento de los mensajes recibidos se puede posponer hasta que se haya completado el trabajo anterior.
Los temas de Service Bus son una tecnología sólida y de probada eficacia para habilitar la comunicación entre publicador y suscriptor en los sistemas nativos de nube.
Azure Event Grid
Aunque Azure Service Bus es un agente de mensajería cuya compatibilidad con un conjunto completo de características empresariales está más que probada, Azure Event Grid es el nuevo niño bonito.
A primera vista, Event Grid puede parecer un sistema más de mensajería basada en temas. Sin embargo, es diferente en muchas vertientes. Se centra en las cargas de trabajo controladas por eventos, lo que permite el procesamiento de eventos en tiempo real, una profunda integración con Azure y una infraestructura sin servidor de plataforma abierta. Está diseñado para las aplicaciones nativas de nube y sin servidor de hoy día.
Como un backplane de eventos centralizado, o canalización, Event Grid reacciona a los eventos dentro de los recursos de Azure y desde sus propios servicios.
Las notificaciones de eventos se publican en un tema de Event Grid, que, a su vez, enruta cada evento a una suscripción. Los suscriptores se asignan a suscripciones y consumen los eventos. Al igual que Service Bus, Event Grid admite un modelo de suscriptor filtrado según el cual cada suscripción establece las reglas relativas a los eventos que quiere recibir. El rendimiento de Event Grid es tremendamente rápido, con una garantía de 10 millones de eventos por segundo, lo que permite la entrega casi en tiempo real, mucho más de lo que Azure Service Bus es capaz de generar.
Algo genial de Event Grid es su profunda integración en el tejido de la infraestructura de Azure. Un recurso de Azure, como Cosmos DB, puede publicar eventos integrados directamente en otros recursos de Azure interesados, sin necesidad de código personalizado. Event Grid puede publicar eventos desde una suscripción de Azure, un grupo de recursos o un servicio, lo que confiere a los desarrolladores un control específico sobre el ciclo de vida de los recursos de nube. Sin embargo, Event Grid no se limita a Azure, sino que se trata una plataforma abierta que puede consumir eventos HTTP personalizados publicados desde aplicaciones o servicios de terceros, así como enrutar eventos a suscriptores externos.
Al publicar eventos nativos de recursos de Azure y suscribirse a ellos, no se requiere codificación alguna. Con una configuración sencilla, los eventos de un recurso de Azure se pueden integrar en otro haciendo uso de la "fontanería" ya integrada de los temas y las suscripciones. En la figura 4-17 se muestra la anatomía de Event Grid.
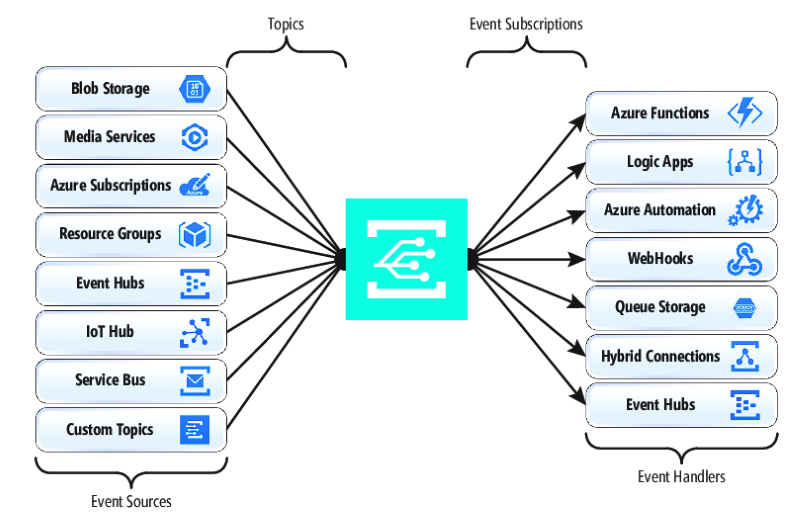
Figura 4-17. Anatomía de Event Grid
Una diferencia importante entre Event Grid y Service Bus es el patrón de intercambio de mensajes subyacente.
Service Bus implementa un modelo de extracción más antiguo según el cual el suscriptor descendente sondea activamente la suscripción a temas para ver si hay mensajes nuevos. El lado bueno de este enfoque es que el suscriptor tiene control total del ritmo al que procesa los mensajes. Controla cuándo y cuántos mensajes se van a procesar en un momento dado. Los mensajes no leídos permanecen en la suscripción hasta que se procesan. Una limitación significativa es la latencia entre el momento en que el evento se genera y la operación de sondeo que extrae ese mensaje al suscriptor para su procesamiento. Asimismo, la sobrecarga de este sondeo constante en pos del siguiente evento consume recursos y dinero.
Pero Event Grid es distinto. Implementa un modelo de inserción según el cual los eventos se envían a controladores de eventos en el momento en que se reciben, de modo que la entrega de eventos tiene lugar casi en tiempo real. También reduce el coste, ya que el servicio se desencadena solo cuando es necesario consumir un evento, no continuamente, como ocurre con el sondeo. Dicho esto, un controlador de eventos debe controlar la carga entrante y proporcionar mecanismos de limitación para no sentirse sobrepasado. Muchos servicios de Azure que consumen estos eventos, como Azure Functions y Logic Apps, proporcionan funcionalidades de escalado automático para controlar el aumento de las cargas.
Event Grid es un servicio de nube y sin servidor totalmente administrado. Escala dinámicamente en función del tráfico, y los cargos derivados corresponden a un uso real, no a una capacidad adquirida previamente. Las primeras 100 000 operaciones al mes son gratis: operaciones como la entrada de eventos (notificaciones de eventos entrantes), los intentos de entrega de suscripciones, las llamadas de administración y el filtrado por asunto. Con una disponibilidad del 99,99 %, Event Grid garantiza la entrega de un evento en un plazo de 24 horas, con funcionalidad de reintento integrada en caso de que la entrega no se materialice. Los mensajes no entregados se pueden mover a una cola de "mensajes fallidos" para su resolución. A diferencia de Azure Service Bus, Event Grid está optimizado para alcanzar un rendimiento rápido, y no admite características como la mensajería ordenada, las transacciones ni las sesiones.
Transmisión de mensajes en la nube de Azure
Azure Service Bus y Event Grid proporcionan una gran compatibilidad con aplicaciones que exponen eventos únicos discretos, como cuando un documento nuevo se ha insertado en Cosmos DB. Pero, ¿qué ocurre si el sistema nativo de nube necesita procesar una secuencia de eventos relacionados? Las secuencias de eventos son más complicadas. Suelen ordenarse por tiempo, están interrelacionadas y deben procesarse como un todo.
Azure Event Hubs es una plataforma de transmisión de datos y un servicio de ingesta de eventos que recopila, transforma y almacena eventos. Está optimizado para capturar datos de transmisión, como las continuas notificaciones de eventos emitidas desde un contexto de telemetría. Este servicio es tremendamente escalable y es capaz de almacenar y procesar millones de eventos por segundo. Ilustrado en la figura 4-18, suele actuar como puerta de entrada de una canalización de eventos, lo que separa la secuencia de ingesta del consumo de eventos.
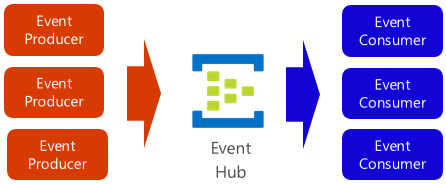
Figura 4-18. Centro de eventos de Azure
Event Hubs admite una latencia baja y la retención de tiempo configurable. A diferencia de las colas y los temas, Event Hubs conserva los datos de los eventos una vez leídos por un consumidor. Esta característica permite que otros servicios analíticos de datos, tanto internos como externos, reproduzcan los datos para su posterior análisis. Los eventos almacenados en un centro de eventos solo se eliminan una vez ha expirado el período de retención, cuyo valor predeterminado es un día, pero esto se puede configurar.
Event Hubs admite protocolos comunes de publicación de eventos, incluidos HTTPS y AMQP. También admite Kafka 1.0. Las aplicaciones de Kafka existentes pueden comunicarse con Event Hubs a través del protocolo de Kafka, lo que supone una alternativa a tener que administrar clústeres de Kafka de gran tamaño. Muchos sistemas nativos de nube y de código abierto usan Kafka.
Event Hubs implementa la transmisión de mensajes a través de un modelo de consumidor de particiones, en el que cada consumidor lee solo un subconjunto específico, o partición, de la secuencia de mensajes. Este patrón permite una gran escala horizontal para procesamiento de eventos y proporciona otras características centradas en secuencias que no están disponibles en colas y temas. Una partición es una secuencia ordenada de eventos que se mantiene en un centro de eventos. A medida que llegan eventos más recientes, se agregan al final de esta secuencia. En la figura 4-19 se ilustran las particiones de Event Hubs.
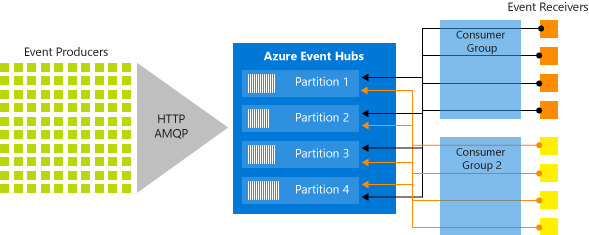
Figura 4-19. Particiones de Event Hubs
En lugar de leer todos el mismo recurso, cada grupo de consumidores lee un subconjunto o partición de la secuencia de mensajes.
Azure Event Hubs puede ser una solución sólida y asequible para las aplicaciones nativas de nube que deben transmitir un gran número de eventos.
Colaborar con nosotros en GitHub
El origen de este contenido se puede encontrar en GitHub, donde también puede crear y revisar problemas y solicitudes de incorporación de cambios. Para más información, consulte nuestra guía para colaboradores.