Características y terminología de Azure Event Hubs
Artículo
Azure Event Hubs es un servicio escalable de procesamiento de eventos que recopila y procesa grandes volúmenes de eventos y datos, con una baja latencia y una alta fiabilidad. Para obtener una introducción detallada del servicio, consulte ¿Qué es Event Hubs?.
Este artículo se basa en el contenido del artículo de información general e incluye detalles técnicos y de implementación de las características y los componentes de Event Hubs.
Espacio de nombres
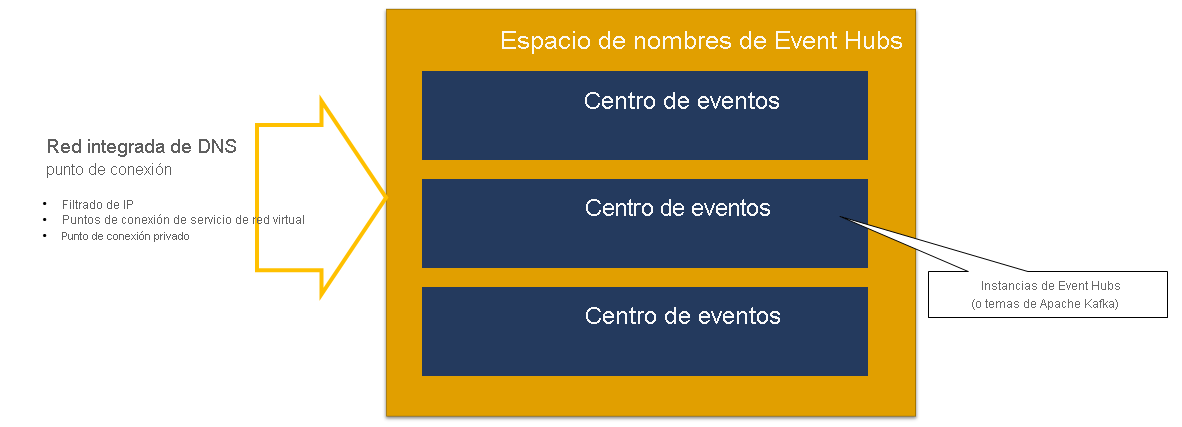
Un espacio de nombres de Event Hubs es un contenedor de administración de centros de eventos (o temas, en la terminología de Kafka). Proporciona puntos de conexión de red integrados de DNS y una variedad de características de administración de control de acceso e integración de red, como filtrado de IP, punto de conexión de servicio de red virtual y Private Link.
Particiones
Event Hubs organiza las secuencias de eventos que se envían a un centro de eventos en una o más particiones. A medida que llegan eventos más recientes, se agregan al final de esta secuencia.
Una partición puede considerarse como un registro de confirmación. Las particiones albergan datos de eventos que contienen la siguiente información:
Cuerpo del evento
Contenedor de propiedades definido por el usuario que describe el evento
Metadatos como su desplazamiento en la partición, su número en la secuencia de secuencia
Marca de tiempo del lado del servicio en la que se aceptó
Ventajas de usar particiones
Event Hubs está diseñado para ayudar en el procesamiento de grandes volúmenes de eventos y la creación de particiones ayuda a hacerlo de dos maneras:
Aunque Event Hubs es un servicio PaaS, hay una realidad física debajo. El mantenimiento de un registro que conserva el orden de los eventos requiere que estos eventos se mantengan juntos en el almacenamiento subyacente y sus réplicas, y esto crea un límite máximo de rendimiento para este tipo de registro. La creación de particiones permite que se usen varios registros paralelos para el mismo centro de eventos y, por lo tanto, multiplicar la capacidad de rendimiento de entrada-salida (E/S) sin procesar disponible.
Sus propias aplicaciones deben poder mantener el procesamiento del volumen de eventos que se envía a un centro de eventos. Esto puede ser complejo y requiere una capacidad de procesamiento en paralelo importante con escalabilidad horizontal. La capacidad de un único proceso para controlar eventos es limitada, por lo que se necesitan varios procesos. Las particiones son el modo en que la solución alimenta esos procesos y, además, garantiza que cada evento tenga un propietario del proceso claro.
Número de particiones
El número de particiones se especifica en el momento de crear un centro de eventos. Debe tener entre uno y el número máximo de particiones admitido para cada plan de tarifa. Para ver el límite del número de particiones para cada plan, consulte este artículo.
Se recomienda elegir al menos tantas particiones como espere necesitar durante la carga máxima de la aplicación para ese centro de eventos específico. En el caso de los niveles distintos de los niveles prémium y dedicado, no se puede cambiar el número de particiones de un centro de eventos después de su creación. En el caso de un centro de eventos en un nivel prémium o dedicado, puede aumentar el número de particiones después de su creación, pero no puede disminuirlo. La distribución de secuencias entre particiones cambiará cuando se realice como la asignación de claves de partición a cambios de particiones, por lo que debe intentar evitar estos cambios si el orden relativo de los eventos es importante en la aplicación.
Establecer el número de particiones en el valor máximo permitido es tentador, pero siempre debe tener en cuenta que los flujos de eventos deben estar estructurados de manera que se puedan aprovechar las ventajas de tener varias particiones. Si necesita conservar el orden absoluto en todos los eventos o solo en un puñado de subsecuencias, es posible que no pueda aprovechar las ventajas de tener muchas particiones. Además, muchas particiones hacen que el procesamiento sea más complejo.
No importa cuántas particiones haya en un centro de eventos en lo que respecta a los precios. Depende del número de unidades de precios (unidades de procesamiento (TU) para el nivel estándar, unidades de procesamiento (PU) para el nivel prémium y unidades de capacidad (CU) para el nivel dedicado) para el espacio de nombres o el clúster dedicado. Por ejemplo, un centro de eventos de nivel estándar con 32 particiones o con una partición generan exactamente el mismo costo cuando el espacio de nombres se establece en una capacidad de una TU. También puede escalar las TU o PU del espacio de nombres o las CU del clúster dedicado independientemente del número de particiones.
Una partición es un mecanismo de organización de datos que permite la publicación y el consumo paralelos. Aunque admite el procesamiento y el escalado paralelos, la capacidad total permanece limitada por la asignación de escalado del espacio de nombres. Se recomienda equilibrar las unidades de escalado (unidades de procesamiento para el nivel estándar, unidades de procesamiento para el nivel Premium o unidades de capacidad para el nivel dedicado) y las particiones para lograr una escala óptima. En general, se recomienda un rendimiento máximo de 1 MB/s por partición. Por lo tanto, una regla general para calcular el número de particiones sería dividir el rendimiento máximo esperado por 1 MB/s. Por ejemplo, si el caso de uso requiriese 20 MB/s, se recomienda elegir al menos 20 particiones para lograr un rendimiento óptimo.
Sin embargo, si tuviese un modelo en el que la aplicación tuviera una afinidad con una partición determinada, aumentar el número de particiones no resultaría beneficioso. Para más información, vea Disponibilidad y coherencia.
Asignación de eventos a particiones
Puede usar una clave de partición para asignar datos de eventos entrantes a particiones concretas con fines de organización de los datos. La clave de partición es un valor proporcionado por el remitente que se pasa a un centro de eventos. Se procesa a través de una función hash estática que crea la asignación de la partición. Si no especifica una clave de partición cuando se publica un evento, se usa una asignación de tipo round robin.
El publicador de eventos solo conoce su clave de partición, no la partición en la que se publican los eventos. Este desacoplamiento de la clave y la partición evita al remitente la necesidad de conocer demasiado sobre el procesamiento de bajada. Una identidad única por cada dispositivo o usuario es una buena clave de partición, pero otros atributos como la geografía también pueden usarse para agrupar eventos relacionados en una única partición.
La especificación de una clave de partición permite mantener los eventos relacionados en la misma partición y en el orden exacto en el que han llegado. La clave de partición es una cadena que se deriva del contexto de la aplicación e identifica la interrelación de los eventos. Una secuencia de eventos identificados por una clave de partición es un flujo. Una partición es un almacén de registros multiplexado para muchos de estos flujos.
Nota
Aunque puede enviar eventos directamente a las particiones, no se recomienda, sobre todo si le da una gran importancia a la alta disponibilidad. Esto degrada la disponibilidad de un centro de eventos en el nivel de partición. Para más información, consulte Disponibilidad y coherencia.
Publicadores de eventos
Toda entidad que envíe datos a un centro de eventos es un publicador de eventos (que se usa como sinónimo de productor de eventos). Los publicadores de eventos pueden publicar eventos mediante HTTPS o AMQP 1.0 o el protocolo de Kafka. Para obtener acceso de publicación, los publicadores de eventos usan la autorización basada en Microsoft Entra ID con tokens JWT emitidos por OAuth2 o un token de firma de acceso compartido (SAS) específico del centro de eventos.
Puede publicar un evento a través de AMQP 1.0, el protocolo de Kafka o HTTPS. El servicio Event Hubs proporciona API REST y bibliotecas cliente para .NET, Java, Python, JavaScript y Go para publicar eventos en un centro de eventos. Para otras plataformas y tiempos de ejecución, puede usar cualquier cliente de AMQP 1.0, como Apache Qpid.
La opción de usar AMQP o HTTPS es específica para el escenario de uso. AMQP requiere el establecimiento de un socket bidireccional persistente, además de la seguridad de nivel de transporte (TLS) o SSL/TLS. AMQP tiene un mayor costo de red al inicializar la sesión, sin embargo, HTTPS requiere una sobrecarga de TLS adicional para cada solicitud. AMQP presenta un rendimiento mayor para publicadores frecuentes y puede lograr latencias mucho menores cuando se usa con código de publicación asincrónico.
Los eventos se pueden publicar de forma individual o por lotes. Una sola publicación tiene un límite de 1 MB, con independencia de si es un evento único o un lote. La publicación de eventos que superen este umbral se rechaza.
El rendimiento de Event Hubs se ajusta mediante particiones y asignaciones de unidades de rendimiento. Se recomienda que los publicadores no estén informados del modelo de particionamiento específico elegido para un centro de eventos y que solo especifiquen una clave de partición que se usa para asignar de forma coherente eventos relacionados a la misma partición.
Event Hubs garantiza que todos los eventos que comparten un valor de clave de partición se almacenen juntos y se entreguen en el orden de llegada. Si se usan claves de partición con directivas de publicador, la identidad del publicador y el valor de la clave de partición deben coincidir. De lo contrario, se produce un error.
Retención de eventos
Los eventos publicados se quitan de un centro de eventos en función de una directiva de retención configurable basada en el tiempo. Estos son algunos puntos importantes:
El valor predeterminado y el periodo de retención más corto posible es de 1 hora.
En el caso de Event Hubs estándar, el período de retención máximo es de 7 días.
En el caso de los niveles Premium y Dedicado de Event Hubs, el período de retención máximo es de 90 días.
Si cambia el período de retención, se aplica a todos los eventos, incluidos los que ya están en el centro de eventos.
Event Hubs retiene los eventos durante el tiempo de retención configurado, que se aplica a todas las particiones. Los eventos se eliminan automáticamente cuando se alcanza el período de retención. Si especificó un período de retención de un día (24 horas), el evento deja de estar disponible exactamente 24 horas después de que se haya aceptado. No puede eliminar eventos explícitamente.
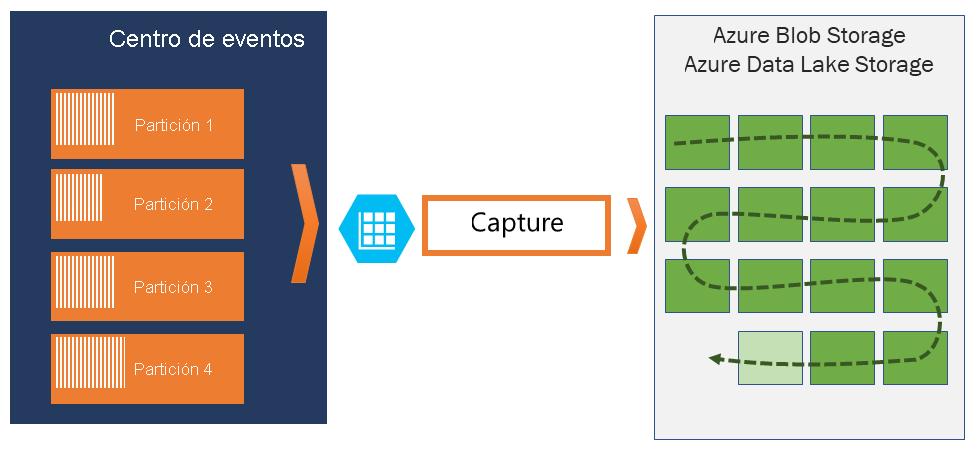
Si necesita archivar eventos más allá del período de retención permitido, puede hacer que se almacenen automáticamente en Azure Storage o Azure Data Lake activando la característica Event Hubs Capture. Si necesita buscar o analizar estos archivos profundos, puede importarlos fácilmente a Azure Synapse o a otros almacenes y plataformas de análisis similares.
La razón del límite de Event Hubs en la retención de datos basada en el tiempo es evitar que grandes volúmenes de datos históricos del cliente se mantengan en un almacén que solo está indexado por una marca de tiempo y solo permite el acceso secuencial. La filosofía arquitectónica aquí es que los datos históricos necesitan una indexación más enriquecida y un acceso más directo que la interfaz de eventos en tiempo real que proporcionan Event Hubs o Kafka. Los motores de flujos de eventos no son adecuados para desempeñar el papel de los lagos de datos o los archivos a largo plazo para la creación de orígenes de eventos.
Nota
Event Hubs es un motor de secuencia de eventos en tiempo real y no está diseñado para usarse en lugar de una base de datos o como almacén permanente para secuencias de eventos que se conservan por tiempo indefinido.
Cuanto más profundo sea el historial de una secuencia de eventos, más se necesitarán índices auxiliares para encontrar un segmento histórico determinado de una secuencia dada. La inspección de cargas de eventos y la indexación no se encuentran dentro del ámbito de características de Event Hubs (o Apache Kafka). Las bases de datos y los almacenes y motores de análisis especializados, como Azure Data Lake Store, Azure Data Lake Analytics y Azure Synapse son, por lo tanto, más adecuados para almacenar eventos históricos.
Los Event Hubs permiten un control granular sobre los publicadores de eventos a través de las directivas de publicador. Las directivas de publicador son características de tiempo de ejecución diseñadas para facilitar grandes números de publicadores de eventos independientes. Con las directivas de publicador, cada publicador usa su propio identificador único al publicar los eventos en un centro de eventos mediante el mecanismo siguiente:
No tiene que crear nombres de publicador con antelación, pero deben coincidir con el token de SAS que se usa al publicar un evento, con el fin de garantizar las identidades de publicador independientes. Cuando use directivas de publicador, el valor PartitionKey debe establecerse en el nombre del publicador. Para que funcione correctamente, estos valores deben coincidir.
Capturar
Event Hubs Capture permite capturar automáticamente los datos de transmisión de Event Hubs y guardarlos en una cuenta de Blob Storage o en una cuenta de Azure Data Lake Storage. Puede habilitar Capture desde Azure Portal y especificar una ventana de tiempo y de tamaño mínimos para realizar la captura. Event Hubs Capture permite especificar una cuenta y un contenedor propios de Azure Blob Storage, o una cuenta de Azure Data Lake Storage, uno de los cuales se usa para almacenar los datos capturados. Los datos capturados se escriben en el formato de Apache Avro.
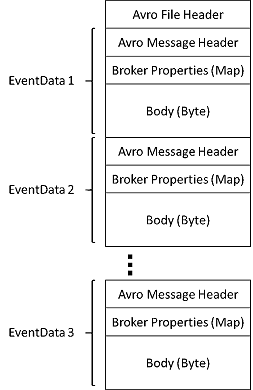
Los archivos que genera Event Hubs Capture tienen el siguiente esquema de Avro:
Event Hubs usa firmas de acceso compartido que están disponibles en el nivel del espacio de nombres y del centro de eventos. Un token de SAS se genera a partir de una clave de SAS y es un hash SHA de una dirección URL, codificado en un formato concreto. Event Hubs puede volver a generar el hash mediante el nombre de la clave (directiva) y el token y así autenticar al remitente. Normalmente, los tokens de SAS para publicadores de eventos se crean solo con privilegios de envío en un centro de eventos concreto. Este mecanismo de dirección URL del token de SAS es la base para la identificación del publicador introducida en la directiva del publicador. Para obtener más información sobre el funcionamiento con SAS, consulte Autenticación con firma de acceso compartido en Service Bus.
Consumidores de eventos
Cualquier entidad que lea datos de eventos de un centro de eventos es un consumidor de eventos. Los consumidores o receptores usan AMQP o Apache Kafka para recibir eventos de un centro de eventos. Event Hubs solo admite el modelo de extracción para que los consumidores reciban eventos de él. Incluso aunque use controladores de eventos para controlar eventos desde un centro de eventos, el procesador de eventos usa internamente el modelo de extracción para recibir eventos del centro de eventos.
Grupos de consumidores
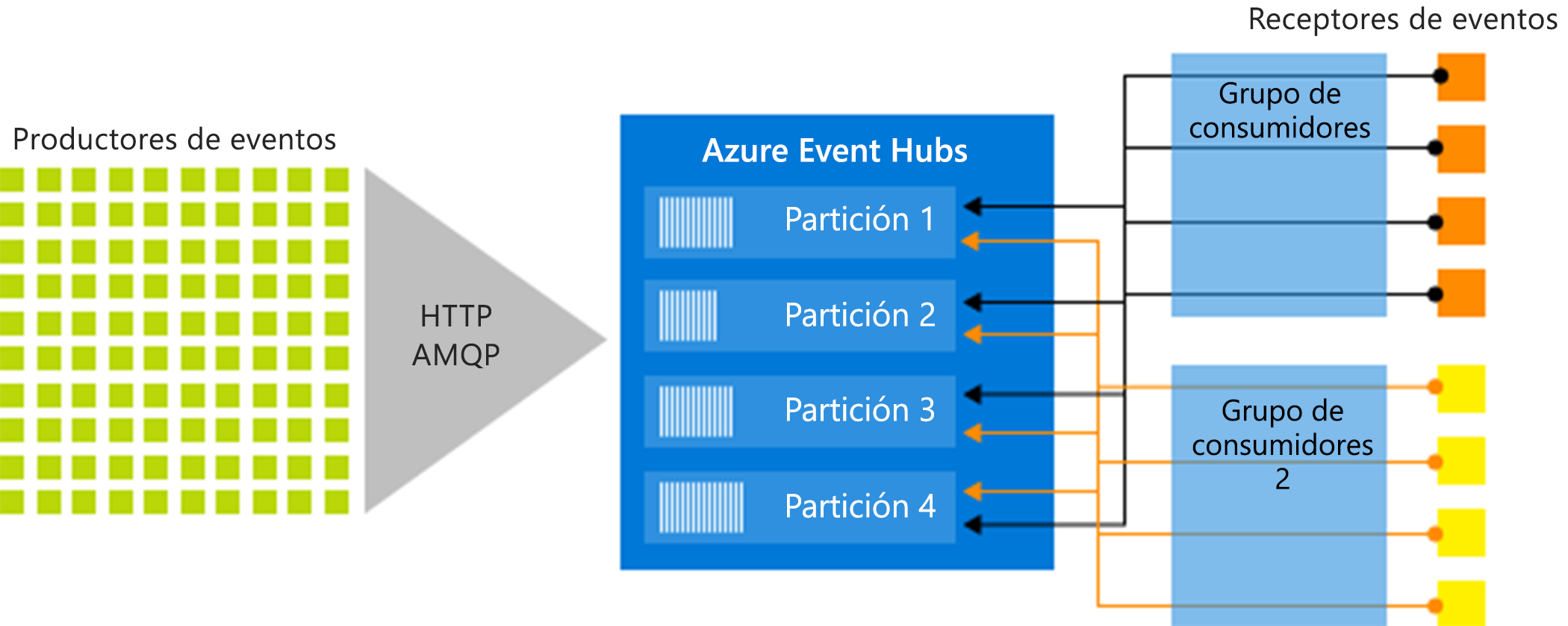
El mecanismo de publicación y suscripción de Event Hubs se habilita a través de los grupos de consumidores. Un grupo de consumidores es una agrupación lógica de consumidores que leen datos de un centro de eventos o un tema de Kafka. Permite que varias aplicaciones que consumen lean los mismos datos de streaming en un centro de eventos de forma independiente a su propio ritmo con sus desplazamientos. Permite paralelizar el consumo de mensajes y distribuir la carga de trabajo entre varios consumidores a la vez que mantiene el orden de los mensajes dentro de cada partición.
Se recomienda que solo haya un receptor activo en una partición dentro de un grupo de consumidores. Sin embargo, en determinados escenarios, puede usar hasta cinco consumidores o receptores por partición donde todos los receptores obtienen todos los eventos de la partición. Si tiene varios lectores en la misma partición, procesará los eventos duplicados. Debe controlarlo en su código, que no es trivial. Sin embargo, es un enfoque válido en algunos escenarios.
En una arquitectura de procesamiento de flujos, cada aplicación de bajada se corresponde con un grupo de consumidores. Si quiere escribir datos de eventos para el almacenamiento a largo plazo, esa aplicación de escritura de almacenamiento es un grupo de consumidores. Otro grupo de consumidores independiente puede realizar el procesamiento de eventos complejos. Solo puede obtener acceso a las particiones a través de un grupo de consumidores. Siempre hay un grupo de consumidores predeterminado en un centro de eventos y puede crear hasta el número máximo de grupos de consumidores para el plan de tarifa correspondiente.
Algunos clientes que ofrecen los SDK de Azure son agentes de consumidor inteligentes que administran automáticamente los detalles para asegurarse de que cada partición tenga un lector único y que se estén leyendo todas las particiones para un centro de eventos. Esto permite que el código se centre en el procesamiento de los eventos que se leen desde el centro de eventos de modo que pueda omitir muchos detalles de las particiones. Para más información, consulte Conexión a una partición.
A continuación se muestran ejemplos de la convención de URI del grupo de consumidores:
HTTP
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #1>
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #2>
La siguiente ilustración muestra la arquitectura de procesamiento del flujo de Event Hubs:
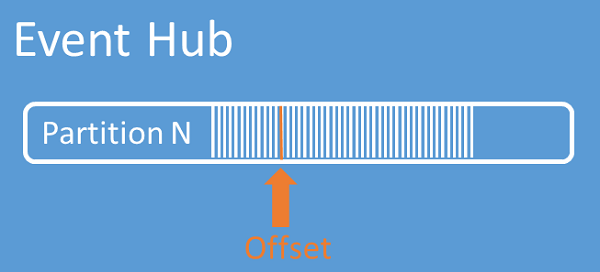
Desplazamientos de los flujos
Un desplazamiento es la posición de un evento dentro de una partición. Puede pensar en un desplazamiento como un cursor de lado cliente. El desplazamiento es una numeración de byte del evento. Este desplazamiento permite que un consumidor de eventos (lector) especifique un punto en el flujo de eventos desde el que quiere empezar a leer los eventos. Puede especificar el desplazamiento como una marca de tiempo o como un valor de desplazamiento. Los consumidores son responsables de almacenar sus propios valores de desplazamiento fuera del servicio de Event Hubs. Dentro de una partición, cada evento incluye un desplazamiento.
Puntos de control
Puntos de control es un proceso en el que los lectores marcan o confirman su posición dentro de la secuencia de eventos de una partición. La creación de puntos de comprobación es responsabilidad del consumidor y se realiza por partición dentro de un grupo de consumidores. Esta responsaibilidad significa que por cada grupo de consumidores, cada lector de la partición debe realizar un seguimiento de su posición actual en el flujo del evento y puede informar al servicio cuando considere que el flujo de datos se ha completado.
Si se desconecta un lector de una partición, cuando se vuelve a conectar comienza a leer en el punto de comprobación que envió previamente el último lector de esa partición en ese grupo de consumidores. Cuando se conecta el lector, pasa este desplazamiento al centro de eventos para especificar la ubicación en la que se va a empezar a leer. De este modo, puede usar puntos de comprobación para marcar eventos como "completados" por las aplicaciones de bajada y para ofrecer resistencia en caso de que se produzca una conmutación por error entre lectores que se ejecutan en máquinas distintas. Es posible volver a los datos más antiguos especificando un desplazamiento inferior desde este proceso de puntos de control. Mediante este mecanismo, los puntos de comprobación permiten una resistencia a la conmutación por error y una reproducción del flujo de eventos.
Importante
El servicio Event Hubs proporciona desplazamientos. Es responsabilidad del consumidor crear puntos de comprobación a medida que se procesan los eventos.
Siga estas recomendaciones al usar Azure Blob Storage como almacén de puntos de control:
Use un contenedor independiente para cada grupo de consumidores. Puede usar la misma cuenta de almacenamiento, pero usar un contenedor por cada grupo.
No use el contenedor ni la cuenta de almacenamiento para otras actividades.
La cuenta de almacenamiento debe estar en la misma región en la que se encuentra la aplicación implementada. Si la aplicación es local, intente elegir la región más cercana posible.
En la página Cuenta de almacenamiento de Azure Portal, en la sección Blob service, asegúrese de que la siguiente configuración está deshabilitada.
Espacio de nombres jerárquico
Eliminación temporal de blobs
Control de versiones
Compactación del registro
Azure Event Hubs admite la compactación del registro de eventos para conservar los eventos más recientes de una clave de evento determinada. Con el tema del centro de eventos o Kafka compacto, puede usar la retención basada en claves en lugar de usar la retención basada en tiempo, que es más imprecisa.
Para obtener más información sobre la compactación de registros, consulte Compactación de registros.
Tareas comunes del consumidor
Todos los consumidores de Event Hubs se conectan a través de una sesión de AMQP 1.0, un canal de comunicación bidireccional con estado. Cada partición tiene una sesión de AMQP 1.0 que facilita el transporte de eventos que deben separarse por partición.
Conexión a una partición
Es una práctica habitual al conectarse a particiones usar un mecanismo de concesiones para coordinar las conexiones del lector a particiones concretas. De este modo, es posible que cada partición de un grupo de consumidores solo tenga un lector activo. Los puntos de comprobación, la concesión y la administración de lectores se simplifican mediante el uso de los clientes de los SDK de Event Hubs, que actúan como agentes de consumidor inteligentes. Son los siguientes:
Después de abrir una sesión de AMQP 1.0 y el vínculo de una partición específica, el servicio de Centros de eventos entrega los eventos al cliente de AMQP 1.0. Este mecanismo de entrega permite un mayor procesamiento y una menor latencia que los mecanismos basados en extracción como HTTP GET. Los eventos se envían al cliente, cada instancia de datos de eventos contiene metadatos importantes, como el número de secuencia y el desplazamiento que se usan para facilitar la creación de puntos de comprobación en la secuencia de eventos.
Datos de evento:
Offset
Número de secuencia
Body
Propiedades de usuario
Propiedades del sistema
Es su responsabilidad administrar el desplazamiento.
Grupos de aplicaciones
Un grupo de aplicaciones es una colección de aplicaciones cliente que se conectan a un espacio de nombres de Event Hubs y que comparten una condición de identificación única, como el contexto de seguridad, directiva de acceso compartida o el Id. de aplicación de Microsoft Entra (Azure AD).
Azure Event Hubs permite definir directivas de acceso a recursos, como directivas de limitación para un grupo de aplicaciones determinado y controla el streaming de eventos (publicación o consumo) entre las aplicaciones cliente y Event Hubs.
La compatibilidad del protocolo con los clientes de Apache Kafka (versiones >=1.0) proporciona puntos de conexión que permiten que las aplicaciones de Kafka existentes usen Event Hubs. La mayoría de las aplicaciones de Kafka existentes se pueden volver a configurar para que apunten a un espacio de nombres en lugar de a un servidor de arranque del clúster de Kafka.
Desde la perspectiva del costo, el esfuerzo operativo y la confiabilidad, Azure Event Hubs es una excelente alternativa a la implementación y el uso de sus propios clústeres de Kafka y Zookeeper y a las ofertas de Kafka como servicio no nativas para Azure.
Además de conseguir la misma funcionalidad básica que la del agente de Apache Kafka, también se obtiene acceso a las características del Azure Event Hubs, como el procesamiento por lotes y el archivado automáticos a través de Event Hubs Capture, el equilibrio y el escalado automáticos, la recuperación ante desastres, la compatibilidad con zonas de disponibilidad sin costos adicionales, la integración de red flexible y segura y la compatibilidad con varios protocolos, como el protocolo compatible con firewall AMQP sobre WebSockets.
Protocolos
Los productores o remitentes pueden utilizar los protocolos Advanced Messaging Queuing Protocol (AMQP), Kafka o HTTPS para enviar eventos a un centro de eventos.
Los consumidores o receptores usan AMQP o Kafka para recibir eventos de un centro de eventos. Event Hubs solo admite el modelo de extracción para que los consumidores reciban eventos de él. Incluso cuando se usan controladores de eventos para controlar eventos desde un centro de eventos, el procesador de eventos usa internamente el modelo de extracción para recibir eventos del centro de eventos.
AMQP
Puede usar el protocolo AMQP 1.0 para enviar y recibir eventos de Azure Event Hubs. AMQP proporciona una comunicación confiable, eficaz y segura para enviar y recibir eventos. Puede usarlo para streaming en tiempo real y de alto rendimiento y es compatible con la mayoría de los SDK de Azure Event Hubs.
HTTPS/API de REST
Solo puede enviar eventos a Event Hubs mediante solicitudes HTTP POST. Event Hubs no admite la recepción de eventos a través de HTTPS. Es adecuado para clientes ligeros en los que una conexión TCP directa no es factible.
Apache Kafka
Azure Event Hubs tiene un punto de conexión de Kafka integrado que admite productores y consumidores de Kafka. Las aplicaciones compiladas mediante Kafka pueden usar el protocolo Kafka (versión 1.0 o posterior) para enviar y recibir eventos de Event Hubs sin cambios en el código.
Los SDK de Azure abstraen los protocolos de comunicación subyacentes y proporcionan una manera simplificada de enviar y recibir eventos de Event Hubs mediante lenguajes como C#, Java, Python, JavaScript, etc.
Pasos siguientes
Para obtener más información acerca de Event Hubs, visite los vínculos siguientes:
Aprenda a usar Azure Event Hubs para procesar de forma confiable flujos de datos de gran volumen que le permitan codificar aplicaciones para enviar y recibir mensajes a través del centro.