Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Sugerencia
Este contenido es un extracto del libro electrónico, Arquitecto de aplicaciones web modernas con ASP.NET Core y Azure, disponible en .NET Docs o como un PDF descargable gratuito que se puede leer sin conexión.

"Si los constructores construyeran edificios de la manera en que los programadores escribieran programas, entonces el primer pájaro carpintero que pasara destruiría la civilización."
- Gerald Weinberg
Debe planificar y diseñar soluciones de software con la capacidad de mantenimiento en mente. Los principios descritos en esta sección pueden ayudarle a guiarse hacia las decisiones arquitectónicas que darán lugar a aplicaciones limpias y fáciles de mantener. Por lo general, estos principios le guiarán hacia la creación de aplicaciones fuera de componentes discretos que no están estrechamente acoplados a otras partes de la aplicación, sino que se comunican a través de interfaces explícitas o sistemas de mensajería.
Principios de diseño comunes
Separación de intereses
Un principio rector al desarrollar es Separación de responsabilidades. Este principio afirma que el software se debe separar en función de los tipos de trabajo que realiza. Por ejemplo, considere una aplicación que incluye lógica para identificar elementos destacados que se muestran al usuario y qué formato da formato a dichos elementos de una manera concreta para que sean más evidentes. El comportamiento responsable de elegir qué elementos dar formato se debe mantener separado del comportamiento responsable de dar formato a los elementos, ya que estos comportamientos son preocupaciones independientes que solo están relacionadas de forma coincidente entre sí.
De forma arquitectónica, las aplicaciones se pueden compilar lógicamente para seguir este principio separando el comportamiento empresarial principal de la lógica de la infraestructura y la interfaz de usuario. Lo ideal es que las reglas de negocios y la lógica residan en un proyecto independiente, que no debe depender de otros proyectos de la aplicación. Esta separación ayuda a garantizar que el modelo de negocio es fácil de probar y puede evolucionar sin estar estrechamente acoplado a detalles de implementación de bajo nivel (también ayuda si los problemas de infraestructura dependen de las abstracciones definidas en el nivel de negocio). La separación de preocupaciones es una consideración clave detrás del uso de capas en arquitecturas de aplicaciones.
Encapsulación
Las distintas partes de una aplicación deben usar la encapsulación para aislarlas de otras partes de la aplicación. Los componentes y capas de la aplicación deben ser capaces de ajustar su implementación interna sin interrumpir sus colaboradores siempre que no se infrinjan los contratos externos. El uso adecuado de la encapsulación ayuda a lograr acoplamiento flexible y modularidad en los diseños de aplicación, ya que los objetos y paquetes se pueden reemplazar por implementaciones alternativas siempre que se mantenga la misma interfaz.
En las clases, la encapsulación se logra limitando el acceso externo al estado interno de la clase. Si un actor externo quiere manipular el estado del objeto, debe hacerlo a través de una función bien definida (o establecedor de propiedades), en lugar de tener acceso directo al estado privado del objeto. Del mismo modo, los componentes de aplicación y las propias aplicaciones deben exponer interfaces bien definidas para que los colaboradores usen, en lugar de permitir que su estado se modifique directamente. Este enfoque libera el diseño interno de la aplicación para evolucionar con el tiempo sin preocuparse de que hacerlo interrumpirá a los colaboradores, siempre y cuando se mantengan los contratos públicos.
El estado global mutable es antitético a la encapsulación. No se puede confiar en un valor capturado del estado global mutable en una función para tener el mismo valor en otra función (o incluso más en la misma función). Comprender los problemas con el estado global mutable es una de las razones por las que los lenguajes de programación como C# admiten diferentes reglas de ámbito, que se usan en todas partes, desde instrucciones a métodos a clases. Es importante señalar que las arquitecturas impulsadas por datos, que dependen de una base de datos central para la integración dentro y entre aplicaciones, eligen, por su naturaleza, depender del estado global mutable representado por la base de datos. Una consideración clave en el diseño controlado por dominio y la arquitectura limpia es cómo encapsular el acceso a los datos y cómo garantizar que el estado de la aplicación no se vuelva inválido mediante el acceso directo a su formato de persistencia.
Inversión de dependencias
La dirección de dependencia dentro de la aplicación debe estar en la dirección de la abstracción, no los detalles de implementación. La mayoría de las aplicaciones se escriben de manera que la dependencia durante la compilación fluya hacia la ejecución, produciendo un gráfico de dependencias directo. Es decir, si la clase A llama a un método de la clase B y la clase B llama a un método de la clase C, la clase A dependerá de la clase B y la clase B dependerá de la clase C, como se muestra en la figura 4-1.
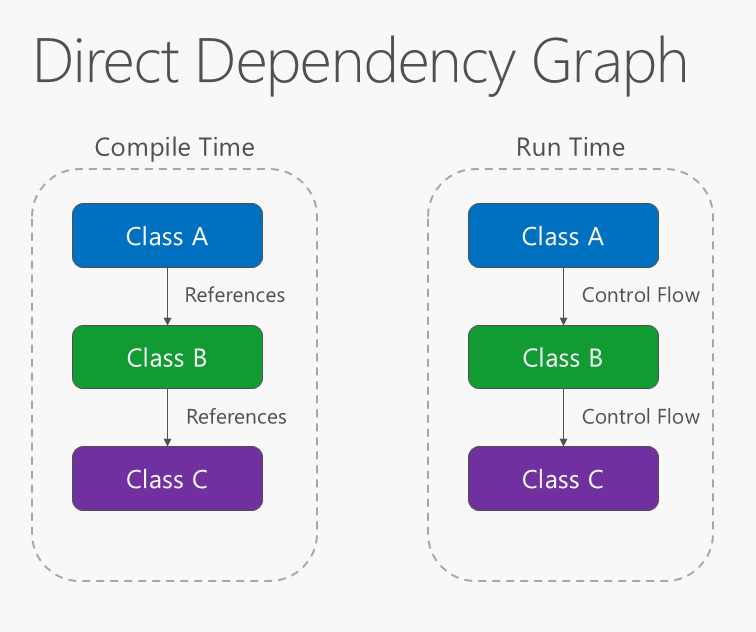
Figura 4-1. Gráfico de dependencias directa.
Aplicar el principio de inversión de dependencias permite que A llame a métodos en una abstracción que implementa B, lo que hace posible que A llame a B en tiempo de ejecución, pero que B dependa de una interfaz que controla A en tiempo de compilación (por tanto, se invierte la dependencia de tiempo de compilación normal). En tiempo de ejecución, el flujo de ejecución del programa permanece sin cambios, pero la introducción de interfaces significa que se pueden conectar fácilmente diferentes implementaciones de estas interfaces.
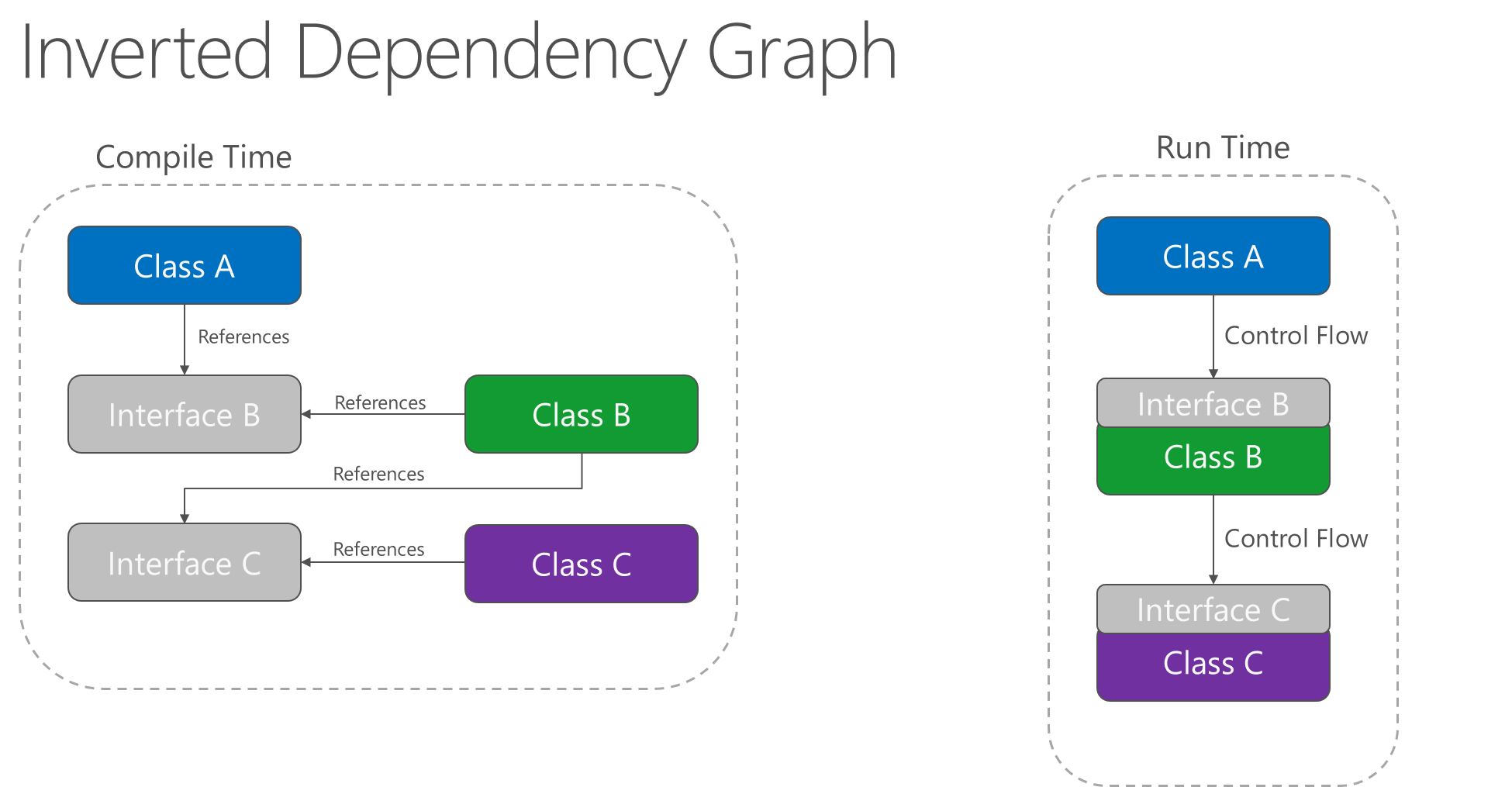
Figura 4-2. Gráfico de dependencias invertido.
La inversión de dependencias es una parte clave de la creación de aplicaciones acopladas de forma flexible, ya que los detalles de implementación se pueden escribir para depender e implementar abstracciones de nivel superior, en lugar de hacerlo de otra manera. Las aplicaciones resultantes son más fáciles de probar, modulares y fáciles de mantener como resultado. La práctica de inserción de dependencias es posible siguiendo el principio de inversión de dependencias.
Dependencias explícitas
Los métodos y clases deben requerir explícitamente los objetos de colaboración que necesiten para funcionar correctamente. Se denomina principio de dependencias explícitas. Los constructores de clase proporcionan una oportunidad para que las clases identifiquen las cosas que necesitan para que estén en un estado válido y funcionen correctamente. Si define clases que se pueden construir y llamar, pero que solo funcionarán correctamente si determinados componentes globales o de infraestructura están en vigor, estas clases están siendo deshonestas con sus clientes. El contrato de constructor indica al cliente que solo necesita las cosas especificadas (posiblemente nada si la clase simplemente usa un constructor sin parámetros), pero en tiempo de ejecución resulta que el objeto realmente necesitaba algo más.
Siguiendo el principio de dependencias explícitas, las clases y los métodos son honestos con sus clientes sobre lo que necesitan para funcionar. Siguiendo el principio, el código es más autodocumentado y los contratos de codificación son más fáciles de usar, ya que los usuarios confiarán en que siempre que proporcionen lo necesario en forma de parámetros de método o constructor, los objetos con los que trabajan se comportarán correctamente en tiempo de ejecución.
Responsabilidad única
El principio de responsabilidad única se aplica al diseño orientado a objetos, pero también se puede considerar como un principio arquitectónico similar a la separación de preocupaciones. Indica que los objetos deben tener solo una responsabilidad y que solo deben tener una razón para cambiar. En concreto, la única situación en la que el objeto debe cambiar es si se debe actualizar la manera en que realiza su responsabilidad. Seguir este principio ayuda a generar sistemas más flexibles y modulares, ya que muchos tipos de comportamiento nuevos se pueden implementar como nuevas clases, en lugar de agregar responsabilidad adicional a las clases existentes. Agregar nuevas clases siempre es más segura que cambiar las clases existentes, ya que aún no hay código que dependa de las nuevas clases.
En una aplicación monolítica, podemos aplicar el principio de responsabilidad única en un nivel alto a las capas de la aplicación. La responsabilidad de la presentación debe permanecer en el proyecto de interfaz de usuario, mientras que la responsabilidad de acceso a los datos debe mantenerse dentro de un proyecto de infraestructura. La lógica de negocios debe mantenerse en el proyecto principal de la aplicación, donde se puede probar fácilmente y puede evolucionar independientemente de otras responsabilidades.
Cuando este principio se aplica a la arquitectura de la aplicación y se lleva a su punto final lógico, se obtienen microservicios. Un microservicio determinado debe tener una sola responsabilidad. Si necesita ampliar el comportamiento de un sistema, normalmente es mejor hacerlo agregando microservicios adicionales, en lugar de agregar responsabilidad a uno existente.
Más información sobre la arquitectura de microservicios
Una vez y solo una (DRY)
La aplicación debe evitar especificar el comportamiento relacionado con un concepto determinado en varios lugares, ya que esta práctica es una fuente frecuente de errores. En algún momento, un cambio en los requisitos requerirá cambiar este comportamiento. Es probable que al menos una instancia del comportamiento no se actualice y el sistema se comportará incoherentemente.
En lugar de duplicar la lógica, encapsularla en una construcción de programación. Haga que esta construcción sea la única autoridad sobre este comportamiento y que cualquier otra parte de la aplicación que requiera este comportamiento use la nueva construcción.
Nota:
Evite vincular comportamientos que solo coincidan por repetición. Por ejemplo, solo porque dos constantes diferentes tienen el mismo valor, eso no significa que solo debe tener una constante, si conceptualmente hacen referencia a cosas diferentes. La duplicación siempre es preferible a acoplarse a la abstracción equivocada.
Omisión de persistencia
La ignorancia de persistencia (PI) hace referencia a los tipos que deben conservarse, pero cuyo código no se ve afectado por la elección de la tecnología de persistencia. Estos tipos de .NET se conocen a veces como Objetos CLR Simples (POCOs), ya que no necesitan heredar de una clase base determinada ni implementar una interfaz determinada. El desconocimiento en materia de persistencia es valioso porque permite que el mismo modelo de negocio se implemente de varias maneras, ofreciendo así una mayor flexibilidad a la aplicación. Las opciones de persistencia pueden cambiar con el tiempo, desde una tecnología de base de datos a otra, o se podrían requerir formas adicionales de persistencia además de lo que se inicie la aplicación (por ejemplo, mediante una caché de Redis o Azure Cosmos DB además de una base de datos relacional).
Algunos ejemplos de infracciones de este principio son:
Clase base necesaria.
Una implementación de interfaz requerida.
Clases responsables de guardarse a sí mismas (por ejemplo, el patrón de registro activo).
Se requiere un constructor sin parámetros.
Propiedades que requieren palabra clave virtual.
Atributos específicos necesarios para la persistencia.
El requisito de que las clases tengan cualquiera de las características o comportamientos anteriores agrega acoplamiento entre los tipos que se van a conservar y la elección de la tecnología de persistencia, lo que dificulta la adopción de nuevas estrategias de acceso a datos en el futuro.
Contextos delimitados
Los contextos delimitados son un patrón central en Domain-Driven diseño. Proporcionan una manera de abordar la complejidad en aplicaciones o organizaciones de gran tamaño dividiéndose en módulos conceptuales independientes. A continuación, cada módulo conceptual representa un contexto que está separado de otros contextos (por lo tanto, delimitados) y puede evolucionar de forma independiente. Idealmente, cada contexto delimitado debe ser libre de elegir sus propios nombres para los conceptos que contiene y debe tener acceso exclusivo a su propio almacenamiento de persistencia.
Como mínimo, las aplicaciones web individuales deben esforzarse por ser su propio contexto limitado, con su propio almacén de persistencia para su modelo de negocio, en lugar de compartir una base de datos con otras aplicaciones. La comunicación entre contextos enlazados se produce a través de interfaces mediante programación, en lugar de a través de una base de datos compartida, lo que permite que la lógica de negocios y los eventos se produzcan en respuesta a los cambios que tienen lugar. Los contextos delimitados se asignan estrechamente a los microservicios que, idealmente, también se implementan como sus propios contextos delimitados individuales.
Recursos adicionales
Colaborar con nosotros en GitHub
El origen de este contenido se puede encontrar en GitHub, donde también puede crear y revisar problemas y solicitudes de incorporación de cambios. Para más información, consulte nuestra guía para colaboradores.