Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Sugerencia
Este contenido es un extracto del libro electrónico, Arquitecto de aplicaciones web modernas con ASP.NET Core y Azure, disponible en .NET Docs o como un PDF descargable gratuito que se puede leer sin conexión.

"Si cree que una buena arquitectura es costosa, pruebe una arquitectura incorrecta". - Brian Foote y Joseph Yoder
La mayoría de las aplicaciones .NET tradicionales se implementan como unidades únicas correspondientes a un archivo ejecutable o a una sola aplicación web que se ejecuta dentro de un único appdomain de IIS. Este enfoque es el modelo de implementación más sencillo y sirve muy bien a muchas aplicaciones públicas internas y más pequeñas. Sin embargo, incluso dada esta sola unidad de implementación, la mayoría de las aplicaciones empresariales no triviales se benefician de cierta separación lógica en varias capas.
¿Qué es una aplicación monolítica?
Una aplicación monolítica es una que es totalmente independiente, en términos de su comportamiento. Puede interactuar con otros servicios o almacenes de datos en el transcurso de realizar sus operaciones, pero el núcleo de su comportamiento se ejecuta dentro de su propio proceso y toda la aplicación normalmente se implementa como una sola unidad. Si esta aplicación necesita escalar horizontalmente, normalmente toda la aplicación se duplica en varios servidores o máquinas virtuales.
Aplicaciones todo en uno
El menor número posible de proyectos para una arquitectura de aplicación es uno. En esta arquitectura, toda la lógica de la aplicación se incluye en un único proyecto, compilado en un único ensamblado e implementado como una sola unidad.
Un nuevo proyecto de ASP.NET Core, ya sea creado en Visual Studio o desde la línea de comandos, comienza como un monolito "todo en uno" simple. Contiene todo el comportamiento de la aplicación, incluida la lógica de presentación, negocio y acceso a datos. En la figura 5-1 se muestra la estructura de archivos de una aplicación de un solo proyecto.
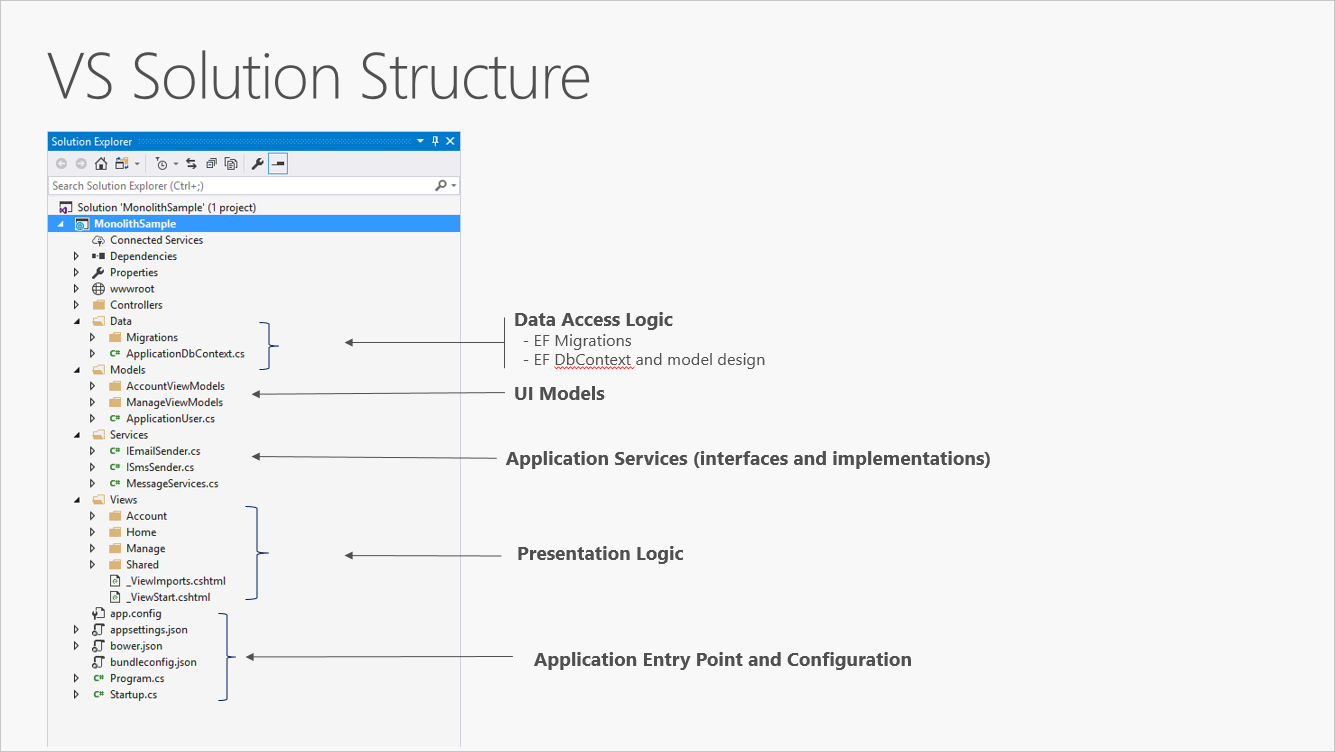
Figura 5-1. Un proyecto de aplicación ASP.NET Core único.
En un único escenario de proyecto, la separación de preocupaciones se logra mediante el uso de carpetas. La plantilla predeterminada incluye carpetas independientes para las responsabilidades del patrón MVC de modelos, vistas y controladores, así como carpetas adicionales para datos y servicios. En esta disposición, los detalles de la presentación deben limitarse tanto como sea posible a la carpeta Vistas y los detalles de implementación de acceso a datos deben limitarse a las clases que se mantienen en la carpeta Datos. La lógica de negocios debe residir en servicios y clases dentro de la carpeta Models.
Aunque es simple, la solución monolítica de un solo proyecto tiene algunas desventajas. A medida que crece el tamaño y la complejidad del proyecto, el número de archivos y carpetas seguirá creciendo también. Los problemas de la interfaz de usuario (modelos, vistas, controladores) residen en varias carpetas, que no se agrupan alfabéticamente. Este problema solo se empeora cuando se agregan construcciones de nivel de interfaz de usuario adicionales, como Filtros o ModelBinders, en sus propias carpetas. La lógica de negocios está dispersa entre las carpetas Modelos y Servicios y no hay ninguna indicación clara de qué clases en qué carpetas deben depender de las demás. Esta falta de organización en el nivel del proyecto suele dar lugar a código espagueti.
Para solucionar estos problemas, las aplicaciones suelen evolucionar en soluciones de varios proyectos, donde se considera que cada proyecto reside en una capa determinada de la aplicación.
¿Qué son las capas?
A medida que las aplicaciones crecen en complejidad, una manera de administrar esa complejidad es dividir la aplicación según sus responsabilidades o preocupaciones. Este enfoque sigue la separación del principio de preocupación y puede ayudar a mantener organizado un código base creciente para que los desarrolladores puedan encontrar fácilmente dónde se implementa cierta funcionalidad. Sin embargo, la arquitectura superpuesta ofrece una serie de ventajas más allá de la organización de código.
Al organizar el código en capas, se puede reutilizar la funcionalidad común de bajo nivel en toda la aplicación. Esta reutilización es beneficiosa porque significa que es necesario escribir menos código y porque puede permitir que la aplicación normalice una sola implementación, siguiendo el principio de no repetirse (DRY).
Con una arquitectura superpuesta, las aplicaciones pueden aplicar restricciones en las que las capas pueden comunicarse con otras capas. Esta arquitectura ayuda a lograr la encapsulación. Cuando se cambia o reemplaza una capa, solo deben verse afectadas las capas que funcionan con ella. Al limitar qué capas dependen de qué otras capas, se puede mitigar el impacto de los cambios para que un único cambio no afecte a toda la aplicación.
Las capas (y la encapsulación) facilitan mucho la sustitución de la funcionalidad dentro de la aplicación. Por ejemplo, una aplicación podría usar inicialmente su propia base de datos de SQL Server para la persistencia, pero más adelante podría optar por usar una estrategia de persistencia basada en la nube o una detrás de una API web. Si la aplicación ha encapsulado correctamente su implementación de persistencia dentro de una capa lógica, esa capa específica de SQL Server podría reemplazarse por una nueva que implemente la misma interfaz pública.
Además del potencial de intercambiar implementaciones en respuesta a cambios futuros en los requisitos, las capas de aplicación también pueden facilitar el intercambio de implementaciones con fines de prueba. En lugar de tener que escribir pruebas que funcionan con la capa de datos real o la capa de interfaz de usuario de la aplicación, estas capas se pueden reemplazar en tiempo de prueba por implementaciones falsas que proporcionan respuestas conocidas a las solicitudes. Este enfoque normalmente hace que las pruebas sean mucho más fáciles de escribir y se ejecuten mucho más rápido en comparación con la ejecución de pruebas en la infraestructura real de la aplicación.
La capa lógica es una técnica común para mejorar la organización del código en aplicaciones de software empresarial y hay varias maneras en que el código se puede organizar en capas.
Nota:
Las capas representan la separación lógica dentro de la aplicación. En caso de que la lógica de la aplicación se distribuya físicamente a servidores o procesos independientes, estos destinos de implementación física independientes se conocen como niveles. Es posible, y bastante común, tener una aplicación de N niveles que se implementa en un solo nivel.
Aplicaciones tradicionales de arquitectura de "N niveles"
La organización más común de la lógica de aplicación en capas se muestra en la figura 5-2.
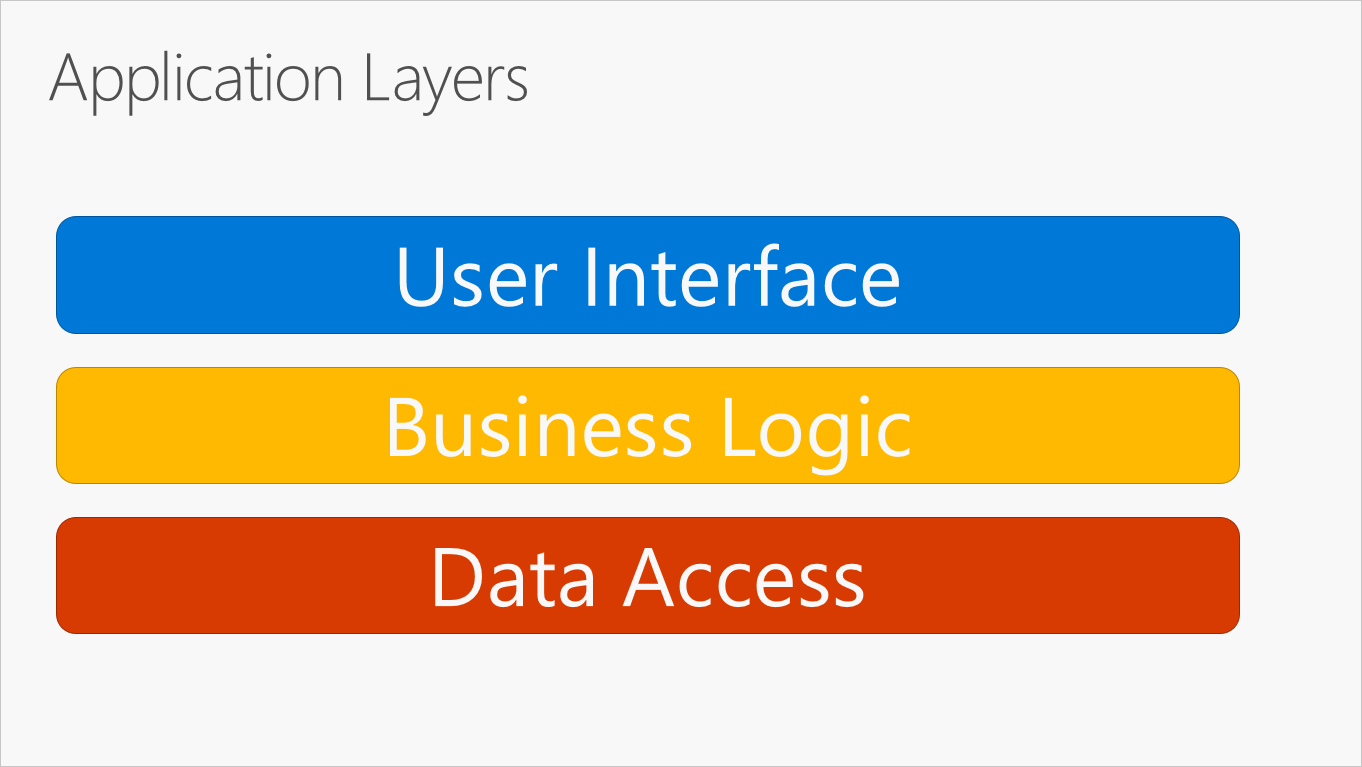
Figura 5-2. Capas de aplicación típicas.
Estas capas suelen abreviarse como UI, BLL (capa de lógica de negocios) y DAL (capa de acceso a datos). Con esta arquitectura, los usuarios realizan solicitudes a través de la capa de interfaz de usuario, que solo interactúa con el BLL. El BLL, a su vez, puede llamar al DAL para las solicitudes de acceso a datos. La capa de interfaz de usuario no debe realizar ninguna solicitud directamente a la DAL ni debe interactuar con la persistencia directamente a través de otros medios. Del mismo modo, BLL solo debe interactuar con la persistencia a través de DAL. De esta manera, cada capa tiene su propia responsabilidad conocida.
Una desventaja de este enfoque tradicional de capas es que las dependencias en tiempo de compilación se ejecutan desde la parte superior a la inferior. Es decir, la capa de interfaz de usuario depende del BLL, que depende de la DAL. Esto significa que el BLL, que normalmente contiene la lógica más importante de la aplicación, depende de los detalles de implementación del acceso a datos (y, a menudo, de la existencia de una base de datos). La prueba de la lógica de negocios en una arquitectura de este tipo suele ser difícil, lo que requiere una base de datos de prueba. El principio de inversión de dependencias se puede usar para solucionar este problema, como verá en la sección siguiente.
En la figura 5-3 se muestra una solución de ejemplo que divide la aplicación en tres proyectos por responsabilidad (o capa).
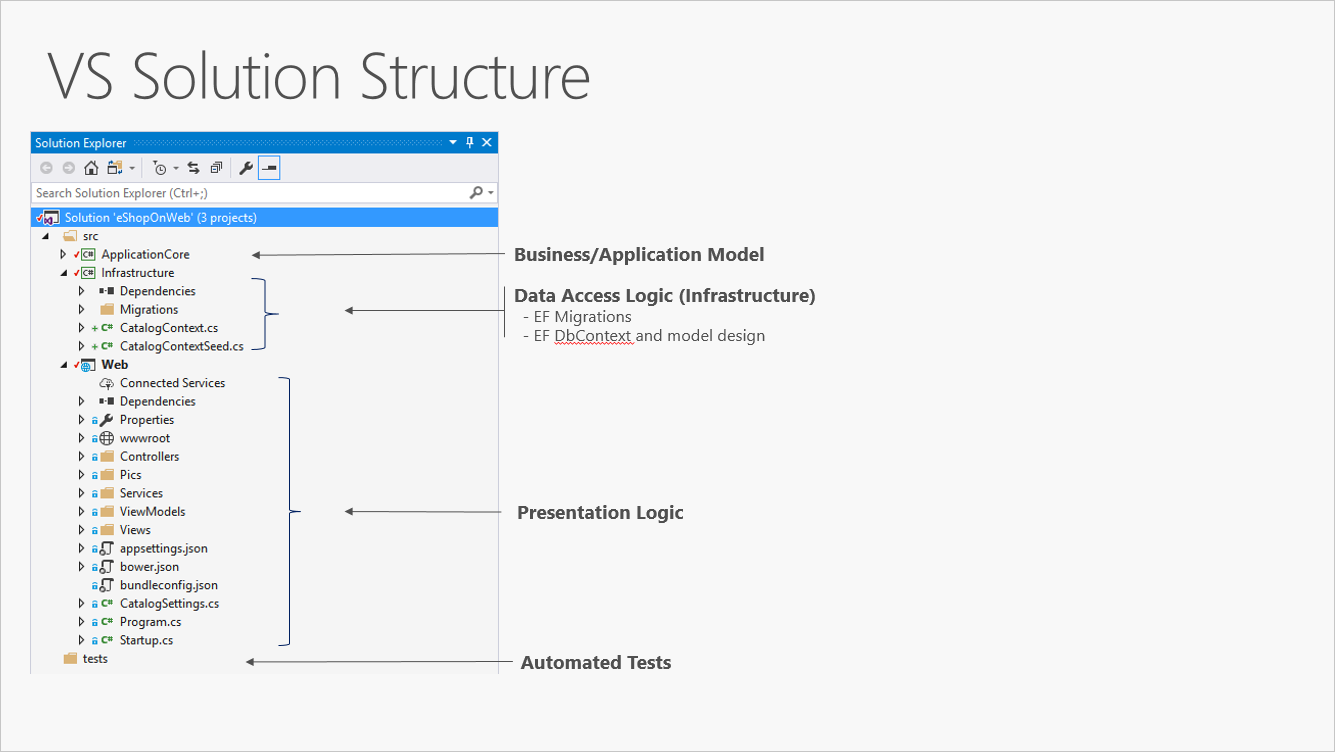
Figura 5-3. Una aplicación monolítica simple con tres proyectos.
Aunque esta aplicación usa varios proyectos para fines organizativos, todavía se implementa como una sola unidad y sus clientes interactuarán con ella como una sola aplicación web. Esto permite un proceso de implementación muy sencillo. En la figura 5-4 se muestra cómo se puede hospedar una aplicación de este tipo mediante Azure.
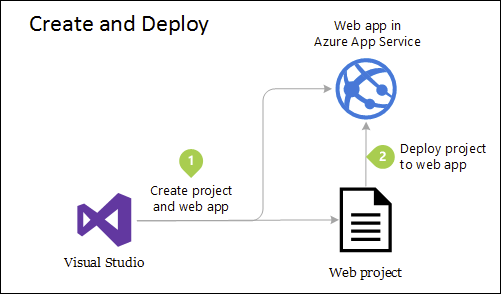
Figura 5-4. Implementación sencilla de Azure Web App
A medida que aumentan las necesidades de la aplicación, es posible que se requieran soluciones de implementación más complejas y sólidas. En la figura 5-5 se muestra un ejemplo de un plan de implementación más complejo que admite funcionalidades adicionales.
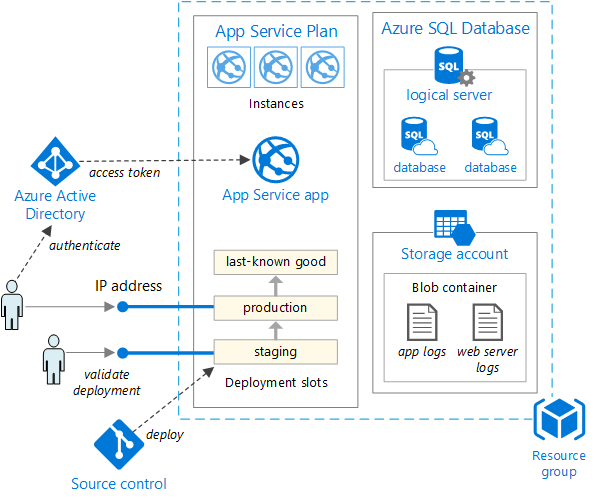
Figura 5-5. Implementación de una aplicación web en un Azure App Service
Internamente, la organización de este proyecto en varios proyectos en función de la responsabilidad mejora la capacidad de mantenimiento de la aplicación.
Esta unidad se puede escalar hacia arriba o hacia afuera para aprovechar la escalabilidad a demanda basada en la nube. El escalado vertical significa agregar cpu adicional, memoria, espacio en disco u otros recursos al servidor que hospeda la aplicación. El escalado horizontal significa agregar instancias adicionales de estos servidores, ya sean servidores físicos, máquinas virtuales o contenedores. Cuando la aplicación se hospeda en varias instancias, se usa un equilibrador de carga para asignar solicitudes a instancias de aplicación individuales.
El enfoque más sencillo para escalar una aplicación web en Azure es configurar el escalado manualmente en el plan de App Service de la aplicación. En la figura 5-6 se muestra la pantalla de panel de Azure adecuada para configurar el número de instancias que atienden una aplicación.
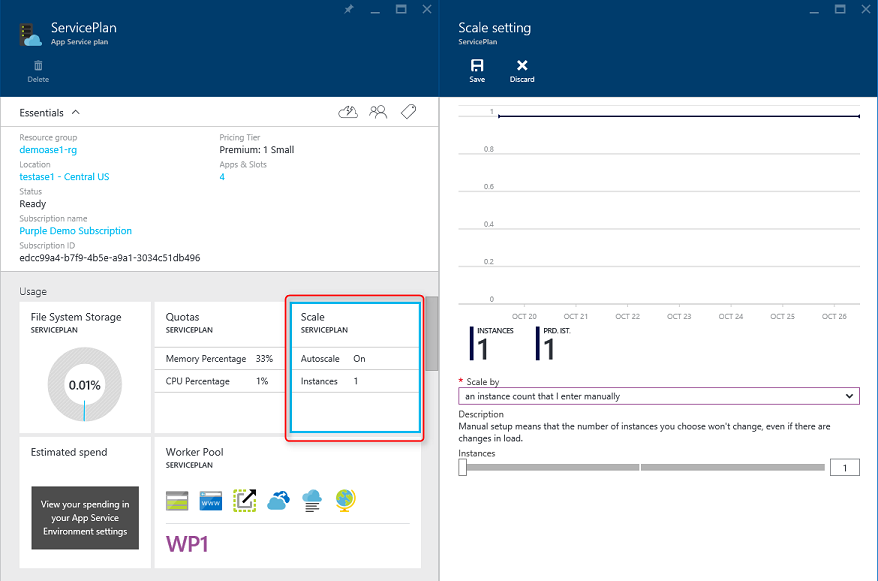
Figura 5-6. Escalamiento del plan de servicio de aplicaciones en Azure.
Arquitectura limpia
Las aplicaciones que siguen el principio de inversión de dependencias, así como los principios de diseño de Domain-Driven (DDD) tienden a llegar a una arquitectura similar. Esta arquitectura ha pasado por muchos nombres a lo largo de los años. Uno de los primeros nombres era Arquitectura hexagonal, seguido de Puertos y Adaptadores. Más recientemente, se ha citado como arquitectura cebolla o arquitectura limpia. Este último nombre, Clean Architecture, se usa como nombre para esta arquitectura en este libro electrónico.
La aplicación de referencia eShopOnWeb usa el enfoque de arquitectura limpia para organizar su código en proyectos. Puede encontrar una plantilla de solución que puede usar como punto de partida para sus propias soluciones de ASP.NET Core en el repositorio de GitHub ardalis/cleanarchitecture o instalando la plantilla desde NuGet.
La arquitectura limpia coloca la lógica de negocios y el modelo de aplicación en el centro de la aplicación. En lugar de que la lógica de negocios dependa del acceso a los datos o de otras consideraciones de infraestructura, esta dependencia se invierte: ahora los detalles de la infraestructura y la implementación dependen del núcleo de la aplicación. Esta funcionalidad se logra mediante la definición de abstracciones, o interfaces, en Application Core, que luego se implementan mediante tipos definidos en el nivel de infraestructura. Una forma común de visualizar esta arquitectura es usar una serie de círculos concéntricos, similares a una cebolla. En la figura 5-7 se muestra un ejemplo de este estilo de representación arquitectónica.
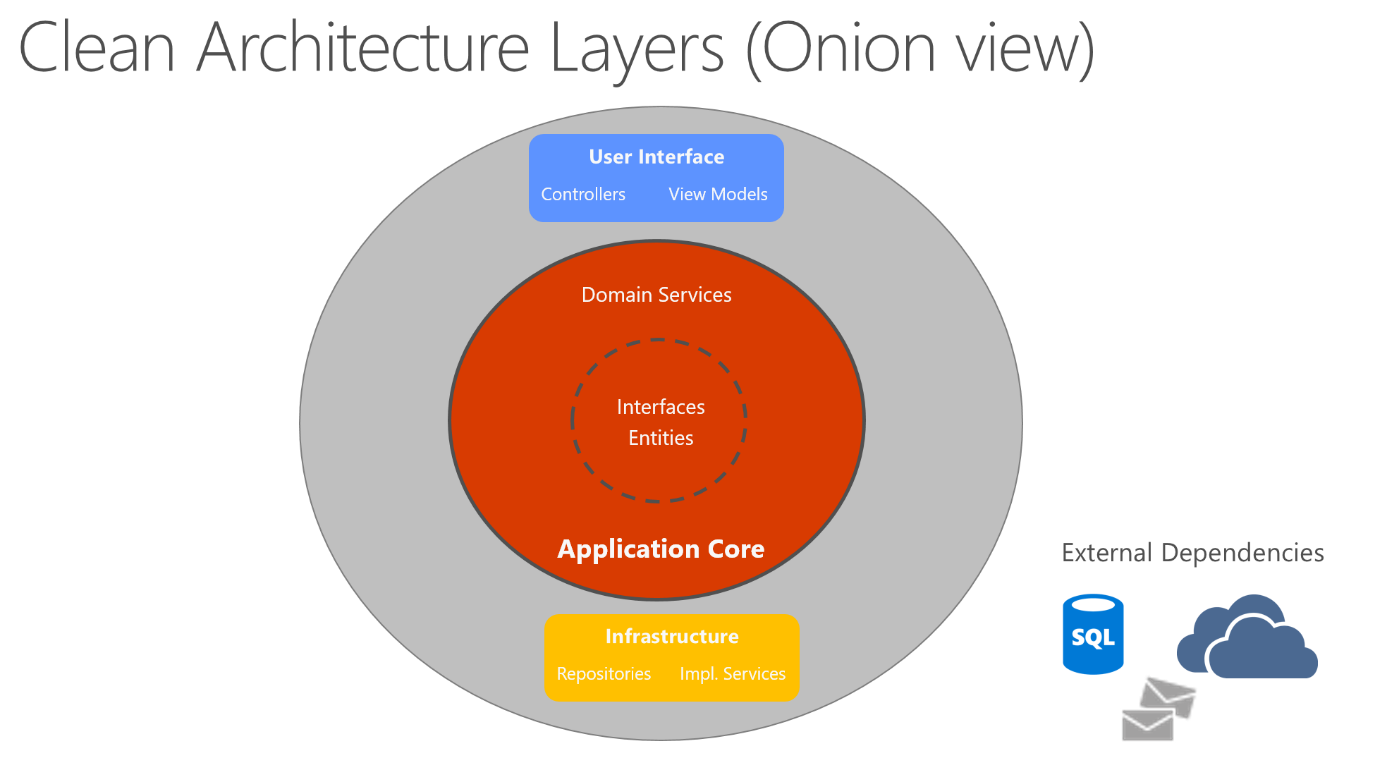
Figura 5-7. Arquitectura limpia; vista de cebolla
En este diagrama, las dependencias fluyen hacia el círculo más interno. Application Core toma su nombre de su posición en el núcleo de este diagrama. Y puede ver en el diagrama que Application Core no tiene dependencias en otras capas de aplicación. Las entidades e interfaces de la aplicación están en el centro. Justo fuera, pero aún dentro del "Application Core", se encuentran los servicios de dominio, que normalmente implementan interfaces definidas en el círculo interno. Fuera del núcleo de la aplicación, tanto la interfaz de usuario como las capas de infraestructura dependen del núcleo de la aplicación, pero no entre sí (necesariamente).
En la figura 5-8 se muestra un diagrama de capas horizontales más tradicional que refleja mejor la dependencia entre la interfaz de usuario y otras capas.
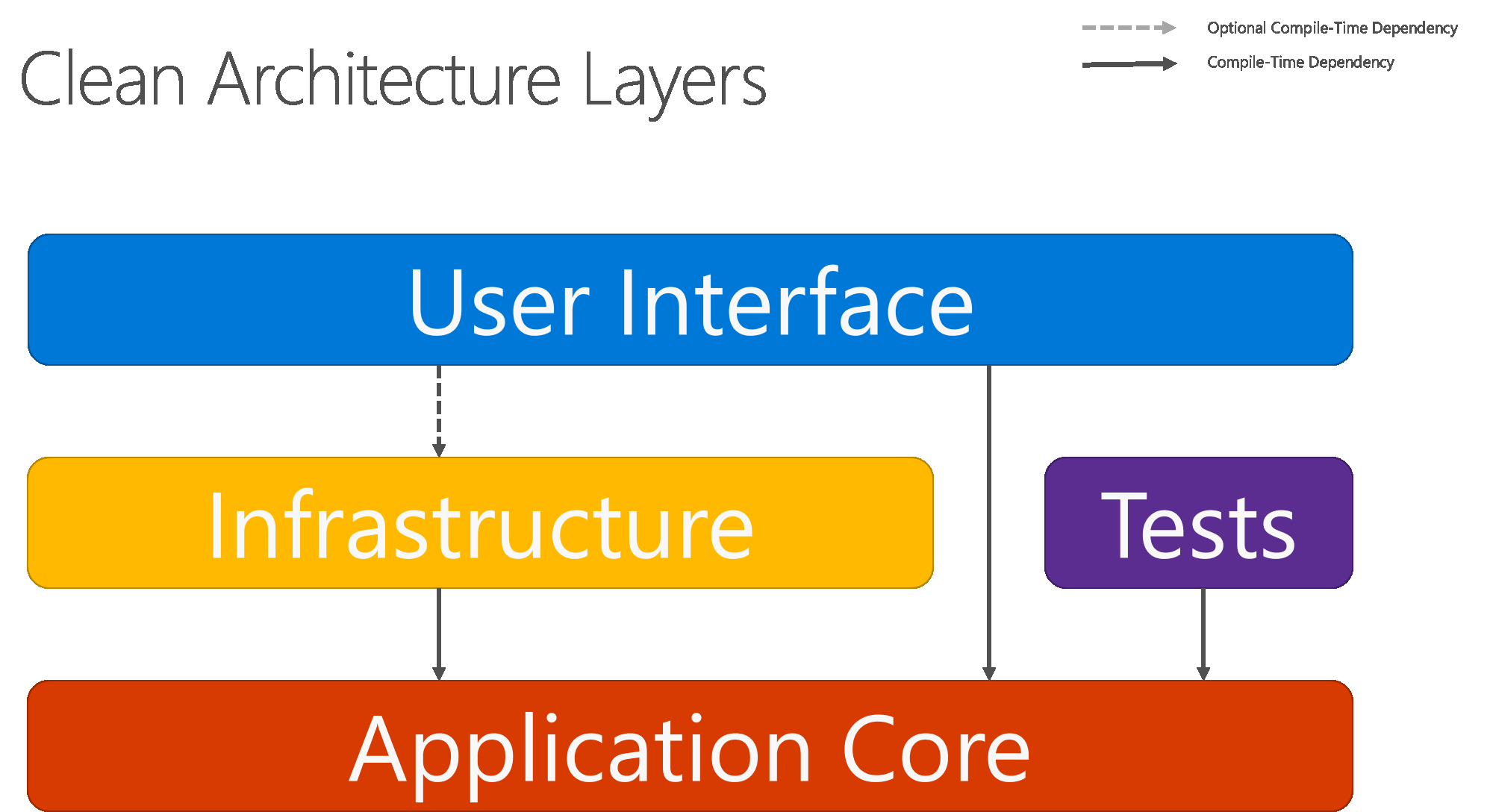
Figura 5-8. Arquitectura limpia; vista de capa horizontal
Tenga en cuenta que las flechas sólidas representan las dependencias de tiempo de compilación, mientras que la flecha discontinua representa una dependencia solo de tiempo de ejecución. Con la arquitectura limpia, la capa de interfaz de usuario funciona con interfaces definidas en Application Core en tiempo de compilación y, idealmente, no debe conocer los tipos de implementación definidos en el nivel de infraestructura. Sin embargo, en tiempo de ejecución, estos tipos de implementación son necesarios para que la aplicación se ejecute, por lo que deben estar presentes y conectados a las interfaces de Application Core a través de la inserción de dependencias.
En la figura 5-9 se muestra una vista más detallada de la arquitectura de una aplicación de ASP.NET Core cuando se compilan siguiendo estas recomendaciones.
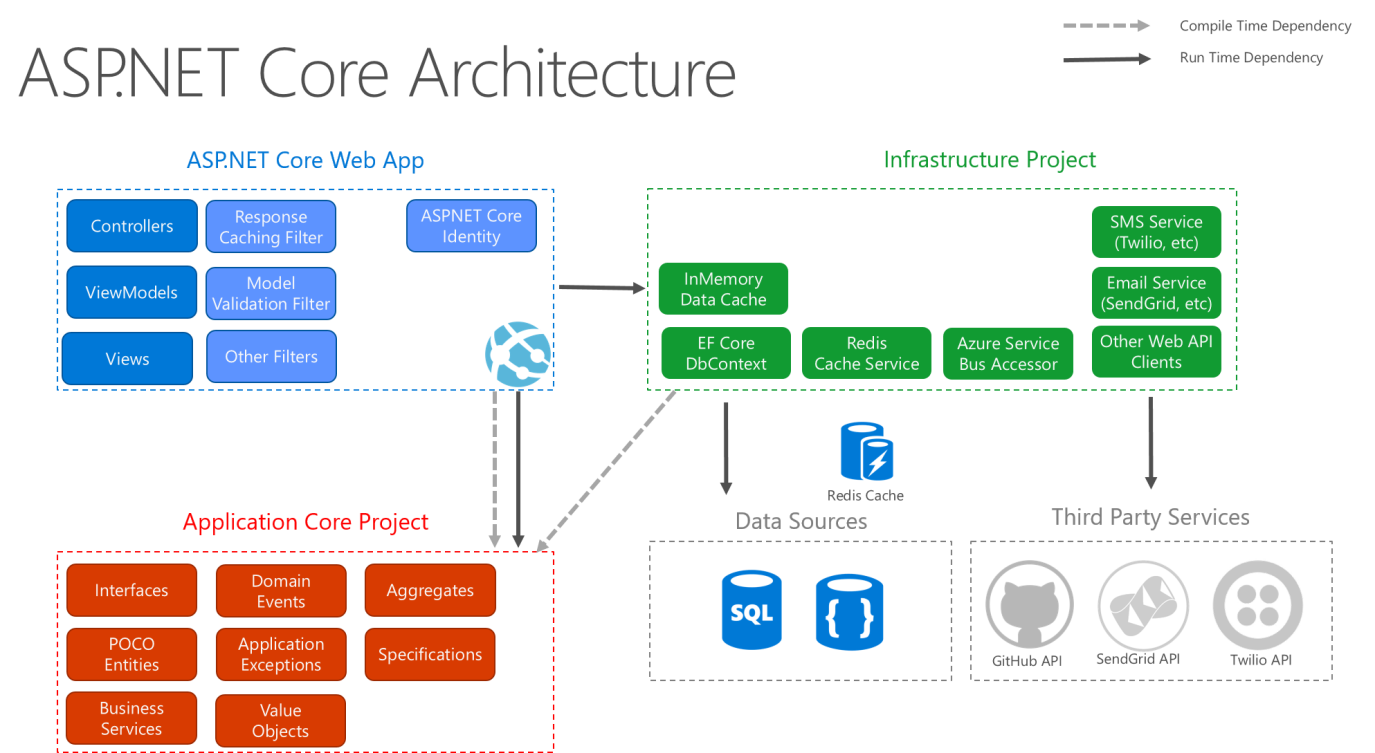
Figura 5-9. Diagrama de arquitectura de ASP.NET Core en el que se sigue la arquitectura limpia.
Dado que Application Core no depende de la infraestructura, es muy fácil escribir pruebas unitarias automatizadas para esta capa. Las figuras 5-10 y 5-11 muestran cómo encajan las pruebas en esta arquitectura.
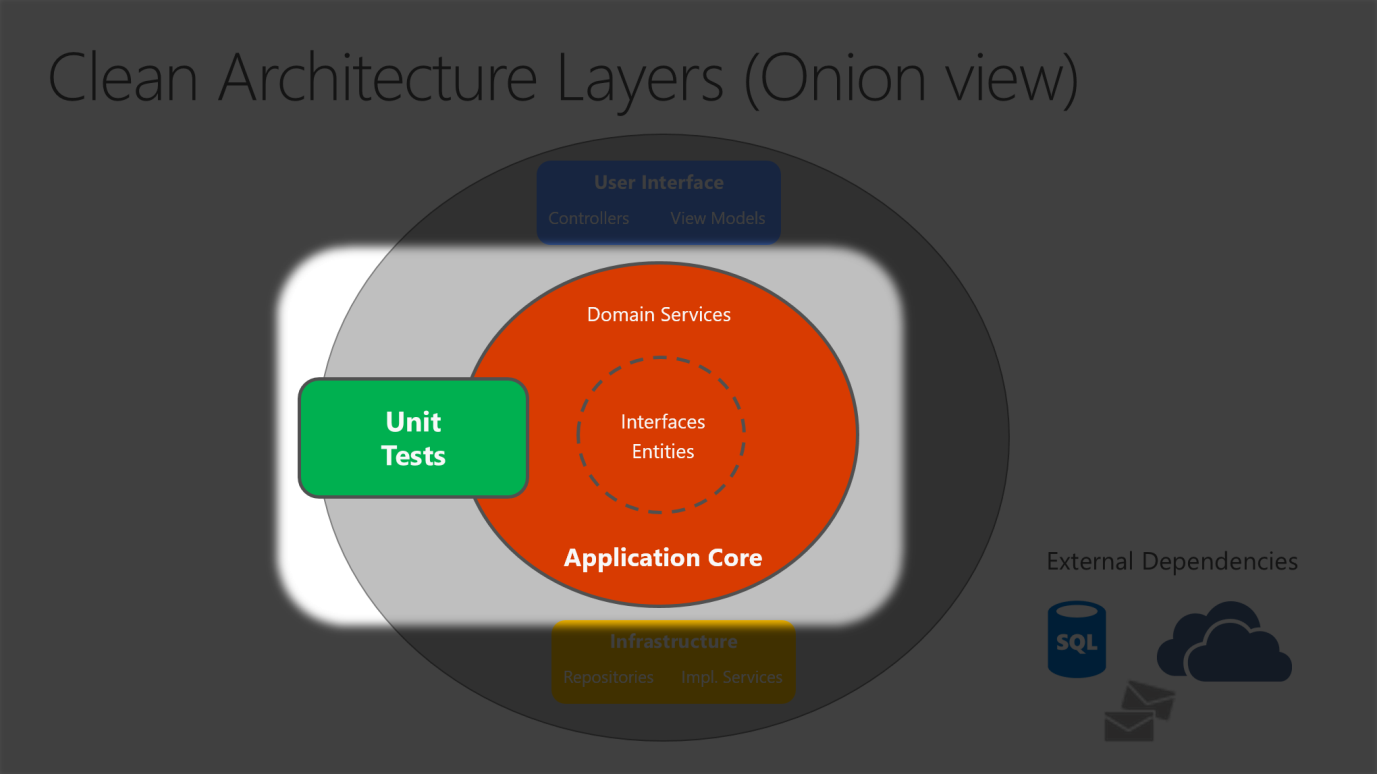
Figura 5-10. Prueba unitaria de Application Core de forma aislada.
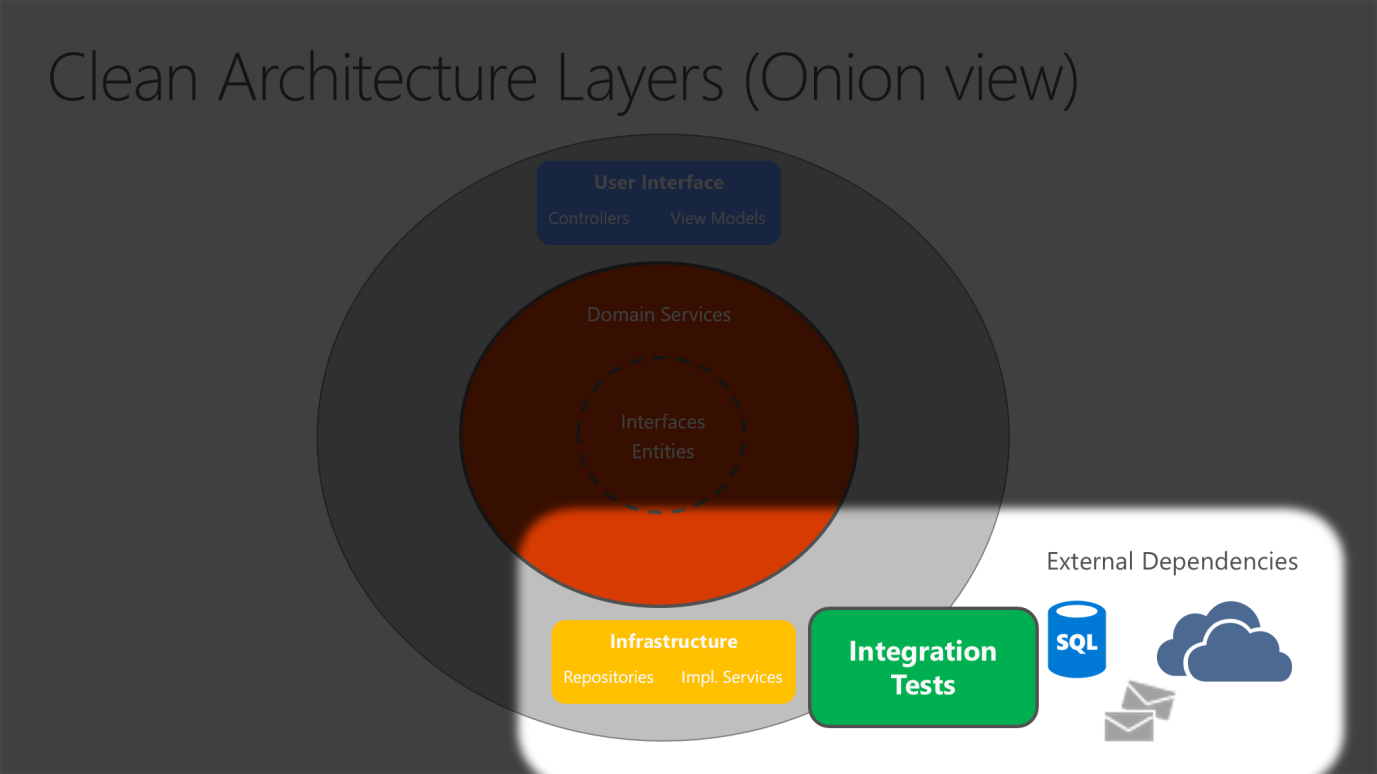
Figura 5-11. Pruebas de integración Implementaciones de infraestructura con dependencias externas.
Dado que la capa de interfaz de usuario no tiene ninguna dependencia directa de los tipos definidos en el proyecto de infraestructura, también es muy fácil intercambiar implementaciones, ya sea para facilitar las pruebas o en respuesta a los cambios en los requisitos de la aplicación. La integración incorporada en ASP.NET Core y el soporte para la inyección de dependencias hace que esta arquitectura sea la manera más adecuada de estructurar aplicaciones monolíticas no triviales.
En el caso de las aplicaciones monolíticas, los proyectos de núcleo de la aplicación, la infraestructura y la interfaz de usuario se ejecutan como una sola aplicación. La arquitectura de la aplicación en tiempo de ejecución podría tener un aspecto similar a la figura 5-12.
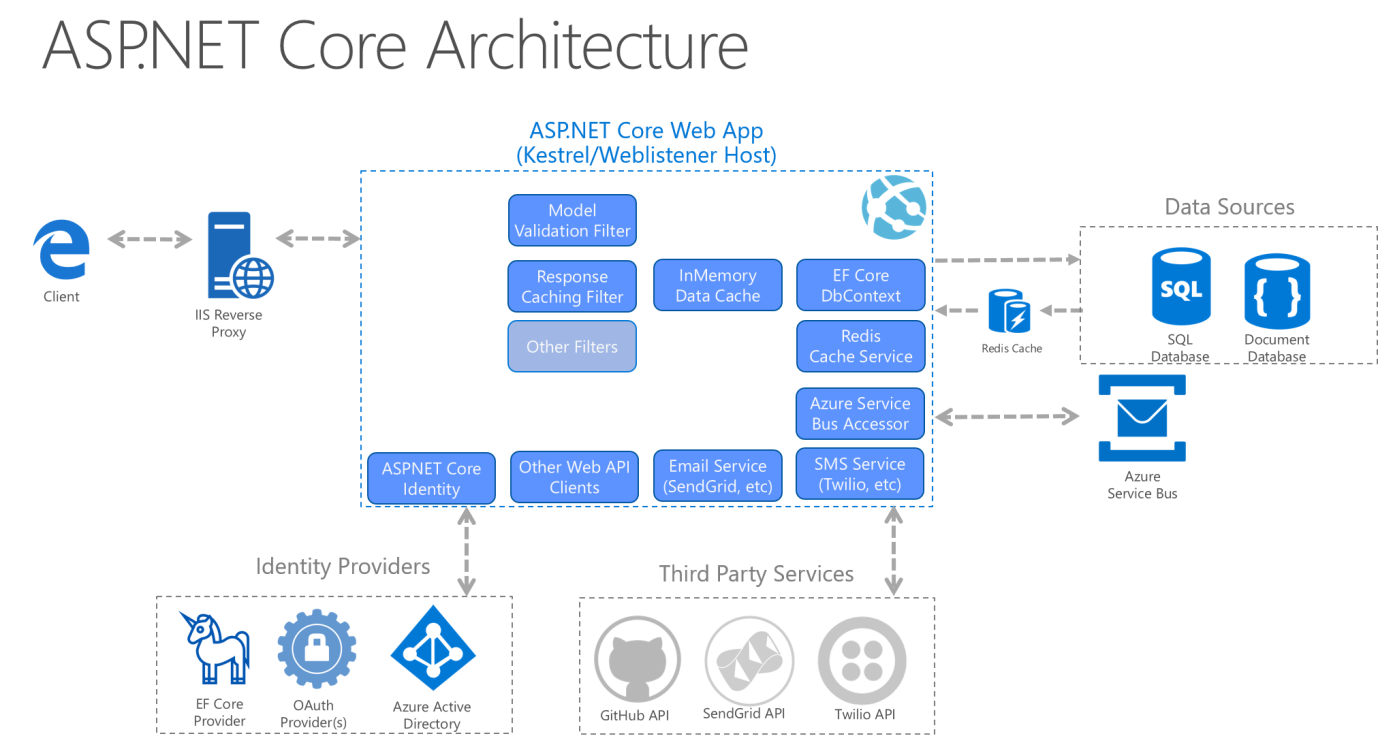
Figura 5-12. Arquitectura en tiempo de ejecución de una aplicación de ejemplo de ASP.NET Core.
Organización del código en arquitectura limpia
En una solución de arquitectura limpia, cada proyecto tiene responsabilidades claras. Por lo tanto, determinados tipos pertenecen a cada proyecto y con frecuencia encontrará carpetas correspondientes a estos tipos en el proyecto adecuado.
Núcleo de la Aplicación
Application Core contiene el modelo de negocio, que incluye entidades, servicios e interfaces. Estas interfaces incluyen abstracciones para las operaciones que se realizarán mediante infraestructura, como el acceso a datos, el acceso al sistema de archivos, las llamadas de red, etc. A veces, los servicios o interfaces definidos en esta capa tendrán que trabajar con tipos que no sean de entidad que no tengan dependencias en la interfaz de usuario o la infraestructura. Se pueden definir como objetos de transferencia de datos simples (DTO).
Tipos principales de la aplicación
- Entidades (clases de modelo de negocio que se conservan)
- Agregados (grupos de entidades)
- Interfaces
- Servicios de dominio
- Características técnicas
- Excepciones personalizadas y cláusulas de protección
- Controladores y eventos de dominio
Infraestructura
Normalmente, el proyecto de infraestructura incluye implementaciones de acceso a datos. En una aplicación web típica de ASP.NET Core, estas implementaciones incluyen Entity Framework (EF) DbContext, cualquier objeto de EF Core Migration que se haya definido y las clases de implementación de acceso a datos. La manera más común de abstraer el código de implementación de acceso a datos es mediante el uso del patrón de diseño repositorio.
Además de las implementaciones de acceso a datos, el proyecto de infraestructura debe contener implementaciones de servicios que deben interactuar con problemas de infraestructura. Estos servicios deben implementar interfaces definidas en Application Core, por lo que la infraestructura debe tener una referencia al proyecto de Application Core.
Tipos de infraestructura
- Tipos de EF Core (
DbContext,Migration) - Tipos de implementación de acceso a datos (repositorios)
- Servicios específicos de la infraestructura (por ejemplo,
FileLoggeroSmtpNotifier)
Capa de interfaz de usuario
La capa de interfaz de usuario de una aplicación ASP.NET Core MVC es el punto de entrada de la aplicación. Este proyecto debe hacer referencia al proyecto de Application Core y sus tipos deben interactuar con la infraestructura estrictamente a través de interfaces definidas en Application Core. No se debe permitir la instanciación directa ni las llamadas estáticas a los tipos de la capa de infraestructura en la capa de interfaz de usuario.
Tipos de capa de interfaz de usuario
- Controladores
- Filtros personalizados
- Middleware personalizado
- Vistas
- ViewModels
- Empresa emergente
La Startup clase o Program.cs archivo es responsable de configurar la aplicación y de conectar tipos de implementación a interfaces. El lugar donde se realiza esta lógica se conoce como raíz de composición de la aplicación y es lo que permite que la inserción de dependencias funcione correctamente en tiempo de ejecución.
Nota:
Para configurar la inyección de dependencias durante el inicio de la aplicación, es posible que el proyecto de la capa de interfaz de usuario tenga que hacer referencia al proyecto de infraestructura. Esta dependencia se puede eliminar más fácilmente mediante un contenedor de inserción de dependencias personalizado que tiene compatibilidad integrada para cargar tipos desde ensamblados. Para los fines de este ejemplo, el enfoque más sencillo es permitir que el proyecto de interfaz de usuario haga referencia al proyecto de infraestructura (pero los desarrolladores deben limitar las referencias reales a los tipos del proyecto de infraestructura a la raíz de composición de la aplicación).
Aplicaciones y contenedores monolíticos
Puede crear una aplicación web o un servicio basados en una implementación única y monolítica e implementarla como un contenedor. Dentro de la aplicación, es posible que no sea monolítico, sino organizado en varias bibliotecas, componentes o capas. Externamente, es un único contenedor con un único proceso, una sola aplicación web o un único servicio.
Para administrar este modelo, implemente un único contenedor para representar la aplicación. Para escalar, solo tiene que agregar más copias con un equilibrador de carga delante. La simplicidad procede de administrar una sola implementación en un único contenedor o máquina virtual.
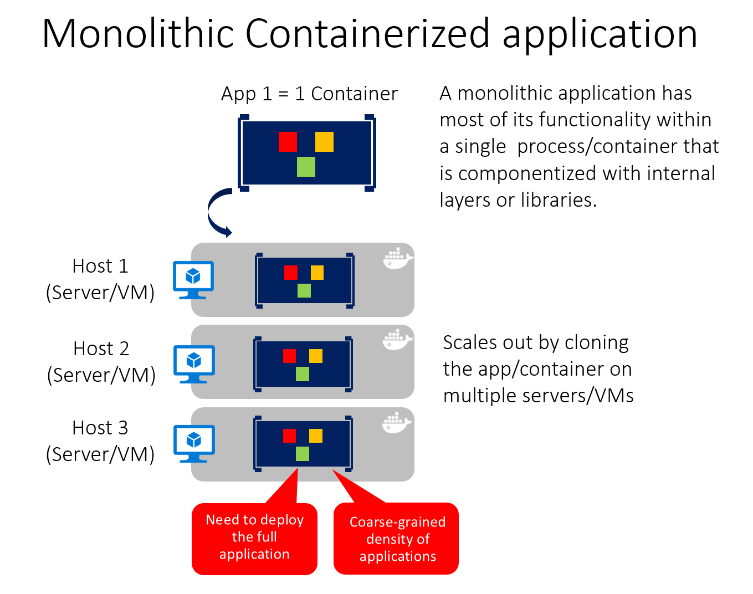
Puede incluir varios componentes o bibliotecas o capas internas dentro de cada contenedor, como se muestra en la figura 5-13. Sin embargo, siguiendo el principio de contenedor de "un contenedor hace una cosa y lo hace en un proceso", el patrón monolítico podría ser un conflicto.
La desventaja de este enfoque viene si o cuando crece la aplicación, lo que requiere que se escale. Si la aplicación se escala completamente, no será realmente un problema. Pero en la mayoría de los casos, solo algunos elementos de la aplicación son los puntos de obstrucción que deben escalarse, mientras que otros componentes se usan menos.
Utilizando el ejemplo típico de comercio electrónico, lo que es probable que necesite escalar es el componente de información del producto. Muchos más clientes examinan productos que los compran. Más clientes usan su cesta que usar la canalización de pago. Menos clientes agregan comentarios o ven su historial de compras. Y es probable que solo tenga unos pocos empleados, en una sola región, que necesiten administrar las campañas de contenido y marketing. Al escalar el diseño monolítico, todo el código se implementa varias veces.
Además del problema de "escalar todo", los cambios en un único componente requieren una nueva prueba completa de toda la aplicación y una reimplementación completa de todas las instancias.
El enfoque monolítico es común y muchas organizaciones están desarrollando con este enfoque arquitectónico. Muchos están obteniendo resultados lo suficientemente buenos, mientras que otros se están encontrando con límites. Muchos diseñaron sus aplicaciones en este modelo, ya que las herramientas y la infraestructura eran demasiado difíciles de compilar arquitecturas orientadas a servicios (SOA) y no vieron la necesidad hasta que creció la aplicación. Si encuentra que alcanza los límites del enfoque monolítico, dividir la aplicación para que pueda aprovechar mejor los contenedores y microservicios puede ser el siguiente paso lógico.
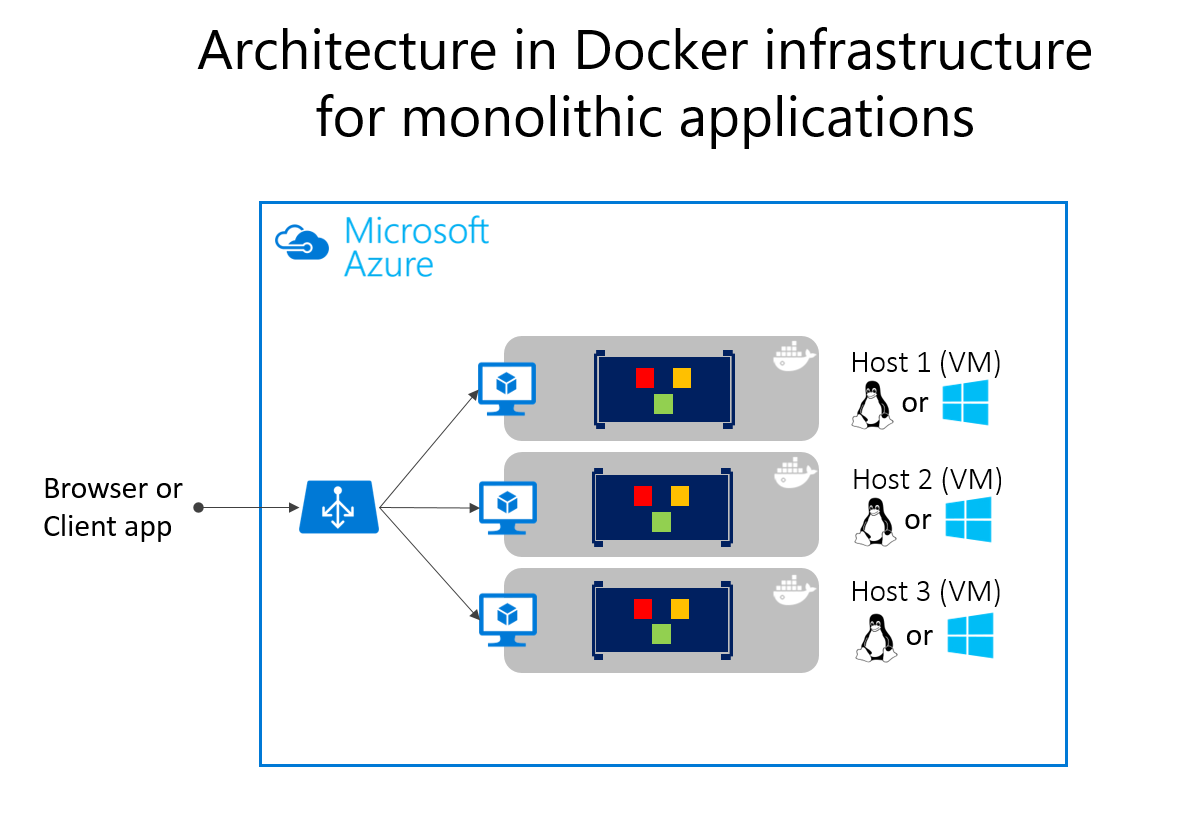
La implementación de aplicaciones monolíticas en Microsoft Azure se puede lograr mediante máquinas virtuales dedicadas para cada instancia. Con Conjuntos de escalado de máquinas virtuales de Azure, puede escalar fácilmente las máquinas virtuales. Azure App Services puede ejecutar aplicaciones monolíticas y escalar fácilmente instancias sin tener que administrar las máquinas virtuales. Azure App Services también puede ejecutar instancias únicas de contenedores de Docker, lo que simplifica la implementación. Con Docker, puede implementar una sola máquina virtual como host de Docker y ejecutar varias instancias. Con el equilibrador de Azure, como se muestra en la figura 5-14, puede administrar el escalado.
La implementación en los distintos hosts se puede administrar con técnicas de implementación tradicionales. Los hosts de Docker se pueden administrar con comandos como docker ejecutados manualmente o a través de la automatización, como canalizaciones de entrega continua (CD).
Aplicación monolítica implementada como contenedor
Existen ventajas de usar contenedores para administrar implementaciones de aplicaciones monolíticas. El escalado de las instancias de contenedores es mucho más rápido y sencillo que la implementación de máquinas virtuales adicionales. Incluso cuando se usan conjuntos de escalado de máquinas virtuales para escalar las máquinas virtuales, la creación tarda un tiempo. Cuando se implementa como instancias de aplicación, la configuración de la aplicación se administra como parte de la máquina virtual.
La implementación de actualizaciones como imágenes de Docker es mucho más rápida y eficiente en cuanto a la red. Normalmente, las imágenes de Docker se inician en segundos, lo que acelera las implementaciones. Eliminar una instancia de Docker es tan fácil como emitir un comando docker stop, que normalmente se completa en menos de un segundo.
Dado que los contenedores son intrínsecamente inmutables por diseño, nunca es necesario preocuparse por las máquinas virtuales dañadas, mientras que los scripts de actualización pueden olvidar tener en cuenta alguna configuración o archivo específicos que quedan en el disco.
Puede usar contenedores de Docker para una implementación monolítica de aplicaciones web más sencillas. Este enfoque mejora la integración continua y las canalizaciones de implementación continua y ayuda a lograr un éxito de implementación en producción. Ya no tendrá que pensar en por qué no funciona en producción, aunque sí que funcione en su equipo.
Una arquitectura basada en microservicios tiene muchas ventajas, pero estas ventajas conllevan un costo mayor de complejidad. En algunos casos, los costos superan las ventajas, por lo que una aplicación de implementación monolítica que se ejecuta en un solo contenedor o en solo unos pocos contenedores es una mejor opción.
Es posible que una aplicación monolítica no se pueda descomponer fácilmente en microservicios bien separados. Los microservicios deben funcionar independientemente entre sí para proporcionar una aplicación más resistente. Si no puede entregar segmentos de características independientes de la aplicación, separarlo solo agrega complejidad.
Es posible que una aplicación aún no necesite escalar características de forma independiente. Muchas aplicaciones, cuando necesitan escalar más allá de una sola instancia, pueden hacerlo a través del proceso relativamente simple de clonación de esa instancia completa. El trabajo adicional para separar la aplicación en servicios discretos proporciona una ventaja mínima cuando el escalado de instancias completas de la aplicación es sencillo y rentable.
Al principio del desarrollo de una aplicación, es posible que no tenga una idea clara de dónde están los límites funcionales naturales. A medida que desarrolle un producto mínimo viable, es posible que la separación natural aún no haya surgido. Algunas de estas condiciones pueden ser temporales. Puede empezar por crear una aplicación monolítica y, posteriormente, separar algunas características que se van a desarrollar e implementar como microservicios. Es posible que otras condiciones sean esenciales para el espacio de problemas de la aplicación, lo que significa que la aplicación nunca se puede dividir en varios microservicios.
La separación de una aplicación en muchos procesos discretos también presenta sobrecarga. Hay más complejidad en separar las características en distintos procesos. Los protocolos de comunicación se vuelven más complejos. En lugar de llamadas a métodos, debe usar comunicaciones asincrónicas entre servicios. Cuando cambie a una arquitectura de microservicios, deberá agregar muchos de los bloques de creación que se implementan en la versión de microservicios de la aplicación eShopOnContainers: control de bus de eventos, reintentos y resistencia de mensajes, coherencia eventual y mucho más.
La aplicación de referencia eShopOnWeb, mucho más sencilla, ofrece soporte para el uso de un contenedor monolítico único. La aplicación incluye una aplicación web que incluye vistas de MVC tradicionales, API web y Páginas de Razor. Opcionalmente, puede ejecutar el componente de administración basado en Blazor de la aplicación, que requiere que también se ejecute un proyecto de API independiente.
La aplicación se puede iniciar desde la raíz de la solución mediante los docker-compose build comandos y docker-compose up . Este comando configura un contenedor para la instancia web, mediante el Dockerfile que se encuentra en la raíz del proyecto web y ejecuta el contenedor en un puerto especificado. Puede descargar el origen de esta aplicación desde GitHub y ejecutarlo localmente. Incluso esta aplicación monolítica se beneficia de la implementación en un entorno de contenedor.
Para una, la implementación en contenedores significa que cada instancia de la aplicación se ejecuta en el mismo entorno. Este enfoque incluye el entorno de desarrollador en el que se realizan las primeras pruebas y el desarrollo. El equipo de desarrollo puede ejecutar la aplicación en un entorno contenedorizado que coincida con el entorno de producción.
Además, las aplicaciones contenedorizadas se escalan horizontalmente con un costo menor. El uso de un entorno de contenedor permite un uso compartido de recursos mayor que los entornos de máquina virtual tradicionales.
Por último, la contenedorización de la aplicación fuerza una separación entre la lógica de negocios y el servidor de almacenamiento. A medida que la aplicación se expande, todos los contenedores dependerán de un solo medio físico de almacenamiento. Este medio de almacenamiento normalmente sería un servidor de alta disponibilidad que ejecuta una base de datos de SQL Server.
Compatibilidad con Docker
El eShopOnWeb proyecto se ejecuta en .NET. Por lo tanto, puede ejecutarse en contenedores basados en Linux o basados en Windows. Tenga en cuenta que para la implementación de Docker, quiere usar el mismo tipo de host para SQL Server. Los contenedores basados en Linux permiten una superficie más pequeña y se prefieren.
Puede usar Visual Studio 2017 o posterior para agregar compatibilidad con Docker a una aplicación existente; para ello, haga clic con el botón derecho en un proyecto en el Explorador de soluciones y elija Agregar>compatibilidad con Docker. En este paso se agregan los archivos necesarios y se modifica el proyecto para usarlos. El ejemplo actual eShopOnWeb ya tiene estos archivos en su lugar.
El archivo docker-compose.yml de nivel de solución contiene información sobre qué imágenes se van a compilar y qué contenedores se van a iniciar. El archivo permite usar el docker-compose comando para iniciar varias aplicaciones al mismo tiempo. En este caso, solo se lanza el proyecto web. También puede usarlo para configurar dependencias, como un contenedor de base de datos independiente.
version: '3'
services:
eshopwebmvc:
image: eshopwebmvc
build:
context: .
dockerfile: src/Web/Dockerfile
environment:
- ASPNETCORE_ENVIRONMENT=Development
ports:
- "5106:5106"
networks:
default:
external:
name: nat
El archivo docker-compose.yml hace referencia a Dockerfile en el proyecto Web.
Dockerfile se usa para especificar qué contenedor base se usará y cómo se configurará la aplicación en él. El Web de Dockerfile:
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
WORKDIR /app
COPY *.sln .
COPY . .
WORKDIR /app/src/Web
RUN dotnet restore
RUN dotnet publish -c Release -o out
FROM mcr.microsoft.com/dotnet/aspnet:8.0 AS runtime
WORKDIR /app
COPY --from=build /app/src/Web/out ./
ENTRYPOINT ["dotnet", "Web.dll"]
Solución de problemas de Docker
Una vez que ejecute la aplicación en contenedor, seguirá ejecutándose hasta que se detenga. Puede ver qué contenedores se ejecutan con el docker ps comando . Puede detener un contenedor en ejecución mediante el docker stop comando y especificar el identificador del contenedor.
Tenga en cuenta que la ejecución de contenedores de Docker puede estar enlazada a los puertos que podría intentar usar en el entorno de desarrollo. Si intenta ejecutar o depurar una aplicación con el mismo puerto que un contenedor de Docker en ejecución, recibirá un error que indica que el servidor no se puede enlazar a ese puerto. Una vez más, detener el contenedor debe resolver el problema.
Si quiere agregar compatibilidad con Docker a la aplicación mediante Visual Studio, asegúrese de que Docker Desktop se está ejecutando al hacerlo. El asistente no se ejecutará correctamente si Docker Desktop no se está ejecutando al iniciar el asistente. Además, el asistente examina la opción de contenedor actual para agregar la compatibilidad correcta con Docker. Si quiere agregar compatibilidad con contenedores de Windows, debe ejecutar el asistente mientras tiene Docker Desktop en ejecución con contenedores de Windows configurados. Si quiere agregar compatibilidad con contenedores de Linux, ejecute el asistente mientras Docker se ejecuta con contenedores de Linux configurados.
Otros estilos de arquitectura de aplicaciones web
- Web-Queue-Worker: Los componentes principales de esta arquitectura son un front-end web que atiende solicitudes de cliente y un worker que realiza tareas que consumen muchos recursos, flujos de trabajo de ejecución prolongada o trabajos por lotes. El front-end web se comunica con el trabajador a través de una cola de mensajes.
- N niveles: una arquitectura de N niveles divide una aplicación en capas lógicas y niveles físicos.
- Microservicio: una arquitectura de microservicios consta de una colección de servicios pequeños y autónomos. Cada uno de servicio es independiente y debe implementar una funcionalidad de negocio individual dentro de un contexto delimitado.
Referencias: arquitecturas web comunes
-
Arquitectura limpia
https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html -
Arquitectura Onion
https://jeffreypalermo.com/blog/the-onion-architecture-part-1/ -
El patrón de repositorio
https://deviq.com/repository-pattern/ -
Plantilla de solución de arquitectura limpia
https://github.com/ardalis/cleanarchitecture -
Libro electrónico sobre la arquitectura de microservicios
https://aka.ms/MicroservicesEbook -
DDD ( diseño deDomain-Driven)
https://learn.microsoft.com/dotnet/architecture/microservices/microservice-ddd-cqrs-patterns/
Colaborar con nosotros en GitHub
El origen de este contenido se puede encontrar en GitHub, donde también puede crear y revisar problemas y solicitudes de incorporación de cambios. Para más información, consulte nuestra guía para colaboradores.