Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este tutorial se muestra cómo crear un recomendador de películas con ML.NET en una aplicación de consola de .NET. Los pasos usan C# y Visual Studio 2019.
En este tutorial, aprenderá a:
- Selección de un algoritmo de aprendizaje automático
- Preparación y carga de los datos
- Compilación y entrenamiento de un modelo
- Evaluación de un modelo
- Implementación y consumo de un modelo
Puede encontrar el código fuente de este tutorial en el repositorio dotnet/samples .
Flujo de trabajo de Aprendizaje automático
Usará los pasos siguientes para realizar la tarea, así como cualquier otra tarea ML.NET:
Prerrequisitos
Selección de la tarea de aprendizaje automático adecuada
Hay varias maneras de abordar problemas de recomendación, como recomendar una lista de películas o recomendar una lista de productos relacionados, pero en este caso predecirá qué clasificación (1-5) un usuario dará a una película determinada y recomendará esa película si es mayor que un umbral definido (cuanto mayor sea la clasificación, mayor será la probabilidad de que un usuario le guste una película determinada).
Creación de una aplicación de consola
Creación de un proyecto
Cree una aplicación de consola de C# denominada "MovieRecommender". Haga clic en el botón Siguiente .
Elija .NET 8 como marco de trabajo que se va a usar. Haga clic en el botón Crear.
Cree un directorio denominado Data en el proyecto para almacenar el conjunto de datos:
En el Explorador de soluciones, haga clic con el botón derecho en el proyecto y seleccione Agregar>nueva carpeta. Escriba "Datos" y seleccione Entrar.
Instale los paquetes NuGet Microsoft.ML y Microsoft.ML.Recommender:
Nota:
En este ejemplo se usa la versión estable más reciente de los paquetes NuGet mencionados a menos que se indique lo contrario.
En el Explorador de soluciones, haga clic con el botón derecho en el proyecto y seleccione Administrar paquetes NuGet. Elija "nuget.org" como origen del paquete, seleccione la pestaña Examinar , busque Microsoft.ML, seleccione el paquete de la lista y seleccione Instalar. Seleccione el botón Aceptar en el cuadro de diálogo Vista previa de cambios y, a continuación, seleccione el botón Acepto en el cuadro de diálogo Aceptación de licencia si está de acuerdo con los términos de licencia de los paquetes enumerados. Repita estos pasos para Microsoft.ML.Recommender.
Agregue las siguientes
usingdirectivas en la parte superior del archivo Program.cs :using Microsoft.ML; using Microsoft.ML.Trainers; using MovieRecommendation;
Descarga tus datos
Descargue los dos conjuntos de datos y guárdelos en la carpeta Datos que creó anteriormente:
Haga clic con el botón derecho en recommendation-ratings-train.csv y seleccione "Guardar vínculo (o Destino) Como..."
Haga clic con el botón derecho en recommendation-ratings-test.csv y seleccione "Guardar vínculo (o Destino) Como..."
Asegúrese de guardar los archivos *.csv en la carpeta Datos o después de guardarlos en otro lugar, mueva los archivos *.csv a la carpeta Datos .
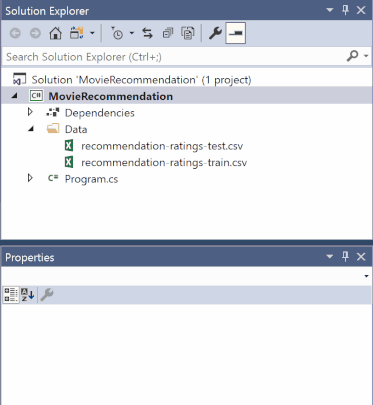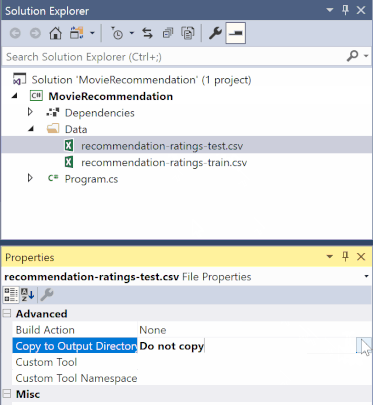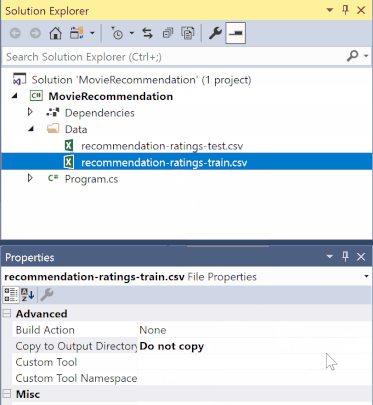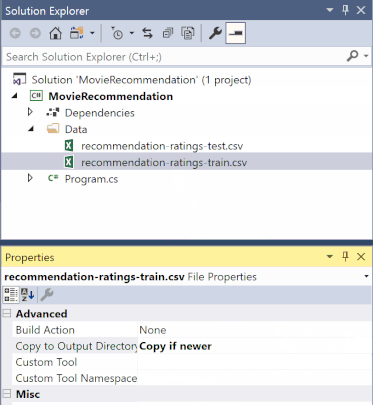
En el Explorador de soluciones, haga clic con el botón derecho en cada uno de los archivos *.csv y seleccione Propiedades. En Avanzado, cambie el valor de Copiar al directorio de salida a Copiar si es más reciente.
Carga de los datos
El primer paso del proceso de ML.NET consiste en preparar y cargar los datos de entrenamiento y pruebas del modelo.
Los datos de clasificación de recomendaciones se dividen en Train conjuntos de datos y Test . Los Train datos se usan para ajustarse al modelo. Los Test datos se usan para realizar predicciones con el modelo entrenado y evaluar el rendimiento del modelo. Es habitual tener una división de 80/20 con Train datos y Test .
A continuación se muestra una vista previa de los datos de los archivos *.csv:
En los archivos *.csv, hay cuatro columnas:
userIdmovieIdratingtimestamp
En el aprendizaje automático, las columnas que se usan para realizar una predicción se denominan Características y la columna con la predicción devuelta se denomina Etiqueta.
Quieres predecir calificaciones de películas, por lo que la columna de calificación es el Label. Las otras tres columnas, userId, movieIdy timestamp se Features usan para predecir .Label
| Características | Etiqueta |
|---|---|
userId |
rating |
movieId |
|
timestamp |
Es necesario decidir cuáles Features se usan para predecir .Label También puede usar métodos como la importancia de la característica de permutación para ayudar a seleccionar el mejor Features.
En este caso, debe eliminar la timestamp columna como un Feature porque la marca de tiempo no afecta realmente a cómo un usuario clasifica una película determinada y, por tanto, no contribuiría a realizar una predicción más precisa.
| Características | Etiqueta |
|---|---|
userId |
rating |
movieId |
A continuación, debe definir la estructura de datos para la clase de entrada.
Agregue una nueva clase al proyecto:
En el Explorador de soluciones, haga clic con el botón derecho en el proyecto y seleccione Agregar > nuevo elemento.
En el cuadro de diálogo Agregar nuevo elemento, seleccione Clase y cambie el campo Nombre a MovieRatingData.cs. A continuación, seleccione Agregar.
El archivo MovieRatingData.cs se abre en el editor de código. Agregue la siguiente using directiva a la parte superior de MovieRatingData.cs:
using Microsoft.ML.Data;
Cree una clase llamada MovieRating quitando la definición de clase existente y agregando el código siguiente en MovieRatingData.cs:
public class MovieRating
{
[LoadColumn(0)]
public float userId;
[LoadColumn(1)]
public float movieId;
[LoadColumn(2)]
public float Label;
}
MovieRating especifica una clase de datos de entrada. El atributo LoadColumn especifica qué columnas (por índice de columna) del conjunto de datos se deben cargar. Las columnas userId y movieId son sus Features (las entradas que proporcionará al modelo para predecir la Label), y la columna de calificación es la Label que predecirá (la salida del modelo).
Cree otra clase, MovieRatingPrediction, para representar los resultados previstos agregando el código siguiente después de la MovieRating clase en MovieRatingData.cs:
public class MovieRatingPrediction
{
public float Label;
public float Score;
}
En Program.cs, reemplace por Console.WriteLine("Hello World!") el código siguiente:
MLContext mlContext = new MLContext();
La clase MLContext es un punto de partida para todas las operaciones de ML.NET e inicializar mlContext crea un nuevo entorno de ML.NET que se puede compartir entre los objetos de flujo de trabajo de creación de modelos. Es similar, conceptualmente, a DBContext en Entity Framework.
En la parte inferior del archivo, cree un método denominado LoadData():
(IDataView training, IDataView test) LoadData(MLContext mlContext)
{
}
Nota:
Este método le dará un error hasta que agregue una instrucción return en los pasos siguientes.
Inicialice las variables de ruta de acceso de datos, cargue los datos de los archivos *.csv y devuelva los datos Train y Test como objetos IDataView agregando lo siguiente como la siguiente línea de código en LoadData():
var trainingDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-train.csv");
var testDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-test.csv");
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<MovieRating>(trainingDataPath, hasHeader: true, separatorChar: ',');
IDataView testDataView = mlContext.Data.LoadFromTextFile<MovieRating>(testDataPath, hasHeader: true, separatorChar: ',');
return (trainingDataView, testDataView);
Los datos de ML.NET se representan como una interfaz IDataView.
IDataView es una manera flexible y eficaz de describir datos tabulares (numéricos y texto). Los datos se pueden cargar desde un archivo de texto o en tiempo real (por ejemplo, archivos de base de datos SQL o de registro) en un IDataView objeto .
LoadFromTextFile() define el esquema de datos y lee en el archivo. Toma las variables de ruta de acceso de datos y devuelve un IDataView. En este caso, proporciona la ruta de acceso para los Test archivos y Train e indica el encabezado del archivo de texto (para que pueda usar los nombres de columna correctamente) y el separador de datos de caracteres de coma (el separador predeterminado es una pestaña).
Agregue el código siguiente para llamar LoadData() al método y devolver los Train datos y Test :
(IDataView trainingDataView, IDataView testDataView) = LoadData(mlContext);
Compilación y entrenamiento del modelo
Cree el BuildAndTrainModel() método , justo después del LoadData() método , con el código siguiente:
ITransformer BuildAndTrainModel(MLContext mlContext, IDataView trainingDataView)
{
}
Nota:
Este método le dará un error hasta que agregue una instrucción return en los pasos siguientes.
Para definir las transformaciones de datos, agregue el código siguiente a BuildAndTrainModel():
IEstimator<ITransformer> estimator = mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "userIdEncoded", inputColumnName: "userId")
.Append(mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "movieIdEncoded", inputColumnName: "movieId"));
Dado que userId y movieId representan usuarios y títulos de películas, no valores reales, se usa el método MapValueToKey() para transformar cada userId y cada movieId en una columna de tipo Feature de clave numérica (un formato aceptado por algoritmos de recomendación) y agregarlos como nuevas columnas del conjunto de datos.
| userId | movieId | Etiqueta | userIdEncoded | movieIdEncoded |
|---|---|---|---|---|
| 1 | 1 | 4 | userKey1 | movieKey1 |
| 1 | 3 | 4 | userKey1 | movieKey2 |
| 1 | 6 | 4 | ClaveDeUsuario1 | movieKey3 |
Elija el algoritmo de aprendizaje automático y anexe a las definiciones de transformación de datos agregando lo siguiente como la siguiente línea de código en BuildAndTrainModel():
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
var trainerEstimator = estimator.Append(mlContext.Recommendation().Trainers.MatrixFactorization(options));
MatrixFactorizationTrainer es el algoritmo de entrenamiento de recomendaciones. La factorización de matriz es un enfoque común para la recomendación cuando tiene datos sobre cómo los usuarios han clasificado los productos en el pasado, que es el caso de los conjuntos de datos de este tutorial. Hay otros algoritmos de recomendación para cuando tiene datos diferentes disponibles (consulte la sección Otros algoritmos de recomendación a continuación para obtener más información).
En este caso, el Matrix Factorization algoritmo usa un método denominado "filtrado colaborativo", que supone que si el usuario 1 tiene la misma opinión que el usuario 2 en un problema determinado, es más probable que el usuario 1 se sienta igual que el usuario 2 sobre un problema diferente.
Por ejemplo, si el usuario 1 y el usuario 2 valoran películas de forma similar, es más probable que el usuario 2 disfrute de una película que el usuario 1 ha visto y valorado altamente:
Incredibles 2 (2018) |
The Avengers (2012) |
Guardians of the Galaxy (2014) |
|
|---|---|---|---|
| Usuario 1 | Películas vistos y gustadas | Películas vistos y gustadas | Películas vistos y gustadas |
| Usuario 2 | Películas vistos y gustadas | Películas vistos y gustadas | No ha visto -- RECOMMEND movie |
El Matrix Factorization instructor tiene varias opciones, que puede leer más sobre en la sección Hiperparámetros de algoritmo a continuación.
Ajuste el modelo a los Train datos y devuelva el modelo entrenado agregando lo siguiente como la siguiente línea de código en el BuildAndTrainModel() método :
Console.WriteLine("=============== Training the model ===============");
ITransformer model = trainerEstimator.Fit(trainingDataView);
return model;
El método Fit() entrena el modelo con el conjunto de datos de entrenamiento proporcionado. Técnicamente, ejecuta las definiciones mediante la Estimator transformación de los datos y la aplicación del entrenamiento, y devuelve el modelo entrenado, que es .Transformer
Para obtener más información sobre el flujo de trabajo de entrenamiento del modelo en ML.NET, consulte ¿Qué es ML.NET y cómo funciona?.
Agregue lo siguiente como la siguiente línea de código debajo de la llamada al LoadData() método para llamar BuildAndTrainModel() al método y devolver el modelo entrenado:
ITransformer model = BuildAndTrainModel(mlContext, trainingDataView);
Evaluación del modelo
Una vez que haya entrenado el modelo, use los datos de prueba para evaluar el rendimiento del modelo.
Cree el EvaluateModel() método , justo después del BuildAndTrainModel() método , con el código siguiente:
void EvaluateModel(MLContext mlContext, IDataView testDataView, ITransformer model)
{
}
Transforme los Test datos agregando el código siguiente a EvaluateModel():
Console.WriteLine("=============== Evaluating the model ===============");
var prediction = model.Transform(testDataView);
El método Transform() realiza predicciones para varias filas de entrada proporcionadas de un conjunto de datos de prueba.
Evalúe el modelo agregando lo siguiente como la siguiente línea de código en el EvaluateModel() método :
var metrics = mlContext.Regression.Evaluate(prediction, labelColumnName: "Label", scoreColumnName: "Score");
Una vez que tenga el conjunto de predicciones, el método Evaluate() evalúa el modelo, que compara los valores previstos con el real Labels en el conjunto de datos de prueba y devuelve métricas sobre cómo funciona el modelo.
Imprima las métricas de evaluación en la consola agregando lo siguiente como la siguiente línea de código en el EvaluateModel() método :
Console.WriteLine("Root Mean Squared Error : " + metrics.RootMeanSquaredError.ToString());
Console.WriteLine("RSquared: " + metrics.RSquared.ToString());
Agregue lo siguiente como la siguiente línea de código debajo de la llamada al BuildAndTrainModel() método para llamar EvaluateModel() al método :
EvaluateModel(mlContext, testDataView, model);
La salida hasta ahora debería ser similar al texto siguiente:
=============== Training the model ===============
iter tr_rmse obj
0 1.5403 3.1262e+05
1 0.9221 1.6030e+05
2 0.8687 1.5046e+05
3 0.8416 1.4584e+05
4 0.8142 1.4209e+05
5 0.7849 1.3907e+05
6 0.7544 1.3594e+05
7 0.7266 1.3361e+05
8 0.6987 1.3110e+05
9 0.6751 1.2948e+05
10 0.6530 1.2766e+05
11 0.6350 1.2644e+05
12 0.6197 1.2541e+05
13 0.6067 1.2470e+05
14 0.5953 1.2382e+05
15 0.5871 1.2342e+05
16 0.5781 1.2279e+05
17 0.5713 1.2240e+05
18 0.5660 1.2230e+05
19 0.5592 1.2179e+05
=============== Evaluating the model ===============
Rms: 0.994051469730769
RSquared: 0.412556298844873
En esta salida, hay 20 iteraciones. En cada iteración, la medida de error disminuye y converge más cerca de 0.
El root of mean squared error (RMS o RMSE) se usa para medir las diferencias entre los valores previstos del modelo y los valores observados del conjunto de datos de prueba. Técnicamente es la raíz cuadrada del promedio de los cuadrados de los errores. Cuanto menor sea, mejor será el modelo.
R Squared indica cómo se ajustan los datos a un modelo. Oscila entre 0 y 1. Un valor de 0 significa que los datos son aleatorios o, de lo contrario, no se pueden ajustar al modelo. Un valor de 1 significa que el modelo coincide exactamente con los datos. Quieres que tu R Squared puntuación esté lo más cerca posible de 1.
La creación de modelos correctos es un proceso iterativo. Este modelo tiene una calidad inferior inicial, ya que el tutorial usa conjuntos de datos pequeños para proporcionar entrenamiento rápido del modelo. Si no está satisfecho con la calidad del modelo, puede intentar mejorarlo proporcionando conjuntos de datos de entrenamiento más grandes o eligiendo algoritmos de entrenamiento diferentes con distintos hiperparámetres para cada algoritmo. Para obtener más información, consulte la sección Mejorar el modelo a continuación.
Usar el modelo
Ahora puede usar el modelo entrenado para realizar predicciones sobre nuevos datos.
Cree el UseModelForSinglePrediction() método , justo después del EvaluateModel() método , con el código siguiente:
void UseModelForSinglePrediction(MLContext mlContext, ITransformer model)
{
}
PredictionEngine Use para predecir la clasificación agregando el código siguiente a UseModelForSinglePrediction():
Console.WriteLine("=============== Making a prediction ===============");
var predictionEngine = mlContext.Model.CreatePredictionEngine<MovieRating, MovieRatingPrediction>(model);
PredictionEngine es una API útil, que permite realizar una predicción en una sola instancia de datos.
PredictionEngine no es seguro para subprocesos. Es aceptable usarlo en entornos de un solo hilo o en prototipos. Para mejorar el rendimiento y la seguridad de los subprocesos en entornos de producción, use el PredictionEnginePool servicio , que crea un ObjectPool de PredictionEngine objetos para su uso en toda la aplicación. Consulte esta guía sobre cómo usar PredictionEnginePool en una API web de ASP.NET Core.
Nota:
PredictionEnginePool la extensión de servicio está actualmente en versión preliminar.
Cree una instancia de MovieRating llamada testInput y pásela al motor de predicción agregando lo siguiente como las siguientes líneas de código en el UseModelForSinglePrediction() método :
var testInput = new MovieRating { userId = 6, movieId = 10 };
var movieRatingPrediction = predictionEngine.Predict(testInput);
La función Predict() realiza una predicción en una sola columna de datos.
A continuación, puede usar la Scoreclasificación predicha para determinar si desea recomendar la película con movieId 10 al usuario 6. Cuanto mayor sea , Scoremayor será la probabilidad de que un usuario prefiera una película determinada. En este caso, supongamos que recomienda películas con una clasificación predicha de > 3,5.
Para imprimir los resultados, agregue lo siguiente como las siguientes líneas de código en el UseModelForSinglePrediction() método :
if (Math.Round(movieRatingPrediction.Score, 1) > 3.5)
{
Console.WriteLine("Movie " + testInput.movieId + " is recommended for user " + testInput.userId);
}
else
{
Console.WriteLine("Movie " + testInput.movieId + " is not recommended for user " + testInput.userId);
}
Agregue lo siguiente como la siguiente línea de código después de la llamada al EvaluateModel() método para llamar UseModelForSinglePrediction() al método :
UseModelForSinglePrediction(mlContext, model);
La salida de este método debe tener un aspecto similar al texto siguiente:
=============== Making a prediction ===============
Movie 10 is recommended for user 6
Guardar el modelo
Para usar el modelo para realizar predicciones en aplicaciones de usuario final, primero debe guardar el modelo.
Cree el SaveModel() método , justo después del UseModelForSinglePrediction() método , con el código siguiente:
void SaveModel(MLContext mlContext, DataViewSchema trainingDataViewSchema, ITransformer model)
{
}
Guarde el modelo entrenado agregando el código siguiente en el SaveModel() método :
var modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "MovieRecommenderModel.zip");
Console.WriteLine("=============== Saving the model to a file ===============");
mlContext.Model.Save(model, trainingDataViewSchema, modelPath);
Este método guarda el modelo entrenado en un archivo .zip (en la carpeta "Datos"), que luego se puede usar en otras aplicaciones de .NET para realizar predicciones.
Agregue lo siguiente como la siguiente línea de código después de la llamada al UseModelForSinglePrediction() método para llamar SaveModel() al método :
SaveModel(mlContext, trainingDataView.Schema, model);
Uso del modelo guardado
Una vez que haya guardado el modelo entrenado, puede utilizar el modelo en distintos entornos. Consulte Guardar y cargar modelos entrenados para obtener información sobre cómo poner en funcionamiento un modelo de Machine Learning entrenado en aplicaciones.
Results
Después de seguir los pasos anteriores, ejecute la aplicación de consola (Ctrl + F5). Los resultados de la predicción única anterior deben ser similares a los siguientes. Es posible que vea advertencias o mensajes de procesamiento, pero estos mensajes se han quitado de los siguientes resultados para mayor claridad.
=============== Training the model ===============
iter tr_rmse obj
0 1.5382 3.1213e+05
1 0.9223 1.6051e+05
2 0.8691 1.5050e+05
3 0.8413 1.4576e+05
4 0.8145 1.4208e+05
5 0.7848 1.3895e+05
6 0.7552 1.3613e+05
7 0.7259 1.3357e+05
8 0.6987 1.3121e+05
9 0.6747 1.2949e+05
10 0.6533 1.2766e+05
11 0.6353 1.2636e+05
12 0.6209 1.2561e+05
13 0.6072 1.2462e+05
14 0.5965 1.2394e+05
15 0.5868 1.2352e+05
16 0.5782 1.2279e+05
17 0.5713 1.2227e+05
18 0.5637 1.2190e+05
19 0.5604 1.2178e+05
=============== Evaluating the model ===============
Rms: 0.977175077487166
RSquared: 0.43233349213192
=============== Making a prediction ===============
Movie 10 is recommended for user 6
=============== Saving the model to a file ===============
¡Felicidades! Has construido con éxito un modelo de aprendizaje automático para recomendar películas. Puede encontrar el código fuente de este tutorial en el repositorio dotnet/samples .
Mejora del modelo
Hay varias maneras de mejorar el rendimiento del modelo para que pueda obtener predicciones más precisas.
Data
Agregar más datos de entrenamiento que tengan suficientes ejemplos para cada usuario y identificador de película puede ayudar a mejorar la calidad del modelo de recomendación.
La validación cruzada es una técnica para evaluar modelos que dividen aleatoriamente los datos en subconjuntos (en lugar de extraer datos de prueba del conjunto de datos como lo hizo en este tutorial) y toma algunos de los grupos como datos de entrenamiento y algunos de los grupos como datos de prueba. Este método supera el rendimiento de la división de una prueba de entrenamiento en términos de calidad del modelo.
Características
En este tutorial, solo usará los tres Features (user id, movie idy rating) proporcionados por el conjunto de datos.
Aunque esto es un buen comienzo, en realidad es posible que quiera agregar otros atributos o Features (por ejemplo, edad, sexo, ubicación geográfica, etc.) si se incluyen en el conjunto de datos. Agregar más relevante Features puede ayudar a mejorar el rendimiento del modelo de recomendación.
Si no está seguro acerca de cuál Features podría ser el más relevante para la tarea de aprendizaje automático, también puede usar el cálculo de contribución de características (FCC) y la importancia de las características de permutación, que ML.NET proporciona para descubrir el más influyente Features.
Hiperparámetros de algoritmo
Aunque ML.NET proporciona buenos algoritmos de entrenamiento predeterminados, puede ajustar aún más el rendimiento cambiando los hiperparámetros del algoritmo.
Para Matrix Factorization, puede experimentar con hiperparámetros como NumberOfIterations y ApproximationRank para ver si eso le da mejores resultados.
Por ejemplo, en este tutorial, las opciones de algoritmo son:
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
Otros algoritmos de recomendación
El algoritmo de factorización de matriz con filtrado colaborativo es solo un enfoque para realizar recomendaciones de películas. En muchos casos, es posible que no tenga los datos de clasificaciones disponibles y que solo tenga historial de películas disponible de los usuarios. En otros casos, puede tener más que solo los datos de evaluación del usuario.
| Algoritmo | Scenario | Ejemplo |
|---|---|---|
| Factorización de matriz de una clase | Úselo cuando solo tenga userId y movieId. Este estilo de recomendación se basa en el escenario de compra conjunta o en los productos que se compran con frecuencia, lo que significa que recomendará a los clientes un conjunto de productos basados en su propio historial de pedidos de compra. | >Pruébelo |
| Máquinas de Factorización Sensibles a Campos | Úselo para realizar recomendaciones cuando tenga más características más allá de userId, productId y rating (por ejemplo, descripción del producto o precio del producto). Este método también usa un enfoque de filtrado colaborativo. | >Pruébelo |
Nuevo escenario de usuario
Un problema común en el filtrado colaborativo es el problema de inicio en frío, que es cuando tiene un nuevo usuario sin datos anteriores para extraer inferencias. Este problema suele resolverse pidiendo a los nuevos usuarios que creen un perfil y, por ejemplo, valorar películas que han visto en el pasado. Aunque este método pone cierta carga al usuario, proporciona algunos datos iniciales para los nuevos usuarios sin historial de clasificación.
Recursos
Los datos usados en este tutorial se derivan del conjunto de datos MovieLens.
Pasos siguientes
En este tutorial, ha aprendido a:
- Selección de un algoritmo de aprendizaje automático
- Preparación y carga de los datos
- Compilación y entrenamiento de un modelo
- Evaluación de un modelo
- Implementación y consumo de un modelo
Avance al siguiente tutorial para obtener más información
Colaborar con nosotros en GitHub
El origen de este contenido se puede encontrar en GitHub, donde también puede crear y revisar problemas y solicitudes de incorporación de cambios. Para más información, consulte nuestra guía para colaboradores.