Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
La extensión de Visual Studio Code para Fabric Data Engineering admite completamente las operaciones de definición de trabajos de Spark, como crear, leer, actualizar y eliminar (CRUD) en Fabric. Después de crear una definición de trabajo de Spark, puede cargar más bibliotecas a las que se hace referencia, enviar una solicitud para ejecutar la definición de trabajo de Spark y comprobar el historial de ejecución.
Creación de una definición de trabajo de Spark
Para crear una nueva definición de trabajo de Spark:
En el Explorador de VS Code, seleccione la opción Crear definición de trabajo de Spark.

Escriba los campos necesarios iniciales: nombre, lakehouse de referencia y lakehouse predeterminado.
Los procesos de solicitud y el nombre de la definición de trabajo de Spark recién creada aparece en el nodo raíz Definición de trabajo de Spark en el Explorador de VS Code. En el nodo de la definición de trabajo de Spark, verás tres subnodos:
- Archivos: lista del archivo de definición principal y otras bibliotecas a las que se hace referencia. Puede cargar nuevos archivos de esta lista.
-
Almacén de lago: lista de todos los almacenes de lago a los que hace referencia esta definición de trabajo de Spark. El lakehouse predeterminado está indicado en la lista, y puede acceder a él a través de la ruta de acceso relativa
Files/…, Tables/…. - Ejecutar: lista del historial de ejecución de esta definición de trabajo de Spark y el estado del trabajo de cada ejecución.

Carga de un archivo de definición principal en una biblioteca a la que se hace referencia
Para cargar o sobrescribir el archivo de definición principal, seleccione la opción Agregar archivo principal.

Para cargar el archivo de biblioteca al que se hace referencia en el archivo de definición principal, seleccione la opción Agregar archivo de biblioteca.

Después de cargar un archivo, puede invalidarlo haciendo clic en la opción Actualizar archivo y cargando un nuevo archivo, o puede eliminar el archivo a través de la opción Eliminar.

Envío de una solicitud de ejecución
Para enviar una solicitud para ejecutar la definición de trabajo de Spark desde VS Code:
En las opciones a la derecha del nombre de la definición de trabajo de Spark que desea ejecutar, seleccione la opción Ejecutar trabajo de Spark.

Después de enviar la solicitud, aparece una nueva aplicación de Apache Spark en el nodo Ejecuciones de la lista Explorador. Para cancelar el trabajo en ejecución, seleccione la opción Cancelar trabajo de Spark.
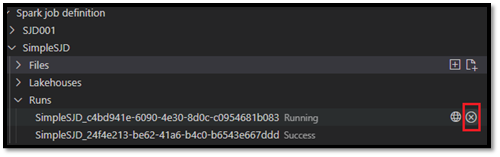


Apertura de una definición de trabajo de Spark en el portal de Fabric
Para abrir la página de creación de la definición de trabajo de Spark en el portal de Fabric, seleccione la opción Abrir en el explorador.
También puede seleccionar Abrir en el explorador junto a una ejecución completada para ver la página de supervisión detallada de esa ejecución.

Depurar el código fuente de la definición de tarea de Spark (Python)
Si la definición de trabajo de Spark se crea con PySpark (Python), puede descargar el script .py del archivo de definición principal y el archivo al que se hace referencia y depurar el script de origen en VS Code.
Para descargar el código fuente, seleccione la opción Depurar definición de trabajo de Spark a la derecha de la definición de trabajo de Spark.

Una vez completada la descarga, se abre automáticamente la carpeta del código fuente.
Seleccione la opción Confiar en los autores cuando se le solicite. (Esta opción solo aparece la primera vez que abre la carpeta. Si no selecciona esta opción, no puede depurar ni ejecutar el script de origen. Para obtener más información, consulte Seguridad de Confianza del área de trabajo de Visual Studio Code.)
Si ha descargado el código fuente antes, se le pedirá que confirme que la quiere sobrescribir la versión local con la nueva descarga.
Nota:
En la carpeta raíz del script de origen, el sistema crea una subcarpeta denominada conf. Dentro de esta carpeta, un archivo denominado light-config.json contiene algunos metadatos del sistema necesarios para la ejecución remota. NO realice ningún cambio en él.
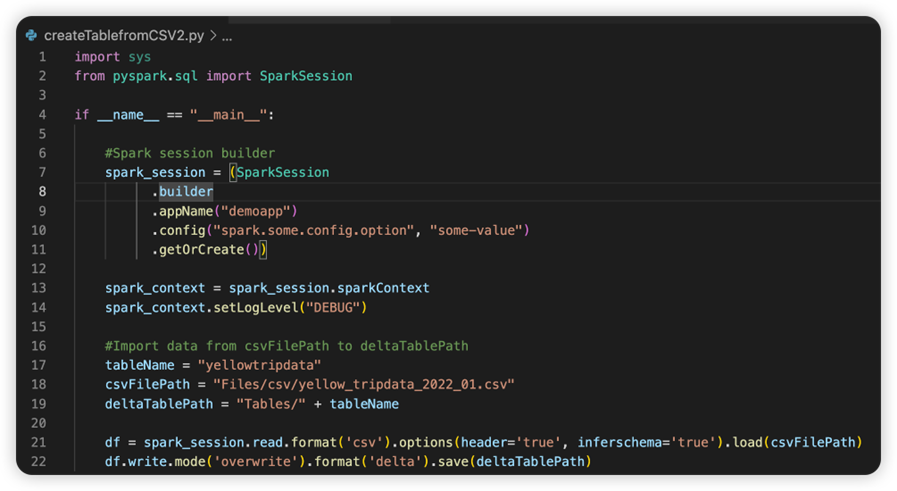
El archivo denominado sparkconf.py contiene un fragmento de código que debe agregar para configurar el objeto SparkConf. Para habilitar la depuración remota, asegúrese de que el objeto SparkConf está configurado correctamente. En la imagen siguiente se muestra la versión original del código fuente.
La siguiente imagen es el código fuente actualizado después de copiar y pegar el fragmento de código.
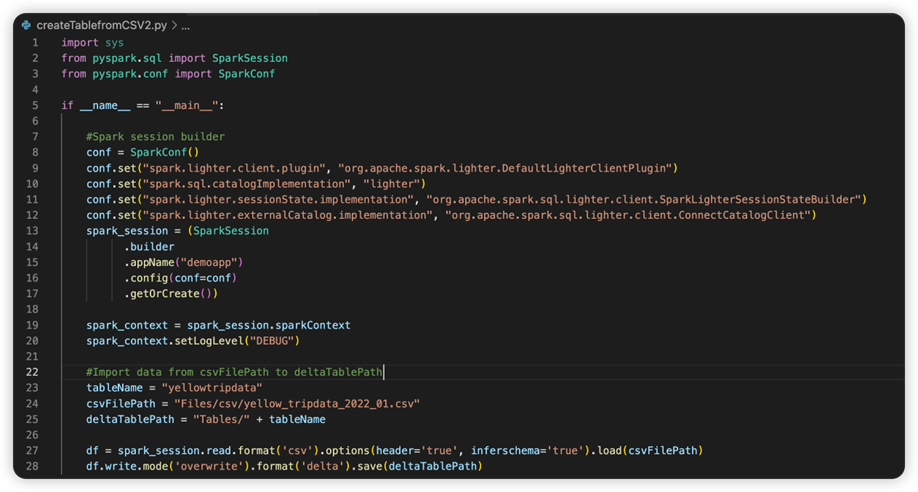
Después de actualizar el código fuente con la configuración necesaria, debe elegir el intérprete de Python adecuado. Asegúrese de seleccionar el que está instalado en el entorno synapse-spark-kernel de conda.



Editar las propiedades de definición de trabajo de Spark
Puede editar las propiedades detalladas de las definiciones de trabajo de Spark, como los argumentos de la línea de comandos.
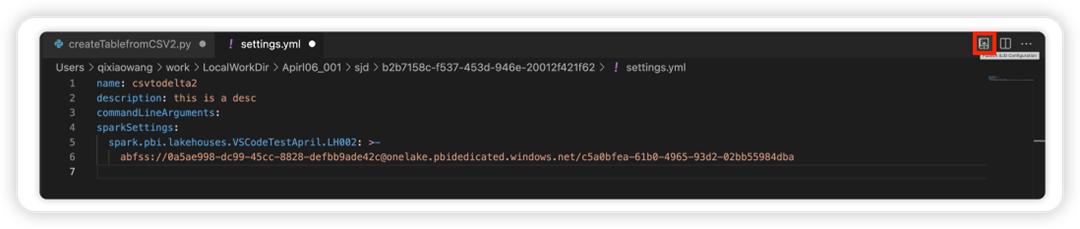
Seleccione la opción Actualizar configuración de SJD para abrir un archivo settings.yml. Las propiedades existentes rellenan el contenido de este archivo.
Actualice y guarde el archivo .yml.
Seleccione la opción Publicar propiedad de SJD en la esquina superior derecha para volver a sincronizar el cambio en el área de trabajo remota.