Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Use grupos de Spark personalizados para personalizar la computación de sus cargas de trabajo en Fabric. Puede elegir el tamaño del nodo, configurar el comportamiento de escalado automático y habilitar la asignación dinámica del ejecutor.
Los grupos personalizados le ayudan a equilibrar el rendimiento y el costo al permitirle establecer límites de escalado que coincidan con la demanda de la carga de trabajo.
Nota:
Los grupos de Spark personalizados pueden lograr aproximadamente 5 segundos de inicio de sesión cuando se configura como un grupo activo personalizado con un entorno que usa el modo Completo para la publicación de bibliotecas. Sin una configuración de grupo activo, los grupos de Spark personalizados tardan unos tres minutos en iniciarse.
Si ya usa grupos de inicio, los grupos personalizados son una opción complementaria cuando necesita más control sobre el comportamiento de ajuste de tamaño y escalado para cargas de trabajo específicas. Use los grupos de inicio para el inicio rápido y la configuración predeterminada, y pase a grupos personalizados cuando necesite el ajuste de proceso específico de la carga de trabajo. Para más información sobre los grupos de inicio, consulte Configurar los grupos de inicio en Fabric.
Prerrequisitos
Para crear un grupo de Spark personalizado:
- Necesita el rol Administrador en el área de trabajo.
- Un administrador de capacidad debe habilitar grupos de áreas de trabajo personalizadas en la configuración de proceso de Spark para la capacidad.
Para obtener más información, consulte Configurar y gestionar las configuraciones de ingeniería de datos y ciencia de datos para capacidades de Fabric.
Creación de grupos de Spark personalizados
Para crear o administrar el grupo de Spark asociado al área de trabajo:
Vaya al área de trabajo y seleccione Configuración del área de trabajo.
Seleccione la opción Ingeniería de datos/Ciencia para expandir el menú y, a continuación, seleccione Configuración de Spark.
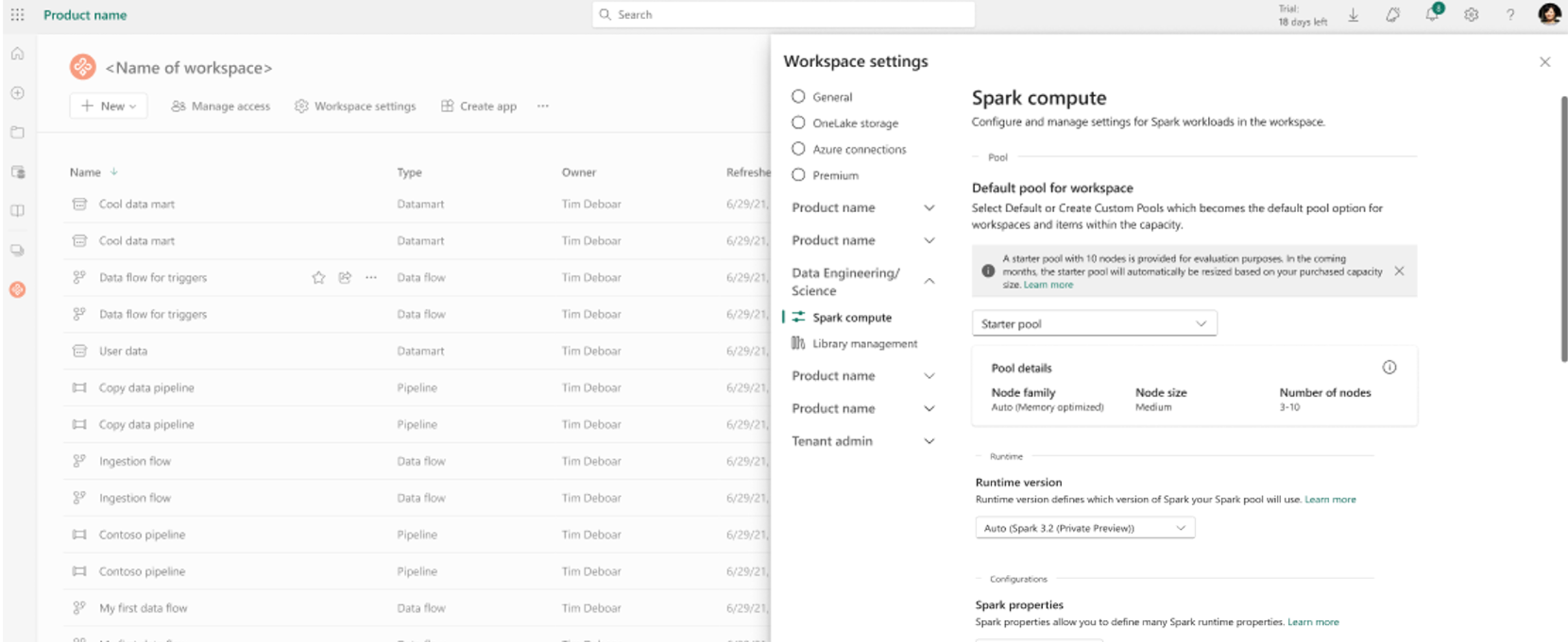
Seleccione Nuevo grupo en la lista desplegable Grupo predeterminado para el área de trabajo para crear un nuevo grupo de Spark personalizado. Puede crear varios grupos personalizados y seleccionar cualquiera de ellos como grupo predeterminado para el área de trabajo.
En la página Crear nuevo grupo , escriba un nombre de grupo. Seleccione una familia de nodos (como optimizado para memoria) y tamaño del nodo en función de los requisitos de carga de trabajo. Para obtener más información sobre los tamaños de nodo, consulte la sección Opciones de tamaño de nodo a continuación.
Sugerencia
El tamaño del nodo viene determinado por unidades de capacidad (CU), que representan la capacidad de proceso asignada a cada nodo.
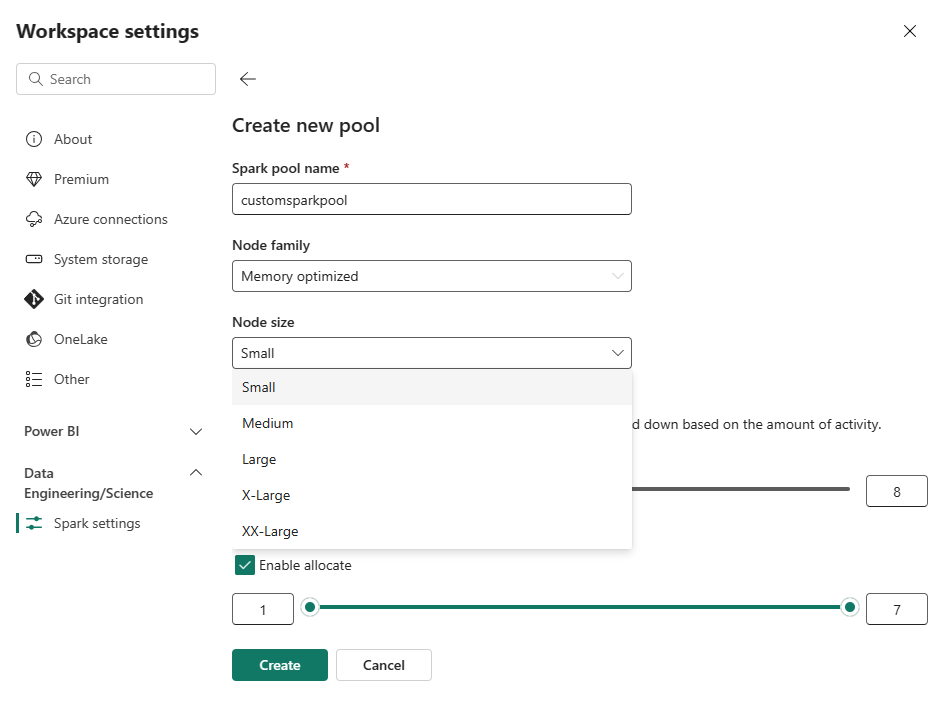
En la vista de edición, configure escalabilidad automática y asigne ejecutores dinámicamente.
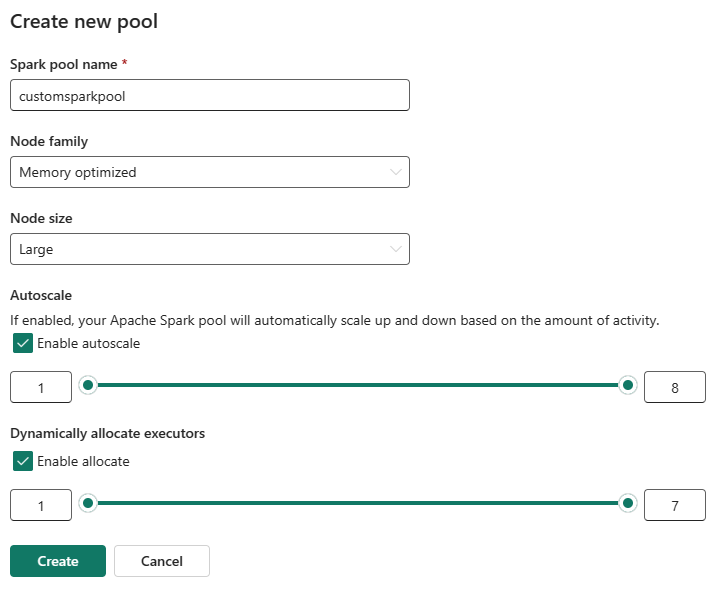
Use los controles deslizantes para aumentar o disminuir cada configuración en función de las necesidades de la carga de trabajo.
Si la escalabilidad automática está habilitada, el grupo se escala entre los valores de nodo mínimo y máximo configurados en función de la actividad.
Si se habilita la asignación dinámica de ejecutores , Fabric ajusta la asignación del ejecutor en función de la demanda de carga de trabajo dentro de los límites configurados.
Selecciona Crear.




Sugerencia
Después de crear un grupo de Spark personalizado, el tiempo de implementación de la biblioteca depende del modo de publicación en el entorno adjunto. El modo rápido se publica en aproximadamente 5 segundos e instala bibliotecas en el inicio de la sesión. El modo completo tarda entre 3 y 6 minutos en publicar e implementar bibliotecas como parte del inicio de la sesión (de 1 a 3 minutos). Para obtener la experiencia más rápida, configure el grupo como un grupo activo personalizado con el modo completo para lograr aproximadamente 5 segundos de inicio de sesión.
Los grupos personalizados tienen una duración predeterminada de pausa automática de 2 minutos después de la inactividad. Cuando se alcanza la pausa automática, la sesión expira y el clúster se desaloca. La facturación solo se aplica mientras los recursos de cómputo se utilizan activamente. Los grupos de Spark personalizados en Microsoft Fabric actualmente admiten un límite máximo de nodo de 200, por lo que debe asegurarse de que los valores de escalado automático mínimo y máximo permanecen dentro de este límite.
Opciones de tamaño de nodo
Al configurar un grupo de Spark personalizado, elija entre los siguientes tamaños de nodo:
| Tamaño del nodo | vCores | Memoria (GB) | Descripción |
|---|---|---|---|
| Pequeño | 4 | 32 | Para trabajos ligeros de desarrollo y pruebas. |
| Mediana | 8 | 64 | Para cargas de trabajo generales y operaciones típicas. |
| Grande | 16 | 128 | Para tareas de uso intensivo de memoria o trabajos de procesamiento de datos de gran tamaño. |
| Extra grande | 32 | 256 | Para las cargas de trabajo de Spark más exigentes que necesitan recursos significativos. |
| Extra grande | 64 | 512 | Para las cargas de trabajo de Spark más grandes que requieren el mayor procesamiento y memoria por nodo. |
Contenido relacionado
- Obtenga más información en la documentación pública de Apache Spark.
- Introducción a la configuración de administración del área de trabajo de Spark en Microsoft Fabric.
- Administración de bibliotecas en entornos de Fabric