Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este tutorial, aprenderá a crear una definición de trabajo de Spark en Microsoft Fabric.
El proceso de creación de una definición de empleo en Spark es rápido y sencillo; hay varias formas de empezar.
Puede crear una definición de trabajo de Spark desde el portal de Fabric o mediante la API rest de Microsoft Fabric. Este artículo se centra en la creación de una definición de trabajo de Spark desde el portal de Fabric. Para obtener información sobre cómo crear una definición de trabajo de Spark mediante la API REST, consulte Api de definición de trabajos de Apache Spark v1 y API de definición de trabajos de Apache Spark v2.
Requisitos previos
Antes de comenzar, necesita:
- Una cuenta de arrendatario de Fabric con una suscripción activa. Cree una cuenta gratuita.
- Un área de trabajo en Microsoft Fabric. Para obtener más información, consulte Creación y administración de áreas de trabajo en Microsoft Fabric.
- Al menos un lakehouse en el espacio de trabajo. Lakehouse actúa como sistema de archivos predeterminado para la definición del trabajo de Spark. Para obtener más información, consulte Crear un Lakehouse.
- Un archivo de definición principal para el trabajo de Spark. Este archivo contiene la lógica de la aplicación y es obligatorio ejecutar un trabajo de Spark. Cada definición de trabajo de Spark solo puede tener un archivo de definición principal.
Debe asignarle un nombre a su definición de trabajo Spark cuando la cree. El nombre debe ser único dentro del área de trabajo actual. La nueva definición de trabajo Spark se crea en su área de trabajo actual.
Creación de una definición de trabajo de Spark en el portal de Fabric
Para crear una definición de trabajo de Spark en el portal de Fabric, siga estos pasos:
- Inicie sesión en el portal de Microsoft Fabric.
- Vaya al área de trabajo deseada en la que desea crear la definición del trabajo de Spark.
- Seleccione New item>
- En el panel Nueva definición de trabajo de Spark , proporcione la siguiente información:
- Nombre: escriba un nombre único para la definición del trabajo de Spark.
- Ubicación: seleccione la ubicación del área de trabajo.
- Seleccione Crear para crear la definición del trabajo de Spark.
Un punto de entrada alternativo para crear una definición de trabajo de Spark es el análisis de datos mediante un icono de SQL ... en la página principal de Fabric. Para encontrar la misma opción, seleccione el icono General.

Al seleccionar el icono, se le pedirá que cree una nueva área de trabajo o seleccione una existente. Después de seleccionar el área de trabajo, se abre la página de creación de la definición de trabajo de Spark.
Personalización de una definición de trabajo de Spark para PySpark (Python)
Antes de crear una definición de trabajo de Spark para PySpark, necesita un archivo Parquet de ejemplo cargado en lakehouse.
- Descargue el archivo Parquet de ejemplo yellow_tripdata_2022-01.parquet.
- Dirígete a la casa en el lago donde quieres subir el archivo.
- Súbalo en la sección "Archivos" del lakehouse.
Para crear una definición de trabajo Spark para PySpark:
Seleccione PySpark (Python) en la lista desplegable Lenguaje .
Descargue el archivo de definición de ejemplo createTablefromParquet.py. Cárguelo como archivo de definición principal. El archivo de definición principal (job.Main) es el archivo que contiene la lógica de la aplicación y es obligatorio para ejecutar un trabajo Spark. Para cada definición de trabajo Spark, solo puede cargar un archivo de definición principal.
Nota:
Puede cargar el archivo de definición principal desde su escritorio local, o puede cargarlo desde un Azure Data Lake Storage (ADLS) Gen2 existente proporcionando la ruta ABFSS completa del archivo. Por ejemplo,
abfss://your-storage-account-name.dfs.core.windows.net/your-file-path.Opcionalmente, cargue archivos de referencia como
.pyarchivos (Python). Los archivos de referencia son los módulos de Python que importa el archivo de definición principal. Al igual que el archivo de definición principal, puede cargarlo desde su escritorio o desde un ADLS Gen2 existente. Se admiten varios archivos de referencia.Sugerencia
Si usa una ruta de acceso de ADLS Gen2, asegúrese de que el archivo sea accesible. Debe conceder a la cuenta de usuario que ejecute el trabajo el permiso adecuado para la cuenta de almacenamiento. Estas son dos maneras diferentes de conceder el permiso:
- Asigne a la cuenta de usuario una función de colaborador para la cuenta de almacenamiento.
- Conceda permiso de Lectura y Ejecución a la cuenta de usuario para el archivo a través de la Lista de Control de Acceso (ACL) de ADLS Gen2.
Para una ejecución manual, la cuenta del usuario que ha iniciado sesión actual se usa para ejecutar el trabajo.
Proporcione argumentos de línea de comandos para el trabajo, si es necesario. Utilice un espacio como separador para separar los argumentos.
Agregue la referencia de lakehouse al trabajo. Debe tener al menos una referencia de lakehouse agregada al trabajo. Este lakehouse es el contexto de lakehouse predeterminado para el trabajo.
Se admiten varias referencias de lakehouse. Encuentre el nombre no predeterminado del almacén del lago y la URL completa de OneLake en la página de Configuración de Spark.

Personalización de una definición de trabajo de Spark para Scala/Java
Para crear una definición de trabajo Spark para Scala/Java:
Seleccione Spark(Scala/Java) en la lista desplegable Lenguaje .
Cargue el archivo de definición principal como un
.jararchivo (Java). El archivo de definición principal es el archivo que contiene la lógica de aplicación de este trabajo y es obligatorio para ejecutar un trabajo Spark. Para cada definición de trabajo Spark, solo puede cargar un archivo de definición principal. Seleccione el nombre de clase Main.Puede cargar opcionalmente archivos de referencia como archivos
.jar(Java). Los archivos de referencia son los archivos a los que hace referencia o importa el archivo de definición principal.Proporcione argumentos de línea de comandos para el trabajo, si es necesario.
Agregue la referencia de lakehouse al trabajo. Debe tener al menos una referencia de lakehouse agregada al trabajo. Este lakehouse es el contexto de lakehouse predeterminado para el trabajo.
Personalización de una definición de trabajo de Spark para R
Para crear una definición de trabajo Spark para SparkR(R):
Seleccione SparkR(R) en la lista desplegable Lenguaje .
Cargue el archivo de definición principal como un
.rarchivo (R). El archivo de definición principal es el archivo que contiene la lógica de aplicación de este trabajo y es obligatorio para ejecutar un trabajo Spark. Para cada definición de trabajo Spark, solo puede cargar un archivo de definición principal.Puede cargar archivos de referencia como archivos
.r(R). Los archivos de referencia son los archivos a los que hace referencia/importa el archivo de definición principal.Proporcione argumentos de línea de comandos para el trabajo, si es necesario.
Agregue la referencia de lakehouse al trabajo. Debe tener al menos una referencia de lakehouse agregada al trabajo. Este lakehouse es el contexto de lakehouse predeterminado para el trabajo.
Nota:
La definición del trabajo de Spark se crea en el área de trabajo actual.
Opciones para personalizar las definiciones de trabajo de Spark
Existen algunas opciones para personalizar aún más la ejecución de las definiciones de trabajo de Spark.
Proceso de Spark: en la pestaña Proceso de Spark , puede ver la versión del entorno de ejecución de Fabric que se usa para ejecutar el trabajo de Spark. También puede ver las opciones de configuración de Spark que se usan para ejecutar el trabajo. Puede personalizar las opciones de configuración de Spark seleccionando el botón Agregar .
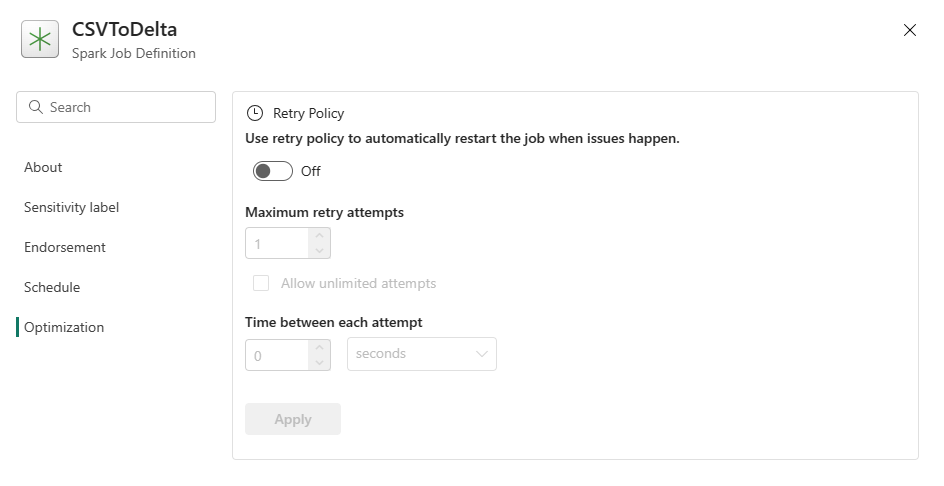
Optimización: En la pestaña Optimización, puede habilitar y configurar la Directiva de Reintentos para el trabajo. Cuando está habilitada, el trabajo se reintenta si falla. También puedes establecer el número máximo de reintentos y el intervalo entre ellos. Por cada intento de reintento, el trabajo se reinicia. Asegúrese de que el trabajo es idempotente.