Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Los flujos de datos son una herramienta basada en la nube que le ayuda a preparar y transformar datos sin escribir código. Proporcionan una interfaz de bajo código para incorporar datos de cientos de fuentes de datos, transformar tus datos mediante más de 300 transformaciones, y cargar los datos resultantes en múltiples destinos. Piense en ellos como su asistente de datos personales que puede conectarse a cientos de orígenes de datos diferentes, limpiar datos desordenados y entregarlos exactamente donde lo necesite. Tanto si es un desarrollador ciudadano como profesional, los flujos de datos le permiten disfrutar de una experiencia de integración de datos moderna para ingerir, preparar y transformar datos de un amplio conjunto de orígenes de datos, como bases de datos, data warehouse, Lakehouse, datos en tiempo real, etc.
Dataflow Gen2 es la versión más reciente y eficaz que funciona junto con el flujo de datos de Power BI original (ahora denominado Gen1). Creado con la experiencia familiar Power Query disponible en varios productos y servicios de Microsoft, como Excel, Power BI, Power Platform y Dynamics 365, Dataflow Gen2 proporciona características mejoradas, un mejor rendimiento y funcionalidades de copia rápidas para ingerir y transformar rápidamente datos. Si está comenzando desde cero, te recomendamos Dataflow Gen2 por sus características avanzadas y un mejor rendimiento.
Importante
A partir de abril de 2026, la opción de crear nuevos elementos de Dataflow Gen2 sin compatibilidad con integración de CI/CD y Git (anteriormente conocido como Dataflow Gen2 Classic) ya no está disponible. Todos los nuevos elementos de Dataflow Gen2 ahora se crean con la compatibilidad de integración de CI/CD y Git de forma predeterminada. Los elementos de Dataflow Gen2 existentes sin compatibilidad con CI/CD siguen funcionando según lo previsto. Para convertir un flujo de datos clásico existente, use la característica Guardar como.
¿Qué puede hacer con los flujos de datos?
Con flujos de datos, puede hacer lo siguiente:
- Conectarse a los datos: extraiga información de bases de datos, archivos, servicios web, etc. También puede volver a conectarse a fuentes usadas recientemente.
- Transformar los datos: limpie, filtre, combine y vuelva a dar forma a los datos mediante una interfaz visual.
- Load data anywhere: Envíe los datos transformados a bases de datos, almacenes de datos o storage en la nube.
- Automatice el proceso: Establezca horarios para que los datos permanezcan frescos y actualizados.
Características de flujo de datos
Estas son las características disponibles entre Dataflow Gen2 y Gen1:
| Característica | Flujo de datos Gen2 | Flujo de datos Gen1 |
|---|---|---|
| Creación de flujos de datos con Power Query | ✓ | ✓ |
| Proceso de creación más sencillo | ✓ | |
| Guardado automático y publicación en segundo plano | ✓ | |
| Varios destinos de salida | ✓ | |
| Mejor supervisión y seguimiento de actualizaciones | ✓ | |
| Funciona con canalizaciones | ✓ | |
| Informática de alto rendimiento | ✓ | |
| Conexión mediante el conector de flujo de datos | ✓ | ✓ |
| Direct Query a través del conector de flujo de datos | ✓ | |
| Actualizar solo los datos modificados | ✓ | ✓ |
| Información basada en inteligencia artificial | ✓ | ✓ |
| Accesos directos a datos recientes de fuentes usadas anteriormente | ✓ |
Actualizaciones a Dataflow Gen2
En las secciones siguientes se muestran algunas de las mejoras clave de Dataflow Gen2 en comparación con Gen1 para facilitar y mejorar la eficacia de las tareas de preparación de datos.
Gen2 es más fácil de crear y usar
Dataflow Gen2 se siente familiar si ha usado antes Power Query. Hemos simplificado el proceso para que pueda ponerse en marcha más rápido. Se le guiará paso a paso al obtener datos en el flujo de datos y hemos reducido el número de pasos necesarios para crear los flujos de datos.

Auto Guardado mantiene tu trabajo seguro
Dataflow Gen2 guarda automáticamente los cambios mientras trabaja. Puede alejarse del equipo, cerrar el navegador o perder la conexión a Internet sin preocuparse por perder el progreso. Cuando vuelves, todo está justo donde lo dejaste.
Una vez que haya terminado de compilar el flujo de datos, puede publicar los cambios. La publicación guarda su trabajo y realiza validaciones en segundo plano, por lo que usted no tiene que esperar a que todo se verifique antes de pasar a la siguiente tarea.
Para más información sobre cómo funciona el proceso de guardado, consulte Guardar un borrador del dataflow.
Envío de datos donde quiera que lo necesite
Aunque Dataflow Gen1 almacena datos transformados en su propio almacenamiento interno (al que puede acceder a través del conector de Dataflow), Dataflow Gen2 le ofrece la flexibilidad de usar ese almacenamiento o enviar los datos a diferentes destinos.
Esta flexibilidad abre nuevas posibilidades. Por ejemplo, puede hacer lo siguiente:
- Uso de un flujo de datos para cargar datos en una instancia de LakeHouse y, a continuación, analizarlos con un cuaderno
- Cargar datos en una base de datos de Azure SQL y, a continuación, usar una canalización para moverlos a un almacenamiento de datos
Dataflow Gen2 admite actualmente estos destinos:
- bases de datos de Azure SQL
- Azure Data Explorer (Kusto)
- Azure Datalake Gen2
- Tablas de Fabric Lakehouse
- archivos de Fabric Lakehouse
- almacenamiento de Fabric
- base de datos KQL de Fabric
- Fabric base de datos SQL
- archivos de SharePoint
- Base de datos de Snowflake
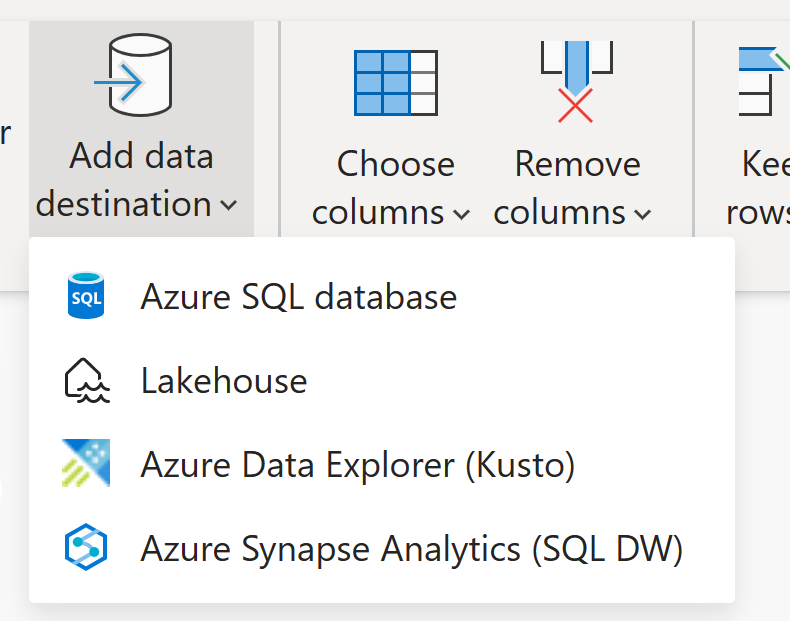
Para obtener más información sobre los destinos de datos disponibles, consulte Destinos de datos de Dataflow Gen2 y configuración administrada.
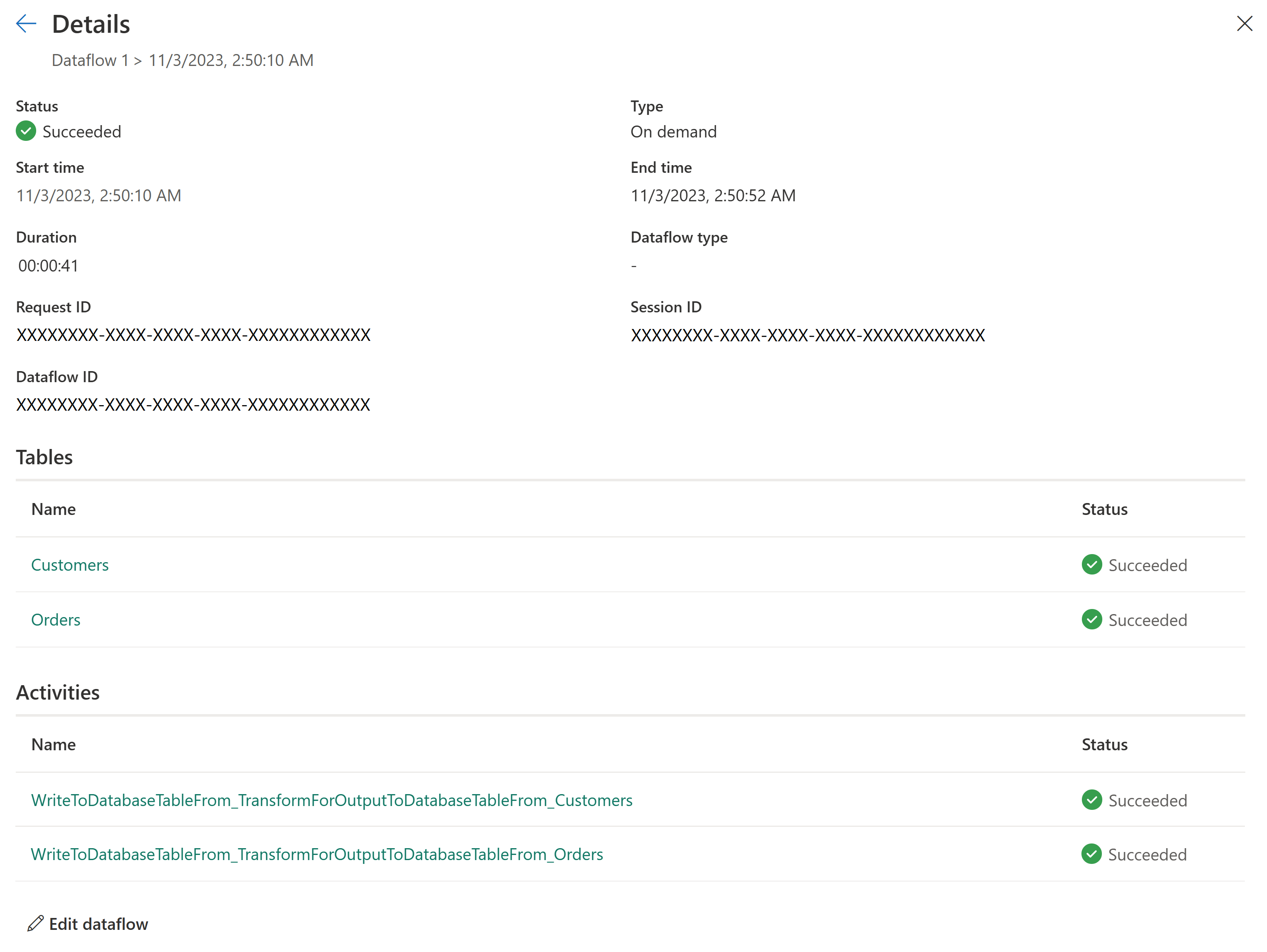
Mejor supervisión y seguimiento de actualizaciones
Dataflow Gen2 proporciona una imagen más clara de lo que sucede con las actualizaciones de datos. Hemos integrado con el Centro de supervisión y mejorado la experiencia del historial de actualizaciones , por lo que puede realizar un seguimiento del estado y el rendimiento de los flujos de datos.
Funciona perfectamente con tuberías
Pipelines permiten agrupar las actividades para completar tareas más grandes. Piense en ellos como flujos de trabajo que pueden copiar datos, ejecutar consultas SQL, ejecutar procedimientos almacenados o ejecutar cuadernos Python.
Puede conectar varias actividades en una canalización y establecerla para que se ejecute según una programación. Por ejemplo, cada lunes puede usar una canalización para extraer datos de un blob de Azure y limpiarlos y, a continuación, desencadenar un flujo de datos Gen2 para analizar los datos de registro. O bien, al final del mes, podría copiar datos de un blob de Azure a una base de datos de Azure SQL y, a continuación, ejecutar un procedimiento almacenado en esa base de datos.
Para más información sobre cómo conectar flujos de datos con pipelines, consulte actividades de flujo de datos.
Informática de alto rendimiento
Dataflow Gen2 usa motores de cálculo avanzados de Fabric y SQL para manejar grandes cantidades de datos de forma eficaz. Para que esto funcione, Dataflow Gen2 crea elementos de Lakehouse y Warehouse en el espacio de trabajo y los usa para almacenar y acceder a datos, mejorando el rendimiento de todos los flujos de datos.
Búsqueda y reutilización de orígenes de datos recientes
Dataflow Gen2 incluye un módulo de datos recientes que registra los elementos que ha usado anteriormente (como tablas, archivos, carpetas, bases de datos y hojas) y permite cargarlos directamente en el lienzo de edición de Dataflow Gen2. Puede acceder a los datos recientes desde la cinta de opciones de Power Query o desde la experiencia De obtención de datos moderna, por lo que puede volver rápidamente a los datos que necesita sin volver a configurar las conexiones.
En cualquier entrada de datos recientes, también puede seleccionar Examinar ubicación para explorar y seleccionar elementos relacionados adicionales dentro de la misma carpeta o base de datos, lo que facilita el trabajo con varios recursos en la misma ubicación.
Copilot para Dataflow Gen2
Dataflow Gen2 se integra con Microsoft Copilot en Fabric para proporcionar asistencia con tecnología de inteligencia artificial para crear soluciones de integración de datos mediante mensajes de lenguaje natural. Copilot le ayuda a simplificar el proceso de desarrollo del flujo de datos al permitirle usar el lenguaje conversacional para realizar transformaciones y operaciones de datos.
- Obtener datos de fuentes: Usa la instrucción inicial "Obtener datos de" para conectarte a diversas fuentes de datos, como OData, bases de datos y archivos.
-
Transformación de datos con lenguaje natural: aplique transformaciones mediante avisos conversacionales como:
- "Solo mantener a los clientes europeos"
- "Contar el número total de empleados por ciudad"
- "Mantener solo pedidos cuyas cantidades están por encima del valor medio"
- Crear datos de ejemplo: Use Azure OpenAI para generar datos de ejemplo para pruebas y desarrollo
- Operaciones de deshacer: escriba o seleccione "Deshacer" para eliminar el último paso aplicado.
- Validar y revisar: Cada acción de Copilot aparece como una tarjeta de respuesta con los pasos correspondientes en la lista Pasos aplicados
Para obtener más información, consulte Copilot for Dataflow Gen2.
¿Qué necesita para usar flujos de datos?
Dataflow Gen2 requiere una capacidad de Fabric, una capacidad de prueba Fabric o una capacidad Power BI Premium. Para comprender cómo funcionan las licencias para flujos de datos, consulte Microsoft Fabric conceptos y licencias.
Traslado de Dataflow Gen1 a Gen2
Si ya tiene flujos de datos creados con Gen1, no se preocupe: puede migrarlos fácilmente a Gen2. Tenemos varias opciones para ayudarle a realizar el cambio:
- Exportación e importación de las consultas
- Copy y pegue Power Query
- Uso de la característica Guardar como
Exportación e importación de las consultas
Puede exportar las consultas de Dataflow Gen1 y guardarlas en un archivo PQT y, a continuación, importarlas en Dataflow Gen2. Para obtener instrucciones paso a paso, consulte Uso de la característica de plantilla de exportación.
Copiar y pegar en Power Query
Si tiene un flujo de datos en Power BI o Power Apps, puede copiar las consultas y pegarlas en el editor de Dataflow Gen2. Este enfoque le permite migrar sin tener que recompilar las consultas desde cero. Más información: Copie y pegue las consultas existentes de Dataflow Gen1.
Uso de la característica Guardar como
Si ya tiene algún tipo de flujo de datos (Gen1 o Gen2), Data Factory incluye una característica Guardar como. Esto le permite guardar cualquier flujo de datos existente como un nuevo elemento de Dataflow Gen2 con compatibilidad de integración de CI/CD y Git en una sola acción. Más detalles: Migración a Dataflow Gen2 mediante Guardar como.
Elementos de almacenamiento provisional en el área de trabajo
En algunas experiencias, es posible que vea elementos generados por el sistema como DataflowsStagingLakehouse o DataflowsStagingWarehouse en el área de trabajo. Estos son elementos de almacenamiento provisional internos usados por Dataflow Gen2 y no están diseñados para la interacción directa. Puedes ignorarlos de forma segura.
Contenido relacionado
¿Quiere aprender algo nuevo? Consulte estos recursos útiles:
- Supervisión de los flujos de datos : seguimiento del historial y el rendimiento de las actualizaciones
- Guardar borradores mientras trabaja : obtenga información sobre la característica de autoguardado.
- Migración de Gen1 a Gen2 : guía de migración paso a paso