Transición de Flujo de datos Generación 1 a Flujo de datos Generación 2
Flujo de datos Gen2 es la nueva generación de flujos de datos. La nueva generación de flujos de datos reside junto con el flujo de datos de Power BI (Gen1) y aporta nuevas características y experiencias mejoradas. En la sección siguiente se proporciona una comparación entre Flujo de datos Gen1 y Flujo de datos Gen2.
Introducción a las características
| Característica | Flujo de datos Gen2 | Flujo de datos Gen1 |
|---|---|---|
| Creación de flujos de datos con Power Query | ✓ | ✓ |
| Flujo de creación más corto | ✓ | |
| Guardar automáticamente y publicar en segundo plano | ✓ | |
| Destinos de datos | ✓ | |
| Mejora del historial de supervisión y actualización | ✓ | |
| Integración con canalizaciones de datos | ✓ | |
| Proceso a gran escala | ✓ | |
| Obtención de datos a través del conector de flujos de datos | ✓ | ✓ |
| Direct Query a través del conector de flujos de datos | ✓ | |
| Actualización incremental | ✓ | |
| Compatibilidad con Conclusiones de IA | ✓ |
Experiencia de creación más corta
Trabajar con Flujo de datos Gen2 se siente como volver a casa. Hemos mantenido toda la experiencia de Power Query que usa en flujos de datos de Power BI. Al escribir la experiencia, se le guiará paso a paso para obtener los datos en el flujo de datos. También acortamos la experiencia de creación para reducir el número de pasos necesarios para crear flujos de datos y hemos agregado algunas características nuevas para mejorar aún más su experiencia.

Nueva experiencia de guardado de flujo de datos
Con Flujo de datos Gen2, hemos cambiado cómo funciona guardar un flujo de datos. Los cambios realizados en un flujo de datos se guardan automáticamente en la nube. Por lo tanto, puede salir de la experiencia de creación en cualquier momento y continuar desde donde la dejó en un momento posterior. Una vez que haya terminado de crear el flujo de datos, publique los cambios y esos cambios se usarán cuando se actualice el flujo de datos. Además, la publicación del flujo de datos guarda los cambios y ejecuta validaciones que se deben realizar en segundo plano. Esta característica le permite guardar el flujo de datos sin tener que esperar a que finalice la validación.
Para más información sobre la nueva experiencia de guardado, vaya a Guardar un borrador del flujo de datos.
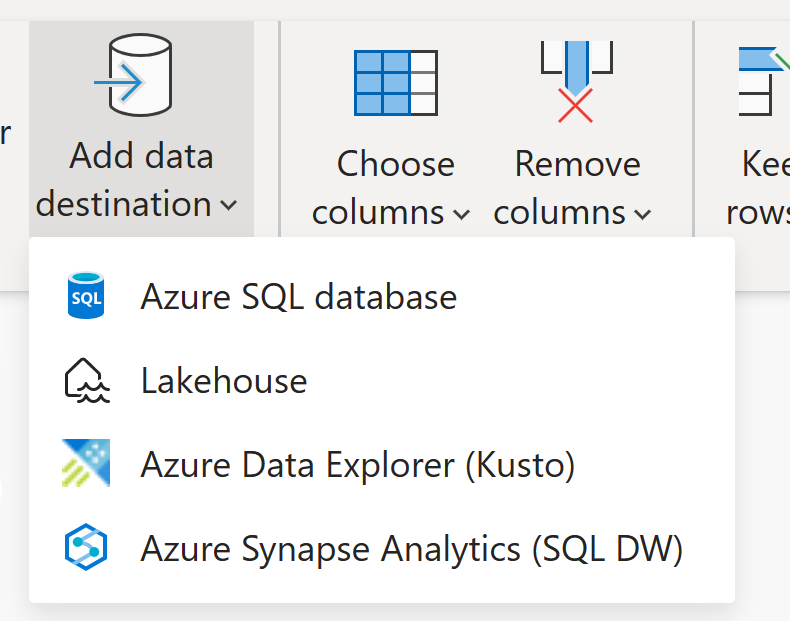
Destinos de datos
De forma similar a Flujo de datos Gen1, Flujo de datos Gen2 permite transformar los datos en el almacenamiento interno o provisional del flujo de datos al que se puede acceder mediante el conector de Flujo de datos. El Flujo de datos Gen2 también permite especificar un destino de datos para los datos. Con esta característica, ahora puede separar la lógica ETL y el almacenamiento de destino. Esta característica le beneficia de muchas maneras. Por ejemplo, ahora puede usar un flujo de datos para cargar datos en un lago y, a continuación, usar un cuaderno para analizar los datos. También puede usar un flujo de datos para cargar datos en una base de datos de Azure SQL y, a continuación, usar una canalización de datos para cargar los datos en un almacenamiento de datos.
En Flujo de datos Gen2, hemos agregado compatibilidad con los siguientes destinos y muchos más próximamente:
- Fabric de Lago de datos
- Azure Data Explorer (Kusto)
- Azure Synapse Analytics (SQL DW)
- Azure SQL Database
Nota
Para cargar los datos en Fabric Warehouse, puede usar el conector de Azure Synapse Analytics (SQL DW) mediante la recuperación de la cadena de conexión de SQL. Más información: Conectividad al almacenamiento de datos en Microsoft Fabric
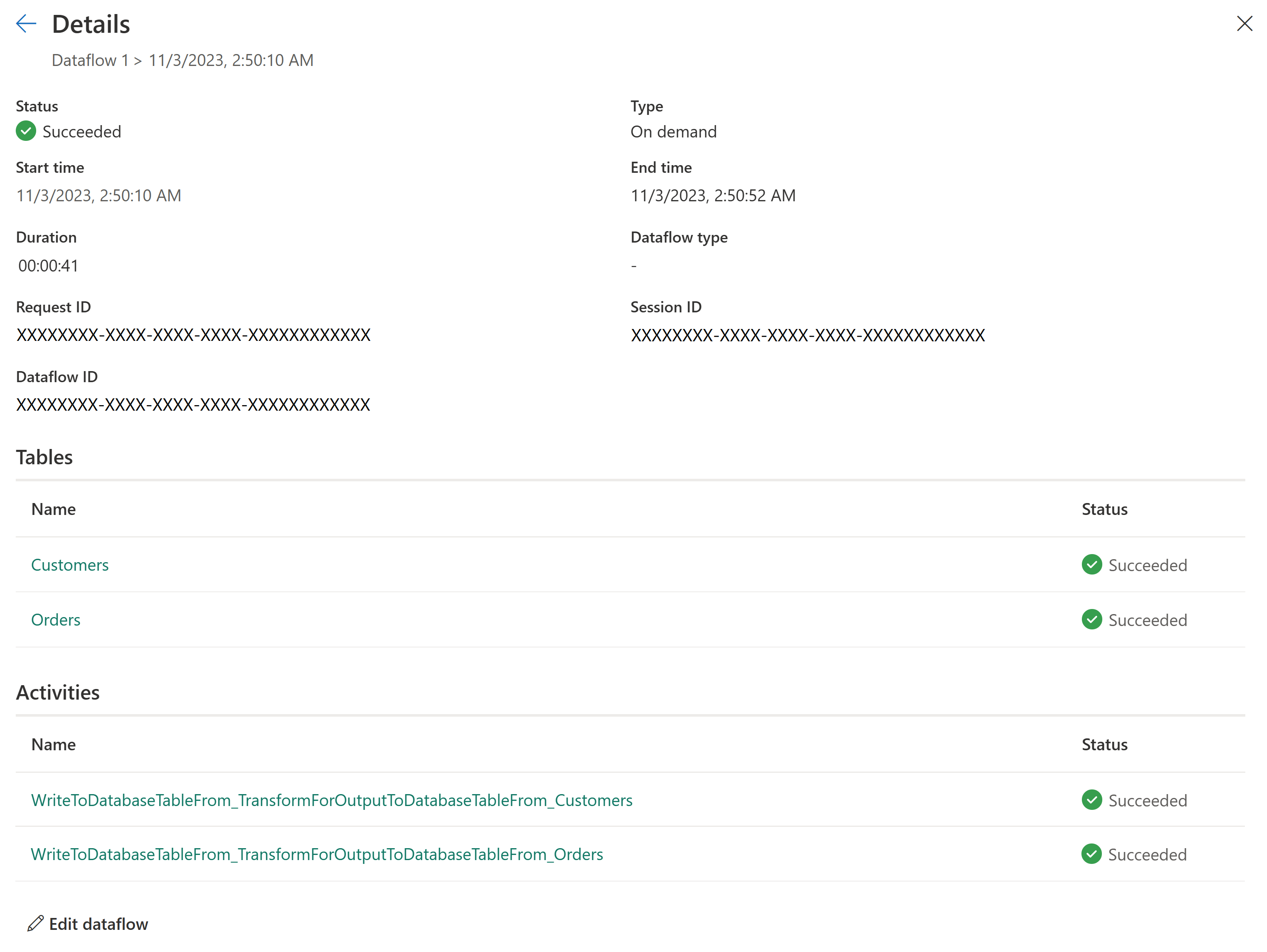
Nuevo historial de actualización y supervisión
Con Flujo de datos Gen2, presentamos una nueva manera de supervisar las actualizaciones del flujo de datos. Integramos la compatibilidad con el Centro de supervisión y proporcionamos a nuestra experiencia de Historial de actualizaciones una actualización importante.
Integración con canalizaciones de datos
Las canalizaciones de datos permiten agrupar actividades que realizan una tarea. Una actividad es una unidad de trabajo que se puede ejecutar. Por ejemplo, una actividad puede copiar datos de una ubicación a otra, ejecutar una consulta SQL, ejecutar un procedimiento almacenado o ejecutar un cuaderno de Python.
Una canalización puede contener una o varias actividades conectadas por dependencias. Por ejemplo, puede usar una canalización para ingerir y limpiar datos de un blob de Azure y, a continuación, iniciar una instancia de Flujo de datos Gen2 para analizar los datos de registro. También puede usar una canalización para copiar datos de un blob de Azure en una base de datos de Azure SQL y, a continuación, ejecutar un procedimiento almacenado en la base de datos.
Guardar como borrador
Con Flujo de datos Gen2, presentamos una experiencia sin preocupaciones eliminando la necesidad de publicar para guardar los cambios. Con la funcionalidad guardar como borrador, almacenamos una versión de borrador del flujo de datos cada vez que realiza un cambio. ¿Perdió la conectividad a Internet? ¿Ha cerrado accidentalmente su navegador? No se preocupe, tenemos todo bajo control. Una vez que vuelva al flujo de datos, los cambios recientes todavía estarán allí y podrá continuar donde lo dejó. Se trata de una experiencia sin problemas y que no requiere ninguna entrada de su parte. Esto le permite trabajar en el flujo de datos sin tener que preocuparse por perder los cambios o tener que corregir todos los errores de consulta antes de poder guardar los cambios. Para más información sobre esta característica, vaya a Guardar un borrador del flujo de datos.
Proceso a gran escala
De forma similar a Flujo de datos Gen1, Flujo de datos Gen2 también incluye un motor de proceso mejorado para mejorar el rendimiento de ambas transformaciones de consultas a las que se hace referencia y obtener escenarios de datos. Para ello, Flujo de datos Gen2 crea elementos de lago de datos y almacén de datos en el área de trabajo y los usa para almacenar y acceder a los datos para mejorar el rendimiento de todos los flujos de datos.
Concesión de licencias de Flujo de datos Gen1 frente a Gen2
Flujo de datos Gen2 es la nueva generación de flujos de datos que residen junto con el flujo de datos de Power BI (Gen1) y aporta nuevas características y experiencias mejoradas. Requiere una capacidad de Fabric o una capacidad de prueba de Fabric. Para entender mejor cómo funciona la concesión de licencias para los flujos de datos puede leer el siguiente artículo: Conceptos y licencias de Microsoft Fabric
Pruebe Flujo de datos Gen2 mediante la reutilización de las consultas de Flujo de datos Gen1
Es probable que tenga muchas consultas de Flujo de datos Gen1 y se pregunte cómo puede probarlas en Flujo de datos Gen2. Tenemos algunas opciones para volver a crear los flujos de datos de Gen1 como Flujo de datos Gen2.
Exportación de las consultas de Flujo de datos Gen1 e importación en Flujo de datos Gen2
Ahora puede exportar consultas en las experiencias de creación de Flujo de datos Gen1 y Gen2 y guardarlas en un archivo PQT que puede importar en Flujo de datos Gen2. Para obtener más información, vaya a Uso de la característica de plantilla de exportación.
Copiar y pegar en Power Query
Si tiene un flujo de datos en Power BI o Power Apps, puede copiar las consultas y pegarlas en el editor de Flujo de datos Gen2. Esta funcionalidad le permite migrar el flujo de datos a Gen2 sin tener que volver a escribir las consultas. Para obtener más información, vaya a Copiar y pegar consultas existentes de Flujo de datos Gen1.