Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este tutorial se presenta un ejemplo completo de un flujo de trabajo de ciencia de datos de Synapse en Microsoft Fabric. Usa tanto el recurso de datos nycflights13 como R para predecir si un avión llega más de 30 minutos tarde. A continuación, usa los resultados de predicción para crear un panel interactivo de Power BI.
En este tutorial, aprenderá a:
Usar paquetes tidymodels
- Recetas
- parsnip
- rsample
- flujos de trabajo para procesar datos y entrenar un modelo de Machine Learning
Escritura de los datos de salida en un almacén de lago de datos como una tabla delta
Creación de un informe visual de Power BI para acceder directamente a los datos de ese almacén de lago de datos
Prerrequisitos
Obtenga una suscripción a Microsoft Fabric. También puede registrarse para obtener una evaluación gratuita de Microsoft Fabric.
Inicie sesión en Microsoft Fabric.
Cambie a Fabric mediante el conmutador de experiencia en el lado inferior izquierdo de la página principal.

Abra o cree un cuaderno. Para obtener información sobre cómo, consulte Uso de cuadernos de Microsoft Fabric.
Establezca la opción de idioma en SparkR (R) para cambiar el idioma principal.
Adjunte su bloc de notas a un almacén de lago de datos. En el lado izquierdo, seleccione Añadir para añadir un almacén de lago de datos existente o crear uno.
Instalación de paquetes
Instale el paquete nycflights13 para usar el código de este tutorial.
install.packages("nycflights13")
# Load the packages
library(tidymodels) # For tidymodels packages
library(nycflights13) # For flight data
Exploración de los datos
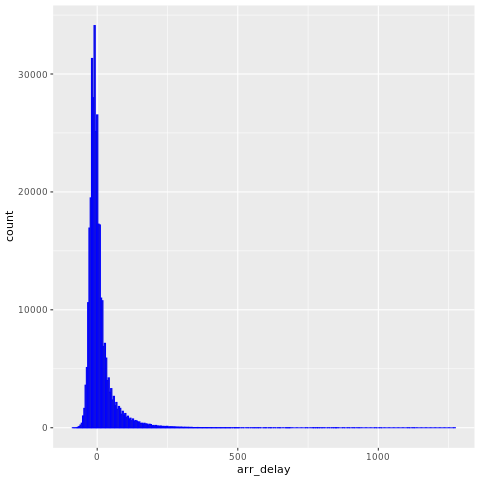
Los nycflights13 datos tienen información sobre 325.819 vuelos que llegaron cerca de Nueva York en 2013. En primer lugar, examine la distribución de retrasos de vuelos. La celda de código siguiente genera un gráfico que muestra que la distribución del retraso de llegada está sesgada a la derecha:
ggplot(flights, aes(arr_delay)) + geom_histogram(color="blue", bins = 300)
Tiene una cola larga en los valores altos, como se muestra en la siguiente imagen:
Cargue los datos y realice algunos cambios en las variables:
set.seed(123)
flight_data <-
flights %>%
mutate(
# Convert the arrival delay to a factor
arr_delay = ifelse(arr_delay >= 30, "late", "on_time"),
arr_delay = factor(arr_delay),
# You'll use the date (not date-time) for the recipe that you'll create
date = lubridate::as_date(time_hour)
) %>%
# Include weather data
inner_join(weather, by = c("origin", "time_hour")) %>%
# Retain only the specific columns that you'll use
select(dep_time, flight, origin, dest, air_time, distance,
carrier, date, arr_delay, time_hour) %>%
# Exclude missing data
na.omit() %>%
# For creating models, it's better to have qualitative columns
# encoded as factors (instead of character strings)
mutate_if(is.character, as.factor)
Antes de compilar el modelo, tenga en cuenta algunas variables específicas que tienen importancia para el preprocesamiento y el modelado.
La arr_delay variable es una variable factor. Para el entrenamiento del modelo de regresión logística, es importante que la variable de resultado sea una variable factor.
glimpse(flight_data)
Aproximadamente 16% de los vuelos de este conjunto de datos llegaron más de 30 minutos tarde:
flight_data %>%
count(arr_delay) %>%
mutate(prop = n/sum(n))
La dest función tiene 104 destinos de vuelo.
unique(flight_data$dest)
Hay 16 portadores distintos:
unique(flight_data$carrier)
División de los datos
Divida el conjunto de datos único en dos conjuntos: un conjunto de entrenamiento y un conjunto de pruebas . Mantenga la mayoría de las filas del conjunto de datos original (como un subconjunto elegido aleatoriamente) en el conjunto de datos de entrenamiento. Use el conjunto de datos de entrenamiento para ajustarse al modelo y use el conjunto de datos de prueba para medir el rendimiento del modelo.
Use el rsample paquete para crear un objeto que contenga información sobre cómo dividir los datos. A continuación, use dos funciones más rsample para crear dataframes para los conjuntos de entrenamiento y pruebas:
set.seed(123)
# Keep most of the data in the training set
data_split <- initial_split(flight_data, prop = 0.75)
# Create DataFrames for the two sets:
train_data <- training(data_split)
test_data <- testing(data_split)
Creación de una receta y roles
Cree una receta para un modelo de regresión logística simple. Antes de entrenar el modelo, use una receta para crear nuevos predictores y llevar a cabo el preprocesamiento que requiere el modelo.
Use la update_role() función , con un rol personalizado denominado ID, para que las recetas sepan que flight y time_hour son variables. Un rol puede tener cualquier valor de carácter. La fórmula incluye todas las variables del conjunto de entrenamiento como predictores, excepto para arr_delay. La receta mantiene estas dos variables de identificador, pero no las usa como resultados o predictores:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID")
Para ver el conjunto actual de variables y roles, use la summary() función :
summary(flights_rec)
Creación de características
La ingeniería de características puede mejorar el modelo. La fecha del vuelo podría tener un efecto razonable en la probabilidad de una llegada tardía:
flight_data %>%
distinct(date) %>%
mutate(numeric_date = as.numeric(date))
Puede ayudar a agregar términos del modelo, derivados de la fecha, que tienen una importancia potencial para el modelo. Derive las siguientes características significativas de la variable de fecha única:
- Día de la semana
- Mes
- Indica si la fecha corresponde a un día festivo
Agregue los tres pasos a la receta:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID") %>%
step_date(date, features = c("dow", "month")) %>%
step_holiday(date,
holidays = timeDate::listHolidays("US"),
keep_original_cols = FALSE) %>%
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors())
Ajustar un modelo con una receta
Use la regresión logística para modelar los datos piloto. En primer lugar, compile una especificación de modelo con el parsnip paquete:
lr_mod <-
logistic_reg() %>%
set_engine("glm")
Utiliza el paquete workflows para agrupar tu modelo parsnip (lr_mod) con tu receta flights_rec.
flights_wflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(flights_rec)
flights_wflow
Entrenamiento del modelo
Esta función puede preparar la receta y entrenar el modelo a partir de los predictores resultantes:
flights_fit <-
flights_wflow %>%
fit(data = train_data)
Use las funciones xtract_fit_parsnip() auxiliares y extract_recipe() para extraer el modelo o los objetos de receta del flujo de trabajo. En este ejemplo, extraiga el objeto de modelo ajustado y, a continuación, use la función broom::tidy() para obtener un tibble ordenado de coeficientes de modelo:
flights_fit %>%
extract_fit_parsnip() %>%
tidy()
Predicción de resultados
Una sola llamada a predict() usa el flujo de trabajo entrenado (flights_fit) para realizar predicciones con los datos de prueba no vistos. El predict() método aplica la receta a los nuevos datos y, a continuación, pasa los resultados al modelo ajustado.
predict(flights_fit, test_data)
Obtenga la salida de predict() para devolver la clase predicha: late frente a on_time. Sin embargo, para las probabilidades de clase predichas para cada vuelo, use augment() con el modelo, combinado con datos de prueba, para guardarlas juntas:
flights_aug <-
augment(flights_fit, test_data)
Revise los datos:
glimpse(flights_aug)
Evaluación del modelo
Ahora tenemos un tibble con las probabilidades de clase predichas. En las primeras filas, el modelo predijo correctamente cinco vuelos a tiempo (los valores de .pred_on_time son p > 0.50). Sin embargo, necesitamos predicciones para un total de 81 455 filas.
Necesitamos una métrica que indique qué tan bien el modelo predijo las llegadas tardías, en comparación con el verdadero estado de la arr_delay variable de resultado.
Use el área bajo la característica de funcionamiento del receptor de curva (AUC-ROC) como métrica. Calcule con roc_curve() y roc_auc(), desde el paquete yardstick.
flights_aug %>%
roc_curve(truth = arr_delay, .pred_late) %>%
autoplot()
Creación de un informe de Power BI
El resultado del modelo luce bien. Use los resultados de predicción de retraso de vuelos para crear un panel interactivo de Power BI. El panel muestra el número de vuelos por transportista y el número de vuelos por destino. El panel puede filtrar por los resultados de la predicción retrasada.

Incluya el nombre del operador y el nombre del aeropuerto en el conjunto de datos de resultados de predicción:
flights_clean <- flights_aug %>%
# Include the airline data
left_join(airlines, c("carrier"="carrier"))%>%
rename("carrier_name"="name") %>%
# Include the airport data for origin
left_join(airports, c("origin"="faa")) %>%
rename("origin_name"="name") %>%
# Include the airport data for destination
left_join(airports, c("dest"="faa")) %>%
rename("dest_name"="name") %>%
# Retain only the specific columns you'll use
select(flight, origin, origin_name, dest,dest_name, air_time,distance, carrier, carrier_name, date, arr_delay, time_hour, .pred_class, .pred_late, .pred_on_time)
Revise los datos:
glimpse(flights_clean)
Convertir los datos en un dataframe de Spark:
sparkdf <- as.DataFrame(flights_clean)
display(sparkdf)
Escriba los datos en una tabla delta en el almacén de lago de datos:
# Write data into a delta table
temp_delta<-"Tables/nycflight13"
write.df(sparkdf, temp_delta ,source="delta", mode = "overwrite", header = "true")
Use la tabla delta para crear un modelo semántico.
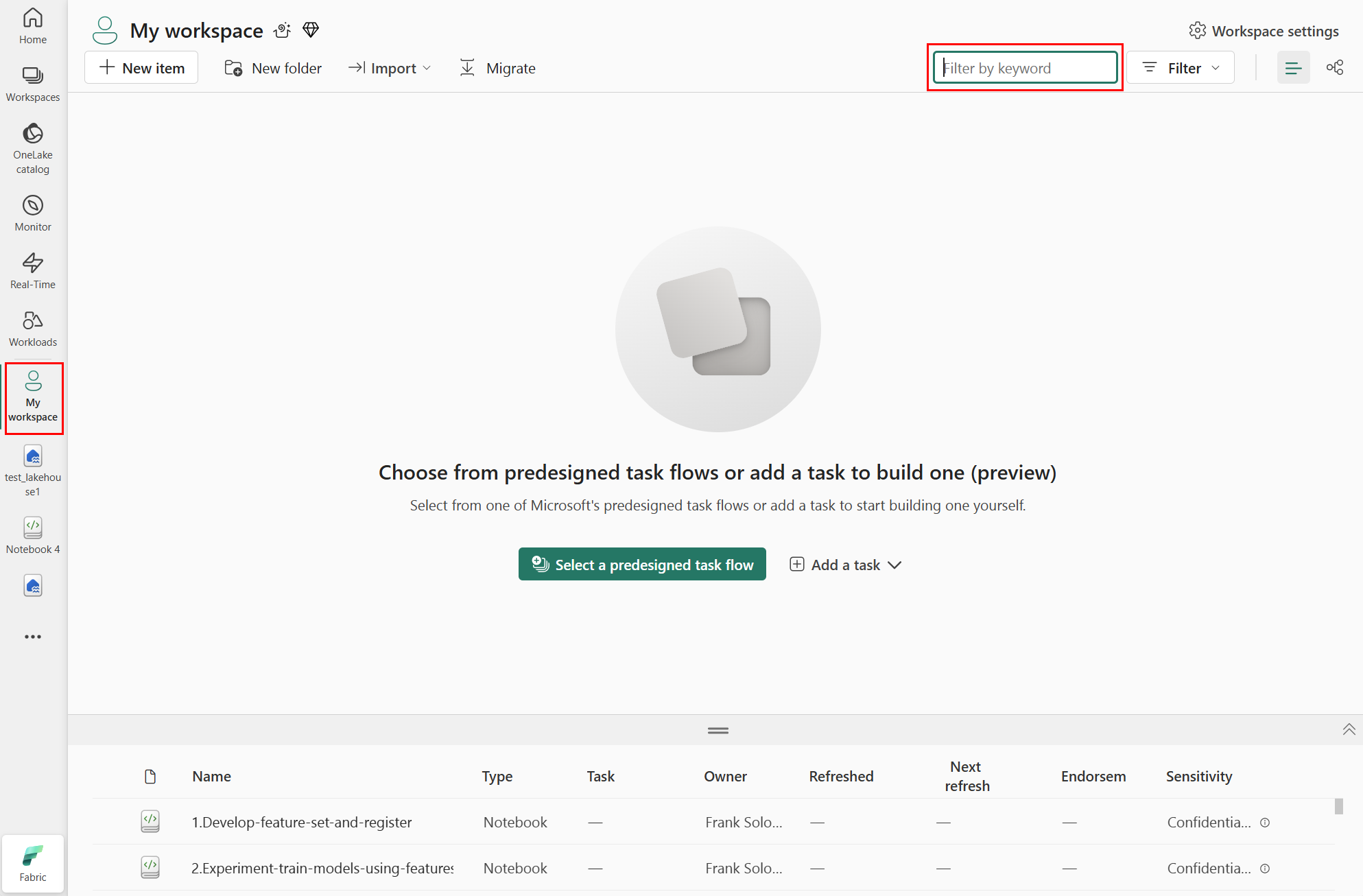
En el panel de navegación izquierdo, seleccione el área de trabajo y, en el cuadro de texto superior derecho, escriba el nombre del almacén de lago de datos que adjuntó al cuaderno. En la captura de pantalla siguiente se muestra que hemos seleccionado Mi área de trabajo:
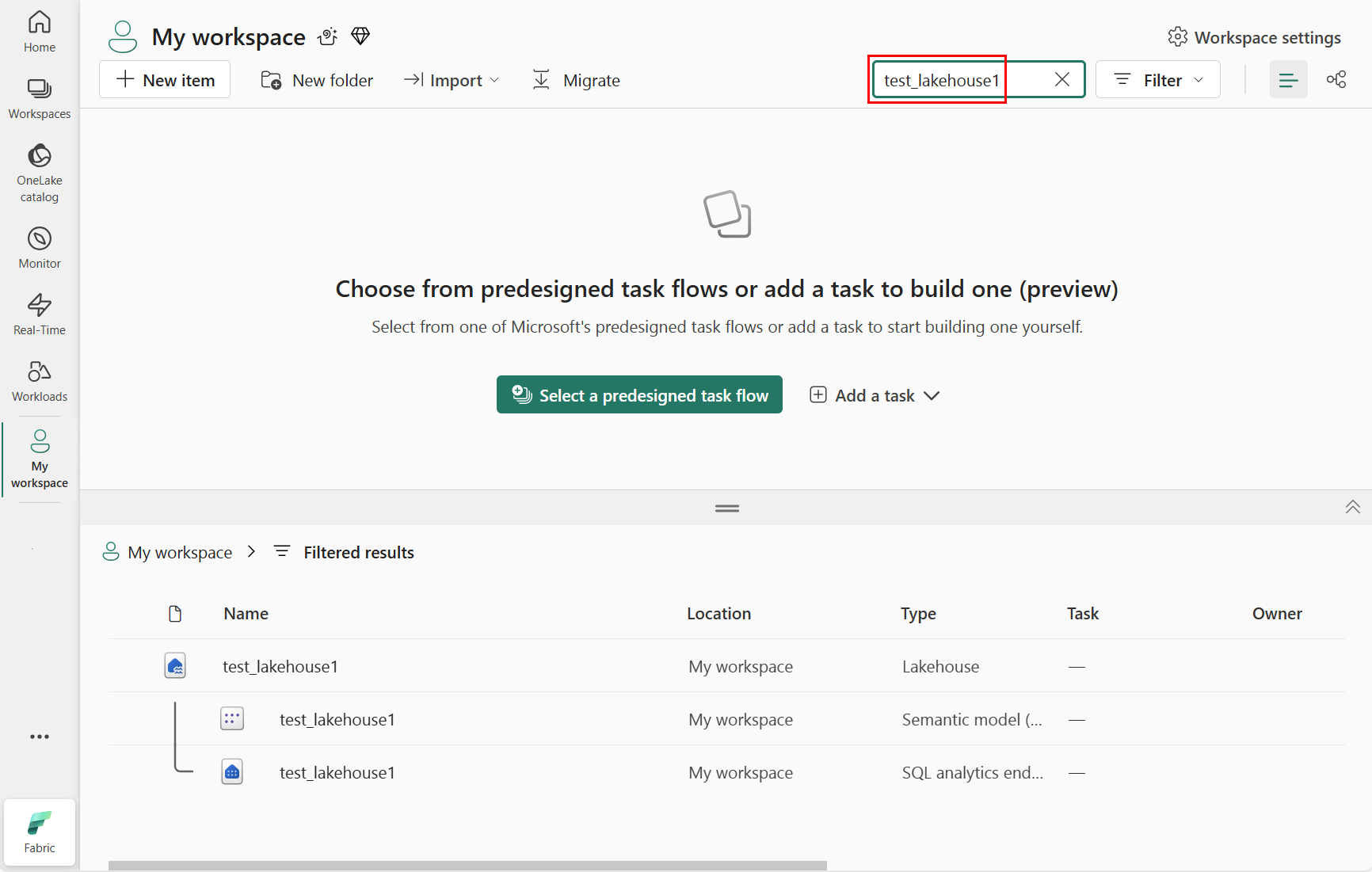
Escriba el nombre del almacén de lago de datos que adjuntó al cuaderno. Entramos test_lakehouse1, como se muestra en la captura de pantalla siguiente:
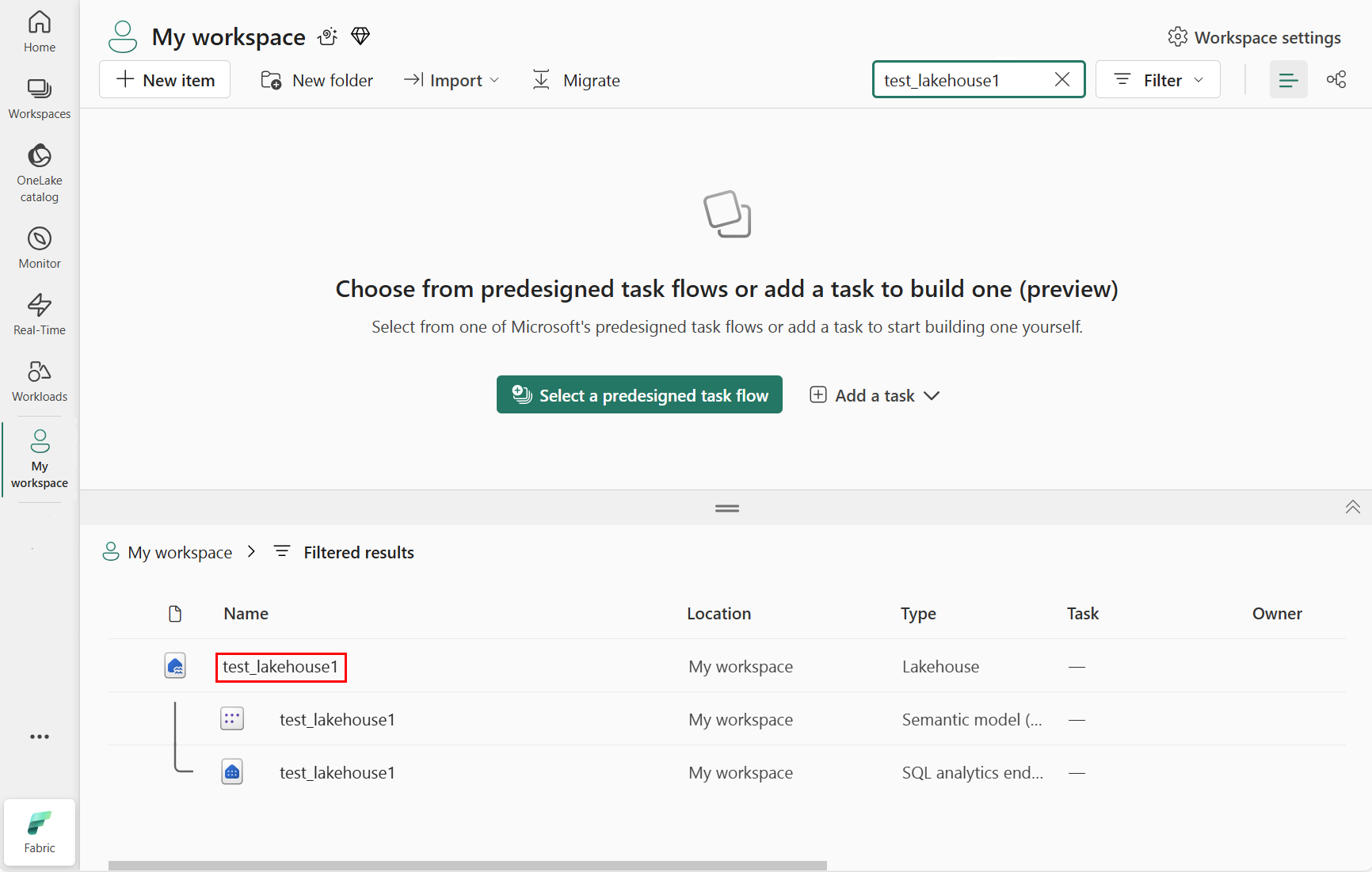
En el área de resultados filtrados, seleccione el lakehouse, como se muestra en la siguiente captura de pantalla.
Seleccione Nuevo modelo semántico como se muestra en la captura de pantalla siguiente:
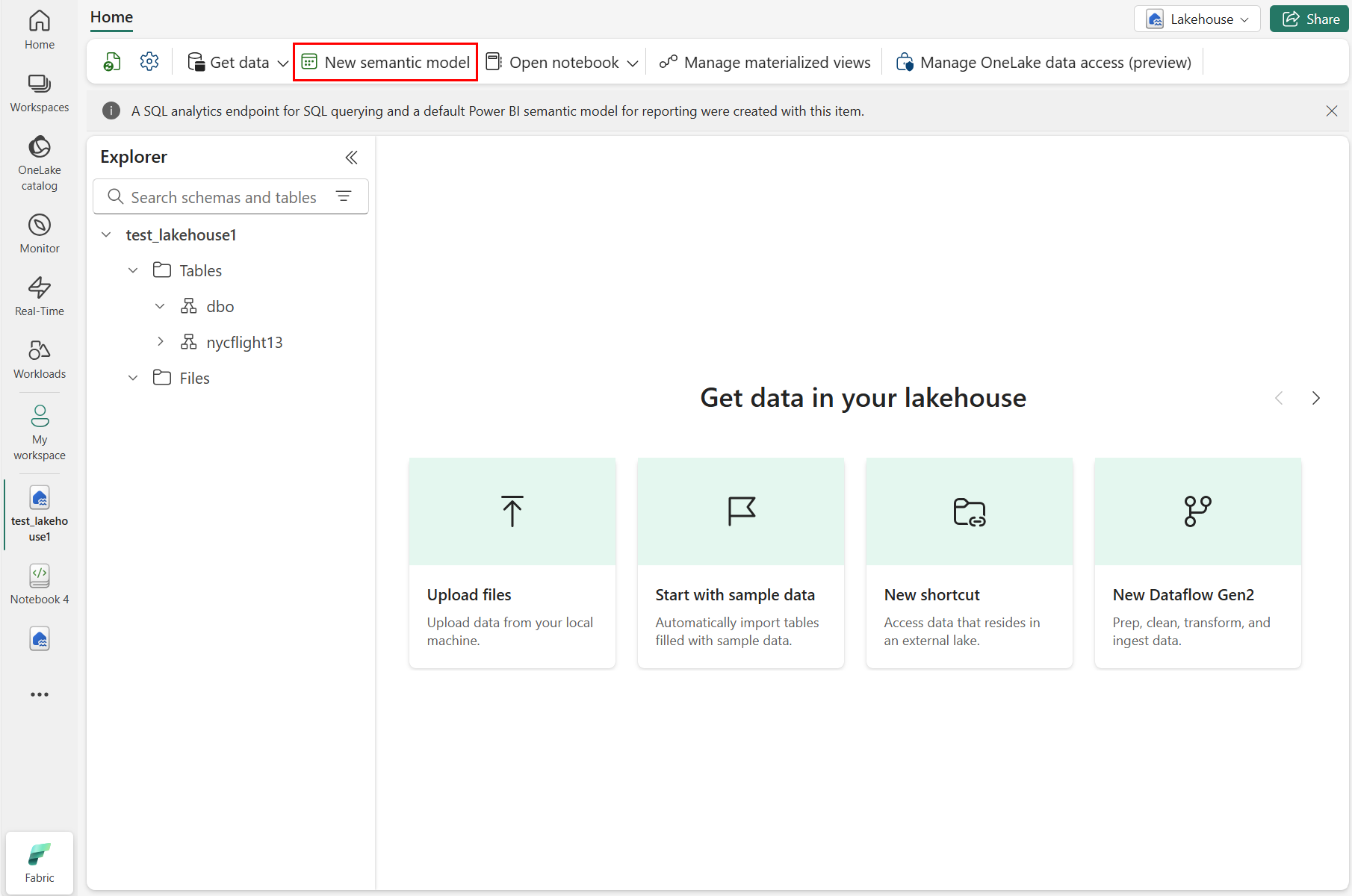
En el panel Nuevo modelo semántico, escriba un nombre para el nuevo modelo semántico, seleccione un área de trabajo y seleccione las tablas que se usarán para ese nuevo modelo y, a continuación, seleccione Confirmar, como se muestra en la captura de pantalla siguiente:
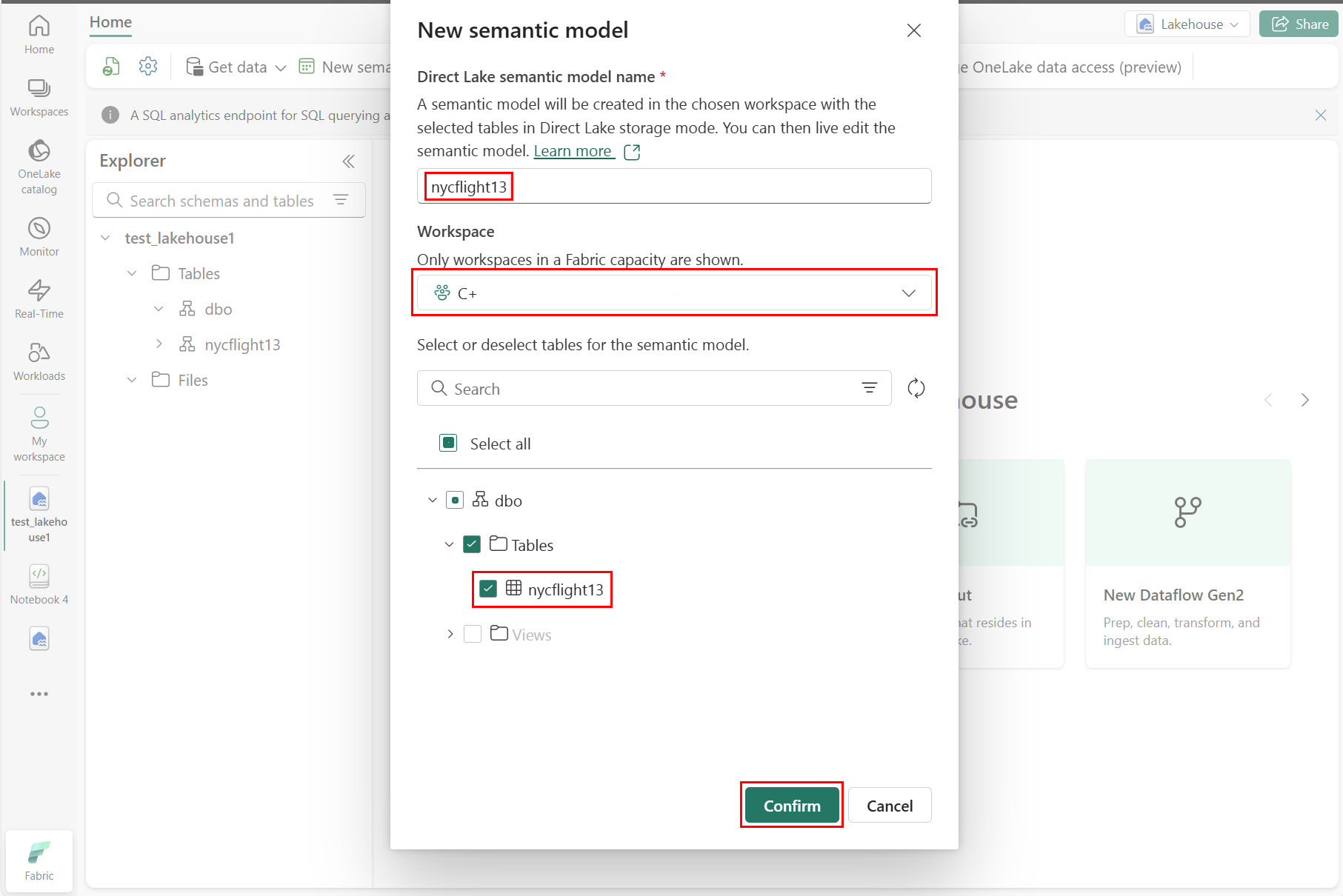
Para crear un nuevo informe, seleccione Crear nuevo informe, como se muestra en la captura de pantalla siguiente:
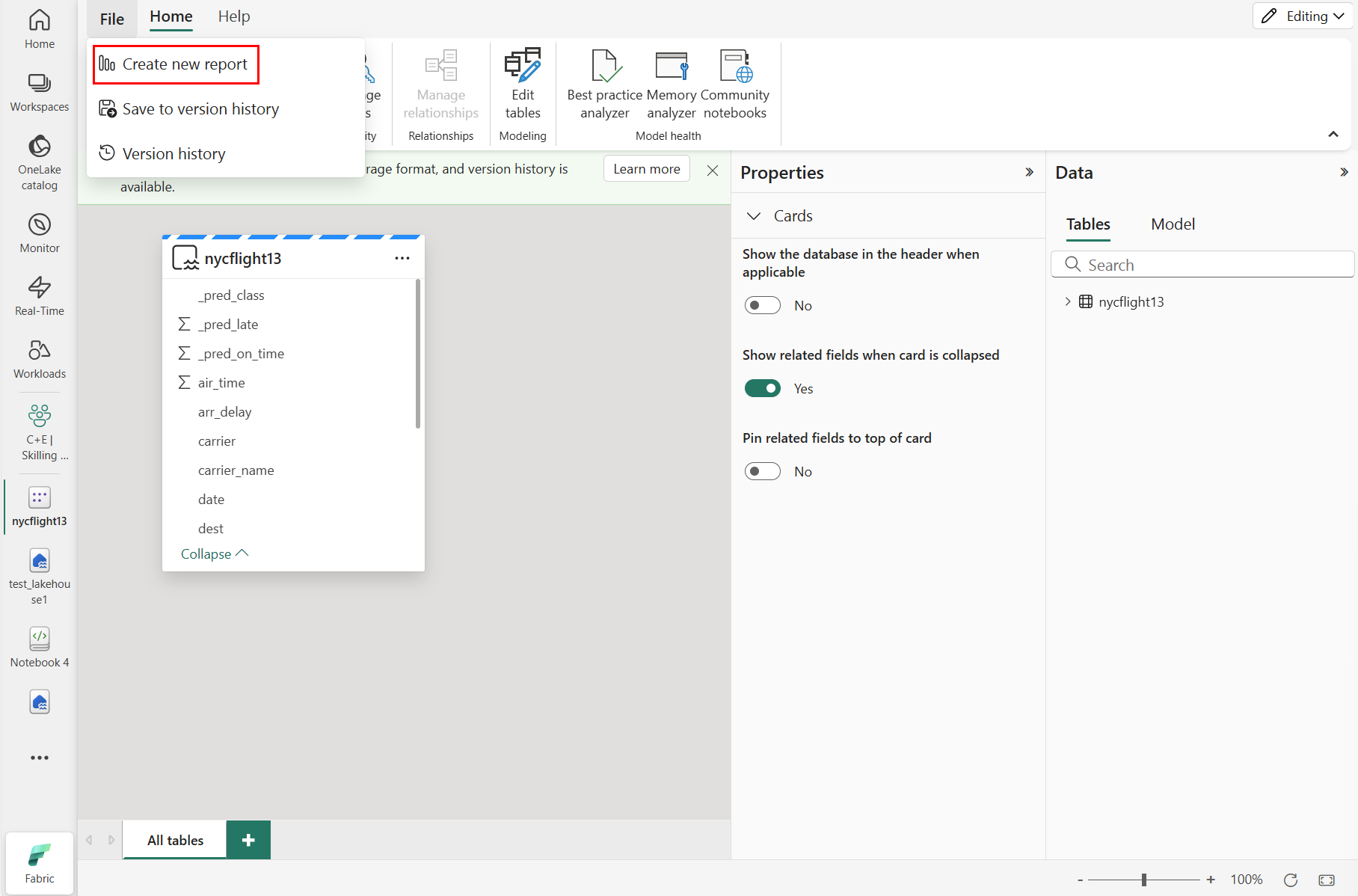
Seleccione o arrastre campos desde los paneles Datos y visualizaciones al lienzo del informe para compilar el informe.
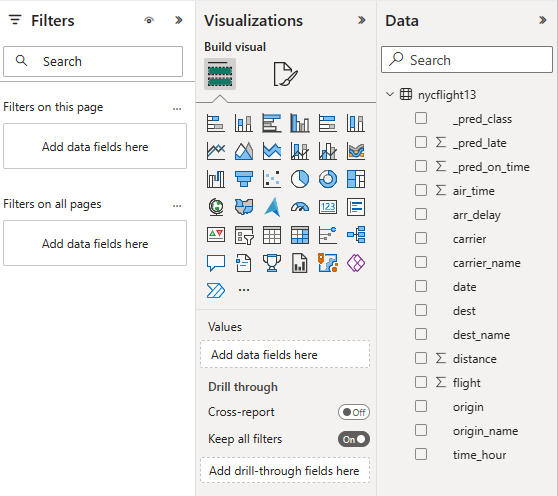






Para crear el informe que se muestra al principio de esta sección, use estas visualizaciones y datos:
-
 Gráfico de barras apiladas con:
Gráfico de barras apiladas con:- Eje Y: carrier_name
- Eje X: vuelo. Seleccione Recuento para la agregación
- Leyenda: origin_name
-
Gráfico de barras apiladas con:
- Eje Y: dest_name
- Eje X: vuelo. Seleccione Recuento para la agregación
- Leyenda: origin_name
-
 Segmentación con:
Segmentación con:- Campo: _pred_class
-
Segmentación con:
- Campo: _pred_late