Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Microsoft Fabric proporciona varias maneras de incorporar datos a su entorno de análisis. Tanto si necesita procesar eventos de streaming en tiempo real, replicar bases de datos operativas, orquestar canalizaciones por lotes o acceder a datos sin copiarlos, Fabric ofrece funcionalidades integradas para admitir cada escenario.
En este artículo se describen las opciones principales de ingesta de datos y movimiento de datos en Fabric. Abarca:
- Ingesta en tiempo real con Eventstreams y Eventhouse
- Orquestación por lotes con canalizaciones de Data Factory y trabajo de copia
- Replicación casi en tiempo real con creación de reflejo
- Virtualización de datos con accesos directos de OneLake
Use esta introducción para comprender cómo funciona cada enfoque y elegir la estrategia que mejor se adapte a los requisitos de carga de trabajo para la latencia, la transformación y la complejidad operativa.
Ingesta de datos en tiempo real
Los elementos Eventstreams y Eventhouse de la carga de trabajo de Inteligencia en Tiempo Real admiten escenarios de datos en streaming. Las secuencias de eventos ingieren y procesan eventos en tiempo real, y Eventhouses almacenan y consultan esos eventos a escala. Normalmente, se usa una secuencia de eventos para capturar y enrutar datos a un centro de eventos. También puede usar cada funcionalidad de forma independiente en función de sus requisitos. En el diagrama siguiente se muestra cómo fluyen los conjuntos de datos en tiempo real a Eventstream y Eventhouse en Fabric:
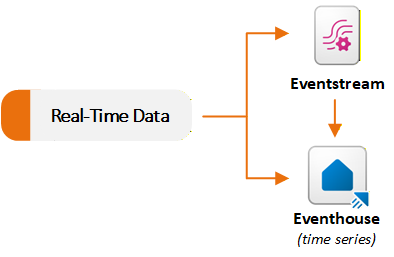
Ingesta y enrutamiento de eventos con Eventstream
Eventstream proporciona una experiencia sin código para ingerir eventos en Fabric, aplicar transformaciones en flujo y enrutar datos a varios destinos. Eventstream actúa como una canalización de ingesta en tiempo real. Cree una secuencia de eventos y agregue uno o varios conectores de origen. Fabric admite muchos orígenes de streaming, incluidos eventos internos de Fabric, como eventos de área de trabajo de Fabric, eventos de archivo de OneLake y eventos de trabajos de canalización.
Después de que los eventos empiecen a fluir, puede aplicar transformaciones opcionales en tiempo real a través de un editor de arrastrar y colocar. Por ejemplo, puede filtrar eventos, calcular agregados de ventanas de tiempo, combinar varias secuencias o reestructurar campos sin escribir código.
Puede enviar la secuencia procesada a uno o varios destinos admitidos. Eventstreams puede exponer puntos de conexión de Apache Kafka a través de orígenes y destinos de punto de conexión personalizados. Esta funcionalidad permite a los productores de Kafka transmitir eventos a Fabric y a los consumidores de Kafka consumir eventos de Fabric.
Las secuencias de eventos no almacenan datos de forma permanente. Transmiten eventos a través de la memoria y los reenvían a destinos configurados. Este diseño hace que Eventstreams sea adecuado para escenarios de extracción, transformación, carga (ETL) en tiempo real y distribución de datos de streaming a varios destinos. Por ejemplo, puede ingerir telemetría de sensores del Internet de las cosas (IoT), filtrar y agregar datos en tiempo real, enviar el flujo refinado a Eventhouse para su análisis y enrutar eventos de anomalías a Activator para aplicaciones de alerta.
Ingesta de datos directamente en Eventhouse
Los centros de eventos pueden ingerir datos directamente desde varios orígenes. Fabric incluye una experiencia de obtención de datos integrada en Eventhouse. El asistente se conecta a orígenes como archivos locales, Azure Storage, Amazon S3, Azure Event Hubs y OneLake. Puede cargar datos en una tabla de base de datos del lenguaje de consulta kusto (KQL) en tiempo real o en modo por lotes mediante la interfaz de usuario de Eventhouse.
También puede seleccionar una secuencia de eventos existente en Fabric como origen. Por ejemplo, si usa una secuencia de eventos que ingiere datos de IoT Hub o Kafka, puede enrutar su salida directamente a una tabla de base de datos KQL sin configuración adicional.
Ingesta de datos por lotes
Data Factory proporciona la experiencia principal para las canalizaciones tradicionales de extracción, transformación y carga (ETL), así como de extracción, carga y transformación (ELT). Incluye una biblioteca de conectores grande. Fabric Data Factory proporciona una lista de conectores nativos para almacenes de datos locales y en la nube, incluidas bases de datos, aplicaciones de software como servicio (SaaS) y sistemas basados en archivos. Estos conectores le ayudan a conectarse a casi cualquier sistema de origen.
Orquestar el movimiento de datos con tuberías
Puede crear canalizaciones que usen estos conectores para copiar o mover datos a almacenes analíticos o de OneLake. Este enfoque admite:
- Conjuntos de datos no estructurados, como imágenes, vídeo y audio
- Conjuntos de datos semiestructurados, como JSON, CSV y XML
- Conjuntos de datos estructurados de sistemas de bases de datos relacionales compatibles
En un pipeline, combinará varios componentes de orquestación, entre los que se incluyen:
- Actividades de movimiento de datos, como Copiar datos y Copiar trabajo
- Actividades de transformación de datos, como Flujo de datos Gen2, Eliminación de datos, Fabric Notebook y script SQL
- Actividades de flujo de control, como ForEach, Lookup, Set Variable y Webhook
Puede ejecutar una canalización a petición, según una programación o en respuesta a eventos. Por ejemplo, puede programar una canalización para que se ejecute cada dos horas durante los días laborables o desencadenarla cuando se cree un nuevo archivo en OneLake.
Simplifique el movimiento de datos con Copy job
El trabajo de copia admite varios patrones de entrega de datos, incluidos la copia masiva, la copia incremental y la replicación de captura de cambios en los datos (CDC). Puede usar la tarea de copia para mover datos de un origen a OneLake sin crear una canalización, mientras accede a opciones de configuración avanzadas. El trabajo de copia admite múltiples orígenes y destinos. Ofrece más control que la duplicación y menos complejidad operativa que la gestión de canalizaciones que utilizan la actividad de copiado.
Replicación de datos con reflejo
El reflejo replica datos de sistemas externos en Fabric casi en tiempo real con configuración automatizada. Se conecta a un sistema externo, como Azure SQL Database, SQL Server, Oracle, SAP o Snowflake. Fabric replica continuamente los datos o metadatos en OneLake. La creación de reflejo admite tres tipos:
- Reflejo de base de datos replica todas las bases de datos y tablas.
- Reflejo de metadatos sincroniza metadatos como nombres de catálogo, esquemas y tablas en lugar de realizar un movimiento físico de datos. Este enfoque usa accesos directos para que los datos permanezcan en su sistema de origen mientras siguen siendo accesibles en Fabric.
- Reflejo abierto usa el formato de tabla de Delta Lake abierto. Los desarrolladores pueden escribir cambios de aplicación directamente en un elemento de base de datos reflejado en OneLake mediante api públicas.
Fabric escucha los cambios del sistema de origen (mediante la captura de datos modificados o métodos similares) y aplica esos cambios casi en tiempo real a la copia reflejada. El resultado es un conjunto de datos activa y consultable que permanece sincronizado con baja latencia, sin canalizaciones ETL complejas.
El reflejo actualmente admite varios orígenes, incluyendo Azure SQL Database, SQL Managed Instance, Azure Cosmos DB, Azure Database for PostgreSQL, Google BigQuery, Oracle, SAP, Snowflake y SQL Server. También admite orígenes de datos de soluciones de socios que han implementado la Open Mirroring API. Los datos reflejados se almacenan en OneLake como las tablas Delta actualizadas. Fabric mantiene estas tablas automáticamente para que pueda usarlas para el análisis en tiempo real o combinarlas con otros datos de Fabric. Esta funcionalidad admite escenarios híbridos de procesamiento transaccional y analítico, donde los datos operativos fluyen continuamente a la plataforma de análisis.
La replicación elimina la necesidad de construir canalizaciones de carga incremental manualmente. Desde la perspectiva del costo de replicación, las operaciones de proceso que mantienen las bases de datos replicadas sincronizadas no usan unidades de capacidad (UC) de su capacidad de Fabric. El almacenamiento de datos reflejado en OneLake también es gratuito hasta el límite de terabyte en tu SKU de Fabric (por ejemplo, F64 incluye 64 TB de almacenamiento de base de datos reflejado gratuito).
Acceso a datos externos con accesos directos
Fabric proporciona accesos directos para habilitar la virtualización de datos. Un acceso directo de OneLake hace referencia a los datos almacenados en un sistema externo, como Azure Data Lake Storage Gen2, Amazon S3 o SharePoint. En lugar de copiar datos, los accesos directos permiten a OneLake hacer referencia a archivos externos como parte del lago de datos unificado. Puede consultar o combinar datos externos con datos locales sin realizar una migración inicial. Este enfoque de ingesta sin copia es útil cuando los requisitos de residencia de datos o los problemas de duplicación impiden mover datos. En el diagrama siguiente se muestra cómo los accesos directos conectan sistemas de almacenamiento externos a elementos de Fabric sin copiar datos:
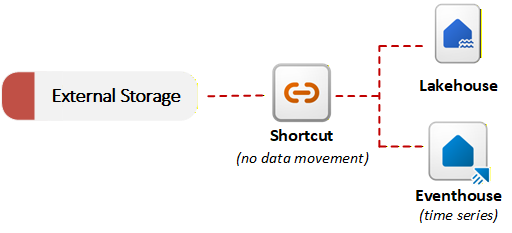
OneLake puede detectar el tipo de datos al que hace referencia un acceso directo y aplicar transformaciones de archivo o transformaciones de IA sin necesidad de una canalización ni de código personalizado. OneLake mantiene la tabla Delta resultante sincronizada con el origen automáticamente. Por ejemplo, puede convertir .csv archivos en tablas Delta o aplicar análisis de opiniones basados en IA a .txt archivos de una carpeta.
Junto con el reflejo, los accesos rápidos proporcionan patrones flexibles de acceso a datos. Puede mantener los datos en su lugar mediante accesos directos o puede replicar datos mediante la creación de reflejo. En ambos casos, los datos están listos para las herramientas de análisis de Fabric sin procesos ETL complejos.
Guía de decisión: Elección de una estrategia de movimiento de datos
Microsoft Fabric proporciona varias opciones para incorporar datos a Fabric, incluidas Eventstreams para el procesamiento en tiempo real, Mirroring, las canalizaciones con actividades de copia, la tarea de copia y los accesos directos. Cada opción ofrece un equilibrio diferente de control, automatización y complejidad operativa.
Para obtener instrucciones sobre cómo seleccionar el enfoque adecuado para su escenario, consulte Guía de decisión de Microsoft Fabric: Elegir una estrategia de movimiento de datos.