Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Copilot en Microsoft Fabric es una tecnología de asistencia de IA generativa que pretende mejorar la experiencia de análisis de datos en la plataforma Fabric. Este artículo le ayuda a comprender cómo funciona Copilot en Fabric y proporciona algunas instrucciones y consideraciones de alto nivel sobre cómo puede usarlo mejor.
Nota:
Las funcionalidades de Copilot evolucionan con el tiempo. Si tiene previsto usar Copilot, asegúrese de mantenerse al día de las actualizaciones mensuales de Fabric y los cambios o anuncios en las experiencias de Copilot.
Este artículo le ayuda a comprender cómo funciona Copilot en Fabric, incluida su arquitectura y costo. La información de este artículo está pensada para guiarle y su organización a usar y administrar Copilot de forma eficaz. Este artículo se dirige principalmente a:
Directores o administradores de BI y análisis: Responsables de la toma de decisiones responsables de supervisar el programa y la estrategia de BI, y quién decide si habilitar y usar Copilot en Fabric u otras herramientas de inteligencia artificial.
Administradores de Fabric: Los responsables en la organización de supervisar Microsoft Fabric y sus diversas cargas de trabajo. Los administradores de Fabric supervisan quién puede usar Copilot en Fabric para cada una de estas cargas de trabajo y supervisar cómo afecta el uso de Copilot a la capacidad de Fabric disponible.
Arquitectos de datos: Las personas responsables de diseñar, compilar y administrar las plataformas y la arquitectura que admiten datos y análisis en la organización. Los arquitectos de datos consideran el uso de Copilot en el diseño de la arquitectura.
Centro de excelencia (COE), equipos de TI y BI: Los equipos responsables de facilitar la adopción y el uso correctos de plataformas de datos como Fabric en la organización. Estos equipos y personas pueden utilizar herramientas de inteligencia artificial como Copilot, y también apoyar y guiar a los usuarios de autoservicio de la organización para que ellos también se beneficien.
Información general sobre cómo funciona Copilot en Fabric
Copilot en Fabric funciona de forma similar a las otras de Microsoft Copilot, como Microsoft 365 Copilot,Microsoft Security Copilot y Copilots e IA generativa en Power Platform. Sin embargo, hay varios aspectos específicos de cómo funciona Copilot en Fabric.
Diagrama de información general del proceso
En el diagrama siguiente se muestra información general sobre cómo funciona Copilot en Fabric.
Nota:
En el diagrama siguiente se muestra la arquitectura general de Copilot en Fabric. Sin embargo, dependiendo de la carga de trabajo y la experiencia específicas, puede haber adiciones o diferencias.
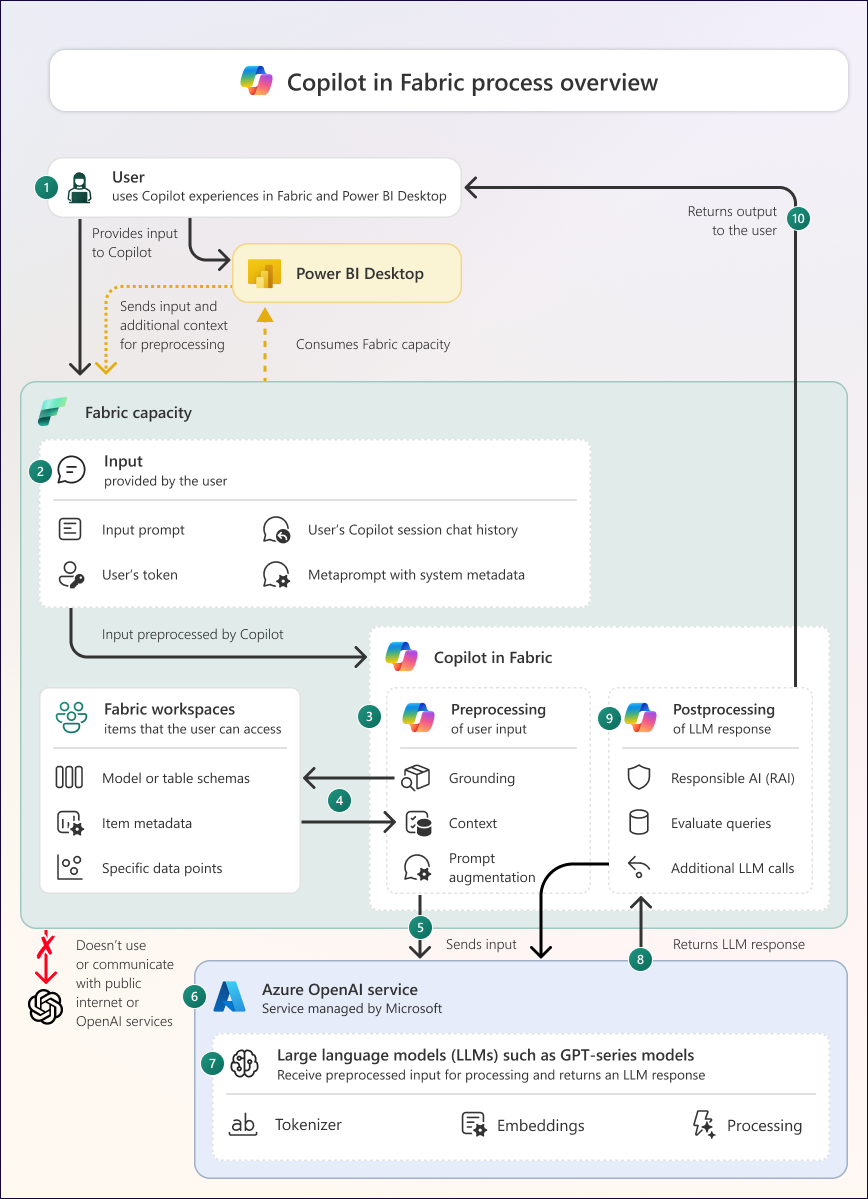
El diagrama consta de las siguientes partes y procesos:
| Elemento | Descripción |
|---|---|
| 1 | El usuario proporciona una entrada a Copilot en Fabric, Power BI Desktop o la aplicación móvil de Power BI. La entrada puede ser un mensaje escrito u otra interacción que genere un mensaje. Todas las interacciones con Copilot son específicas del usuario. |
| 2 | La entrada contiene información que incluye el aviso, el token del usuario y el contexto, como el historial de chat de sesión de Copilot del usuario y un meta-prompt con metadatos del sistema, incluido dónde está el usuario y lo que está haciendo en Fabric o Power BI Desktop. |
| 3 | Copilot controla el preprocesamiento y el postprocesamiento de las entradas de usuario y las respuestas del modelo de lenguaje grande (LLM), respectivamente. Algunos pasos específicos realizados durante el preprocesamiento y el postprocesamiento dependen de la experiencia de Copilot que usa un individuo. Copilot debe estar habilitado por un administrador de Fabric en la configuración del inquilino para usarlo. |
| 4 | Durante el preprocesamiento, Copilot realiza la puesta en tierra para recuperar información contextual adicional para mejorar la especificidad y la utilidad de la respuesta LLM final. Los datos en tierra pueden incluir metadatos (como el esquema de una instancia de almacén de lago de datos o un modelo semántico) o puntos de datos de elementos de un área de trabajo, o el historial de chat de la sesión actual de Copilot. Copilot solo recupera los datos de base a los que un usuario tiene acceso. |
| 5 | El preprocesamiento da como resultado las entradas finales: una solicitud final y datos fundamentales. Los datos que se envían dependen de la experiencia específica de Copilot y de lo que solicita el usuario. |
| 6 | Copilot envía la entrada al servicio Azure OpenAI. Microsoft administra este servicio y el usuario no lo puede configurar. Azure OpenAI no entrena modelos con los datos. Si Azure OpenAI no está disponible en su área geográfica y ha habilitado la configuración de inquilino Los datos enviados a Azure OpenAI se pueden procesar fuera de la región geográfica de la capacidad, el límite de cumplimiento o la instancia de nube nacional, Copilot podría enviar los datos fuera de estas áreas geográficas. |
| 7 | Azure OpenAI hospeda los LLM como la serie GPT de modelos. Azure OpenAI no usa los servicios públicos ni las API de OpenAI y OpenAI no tiene acceso a los datos. Estos LLM tokenizan la entrada y usan incrustaciones de sus datos de entrenamiento para procesar las entradas en una respuesta. Los LLM están limitadas en el ámbito y la escala de sus datos de entrenamiento. Azure OpenAI contiene la configuración que determina cómo procesa LLM la entrada y la respuesta que devuelve. No es posible que los clientes vean o cambien esta configuración. La llamada al servicio OpenAI se realiza a través de Azure y no a través de la red pública de Internet. |
| 8 | La respuesta del LLM se envía desde Azure OpenAI a Copilot en Fabric. Esta respuesta comprende texto, que puede ser lenguaje natural, código o metadatos. La respuesta puede incluir información inexacta o de baja calidad. También es no determinista, lo que significa que se puede devolver una respuesta diferente para la misma entrada. |
| 9 | Copilot posprocesa la respuesta del LLM. El postprocesamiento incluye el filtrado de inteligencia artificial responsable, pero también implica controlar la respuesta del LLM y producir la salida final de Copilot. Los pasos específicos realizados durante el postprocesamiento dependen de la experiencia de Copilot de un uso individual. |
| 10 | Copilot devuelve la salida final al usuario. El usuario comprueba la salida antes de utilizarla, ya que la salida no contiene ninguna indicación de fiabilidad, exactitud o confianza. |
En las secciones siguientes se describen los cinco pasos del proceso de Copilot que se muestra en el diagrama anterior. Estos pasos explican en detalle cómo Copilot va de la entrada del usuario a la salida del usuario.
Paso 1: Un usuario proporciona una entrada a Copilot
Para usar Copilot, un usuario primero debe enviar una entrada. Esta entrada puede ser un mensaje escrito que el usuario envía o puede ser un mensaje generado por Copilot cuando el usuario selecciona un elemento interactivo en la interfaz de usuario. Dependiendo de la experiencia específica de Fabric, elemento y Copilot que alguien usa, tienen diferentes maneras de proporcionar una entrada a Copilot.
En las secciones siguientes se describen varios ejemplos de cómo un usuario puede proporcionar entradas a Copilot.
Entrada a través del panel de chat de Copilot
Con muchas experiencias de Copilot en Fabric, puede ampliar un panel de chat de Copilot para interactuar con Copilot mediante lenguaje natural como lo haría con un bot de chat o un servicio de mensajería. En el panel de chat de Copilot, puede escribir un mensaje de lenguaje natural que describa la acción que desea que Realice Copilot. Como alternativa, el panel de chat de Copilot puede contener botones con avisos sugeridos que puede seleccionar. La interacción con estos botones hace que Copilot genere un mensaje correspondiente.
En la imagen siguiente se muestra un ejemplo del uso del panel de chat de Copilot para formular una pregunta de datos sobre un informe de Power BI.

Nota:
Si usa el explorador Microsoft Edge, es posible que también tenga acceso a Copilot allí. Copilot in Edge también puede abrir un panel de chat de Copilot (o barra lateral) en el explorador. Copilot en Edge no puede interactuar ni usar ninguna de las experiencias de Copilot en Fabric. Aunque ambos Copilots tienen una experiencia de usuario similar, Copilot en Edge es completamente independiente de Copilot en Fabric.
Entrada a través de ventanas emergentes dependientes del contexto
En determinadas experiencias, puede seleccionar el icono de Copilot para desencadenar una ventana emergente para interactuar con Copilot. Algunos ejemplos son cuando utilizas Copilot en la vista de consulta DAX o en la vista de scripting TMDL de Power BI Desktop. Esta ventana emergente contiene un área para que escriba un mensaje de lenguaje natural (similar al panel de Copilot Chat), así como botones específicos del contexto que pueden generar una solicitud para usted. Esta ventana también puede contener información de salida, como explicaciones sobre consultas DAX o conceptos al usar Copilot en la vista de consulta DAX.
En la imagen siguiente se muestra un ejemplo de alguien que usa la experiencia de Copilot en la vista de consulta DAX para explicar una consulta que generó mediante Copilot en Power BI.

Tipos de entradas de usuario
Las entradas de Copilot pueden ser desde un mensaje escrito o un botón en la interfaz de usuario:
Mensaje escrito: Un usuario puede escribir un mensaje en el panel de chat de Copilot o en otras experiencias de Copilot, como la vista de consulta DAX en Power BI Desktop. Las indicaciones escritas requieren que el usuario explique adecuadamente la instrucción o pregunta de Copilot. Por ejemplo, un usuario puede hacer una pregunta sobre un modelo semántico o un informe al usar Copilot en Power BI.
Botón: Un usuario puede seleccionar un botón en el panel de chat de Copilot u otras experiencias de Copilot para proporcionar una entrada. A continuación, Copilot genera el mensaje en función de la selección del usuario. Estos botones pueden ser la entrada inicial de Copilot, como las sugerencias en el panel de chat de Copilot. Sin embargo, estos botones también pueden aparecer durante una sesión cuando Copilot realiza sugerencias o solicitudes de aclaraciones. El mensaje que genera Copilot depende del contexto, como el historial de chat de la sesión actual. Un ejemplo de entrada de botón es cuando se pide a Copilot que sugiera sinónimos para campos de modelo o descripciones para las medidas del modelo.
Además, puede proporcionar entradas en diferentes servicios o aplicaciones:
Fabric: Puede usar Copilot en Fabric desde el explorador web. Esta es la única manera de usar Copilot para cualquier elemento que exclusivamente crees, administres y consumas en Fabric.
Power BI Desktop: Puede usar Copilot en Power BI Desktop con informes y modelos semánticos. Entre ellas se incluyen las experiencias de Copilot de desarrollo y consumo para la carga de trabajo de Power BI en Fabric.
Aplicación móvil de Power BI: Puede usar Copilot en la aplicación móvil de Power BI si el informe está en un área de trabajo compatible (o una aplicación conectada a esa área de trabajo) con Copilot habilitado.
Nota:
Para usar Copilot con Power BI Desktop, debe configurar Power BI Desktop para usar el consumo de Copilot desde un área de trabajo compatible respaldada por la capacidad de Fabric. A continuación, puede usar Copilot con modelos semánticos publicados en cualquier área de trabajo, incluidas las áreas de trabajo Pro y PPU.
Aunque no se pueden modificar las indicaciones que Genera Copilot al seleccionar un botón con avisos escritos, puede hacer preguntas y proporcionar instrucciones mediante lenguaje natural. Una de las formas más importantes de mejorar los resultados que obtiene con Copilot es escribir mensajes claros y descriptivos que transmitan con precisión lo que desea hacer.
Mejora de las solicitudes escritas para Copilot
La claridad y la calidad de la solicitud que un usuario envía a Copilot puede afectar a la utilidad de la salida que recibe el usuario. Lo que constituye un buen mensaje escrito depende de la experiencia específica de Copilot que esté usando; sin embargo, hay algunas técnicas que se pueden aplicar a todas las experiencias para mejorar sus mensajes en general.
Estas son varias maneras de mejorar las solicitudes que envíe a Copilot:
Use avisos en inglés: Hoy en día, las características de Copilot funcionan mejor en inglés. Esto se debe a que el corpus de datos de entrenamiento de estos LLM es mayoritariamente inglés. Es posible que otros lenguajes no funcionen bien. Puede intentar escribir mensajes en otros idiomas, pero para obtener los mejores resultados, se recomienda escribir y enviar mensajes en inglés.
Sea específico: Evite ambigüedad o imprecisión en preguntas e instrucciones. Incluya detalles suficientes para describir la tarea que desea que Copilot realice y cuál es la salida que espera.
Proporcionar contexto: Cuando sea necesario, proporcione el contexto pertinente para la solicitud, incluida lo que usted desea lograr o qué pregunta desea responder con el resultado. Por ejemplo, los componentes clave de un mensaje correcto podrían incluir:
- Objetivo: Qué resultado desea que Copilot logre.
- Contexto: Qué piensa hacer con esa salida concreta y por qué.
- Expectativas: cómo espera que sea el resultado.
- Fuente: Qué datos o campos debe usar Copilot.
Usar verbos: Consulte explícitamente las acciones específicas que desea que Realice Copilot, como "crear una página de informe" o "filtrar a cuentas de clave de cliente".
Use la terminología correcta y pertinente: Consulte explícitamente los términos adecuados en su solicitud, como nombres de funciones, campos o tablas, tipos visuales o terminología técnica. Evite errores ortográficos, acrónimos o abreviaturas, así como gramática superflua o caracteres inusuales como caracteres Unicode o emojis.
Iteración y solución de problemas: Cuando no obtenga el resultado esperado, intente ajustar el mensaje y volver a enviarlo para ver si esto mejora la salida. Algunas experiencias de Copilot también proporcionan un botón Reintentar para volver a enviar el mismo mensaje y comprobar si hay un resultado diferente.
Importante
Considere la posibilidad de entrenar a los usuarios para escribir mensajes correctos antes de habilitar Copilot para ellos. Asegúrese de que los usuarios comprendan la diferencia entre una solicitud clara que pueda generar resultados útiles y un mensaje impreciso que no lo haga.
Además, Copilot y muchas otras herramientas de LLM son no deterministas. Esto significa que dos usuarios que envían la misma solicitud que usa los mismos datos de base pueden obtener resultados diferentes. Este no determinismo es inherente a la tecnología subyacente de inteligencia artificial generativa y es una consideración importante cuando espera o necesita resultados deterministas, como una respuesta a una pregunta de datos, como "¿Cuáles son las ventas en agosto de 2021?"
Otra información de entrada que Copilot usa en el preprocesamiento
Además de la entrada que proporciona un usuario, Copilot también recupera información adicional que usa en el preprocesamiento durante el paso siguiente. Esta información incluye:
Token del usuario. Copilot no funciona con una cuenta o autoridad del sistema. Toda la información enviada y utilizada por Copilot es específica del usuario; Copilot no puede permitir que un usuario vea o acceda a elementos o datos que aún no tienen permiso para ver.
Historial de chats de sesión de Copilot para la sesión actual. Para las experiencias de chat o el panel de Copilot Chat, Copilot siempre proporciona el historial de chat para su uso en el preprocesamiento como parte del contexto de datos de fundamento. Copilot no recuerda ni usa el historial de chat de sesiones anteriores.
Meta-prompt con metadatos del sistema. Un meta-prompt proporciona contexto adicional sobre dónde está el usuario y lo que está haciendo en Fabric o Power BI Desktop. Esta información de metadatos se usa durante el preprocesamiento para determinar qué aptitud o herramienta Debe usar Copilot para responder a la pregunta del usuario.
Una vez que un usuario envía su entrada, Copilot continúa con el paso siguiente.
Paso 2: Copilot preprocesa la entrada
Antes de enviar un mensaje al servicio Azure OpenAI, Copilot lo preprocesa . El preprocesamiento constituye todas las acciones que controla Copilot entre cuando recibe la entrada y cuando esta entrada se procesa en el servicio Azure OpenAI. El preprocesamiento es necesario para asegurarse de que la salida de Copilot sea específica y adecuada para sus instrucciones o preguntas.
No puede afectar al preprocesamiento que realiza Copilot. Sin embargo, es importante comprender el preprocesamiento para que sepa qué datos usa Copilot y cómo lo obtiene. Esto es pertinente para comprender el costo de Copilot en Fabric y, al solucionar problemas, se produce un resultado incorrecto o inesperado.
Sugerencia
En determinadas experiencias, también puede realizar cambios en los elementos para que sus datos de base se estructuren mejor para que Copilot los use. Un ejemplo es realizar el modelado lingüístico en un modelo semántico o agregar sinónimos y descripciones a las medidas y columnas del modelo semántico.
En el diagrama siguiente se muestra lo que sucede durante el preprocesamiento de Copilot en Fabric.
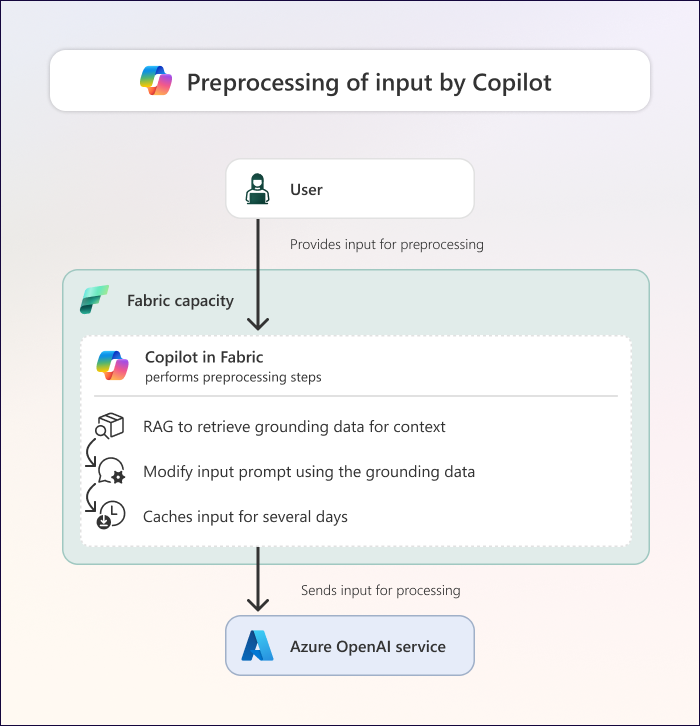
Después de recibir la entrada del usuario, Copilot realiza el preprocesamiento, lo que implica los pasos siguientes:
Fundamento: Copilot realiza la recuperación de generación aumentada (RAG) para recopilar datos de fundamento. Los datos de fundamento constan de información relevante del contexto actual en el que se usa Copilot en Fabric. Los datos de puesta a tierra pueden incluir contextos como:
- Historial de chat de la sesión actual con Copilot.
- Metadatos sobre el elemento de Fabric que usa con Copilot (como el esquema del modelo semántico o almacén de lago de datos, o metadatos de un objeto visual de informe).
- Puntos de datos específicos, como los que se muestran en una visualización de informe. Los metadatos de informe de la configuración visual también contienen puntos de datos.
- Meta-prompts, que son instrucciones complementarias proporcionadas para cada experiencia para ayudar a garantizar una salida más específica y coherente.
Aumento de la petición: En función del escenario, Copilot vuelve a escribir (o aumenta) el mensaje en función de los datos de entrada y de tierra. El mensaje aumentado debe ser mejor y tener más en cuenta el contexto que el mensaje de entrada original.
Caché: En determinados escenarios, Copilot almacena en caché el mensaje y los datos de puesta en tierra durante 48 horas. El almacenamiento en caché de la solicitud garantiza que las solicitudes repetidas devuelvan los mismos resultados mientras se almacenan en caché, que devuelven estos resultados más rápido y que no consume la capacidad de Fabric solo para repetir un mensaje en el mismo contexto. El almacenamiento en caché se produce en dos lugares diferentes:
- Caché del explorador del usuario.
- La primera caché de backend en la región principal del inquilino, donde se almacena con fines de auditoría. No se almacena en caché ningún dato en el servicio Azure OpenAI ni en la ubicación de las GPU. Para obtener más información sobre el almacenamiento en caché en Fabric, consulte las notas del producto sobre seguridad de Microsoft Fabric.
Envío de entrada a Azure OpenAI: Copilot envía el mensaje aumentado y los datos de puesta a tierra pertinentes al servicio Azure OpenAI.
Cuando Copilot realiza la puesta en tierra, solo recopila información de datos o elementos a los que un usuario puede acceder normalmente. Copilot respeta los roles del área de trabajo, los permisos de elemento y la seguridad de los datos. Copilot tampoco puede acceder a los datos de otros usuarios; las interacciones con Copilot son específicas de cada usuario individual.
Los datos que Copilot recopila durante el proceso de configuración y lo que Azure OpenAI procesa dependen de la experiencia específica de Copilot que use. Para obtener más información, consulte ¿Qué datos usa Copilot y cómo se procesa?.
Una vez finalizado el preprocesamiento y Copilot ha enviado la entrada a Azure OpenAI, el servicio Azure OpenAI puede procesar esa entrada para generar una respuesta y una salida que se envíen de vuelta a Copilot.
Paso 3: Azure OpenAI procesa el mensaje y genera una salida
Todas las experiencias de Copilot cuentan con la tecnología del servicio Azure OpenAI.
Descripción del servicio Azure OpenAI
Copilot usa Azure OpenAI (no los servicios disponibles públicamente de OpenAI) para procesar todos los datos y devolver una respuesta. Como se mencionó anteriormente, una LLM genera esta respuesta. Los LLM son un enfoque específico de la inteligencia artificial "estrecha" que se centra en el uso del aprendizaje profundo para buscar y reproducir patrones en datos no estructurados; específicamente, texto. El texto de este contexto incluye lenguaje natural, metadatos, código y cualquier otra disposición semánticamente significativa de caracteres.
Copilot actualmente usa una combinación de modelos GPT, incluida la serie transformador generativo preentrenado (GPT) de modelos de OpenAI.
Nota:
No puede elegir ni cambiar los modelos que Usa Copilot, incluido el uso de otros modelos básicos o sus propios modelos. Copilot en Fabric usa varios modelos. Tampoco es posible modificar o configurar el servicio Azure OpenAI para que se comporte de forma diferente con Copilot en Fabric; Microsoft administra este servicio.
Actualmente, los modelos usados por Copilot en Fabric no usan ningún ajuste preciso. En su lugar, los modelos se basan en datos y meta-prompts para crear salidas más específicas y útiles.
Actualmente, los modelos usados por Copilot en Fabric no usan ningún ajuste preciso. En su lugar, los modelos se basan en datos y meta-prompts para crear salidas más específicas y útiles.
Microsoft hospeda los modelos de OpenAI en el entorno de Azure de Microsoft y el servicio no interactúa con ningún servicio público de OpenAI (por ejemplo, ChatGPT o las API públicas de OpenAI). Los datos no se usan para entrenar modelos y no están disponibles para otros clientes. Para más información, consulte Azure OpenAI Service.
Descripción de la tokenización
Es esencial que comprenda la tokenización, ya que el costo de Copilot en Fabric (que es la cantidad de capacidad que consume Copilot de Fabric) viene determinado por el número de tokens generados por las entradas y salidas de Copilot.
Para procesar la entrada de texto de Copilot, Azure OpenAI primero debe convertir esa entrada en una representación numérica. Un paso clave de este proceso es la tokenización, que es la creación de particiones del texto de entrada en diferentes partes más pequeñas, denominadas tokens. Un símbolo es un conjunto de caracteres que aparecen conjuntamente, y es la unidad de información más pequeña que un LLM utiliza para generar su resultado. Cada token tiene un identificador numérico correspondiente, que se convierte en el vocabulario del LLM para codificar y usar texto como números. Hay diferentes maneras de tokenizar el texto, y los diferentes LLM tokenizan el texto de entrada de diferentes maneras. Azure OpenAI usa la codificación de pares de bytes (BPE), que es un método de tokenización de subpalabras.
Para comprender mejor qué es un token y cómo un aviso se convierte en tokens, considere el ejemplo siguiente. En este ejemplo se muestra un mensaje de entrada y sus tokens, estimados mediante el tokenizador de la plataforma OpenAI (para GPT4). Debajo de los tokens resaltados en el texto del mensaje se encuentra una matriz (o lista) de los identificadores numéricos de token.

En el ejemplo, cada resaltado de color diferente indica un único token. Como se mencionó anteriormente, Azure OpenAI usa la tokenización de subword , por lo que un token no es una palabra, pero tampoco es un carácter o un número fijo de caracteres. Por ejemplo , "report" es un solo token, pero "." también lo es.
Para repetir, debe comprender qué es un token porque el costo de Copilot (o su tasa de consumo de capacidad de Fabric) está determinado por tokens. Por lo tanto, comprender qué es un token y cómo se crean los tokens de entrada y salida le ayuda a comprender y anticipar cómo el uso de Copilot da como resultado el consumo de CPU de Fabric. Para obtener más información sobre el costo de Copilot en Fabric, consulte la sección adecuada más adelante en este artículo.
Copilot en Fabric usa tokens de entrada y salida, como se muestra en el diagrama siguiente.

Copilot crea dos tipos diferentes de tokens:
- Los tokens de entrada se derivan de la tokenización tanto del aviso final como de los datos de puesta en tierra.
- Los tokens de salida resultan de la tokenización de la respuesta LLM.
Algunas experiencias de Copilot producen varias llamadas del LLM. Por ejemplo, al hacer una pregunta de datos sobre modelos e informes, la primera respuesta de un LLM podría ser una consulta evaluada contra un modelo semántico. A continuación, Copilot envía el resultado de esa consulta evaluada a Azure OpenAI de nuevo y solicita un resumen, que Azure OpenAI devuelve con otra respuesta. Estas llamadas adicionales de LLM se pueden gestionar, y las respuestas del LLM se pueden combinar durante el paso de postprocesamiento.
Nota:
Con Copilot en Fabric, excepto los cambios en un mensaje de entrada escrito, solo puede optimizar los tokens de entrada y salida ajustando la configuración de los elementos pertinentes, como ocultar columnas en un modelo semántico o reducir el número de objetos visuales o páginas de un informe. No puede interceptar ni modificar los datos de puesta en tierra antes de enviarlos a Azure OpenAI by Copilot.
Descripción del procesamiento
Es importante que comprenda cómo un LLM de Azure OpenAI procesa los datos y genera una salida, de modo que pueda comprender mejor por qué obtiene determinadas salidas de Copilot y por qué debe valorarlos de forma crítica antes de usar o tomar decisiones.
Nota:
Este artículo proporciona una información general simple y de alto nivel de cómo funcionan los LLM que utiliza Copilot (como los GPT). Para obtener detalles técnicos y una comprensión más profunda de cómo los modelos GPT procesan la entrada para generar una respuesta, o sobre su arquitectura, lea los artículos de investigación Attention Is All You Need (2017) de Ashish Vaswani y otros, y Los modelos de lenguaje son Few-Shot Alumnos (2020) de Tom Brown y otros.
El propósito de Copilot (y LLM en general) es proporcionar una salida útil y adecuada para el contexto, en función de la entrada que proporciona un usuario y otros datos de base pertinentes. Un LLM lo hace interpretando el significado de los tokens en un contexto similar, como se ve en sus datos de entrenamiento. Para obtener una comprensión semántica significativa de los tokens, los LLM se han entrenado en conjuntos de datos masivos pensados para integrar tanto información protegida por derechos de autor como información de dominio público. Sin embargo, estos datos de entrenamiento están limitados en cuanto a actualización, calidad y ámbito de contenido, lo que crea limitaciones para los modelos de lenguaje extensos (MLE) y las herramientas que los usan, como Copilot. Para obtener más información sobre estas limitaciones, consulte Descripción de las limitaciones de Copilot y LLMs más adelante en este artículo.
El significado semántico de un token se captura en una construcción matemática denominada inserción, que convierte los tokens en vectores densos de números reales. En términos más sencillos, las inserciones proporcionan a las LLM el significado semántico de un token determinado, en función de los demás tokens que lo rodean. Este significado depende de los datos de entrenamiento de LLM. Piensa en los tokens como bloques de creación únicos, mientras que las incrustaciones ayudan a un LLM a saber qué bloque utilizar en cada momento.
Con tokens e incrustaciones, LLM en Azure OpenAI procesa la entrada y genera una respuesta. Este procesamiento es una tarea de proceso intensivo que requiere recursos significativos, que es donde procede el costo. Un LLM genera su respuesta un token a la vez, seleccionando cada token basándose en una probabilidad calculada a partir del contexto de entrada. Cada token generado también se agrega a ese contexto existente antes de generar el siguiente token. Por lo tanto, la respuesta final del LLM debe ser siempre texto, que Copilot podría postprocesar posteriormente para hacer una salida más útil para el usuario.
Es importante comprender varios aspectos clave sobre esta respuesta generada:
- Es no determinista; la misma entrada puede generar una respuesta diferente.
- El usuario puede interpretarlo como de baja calidad o incorrecto en su contexto.
- Se basa en los datos de entrenamiento de LLM, que son finitos y limitados en su ámbito.
Descripción de las limitaciones de Copilot y LLMs
Es importante comprender y reconocer las limitaciones de Copilot y la tecnología subyacente que usa. Comprender estas limitaciones le ayuda a obtener valor de Copilot, a la vez que mitiga los riesgos inherentes al uso. Para usar Copilot en Fabric de forma eficaz, debe comprender los casos de uso y los escenarios que mejor se adapten a esta tecnología.
Es importante tener en cuenta las siguientes consideraciones al usar Copilot en Fabric:
Copilot en Fabric no es determinista. Excepto cuando se almacena en caché una solicitud y su salida, la misma entrada puede generar salidas diferentes. Cuando admite una gama de posibles salidas, como una página de informe, un patrón de código o un resumen, esto es menos problemático, ya que puede tolerar e incluso esperar variedad en la respuesta. Sin embargo, en escenarios en los que solo se espera una respuesta correcta, es posible que desee considerar un enfoque alternativo para Copilot.
Copilot en Fabric puede producir salidas de baja calidad o inexactas: Al igual que todas las herramientas de LLM, es posible que Copilot genere salidas que podrían no ser correctas, esperadas o adecuadas para su escenario. Esto significa que debe evitar el uso de Copilot en Fabric con datos confidenciales o en áreas de alto riesgo. Por ejemplo, no debe usar salidas de Copilot para responder a preguntas de datos sobre procesos críticos para la empresa o para crear soluciones de datos que puedan afectar al bienestar personal o colectivo de las personas. Los usuarios deben comprobar y validar las salidas de Copilot antes de usarlas.
Copilot no entiende la "precisión" ni la "veracidad": Las respuestas que genera Copilot no ofrecen una indicación de confiabilidad, fiabilidad ni sentimientos similares. La tecnología subyacente implica el reconocimiento de patrones y no puede evaluar la calidad o la utilidad de sus salidas. Los usuarios deben evaluar críticamente las salidas antes de usar estas salidas en otros trabajos o decisiones.
Copilot no puede razonar, comprender su intención o conocer el contexto más allá de su entrada: Aunque el proceso de puesta a tierra de Copilot garantiza que las salidas sean más específicas, la base por sí sola no puede proporcionar a Copilot toda la información que necesita para responder a sus preguntas. Por ejemplo, si usa Copilot para generar código, Copilot todavía no sabe lo que hará con ese código. Esto significa que el código puede funcionar en un contexto, pero no en otro, y los usuarios deben modificar la salida o su solicitud para solucionarlo.
Las salidas de Copilot están limitadas por los datos de entrenamiento de los LLM que utiliza: en determinadas experiencias de Copilot, como aquellas en las que genera código, es posible que desee que Copilot genere código con una función o patrón recién publicado. Sin embargo, Copilot no podrá hacerlo eficazmente si no hay ejemplos de eso en los datos de entrenamiento de los modelos GPT que utiliza, que tiene un límite en el pasado. Esto también sucede cuando intenta aplicar Copilot a contextos dispersos en sus datos de entrenamiento, como cuando se usa Copilot con el editor TMDL en Power BI Desktop. En estos escenarios, debe estar especialmente atento y crítico con los resultados de baja calidad o inexactos.
Advertencia
Para mitigar los riesgos de estas limitaciones y consideraciones, y dado que Copilot, los LLMs y la IA generativa son tecnologías incipientes, no debería utilizar Copilot en Fabric para procesos autónomos, de alto riesgo, o críticos empresariales y en la toma de decisiones.
Para obtener más información, consulte la guía de seguridad de los LLM.
Una vez que el servicio Azure OpenAI procesa la entrada y genera una respuesta, devuelve esta respuesta como salida a Copilot.
Paso 4: Copilot realiza el postprocesamiento en la salida
Al recibir la respuesta de Azure OpenAI, Copilot realiza postprocesamiento adicional para asegurarse de que la respuesta es adecuada. El propósito del postprocesamiento es filtrar contenido inapropiado.
Para realizar el posprocesamiento, Copilot puede realizar las siguientes tareas:
Comprobaciones de IA responsables: Asegurarse de que Copilot cumple con los estándares de inteligencia artificial responsables en Microsoft. Para obtener más información, consulte ¿Qué debo saber para usar Copilot de forma responsable?
Filtrado con moderación de contenido de Azure: Filtrar respuestas para asegurarse de que Copilot solo devuelve las respuestas adecuadas para el escenario y la experiencia. Estos son algunos ejemplos de cómo Copilot realiza el filtrado con moderación de contenido de Azure:
- Uso no deseado o incorrecto: La moderación de contenido garantiza que no puede usar Copilot de maneras no deseadas o incorrectas, como formular preguntas sobre otros temas fuera del ámbito de la carga de trabajo, el elemento o la experiencia que está usando.
- Salidas inapropiadas o ofensivas: Copilot evita salidas que podrían contener lenguaje, términos o frases inaceptables.
- Intentos de inyección de mensajes: Copilot evita la inyección de mensajes, donde los usuarios intentan ocultar instrucciones disruptivas en datos de puesta en tierra, como en nombres de objeto, descripciones o comentarios de código en un modelo semántico.
Restricciones específicas del escenario: Dependiendo de la experiencia de Copilot que use, es posible que haya comprobaciones adicionales y control de la respuesta LLM antes de recibir el resultado. Estos son algunos ejemplos de cómo Copilot aplica restricciones específicas del escenario:
- Analizadores de código: El código generado puede colocarse a través de un analizador para filtrar las respuestas y errores de baja calidad para asegurarse de que el código se ejecuta. Esto sucede cuando genera consultas DAX mediante Copilot en la vista de consulta DAX de Power BI Desktop.
- Validación de objetos visuales e informes: Copilot comprueba que los objetos visuales e informes se pueden representar antes de devolverlos en una salida. Copilot no valida si los resultados son precisos o útiles, o si la consulta resultante agotará el tiempo de espera (y generará un error).
Control y uso de la respuesta: Tomar la respuesta y agregar información adicional o usarla en otros procesos para proporcionar la salida al usuario. Estos son algunos ejemplos de cómo Copilot podría controlar y usar una respuesta durante el posprocesamiento:
- Creación de páginas de informes de Power BI: Copilot combina la respuesta LLM (metadatos visuales de informe) con otros metadatos de informe, lo que da como resultado la creación de una nueva página de informe. Copilot también puede aplicar un tema de Copilot si aún no ha creado ningún elemento visual en el informe. El tema no forma parte de la respuesta LLM e incluye una imagen de fondo, así como colores y estilos visuales. Si ha creado objetos visuales, Copilot no aplica el tema de Copilot y usa el tema que ya ha aplicado. Al cambiar una página de informe, Copilot también eliminará la página existente y la reemplazará por una nueva por los ajustes aplicados.
- Preguntas sobre datos de Power BI: Copilot evalúa una consulta con un modelo semántico.
- Sugerencia para el paso de transformación gen2 del flujo de datos en Data Factory: Copilot modifica los metadatos del elemento de datos para insertar el nuevo paso, ajustando la consulta.
Llamadas LLM adicionales: En determinados escenarios, Copilot podría realizar llamadas LLM adicionales para enriquecer la salida. Por ejemplo, Copilot podría enviar el resultado de una consulta evaluada al LLM como una nueva entrada y solicitar una explicación. Esta explicación del lenguaje natural se empaqueta junto con el resultado de la consulta en la salida que un usuario ve en el panel de chat de Copilot.
Si el contenido se filtra en la salida, Copilot volverá a enviar un mensaje nuevo, modificado o devolverá una respuesta estándar.
Vuelva a enviar un mensaje nuevo: Cuando una respuesta no cumple las restricciones específicas del escenario, Copilot generará otro mensaje modificado para volver a intentarlo. En algunas circunstancias, Copilot podría sugerir varias solicitudes nuevas para que el usuario seleccione antes de enviar el mensaje para generar una nueva salida.
Respuesta estándar: La respuesta estándar en este caso indicaría un error genérico. En función del escenario, Copilot puede proporcionar información adicional para guiar al usuario a generar otra entrada.
Nota:
No es posible ver las respuestas originales filtradas de Azure OpenAI ni modificar las respuestas estándar de Copilot. Microsoft administra esto.
Una vez completado el postprocesamiento, Copilot devolverá una salida al usuario.
Paso 5: Copilot devuelve la salida al usuario
La salida de un usuario puede adoptar la forma de lenguaje natural, código o metadatos. Normalmente, estos metadatos se representarán en la interfaz de usuario de Fabric o Power BI Desktop, como cuando Copilot devuelve un objeto visual de Power BI o sugiere una página de informe. Para algunas experiencias de Copilot en Power BI, el usuario puede proporcionar entradas y salidas a Copilot a través de la aplicación móvil de Power BI.
En general, las salidas pueden permitir la intervención del usuario o ser totalmente autónomas y no permitir que el usuario modifique el resultado.
Intervención del usuario: Estas salidas permiten a un usuario modificar el resultado antes de evaluarlo o mostrarlo. Algunos ejemplos de salidas que permiten la intervención del usuario incluyen:
- Generación de código como consultas DAX o SQL, que un usuario puede elegir mantener o ejecutar.
- Generación de descripciones de medida en un modelo semántico, que un usuario puede elegir mantener, modificar o eliminar.
Autónomo: El usuario no puede modificar estas salidas. El código se puede evaluar directamente contra un elemento Fabric, o el texto no se puede editar en el panel. Algunos ejemplos de salidas autónomas son:
- Respuestas a preguntas de datos sobre un modelo semántico o informe en el panel de chat de Copilot, que evalúa automáticamente las consultas en el modelo y muestran el resultado.
- Resúmenes o explicaciones de código, elementos o datos, que eligen automáticamente qué resumir y explicar, y muestran el resultado.
- Creación de una página de informe, que crea automáticamente la página y los objetos visuales del informe.
A veces, como parte del resultado, Copilot también podría sugerir un aviso adicional a seguir, como solicitar una aclaración u otra sugerencia. Esto suele ser útil cuando el usuario quiere mejorar el resultado o seguir trabajando en una salida específica, como explicar un concepto para comprender el código generado.
Las salidas de Copilot pueden contener contenido de baja calidad o inexacto
Copilot no tiene ninguna manera de evaluar o indicar la utilidad o precisión de sus salidas. Por lo tanto, es importante que los usuarios lo evalúen cada vez que usen Copilot.
Para mitigar los riesgos o desafíos de las alucinaciones LLM en Copilot, tenga en cuenta los siguientes consejos:
Entrene a los usuarios para que usen Copilot y otras herramientas similares que aprovechen los LLMs. Considere la posibilidad de entrenarlos en los temas siguientes:
- Lo que Copilot puede y no puede hacer.
- Cuándo usar Copilot y cuándo no usarlo.
- Cómo escribir mejores indicaciones.
- Cómo resolver problemas relacionados con resultados inesperados.
- Cómo validar las salidas mediante orígenes, técnicas o recursos en línea de confianza.
Pruebe los elementos con Copilot antes de permitir que estos elementos se usen con él. Algunos elementos requieren ciertas tareas preparatorias para asegurarse de que funcionan bien con Copilot.
Evite usar Copilot en procesos de toma de decisiones autónomos, de alto riesgo o críticos para la empresa.
Importante
Además, revise los términos de versión preliminar complementarios de Fabric, que incluyen los términos de uso para las versiones preliminares de Microsoft Generative AI Service. Aunque puede probar y experimentar con estas características en versión preliminar, se recomienda no usar las características de Copilot en versión preliminar en las soluciones de producción.
Privacidad, seguridad e inteligencia artificial responsable
Microsoft se compromete a garantizar que nuestros sistemas de inteligencia artificial estén guiados por nuestros principios de inteligencia artificial y estándar de inteligencia artificial responsable. Consulte Privacidad, seguridad y uso responsable de Copilot en Fabric para obtener información general detallada. Consulte también Datos, privacidad y seguridad del servicio Azure OpenAI para obtener información detallada específica para Azure OpenAI.
Para obtener información general específica para cada carga de trabajo de Fabric, consulte los artículos siguientes:
- Uso responsable en Data Factory
- Uso responsable en ciencia de datos e ingeniería de datos
- Uso responsable en el almacenamiento de datos
- Uso responsable en Power BI
- Uso responsable en Real-Time Intelligence
Costo de Copilot en Fabric
A diferencia de otros Copilots de Microsoft, Copilot en Fabric no requiere licencias adicionales por usuario o por capacidad. En su lugar, Copilot en Fabric consume de sus unidades de capacidad (CU) de Fabric disponibles. La tasa de consumo de Copilot se determina por el número de tokens en tus entradas y salidas cuando se utiliza en las diferentes experiencias de Fabric.
Si tiene capacidad para Fabric, está utilizando una instancia de pago por uso o reservada. En ambos casos, el consumo de Copilot funciona igual. En un escenario de pago por uso, se le factura por segundo que la capacidad está activa hasta que se pausa la capacidad. Las tarifas de facturación no tienen relación con el uso de las CPU de Fabric; usted paga la misma cantidad si su capacidad está totalmente utilizada o completamente sin usar. Por lo tanto, Copilot no tiene un costo directo ni un impacto en la facturación de Azure. En su lugar, Copilot consume de las CU disponibles que otras cargas de trabajo y elementos de Fabric también utilizan, y si utiliza demasiadas, los usuarios experimentarán un rendimiento reducido y limitación. También es posible entrar en un estado de deuda CU llamado transporte. Para obtener más información sobre la limitación y el transporte hacia adentro, consulte Fases de limitación y desencadenadores de limitación.
En las siguientes secciones se explicará más sobre cómo entender y gestionar el uso de Copilot en Fabric.
Nota:
Para obtener más información, consulte Consumo de Copilot en Fabric.
El consumo de Copilot en Fabric viene determinado por tokens
Copilot consume las CU de Fabric disponibles, también conocidas como capacidad, procesoo recursos. El consumo viene determinado por los tokens de entrada y salida durante su uso. Para revisarlo, puede comprender los tokens de entrada y salida como resultado de tokenizar lo siguiente:
- Tokens de entrada: tokenización de la indicación escrito y datos de fundamento.
- Tokens de salida: Tokenización de la respuesta de Azure OpenAI, en función de la entrada. Los tokens de salida son tres veces más caros que los tokens de entrada.
Puede limitar el número de tokens de entrada utilizando indicaciones más breves, pero no puede controlar qué datos fundamentales usa Copilot para el preprocesamiento o el número de tokens de salida que devuelve el LLM en Azure OpenAI. Por ejemplo, puede esperar que la experiencia de creación de informes para Copilot en Power BI tenga un alto índice de consumo, ya que podría utilizar datos de base (como el esquema de su modelo) y podría producir una salida detallada (metadatos del informe).
Las entradas, las salidas y los datos de puesta en tierra se convierten en tokens
Para repetir desde una sección anterior de este artículo, es importante comprender el proceso de tokenización para que sepa qué tipos de entradas y salidas producen el consumo más alto.
La optimización de los tokens de indicación no es probable que tenga un efecto significativo en los costos de Copilot. Por ejemplo, el número de tokens en una indicación de usuario escrito suele ser mucho menor que los tokens de datos de fundamento y salidas. Copilot gestiona de forma autónoma los datos de base y las salidas; no puedes optimizar ni influir en estos tokens. Por ejemplo, al usar Copilot en Power BI, Copilot podría usar el esquema del modelo semántico o los metadatos del informe como datos de puesta a tierra durante el preprocesamiento. Es probable que estos metadatos contengan muchos más tokens que el mensaje inicial.
Copilot realiza varias optimizaciones del sistema para reducir los tokens de entrada y salida. Estas optimizaciones dependen de la experiencia de Copilot que usa. Entre los ejemplos de optimizaciones del sistema se incluyen:
Reducción del esquema: Copilot no envía todo el esquema de un modelo semántico o una tabla lakehouse. En su lugar, usa incrustaciones para determinar qué columnas se van a enviar.
Aumento de la petición: Al volver a escribir el mensaje durante el preprocesamiento, Copilot intenta generar un mensaje final que devolverá un resultado más específico.
Además, hay varias optimizaciones de usuario que puedes implementar para limitar qué datos de referencia Copilot puede ver y usar. Estas optimizaciones del usuario dependen del elemento y la experiencia que estás usando. Algunos ejemplos de optimizaciones de usuario son:
Ocultar campos o marcar tablas como privadas en un modelo semántico: Copilot no considerará ningún objeto oculto o privado.
Ocultar páginas o objetos visuales de informe: Del mismo modo, Copilot tampoco tiene en cuenta las páginas o objetos visuales ocultos detrás de un marcador de informe.
Sugerencia
Las optimizaciones de usuario son principalmente eficaces para mejorar la utilidad de las salidas de Copilot, en lugar de optimizar el costo de Copilot. Para obtener más información, consulte artículos específicos de las distintas cargas de trabajo y experiencias de Copilot.
No tiene visibilidad sobre el proceso de tokenización y solo puede afectar mínimamente a los tokens de entrada y salida. Por lo tanto, la forma más eficaz de administrar el consumo de Copilot y evitar la limitación es gestionar cómo se utiliza Copilot.
Copilot es una operación en segundo plano que se suaviza
El uso simultáneo de Copilot en Fabric, cuando muchas personas lo usan al mismo tiempo, se controla mediante un proceso denominado suavizado. En Fabric, cualquier operación clasificada como una operación en segundo plano tiene su consumo de CU dividido en un período de 24 horas, comenzando desde el momento de la operación hasta exactamente 24 horas más tarde. Esto contrasta con las operaciones interactivas, como las consultas de modelos semánticos de usuarios que usan un informe de Power BI, que no se suavizan.
Nota:
Para simplificar la comprensión, las operaciones en segundo plano e interactivas clasifican diferentes cosas que se producen en Fabric con fines de facturación. No necesariamente se relacionan con si un elemento o una característica es interactivo para un usuario o sucede en segundo plano, como podrían sugerir sus nombres.
Por ejemplo, si usa 48 CU con una operación en segundo plano ahora, resulta en 2 CU de consumo ahora, y también 2 CU cada hora desde ahora hasta dentro de 24 horas. Si usa 48 CU con una operación interactiva, da como resultado 48 CU observadas usadas ahora y no tiene ningún efecto en el consumo futuro. Sin embargo, el suavizado también significa que puede acumular el consumo de CU en esa ventana si el uso de Copilot u otras cargas de trabajo de Fabric es lo suficientemente alto.
Para comprender mejor el suavizado y sus efectos en el consumo de CU de Fabric, tenga en cuenta el diagrama siguiente:

En el diagrama se muestra un ejemplo de una situación con un uso simultáneo elevado de una operación interactiva (que no está suavizada). Una operación interactiva cruza el límite (la capacidad disponible de Fabric) y entra en el transporte. Este es el escenario sin suavizar. En cambio, las operaciones en segundo plano, como Copilot, tienen el consumo distribuido durante 24 horas. Las operaciones posteriores que se realicen dentro de ese período de 24 horas se acumularán y contribuirán al consumo acumulado total de ese período. En el escenario suavizado de este ejemplo, las operaciones en segundo plano como Copilot contribuirían al futuro consumo de CU, pero no desencadenan la limitación ni cruzan ningún límite.
Supervisión del consumo de Copilot en Fabric
Los administradores de Fabric pueden supervisar la cantidad de consumo de Copilot que se produce en la capacidad de Fabric mediante la aplicación de Métricas de capacidad de Microsoft Fabric. En la aplicación, un administrador de Fabric puede ver un desglose por actividad y usuario, lo que les ayuda a identificar las personas y áreas en las que es posible que necesiten centrarse durante períodos de alto consumo.
Sugerencia
En lugar de considerar cálculos abstractos como tokens en CU, se recomienda centrarse en el porcentaje de la capacidad de Fabric que ha utilizado. Esta métrica es la más sencilla de comprender y actuar, ya que una vez que alcanza el 100 % de uso, puede experimentar la limitación.
Puede encontrar esta información en la página de punto de tiempo de la aplicación.
Nota:
Al pausar una capacidad, el uso suavizado se compacta en el punto de tiempo en el que la capacidad se pausa. Esta compactación del consumo suavizado da como resultado un pico de consumo observado, que no refleja el uso real. Este pico suele generar notificaciones y advertencias que ha agotado la capacidad de Fabric disponible, pero estos son falsos positivos.
Aliviar el uso elevado y la limitación
Copilot consume CPU de Fabric e incluso con suavizado, es posible que encuentre situaciones de uso elevado, lo que conduce a un consumo elevado y a la limitación de las demás cargas de trabajo de Fabric. En las secciones siguientes se describen algunas estrategias que puede usar para aliviar el impacto en la capacidad de Fabric en este escenario.
Entrenamiento de usuarios y listas de acceso permitido
Una manera importante de garantizar la adopción eficaz de cualquier herramienta es equipar a los usuarios con suficiente mentoría y formación, y implementar gradualmente el acceso a medida que las personas completen dicha formación. Un entrenamiento efectivo es una medida preventiva para evitar la alta utilización y la limitación de forma preventiva, educando a los usuarios sobre cómo utilizar Copilot de forma efectiva y sobre lo que no se debe hacer.
Puede controlar mejor quién puede usar Copilot en Fabric mediante la creación de una lista de permitidos de usuarios con acceso a la característica desde la configuración del inquilino de Fabric. Esto significa que habilita Copilot en Fabric solo para los usuarios que pertenecen a grupos de seguridad específicos. Si es necesario, puede crear grupos de seguridad independientes para cada una de las cargas de trabajo de Fabric, donde puede permitir que Copilot consiga un control más preciso sobre quién puede usar las experiencias de Copilot. Para obtener más información sobre cómo crear grupos de seguridad, consulte Crear, editar o eliminar un grupo de seguridad.
Una vez que agregue grupos de seguridad específicos a la configuración de la instancia de Copilot, puede preparar la formación de incorporación para los usuarios. Un curso de formación de Copilot debe abarcar temas básicos, como los siguientes.
Sugerencia
Considere la posibilidad de crear una visión general de formación sobre conceptos básicos de los LLMs y la inteligencia artificial generativa, pero luego cree una formación específica para las tareas del usuario. No todas las personas necesitan obtener información sobre todas las cargas de trabajo de Fabric si no son necesariamente relevantes para ellas.
LLMs: Explique los conceptos básicos de lo que es un LLM y cómo funciona. No debe entrar en detalles técnicos, pero debe explicar conceptos como indicaciones, fundamento y tokens. También puede explicar cómo las LLM pueden obtener significado de la entrada y generar respuestas adecuadas para el contexto debido a sus datos de entrenamiento. Enseñar esto a los usuarios les ayuda a comprender cómo funciona la tecnología y lo que puede y no puede hacer.
Para qué se usan Copilot y otras herramientas de inteligencia artificial generativa: Debe explicar que Copilot no es un agente autónomo y no está pensado para reemplazar a los humanos en sus tareas, sino para aumentar a los individuos para que puedan realizar sus tareas actuales mejor y más rápido. También debe resaltar los casos en los que Copilot no es adecuado e explicar qué otras herramientas e información pueden usar los individuos para abordar sus problemas en esos escenarios, usando ejemplos específicos.
Evaluación crítica de resultados de Copilot: Es importante guiar a los usuarios sobre cómo pueden validar los resultados de Copilot. Esta validación depende de la experiencia de Copilot que estén usando, pero en general, debería destacar los siguientes puntos:
- Compruebe cada salida antes de usarla.
- Evalúe y pregúntese si la salida es correcta o no.
- Agregue comentarios al código generado para comprender cómo funciona. Como alternativa, pida a Copilot explicaciones para ese código, si es necesario, y haga referencia cruzada a esa explicación con orígenes de confianza.
- Si la salida genera un resultado inesperado, solucione problemas con mensajes diferentes o mediante la validación manual.
Riesgos y limitaciones de los LLM y la IA generativa: Debe explicar los riesgos clave y las limitaciones de Copilot, los LLM y la IA generativa, como las mencionadas en este artículo:
- Son no deterministas.
- No proporcionan ninguna indicación ni garantías de precisión, confiabilidad o veracidad.
- Pueden alucinar y producir salidas inexactas o de baja calidad.
- No pueden generar información que abarque fuera del ámbito de sus datos de entrenamiento.
Dónde encontrar Copilot en Fabric: Proporcione una visión general de alto nivel de las distintas cargas de trabajo, elementos y experiencias de Copilot que alguien podría usar.
Escale la capacidad
Cuando experimenta limitaciones en Fabric debido al consumo de Copilot u otras operaciones, puede escalar temporalmente (o cambiar el tamaño) de la capacidad a una SKU posterior. Se trata de una medida reactiva que eleva temporalmente el costo para aliviar los problemas a corto plazo debido a la limitación o al transporte. Esto resulta especialmente útil cuando se experimenta una limitación principalmente debido a las operaciones en segundo plano, ya que el consumo (y, por tanto, el impacto) se puede distribuir en un período de 24 horas.
Estrategias de capacidad dividida
En escenarios en los que se espera un uso elevado de Copilot en Fabric (por ejemplo, en organizaciones grandes), puede considerar la posibilidad de aislar el consumo de Copilot de las otras cargas de trabajo de Fabric. En este escenario de capacidad dividida, se evita que el consumo de Copilot afecte negativamente a otras cargas de trabajo de Fabric habilitando Copilot solo en una SKU F64 o posterior independiente, que solo se utiliza para experiencias de Copilot dedicadas. Esta estrategia de capacidad dividida produce un mayor costo, pero puede facilitar la administración y control del uso de Copilot.
Sugerencia
Puede usar algunas experiencias de Copilot con elementos de otras capacidades que no admiten ni habilitan Copilot. Por ejemplo, en Power BI Desktop, puede vincularse a un área de trabajo con capacidad F64 SKU Fabric, pero luego conectarse a un modelo semántico en un área de trabajo F2 o PPU. A continuación, puede usar experiencias de Copilot en Power BI Desktop y el consumo de Copilot solo afectará a la SKU F64.
En el diagrama siguiente se muestra un ejemplo de una estrategia de capacidad compartida para aislar el consumo de Copilot con experiencias similares a las de Copilot en Power BI Desktop.

También puede usar una solución de capacidad dividida asignando el consumo de Copilot a una capacidad independiente. Asignar el consumo de Copilot a una capacidad independiente garantiza que el uso elevado de Copilot no afecte a las demás cargas de trabajo de Fabric y a los procesos críticos para la empresa que dependen de ellos. Por supuesto, el uso de cualquier estrategia de capacidad dividida requiere que ya tenga dos o más SKU F64 o posteriores. Por lo tanto, esta estrategia podría no ser manejable para organizaciones o organizaciones más pequeñas con un presupuesto limitado para gastar en sus plataformas de datos.
Independientemente de cómo decida administrar Copilot, lo más importante es que controle el consumo de Copilot en su capacidad de Fabric.