Integración de OneLake con Azure HDInsight
Azure HDInsight es un servicio administrado basado en la nube para el análisis de macrodatos que ayuda a las organizaciones a procesar grandes cantidades de datos. En este tutorial se muestra cómo conectarse a OneLake con un cuaderno de Jupyter desde un clúster de Azure HDInsight.
Uso de Azure HDInsight
Para conectarse a OneLake con un cuaderno de Jupyter desde un clúster de HDInsight:
Creación de un clúster de Apache Spark en HDInsight (HDI). Siga estas instrucciones: Configuración de clústeres en HDInsight.
Al proporcionar información del clúster, recuerde el nombre de usuario y la contraseña de inicio de sesión del clúster, ya que los necesitará más adelante para acceder al clúster.
Cree una identidad administrada asignada al usuario (UAMI): Crear para Azure HDInsight - UAMI y elíjala como identidad en la pantalla Almacenamiento.
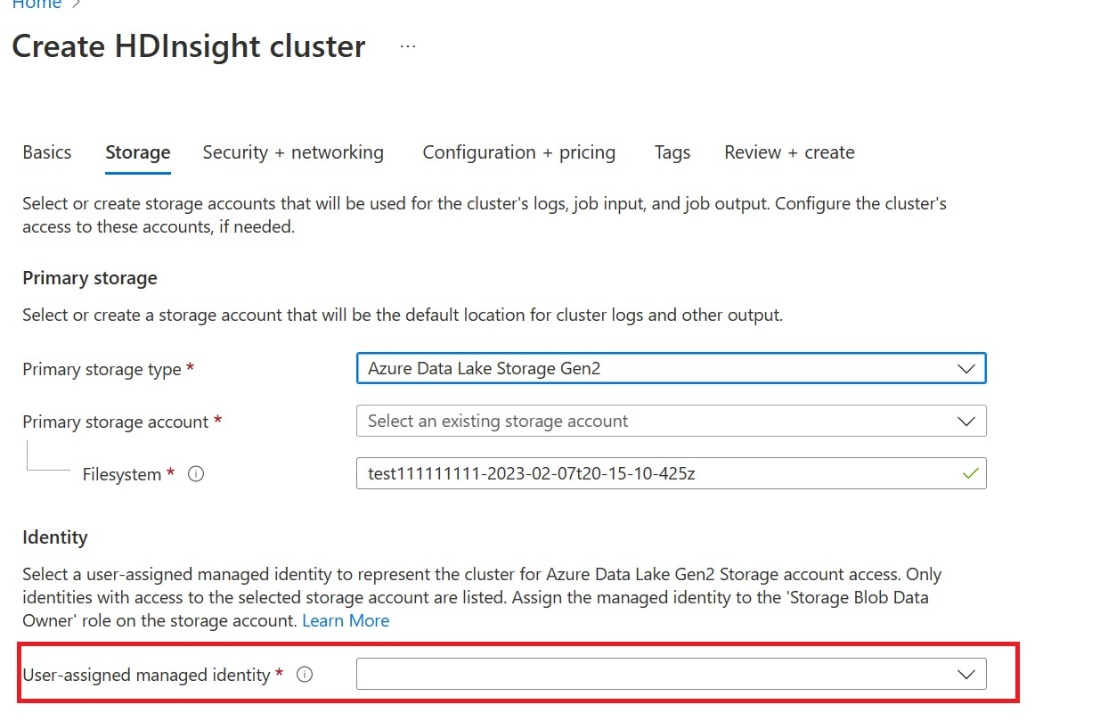
Conceda a esta UAMI acceso al área de trabajo de Fabric que contiene los elementos. Para obtener ayuda para decidir qué rol es mejor, consulte roles del área de trabajo.
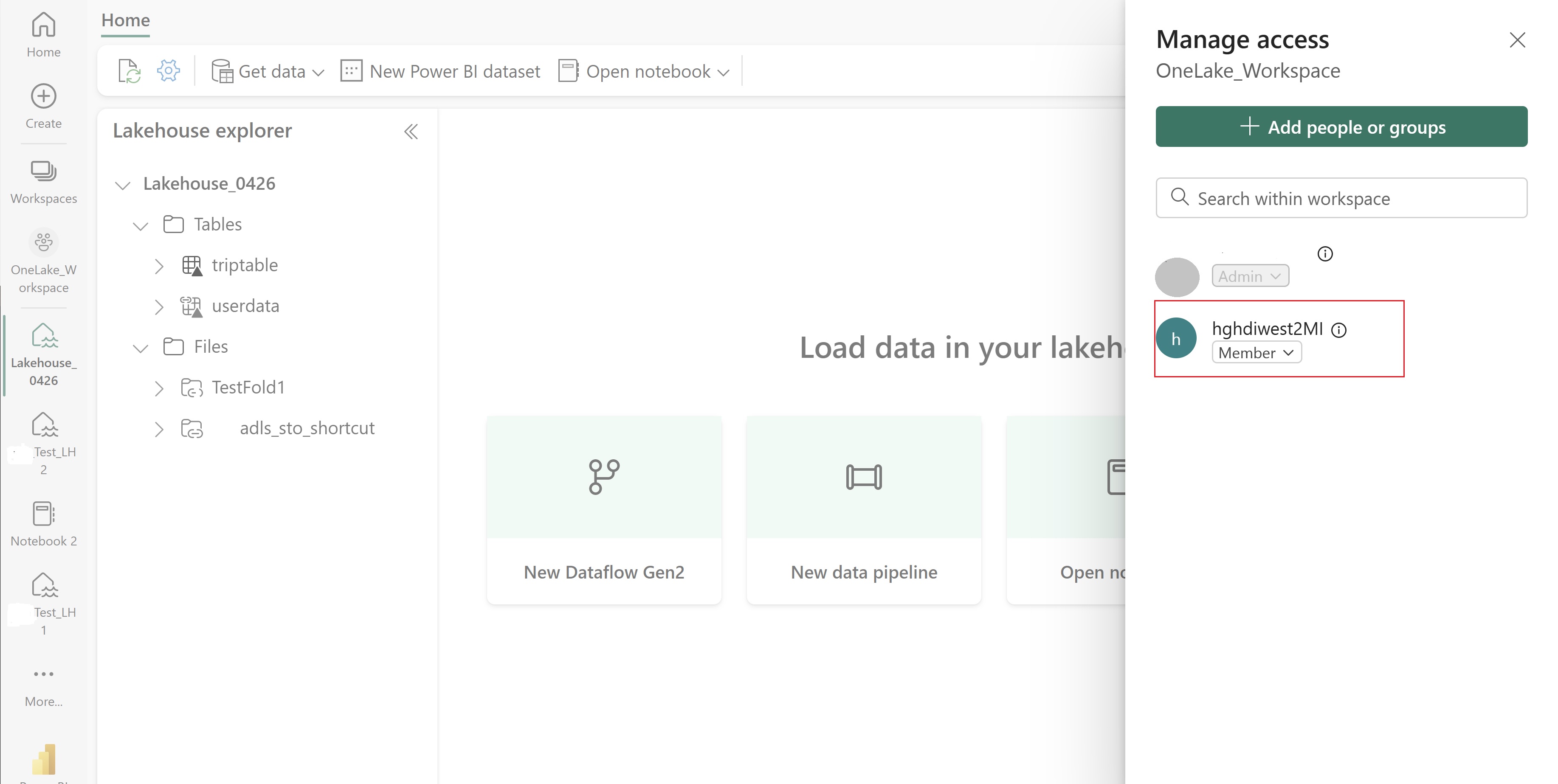
Vaya a Lakehouse y busque el nombre del área de trabajo y Lakehouse. Puede encontrarlos en la dirección URL de Lakehouse o en el panel Propiedades de un archivo.
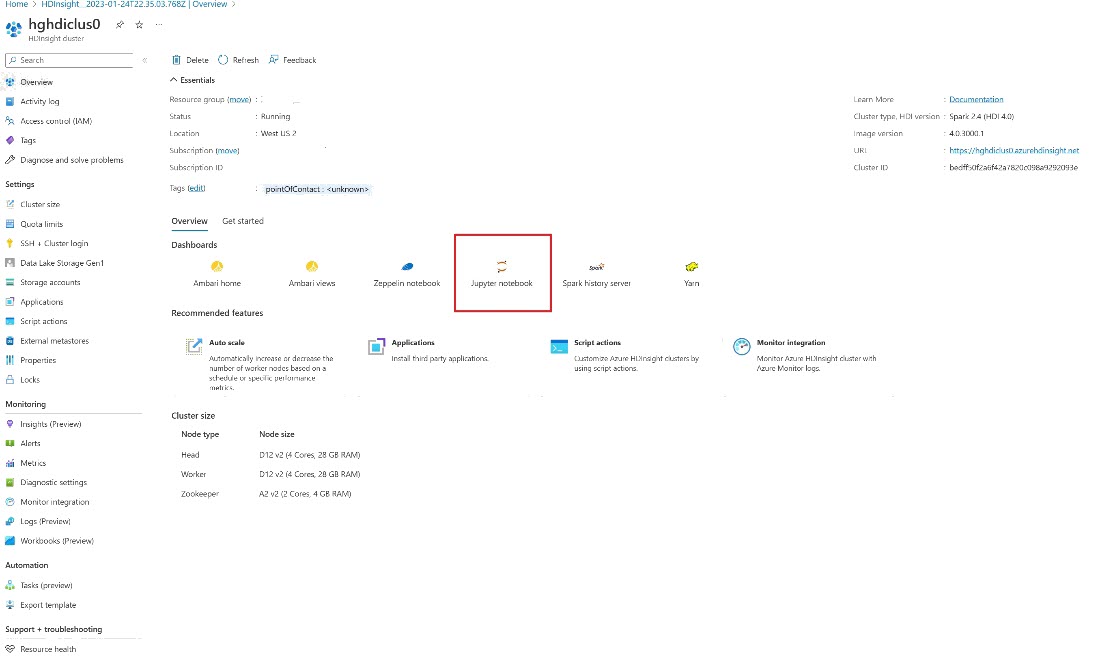
En Azure Portal, busque el clúster y seleccione el cuaderno.
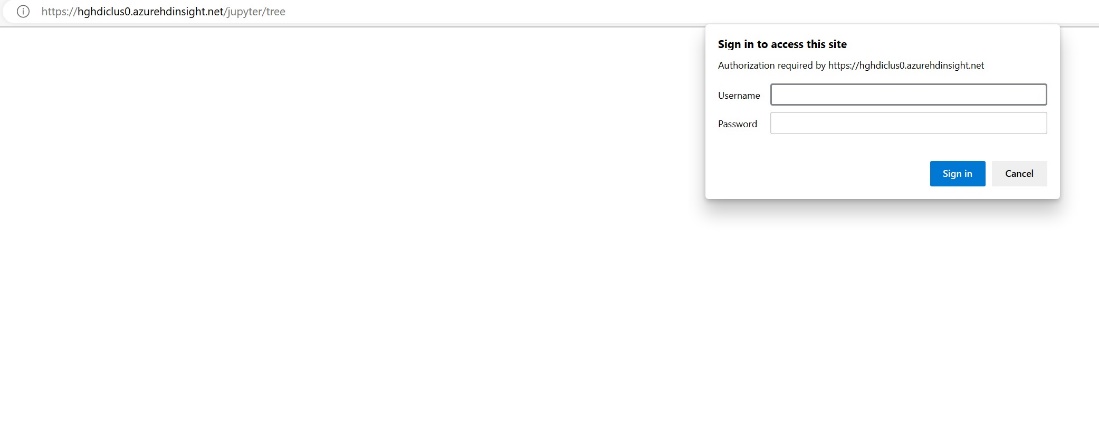
Escriba la información de credenciales que proporcionó al crear el clúster.
Cree un nuevo cuaderno de Apache Spark.
Copie el área de trabajo y los nombres de Lakehouse en el cuaderno y compile la dirección URL de OneLake para Lakehouse. Ahora puede leer cualquier archivo de esta ruta de acceso de archivo.
fp = 'abfss://' + 'Workspace Name' + '@onelake.dfs.fabric.microsoft.com/' + 'Lakehouse Name' + '/Files/' df = spark.read.format("csv").option("header", "true").load(fp + "test1.csv") df.show()Intente escribir algunos datos en Lakehouse.
writecsvdf = df.write.format("csv").save(fp + "out.csv")Compruebe que sus datos se han escrito correctamente verificando su Lakehouse o leyendo su archivo recién cargado.




Ahora puede leer y escribir datos en OneLake mediante el cuaderno de Jupyter en un clúster de HDI Spark.
Contenido relacionado
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de