Azure HDInsight es un servicio de análisis, de código abierto, espectro completo y totalmente administrado en la nube para empresas. Con HDInsight, puede usar plataformas de código abierto, como Apache Spark, Apache Hive, LLAP, Apache Kafka, Hadoop, etc., en el entorno de Azure.
¿Qué son HDInsight y la pila de tecnología de Hadoop?
Azure HDInsight es una plataforma de clúster administrado que facilita la ejecución de marcos de macrodatos como Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Hadoop y otros en su entorno de Azure. Está diseñado para controlar grandes volúmenes de datos con alta velocidad y eficiencia.
¿Por qué debo usar Azure HDInsight?
Capacidad
Descripción
Nativo en la nube
Azure HDInsight permite crear clústeres optimizados para Spark, Interactive Query (LLAP), Kafka, HBase y Hadoop en Azure. HDInsight también proporciona un Acuerdo de Nivel de Servicio de un extremo a otro en las cargas de trabajo de producción.
Rentable y escalable
HDInsight le permite escalar o reducir verticalmente las cargas de trabajo. Puede reducir el costo mediante la creación de clústeres a petición y pagar solo por lo que se utiliza. También puede compilar canalizaciones de datos para poner en marcha los trabajos. El procesamiento y el almacenamiento desacoplados ofrecen un mejor rendimiento y flexibilidad.
Seguro y conforme
HDInsight le permite proteger los recursos de datos empresariales con Azure Virtual Network, cifrado e integración con Microsoft Entra ID. HDInsight también cumple con los estándares de cumplimiento normativo más conocidos del sector y de la administración.
Supervisión
Azure HDInsight se integra con los registros de Azure Monitor para proporcionar una única interfaz con la que puede supervisar todos los clústeres.
Disponibilidad global
HDInsight está disponible en más regiones que ninguna otra oferta de análisis de macrodatos. También está disponible en Azure Government, China y Alemania, lo que le permite satisfacer las necesidades de su empresa en áreas soberanas clave.
Productividad
Azure HDInsight le permite usar herramientas de productividad muy completas de Hadoop y Spark con los entornos de desarrollo que prefiera. Estos entornos de desarrollo incluyen Visual Studio, VSCode, Eclipse e IntelliJ para la compatibilidad con Scala, Python, Java y .NET.
Extensibilidad
Puede ampliar los clústeres de HDInsight con componentes instalados (Hue, Presto, etc.) mediante acciones de script, la incorporación de nodos perimetrales o la integración con otras aplicaciones certificadas de macrodatos. HDInsight le permite una integración sin problemas con las soluciones de macrodatos más conocidas con una implementación con un solo clic.
¿Qué son grandes volúmenes de datos?
Los macrodatos se recopilan en volúmenes de escala a una mayor velocidad y con una variedad de formatos nunca vista. Pueden ser históricos (es decir, almacenados) o en tiempo real (es decir, transferidos directamente desde el origen). Consulte Escenarios de uso de HDInsight para más información sobre los casos de uso más habituales para macrodatos.
Tipos de clúster de HDInsight
HDInsight incluye tipos de clúster concretos y funcionalidades de personalización del clúster, tales como la de agregar componentes, utilidades y lenguajes. HDInsight ofrece los siguientes tipos de clúster:
una plataforma que utiliza HDFS, administración de recursos YARN y un modelo de programación de MapReduce simple para procesar y analizar datos por lotes en paralelo.
plataforma de procesamiento paralelo de código abierto que admite el procesamiento en memoria para mejorar el rendimiento de las aplicaciones de análisis de macrodatos. Consulte ¿qué es Apache Spark en HDInsight?
base de datos NoSQL en Hadoop que proporciona acceso aleatorio y coherencia fuerte para grandes cantidades de datos no estructurados y semiestructurados; potencialmente miles de millones de filas multiplicadas por millones de columnas. Consulte ¿qué es HBase en HDInsight?
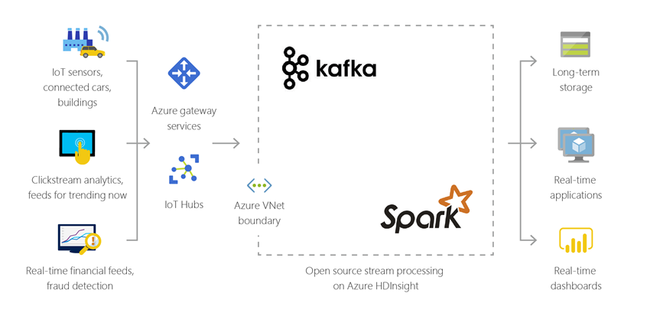
Una plataforma de código abierto que se usa para crear canalizaciones y aplicaciones de datos de streaming. Kafka también proporciona funcionalidad de cola de mensajes que le permite publicar flujos de datos y suscribirse a ellos. Consulte Introducción a Apache Kafka en HDInsight.
Azure HDInsight se puede usar para varios escenarios de procesamiento de macrodatos. Pueden ser datos históricos (datos ya recopilados y almacenados) o datos en tiempo real (datos que se transmiten directamente desde el origen). Los escenarios de procesamiento de tales datos se pueden resumir en las siguientes categorías:
Procesamiento por lotes (ETL)
El de extracción, transformación y carga (ETL) es un proceso en el que se extraen datos estructurados o no estructurados de orígenes de datos heterogéneos. Estos datos se transforman a un formato estructurado y se cargan en un almacén de datos. Los datos transformados se pueden usar para ciencia de datos o almacenamiento de datos.
Almacenamiento de datos
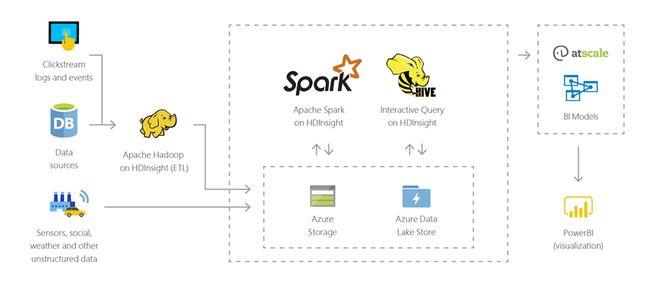
Puede usar HDInsight para realizar consultas interactivas a escalas de petabytes sobre datos estructurados o no estructurados en cualquier formato. También puede generar modelos conectándolos a herramientas de BI.
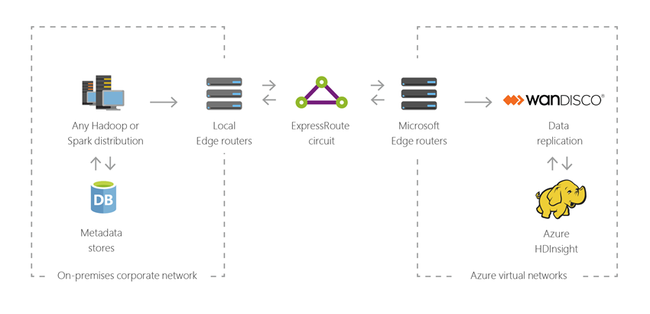
Puede usar HDInsight para ampliar la infraestructura local de macrodatos existente en Azure para aplicar las funcionalidades avanzadas de análisis en la nube.
Componentes de código abierto en HDInsight
Azure HDInsight permite crear clústeres con marcos de código abierto, como Spark, Hive, LLAP, Kafka, Hadoop y HBase. De forma predeterminada, estos clústeres incluyen varios componentes de código abierto, como Apache Ambari, Avro, Apache Hive3, HCatalog, Apache Hadoop MapReduce, Apache Hadoop YARN, Apache Phoenix, Apache Pig, Apache Sqoop, Apache Tez, Apache Oozie y Apache ZooKeeper.
Lenguajes de programación en HDInsight
Los clústeres de HDInsight, como Spark, HBase, Kafka, Hadoop, etc, admiten muchos lenguajes de programación. Aunque algunos no están instalados de manera predeterminada. En el caso de las bibliotecas, los módulos o los paquetes que no se instalan de manera predeterminada, instale el componente con una acción de script.
Lenguaje de programación
Información
Compatibilidad con lenguajes de programación predeterminados
De forma predeterminada, los clústeres de HDInsight admiten lo siguiente:
Java
Python
.NET
Go
Lenguajes de la máquina virtual de Java (JVM)
Muchos lenguajes distintos de Java se pueden ejecutar en una máquina virtual de Java (JVM). Sin embargo, si ejecuta algunos de estos lenguajes, puede que tenga que instalar más componentes en el clúster. Los siguientes lenguajes basados en JVM son compatibles con clústeres de HDInsight:
Clojure
Jython (Python para Java)
Scala
Lenguajes específicos de Hadoop
Los clústeres de HDInsight son compatibles con los siguientes lenguajes específicos de la pila de tecnología de Hadoop:
Pig Latin para trabajos de Pig
HiveQL para trabajos de Hive y SparkSQL
Herramientas de desarrollo para HDInsight
Puede usar herramientas de desarrollo de HDInsight, como IntelliJ, Eclipse, Visual Studio Code y Visual Studio, para crear y enviar trabajos y consultas de datos de HDInsight con una integración perfecta con Azure.
Azure Toolkit for IntelliJ 10
Azure Toolkit for Eclipse 6
Herramientas de Azure HDInsight para VS Code 13
Herramientas de Azure Data Lake para Visual Studio 9
Inteligencia empresarial en HDInsight
Las herramientas de Business Intelligence (BI) habituales recuperan, analizan y generan informes de datos que se integran en HDInsight con el complemento Power Query o Microsoft Hive ODBC Driver:
Spark, Hadoop y LLAP no almacenan datos del cliente, por lo que estos servicios satisfacen automáticamente los requisitos de residencia de los datos en la región especificados en el Centro de confianza.
Kafka y HBase almacenan datos de los clientes. Kafka y HBase almacenan estos datos automáticamente en una sola región, por lo que este servicio satisface los requisitos de residencia de datos en la región especificados en el Centro de confianza.
Las herramientas de inteligencia empresarial (BI) habituales recuperan, analizan y generan informes de datos que se integran en HDInsight con el complemento Power Query o Microsoft Hive ODBC Driver.
Evaluar si Azure HDInsight puede ayudar a su organización a procesar los macrodatos. Describir cómo Azure HDInsight usa marcos de código abierto populares que admiten muchos escenarios, como extracción, transformación, almacenamiento de datos y otros.
Demostrar la comprensión de las tareas comunes de ingeniería de datos para implementar y administrar cargas de trabajo de ingeniería de datos en Microsoft Azure mediante una serie de servicios de Azure.