Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
OneLake es el único lago de datos unificado para Fabric. Cada carga de trabajo de Fabric lee y escribe datos a través de OneLake, por lo que solo es necesario cargar los datos una vez para utilizarlos en cualquier lugar. Puede incluir datos en OneLake de varias maneras:
- Cargue archivos directamente en un lakehouse o almacén de datos.
- Ingerir datos mediante canalizaciones, flujos de datos o experiencias de streaming.
- Conéctese a datos externos mediante accesos directos o creación de reflejo.
En esta guía de inicio rápido, incorpora datos en OneLake de dos maneras: cargas un archivo CSV en un lakehouse y creas un acceso directo en OneLake desde un segundo lakehouse que apunta a esos mismos datos sin copiarlos. Cuando haya terminado, dispondrá de una tabla Delta que se puede consultar y de un acceso directo, ambos disponibles para todos los motores de Fabric a través de OneLake.
Prerequisites
- Una licencia de Fabric. O bien, regístrese para obtener una prueba gratuita Fabric.
- Un área de trabajo de Fabric.
Creación de un almacén de lago de datos
Cuando crea un elemento de Fabric, como un lakehouse, un almacén o un eventhouse, ese elemento aprovisiona almacenamiento en OneLake en su nombre. En este inicio rápido, creará una instancia de Lakehouse, que proporciona un área de archivos (Archivos) para datos no estructurados o semiestructurados y un área de tabla Delta (Tablas) para datos estructurados y consultables. Todo lo que coloque en cualquier área se almacena en OneLake y se puede acceder inmediatamente a otras cargas de trabajo de Fabric.
Inicie sesión en el portal Fabric y seleccione el área de trabajo.
Seleccione Nuevo elemento.
En el panel Nuevo elemento , busque y seleccione Lakehouse.
Escriba un nombre, como
DataLakehouse, y seleccione Crear.El lakehouse se abre en la vista Explorador, que muestra las secciones vacías Tablas y Archivos. Ambas secciones ya están respaldadas por OneLake y están listas para el contenido.
Cargar datos de ejemplo
En este inicio rápido, usará Dim_Products.csv desde un modelo semántico de ejemplo Fabric disponible públicamente. Es una pequeña tabla de información de productos de un distribuidor de café de ejemplo.
- Abra un explorador y vaya a https://fabrictutorialdata.blob.core.windows.net/sampledata/Coffee/Dim_Products.csv.
- Cuando se le solicite, guarde el archivo como
Dim_Products.csven una carpeta del equipo.
En esta sección, carga Dim_Products.csv en Files para tener datos de origen sin procesar en OneLake. El área Files de un lago es una zona de almacenamiento de uso general en OneLake. Piense en ella como la zona de aterrizaje para los datos sin procesar en cualquier formato que llegue. Puede incorporar CSV, JSON, Parquet, imágenes, registros o cualquier otra cosa sin tener que definir antes un esquema.
En el explorador de Lakehouse, mantenga el puntero sobre Archivos, seleccione el menú más opciones (...) y, a continuación, seleccione Cargar>archivos.
En el panel Cargar archivos , seleccione el icono de carpeta y vaya a
Dim_Products.csven el equipo.Seleccione Cargar y cierre el panel de carga.
Seleccione la carpeta Archivos para ver su contenido y confirmar que
Dim_Products.csvaparece.Seleccione
Dim_Products.csvpara ver sus datos.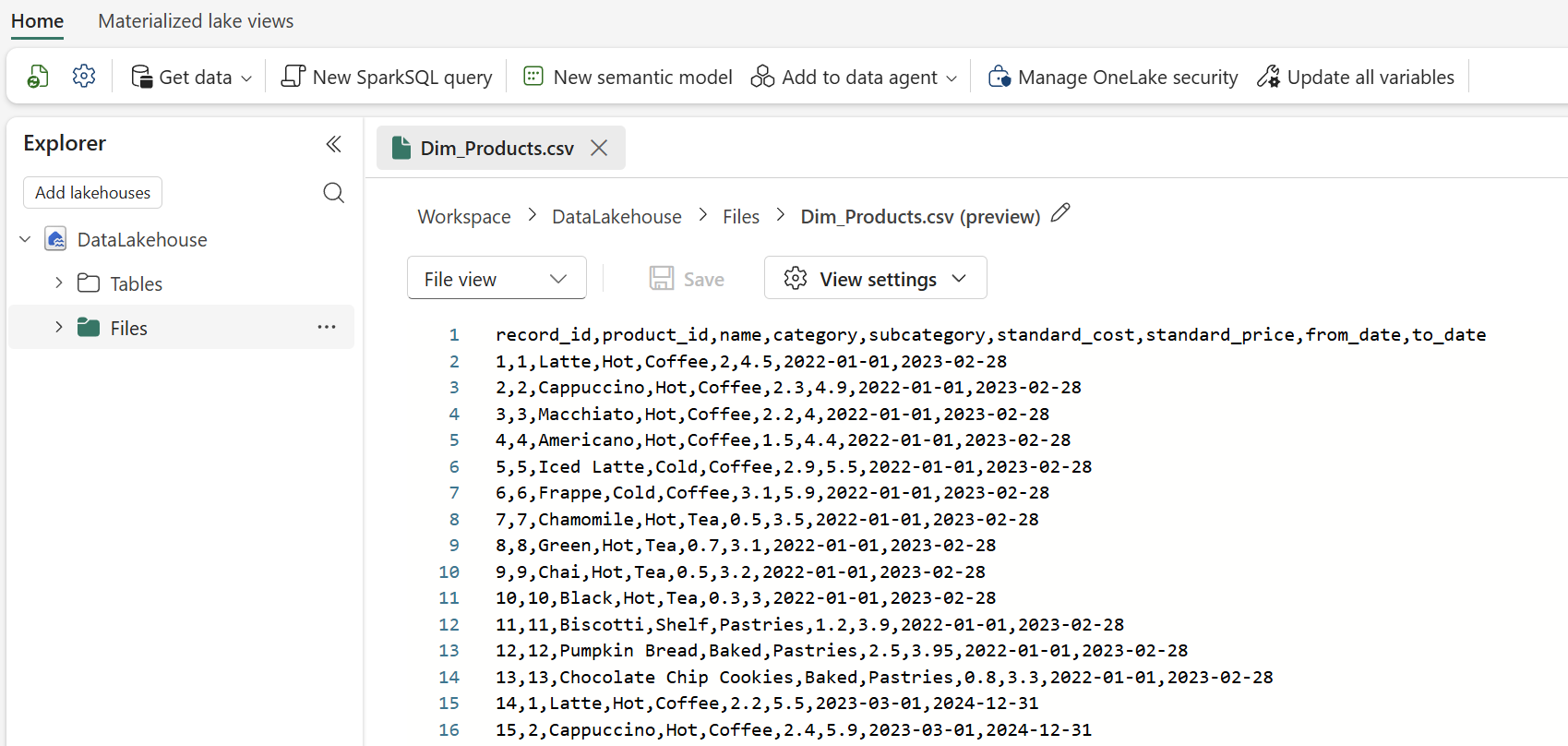
El archivo ahora está en OneLake, pero, como es un CSV sin procesar, todavía no es algo que SQL o Spark puedan consultar como una tabla.
Cargar el archivo en una tabla Delta
Fabric adopta Delta Lake como formato de tabla estándar en OneLake. Al cargar un archivo en el área Tables, Fabric lee el archivo de origen, deduce un esquema y escribe los datos como una tabla Delta. Desde ese momento, cada motor de Fabric puede consultar la misma tabla sin copiar ni convertir los datos de nuevo.
En el explorador de Lakehouse, abra la carpeta Archivos .
Mantenga el puntero sobre el
Dim_Products.csvarchivo y seleccione el menú más opciones (...) y, a continuación, seleccione Cargar en tablas>Nueva tabla.En el cuadro de diálogo Cargar en tabla , escriba
dim_productspara el nombre de la tabla, mantenga los valores predeterminados y seleccione Cargar.Una vez finalizada la carga, expanda Tablas y seleccione
dim_productspara obtener una vista previa de las filas. El CSV sin procesar en Archivos permanece sin cambios, ydim_productses una nueva tabla Delta creada a partir de este.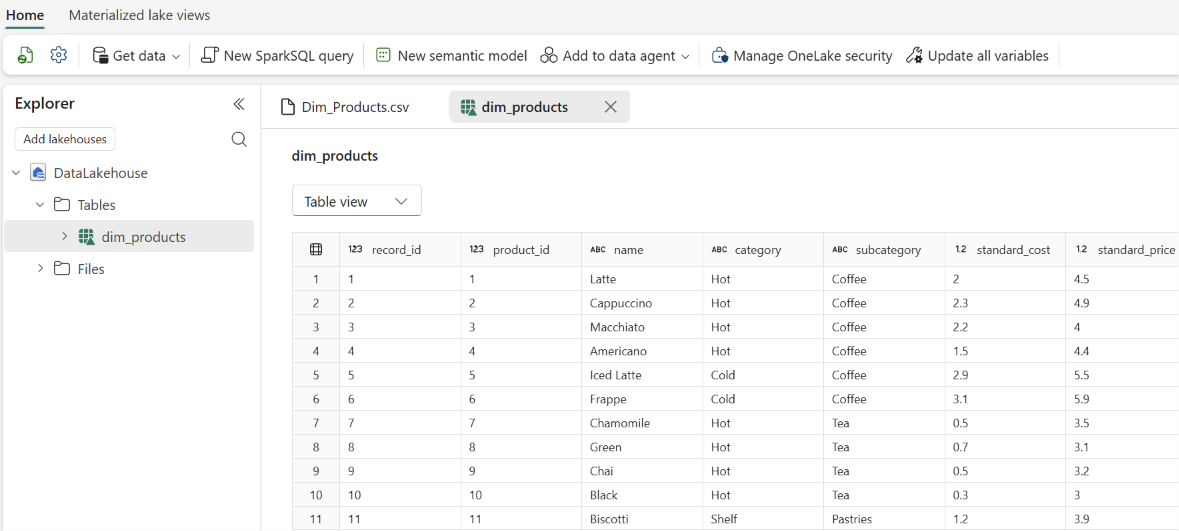
Mantenga el puntero sobre
dim_productsy seleccione el menú más opciones (...) y, a continuación, seleccione Propiedades.La pantalla Propiedades muestra los diversos detalles de la tabla, incluida la dirección URL y la ruta de Azure Blob File System (ABFS) que puede utilizar para hacer referencia a esta tabla en otros motores.
Reutilice los datos con un acceso directo desde un segundo lakehouse
La carga y la ingestión son una forma de introducir datos en OneLake. El otro patrón clave es hacer referencia a datos que ya existen en otro lugar, sin duplicarlos. Eso es un acceso directo: un vínculo en OneLake que hace referencia a datos almacenados en otro lakehouse, en otra área de trabajo de Fabric o en orígenes admitidos fuera de Fabric, como Azure Data Lake Storage o Amazon S3. Los datos no se copian; permanece en la ubicación de origen, pero puede leerlo a través de OneLake como si fuera local. Las actualizaciones del origen están visibles inmediatamente a través del acceso directo, por lo que no es necesario mantener copias de los datos.
En esta sección, crea un segundo lakehouse y agrega un acceso directo desde este a la tabla dim_products de su primer lakehouse. Esto refleja cómo suelen trabajar los equipos, en el que un equipo es responsable de los datos seleccionados y otros equipos o proyectos los consumen mediante accesos directos en sus propios espacios de trabajo.
- En el área de trabajo, seleccione Nuevo elemento.
- En el panel Nuevo elemento , busque y seleccione Lakehouse.
- Escriba un nombre, como
ShortcutLakehouse, y seleccione Crear. - En el nuevo Explorador de Lakehouse, mantenga el puntero sobre Tablas, seleccione el menú más opciones (...) y, a continuación, seleccione Nuevo acceso directo.
- En la página Nuevo acceso directo, en Orígenesinternal, seleccione Microsoft OneLake.
- En el explorador de orígenes de datos, seleccione el primer lakehouse que creó para esta guía de inicio rápido y, a continuación, seleccione Siguiente.
- Expanda Tablas, seleccione la
dim_productstabla y, a continuación, seleccione Siguiente. - Revise la selección y seleccione Crear.
- Expanda Tablas en
ShortcutLakehousey confirme quedim_productsaparece con un icono de acceso directo (una imagen de vínculo pequeña sobre el icono de tabla). Selecciónelo para obtener una vista previa de las filas. La tabla es la misma que en el lago original, pero no se copió ningún dato. - Mantenga el puntero sobre la
dim_productstabla, seleccione más opciones (...) y, a continuación, seleccione Administrar acceso directo. En el panel Administrar acceso directo , puede ver los detalles del acceso directo, incluido el destino de acceso directo donde se almacenan los datos originales.
Limpieza de recursos
Si no tiene previsto continuar con los otros inicios rápidos de OneLake, elimine los almacenes de lago para evitar que se apliquen cargos de almacenamiento de OneLake a su capacidad de Fabric.
- En el espacio de trabajo, sitúe el cursor sobre el Lakehouse que desea eliminar.
- Seleccione el menú más opciones (...) situado junto a lakehouse, seleccione Eliminar y confirme la eliminación.
Al eliminar los lakehouses también se elimina el contenido que contienen: el archivo cargado, la tabla dim_products Delta y el acceso directo.