Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo, aprenderá a obtener datos de Azure Storage (contenedor de ADLS Gen2, contenedor de blobs o blobs individuales). Puede ingerir datos en su tabla continuamente o como una ingesta única vez. Una vez ingeridos, los datos están disponibles para la consulta.
Ingesta continua (versión preliminar): la ingesta continua implica la configuración de una canalización de ingesta que permite a un centro de eventos escuchar eventos de Azure Storage. La canalización notifica al centro de eventos que extraiga información cuando se produzcan eventos suscritos. Los eventos son BlobCreated y BlobRenamed.
Importante
Esta característica se encuentra en versión preliminar.
Nota
Un flujo de ingesta continua puede afectar a la facturación. Para obtener más información, consulte Eventhouse and KQL Database consumption (Consumo de la base de datos de KQL y Eventhouse).
Ingesta única: use este método para recuperar datos de Azure Storage como una operación única.
Prerrequisitos
- Un área de trabajo con una capacidad habilitada para Microsoft Fabric.
- Una base de datos KQL con permisos de edición.
- Una cuenta de almacenamiento.
Para la ingesta continua, también necesita lo siguiente:
Una identidad del área de trabajo. Mi área de trabajo no está admitida. Si es necesario, cree una nueva área de trabajo.
Habilite el espacio de nombres jerárquico en la cuenta de almacenamiento.

Permisos de rol lector de datos de Storage Blob asignados a la identidad del área de trabajo.
Contenedor que contiene los archivos de datos.
Un archivo de datos cargado en el contenedor. La estructura del archivo de datos se usa para definir el esquema de tabla. Para obtener más información, consulte Formatos de datos compatibles con Real-Time Intelligence.
Nota
Debe cargar un archivo de datos:
- Antes de la configuración para definir el esquema de la tabla durante la instalación.
- Después de la configuración para desencadenar la ingesta continua, para obtener una vista previa de los datos y para comprobar la conexión.
Agrega la asignación del rol de identidad del área de trabajo a la cuenta de almacenamiento
En la configuración del área de trabajo de Fabric, copie el identificador de identidad del área de trabajo.

En Azure Portal, vaya a la cuenta de Azure Storage y seleccione Control de acceso (IAM)>Agregar asignación> deroles.
Seleccione Lector de datos de Storage Blob.
En el cuadro de diálogo Agregar asignación de roles , seleccione + Seleccionar miembros.
Pega el identificador de identidad del área de trabajo, selecciona la aplicación y, después, Selecciona>Revisar y asignar.
Creación de un contenedor con un archivo de datos
En la cuenta de almacenamiento, seleccione Contenedores.
Seleccione + Contenedor, escriba un nombre para el contenedor y seleccione Guardar.
Entre en el contenedor, seleccione Subir y suba el archivo de datos preparado anteriormente.
Para obtener más información, consulte formatos admitidos y compresión admitidas.
En el menú contextual, [...], seleccione Propiedades del contenedor y copie la dirección URL que se va a escribir durante la configuración.

Fuente
Establezca el origen para obtener datos.
En el área de trabajo, abra EventHouse y seleccione la base de datos.
En la cinta de opciones de la base de datos KQL, seleccione Obtener datos.
Seleccione el origen de datos de la lista disponible. En este ejemplo, va a ingerir datos de Azure Storage.


Configuración
Seleccione una tabla de destino. Si desea ingerir datos en una nueva tabla, seleccione + Nueva tabla y escriba un nombre de tabla.
Nota
Los nombres de tabla pueden tener hasta 1,024 caracteres, entre los que se incluyen espacios, alfanuméricos, guiones y caracteres de subrayado. No se admiten caracteres especiales.
En la configuración de la conexión de Azure Blob Storage, asegúrese de que la ingesta continua se encuentra activada. Está activado de forma predeterminada.
Configure la conexión mediante la creación de una nueva conexión o mediante una conexión existente.
Para crear una nueva conexión:
Seleccione Conectar a una cuenta de almacenamiento.

Use las descripciones siguientes para ayudar a rellenar los campos.
Configuración Descripción del campo Suscripción La suscripción de la cuenta de almacenamiento. Cuenta de Blob Storage Nombre de la cuenta de almacenamiento. Contenedor Contenedor de almacenamiento que contiene el archivo que desea ingerir. En el campo Conexión , abra la lista desplegable y seleccione + Nueva conexión y, después, Guardar>cerrar. La configuración de conexión está precargada.
Nota
La creación de una nueva conexión da como resultado una nueva secuencia de eventos. El nombre se define como <storate_account_name>_eventstream. Asegúrese de no quitar la secuencia de eventos de ingesta continua del área de trabajo.
Para usar una conexión existente:
Seleccione Seleccionar una cuenta de almacenamiento existente.

Use las descripciones siguientes para ayudar a rellenar los campos.
Configuración Descripción del campo RTAStorageAccount Flujo de eventos que se conecta a tu cuenta de almacenamiento desde Fabric. Contenedor Contenedor de almacenamiento que contiene el archivo que desea ingerir. Conexión Esto se rellena previamente con la cadena de conexión. En el campo Conexión , abra la lista desplegable y seleccione la cadena de conexión existente de la lista. A continuación, seleccione Guardar>cerrar.
Opcionalmente, expanda Filtros de archivo y especifique los filtros siguientes:
Configuración Descripción del campo Ruta de acceso a la carpeta Filtra los datos para ingerir archivos con una ruta de acceso de carpeta específica. Extensión de archivo Filtra los datos para ingerir archivos solo con una extensión de archivo específica. En la sección configuración del flujo de eventos, puede seleccionar los eventos que se van a supervisar en configuración avanzada>tipo(s) de evento. De forma predeterminada, se selecciona Blob creado. También puede seleccionar Blob renamed.

Seleccione Siguiente para obtener una vista previa de los datos.




Inspeccionar
La pestaña Inspeccionar se abre con una vista previa de los datos.
Para completar el proceso de ingesta, seleccione Finalizar.

Nota
Para evocar datos continuos de ingesta y vista previa, asegúrese de cargar un nuevo blob de almacenamiento después de la configuración.
Opcionalmente:
Utiliza el menú desplegable del archivo de definición del esquema para cambiar el archivo del que se infiere el esquema.
Use la lista desplegable tipo de archivo para explorar opciones avanzadas en función del tipo de datos.
Utiliza la lista desplegable Table_mapping para definir un nuevo mapeo.
Seleccione </> para abrir el visor de comandos para ver y copiar los comandos automáticos generados a partir de las entradas. También puede abrir los comandos en un Queryset.
Seleccione el icono de lápiz para editar columnas.
Editar columnas
Nota
- En el caso de formatos tabulares (CSV, TSV, PSV), no se puede asignar una columna dos veces. Para asignar a una columna existente, elimine primero la nueva columna.
- No se puede cambiar un tipo de columna existente. Si intenta asignar a una columna con otro formato, puede acabar con columnas vacías.
Los cambios que puede realizar en una tabla dependen de los parámetros siguientes:
- El tipo de tabla es nuevo o existente
- El tipo de asignación es nuevo o existente
| Tipo de tabla | Tipo de mapeo | Ajustes disponibles |
|---|---|---|
| Nueva tabla | Nuevo mapeo | Cambiar nombre de columna, cambiar el tipo de datos, cambiar el origen de datos, transformación de mapeo, agregar columna, eliminar columna |
| Tabla existente | Nuevo mapeo | Agregar columna (en la que puede cambiar el tipo de datos, cambiar el nombre y actualizar) |
| Tabla existente | Asignación existente | ninguno |

Transformaciones de mapeo
Algunas asignaciones de formato de datos (Parquet, JSON y Avro) admiten transformaciones sencillas durante la ingestión de datos. Para aplicar transformaciones de asignación, cree o actualice una columna en la ventana Editar columnas.
Las transformaciones de asignación se pueden realizar en una columna de tipo string o datetime, con un origen con un tipo de datos int o long. Para obtener más información, consulte la lista completa de transformaciones de asignación admitidas.
Opciones avanzadas basadas en el tipo de datos
Tabular (CSV, TSV, PSV):
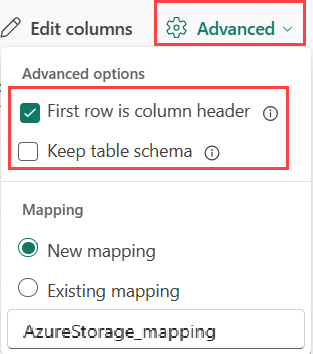
Si vas a ingerir formatos tabulares en una tabla existente , puedes seleccionar Avanzado>Mantener el esquema de la tabla. Los datos tabulares no incluyen necesariamente los nombres de columna que se usan para asignar datos de origen a las columnas existentes. Cuando se activa esta opción, la asignación se realiza por orden y el esquema de tabla es el mismo. Si esta opción está desactivada, se crean nuevas columnas para los datos entrantes, independientemente de la estructura de datos.

Los datos tabulares no incluyen necesariamente los nombres de columna que se usan para asignar datos de origen a las columnas existentes. Para usar la primera fila como nombres de columna, seleccione La primera fila es el encabezado de la columna.

Tabular (CSV, TSV, PSV):
Si va a ingerir formatos tabulares en una tabla existente, puede seleccionar Table_mapping>Usar esquema existente. Los datos tabulares no incluyen necesariamente los nombres de columna que se usan para asignar datos de origen a las columnas existentes. Cuando se activa esta opción, la asignación se realiza por orden y el esquema de tabla es el mismo. Si esta opción está desactivada, se crean nuevas columnas para los datos entrantes, independientemente de la estructura de datos.
Para usar la primera fila como nombres de columna, seleccione Primer encabezado de fila.
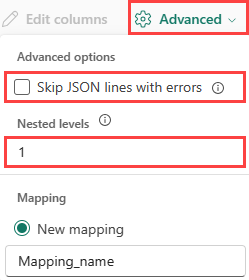
JSON:
Para determinar la división de columnas de los datos JSON, seleccione Niveles anidados, de 1 a 100.
Resumen
En la ventana Resumen , todos los pasos se marcan con marcas de verificación verdes cuando la ingesta de datos finaliza correctamente. Puede seleccionar una tarjeta para explorar los datos, eliminar los datos ingeridos o crear un panel con métricas clave.

Al cerrar la ventana, puede ver la conexión en la pestaña Explorador, en Flujos de datos. Desde aquí, puede filtrar los flujos de datos y eliminar un flujo de datos.


Contenido relacionado
- Para administrar la base de datos, consulte Administración de datos
- Para crear, almacenar y exportar consultas, consulte Datos de consulta en un conjunto de consultas KQL