Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Introducción
Los asociados de Microsoft, incluidos los proveedores de software independientes (ISV), como usted mismo, pueden crear soluciones de inteligencia artificial generativas a través de muchos enfoques diferentes de código pro y bajo código. Para ayudarle en este proceso, Microsoft está creando instrucciones para los ISV para que pueda crear estas soluciones mejor.
A medida que los ISV tienen como objetivo administrar consultas y tareas especializadas, aumenta la complejidad de sus soluciones de inteligencia artificial generativa. Estas soluciones complejas de inteligencia artificial generativa requieren precauciones únicas durante el desarrollo y la supervisión y observación coherentes en toda la producción. Al observar el comportamiento y las salidas del producto, puede identificar rápidamente las áreas de crecimiento, abordar rápidamente los riesgos y los problemas, e impulsar un rendimiento aún mayor para la aplicación.
Creación y puesta en funcionamiento de aplicaciones de copilot
Para comprender cómo afecta la observabilidad a la aplicación desde el principio del ciclo de vida de la solución, es fundamental pensar en el ciclo de vida en tres fases principales: idear el caso de uso, compilar la solución y ponerla en funcionamiento para su uso después de la implementación.
Imagen titulada Ciclo de vida de LLM en el mundo real. Se compone de tres círculos, conectados con flechas y rodeados de una flecha más grande etiquetada como "administrar". El primer círculo se etiqueta como "Ideating/Explore" e incluye "try prompts", "Hypothesis" y "Find LLMs". Se deriva de la flecha de necesidad empresarial y está conectada al segundo círculo con una flecha etiquetada como "proyecto avanzado". El segundo círculo se etiqueta como "Edificio/aumento" y se compone de "generación aumentada de recuperación", "control de excepciones", "ingeniería de avisos o ajuste fino" y "evaluación". El segundo círculo se conecta al último círculo con "preparar la implementación de aplicaciones". El último círculo es el más grande, se etiqueta como "operacionalización" y se compone de "implementar la aplicación/interfaz de usuario de LLM", "administración de cuotas y costos", "filtrado de contenido", "implementación segura/ensayo" y "supervisión". El último círculo está conectado al segundo círculo con "enviar comentarios", mientras que el segundo está conectado al primero con 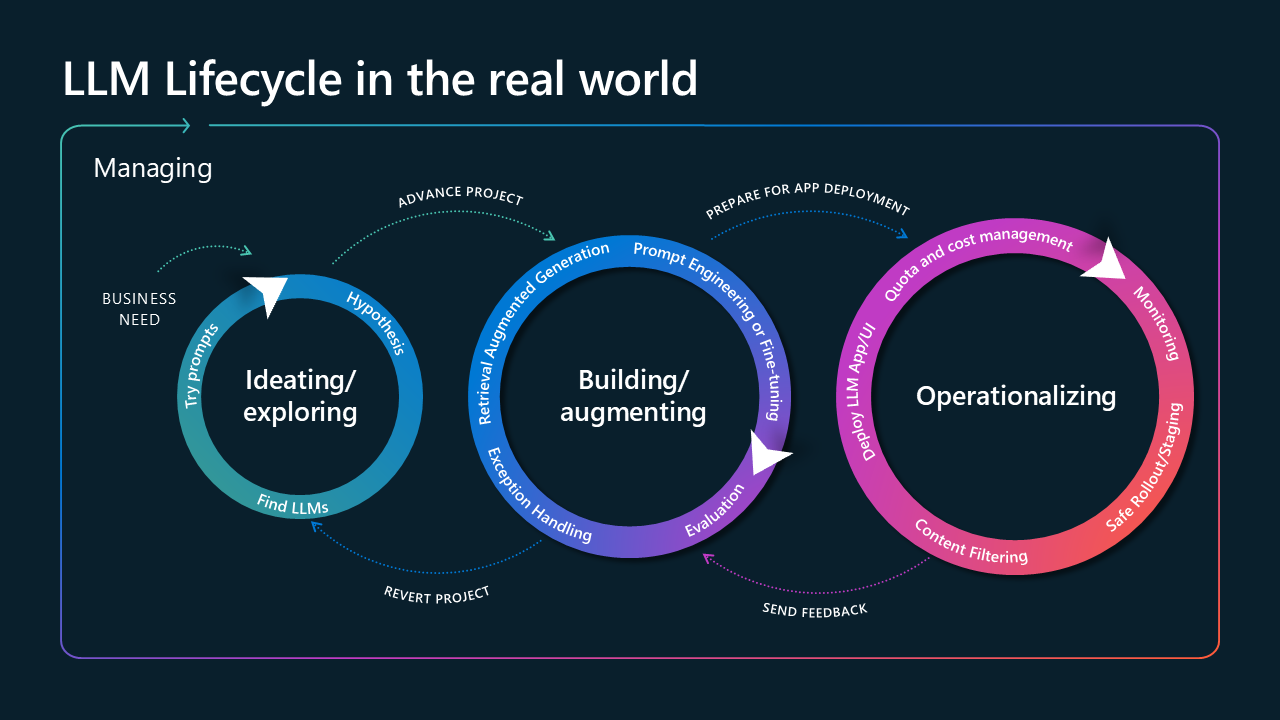
La primera fase se compone de identificar su caso de uso e idear sobre los enfoques tecnológicos para crearlo. Una vez que identifique una ruta de acceso para compilar la aplicación, escriba la segunda fase, que consiste en desarrollar y evaluar la aplicación. Una vez implementada la aplicación en producción, entra en la última fase, donde se puede observar y actualizar.
Las conclusiones de observabilidad extraídas de la segunda y tercera fase se vuelven críticas al volver a fases anteriores para realizar actualizaciones e implementaciones. Al realizar pruebas continuas y recuperar métricas para informar a los procesos anteriores, puede seguir ajustando la aplicación.
Es importante comprender qué acciones puede realizar para practicar la observabilidad en distintos puntos del proceso. En un nivel alto, se producen las siguientes acciones de observabilidad durante el ciclo de vida de la aplicación:
Primera fase
- Los roles no técnicos, como los administradores de productos, practican la observabilidad mediante la idea de las cualidades clave de su aplicación.
- Las partes interesadas pueden definir qué métricas son más importantes para medir el rendimiento de su aplicación, como las métricas de riesgo y seguridad, las métricas de calidad o las métricas de ejecución.
- Teams puede definir objetivos para métricas como la interacción del usuario y la administración de costos.
- Los roles técnicos se centran en identificar plataformas, herramientas y métodos que pueden habilitar la compilación de la aplicación con mayor éxito.
- Este paso podría incluir elegir un patrón para usarlo, elegir un modelo de lenguaje grande (LLM) e identificar los orígenes de datos clave de los que se va a extraer.
Segunda fase
- Durante esta fase, los desarrolladores y científicos de datos pueden configurar su solución para que se supervisen e iteran fácilmente. Para promover la observabilidad más adelante, los ISV pueden:
- Cree conjuntos de datos dorados y conjuntos de datos de conversación multiturno automatizados para la evaluación de copilot.
- Depurar, ejecutar y evaluar el flujo con un subconjunto de datos.
- Cree variaciones para la evaluación del modelo con mensajes diferentes.
- Realice la optimización de los precios y los recursos para reducir los costos de LLM para iterar y compilar.
- Los desarrolladores se centran en realizar experimentos a lo largo del desarrollo y evaluar la calidad de su aplicación antes de implementarlos en producción. Durante esta fase, es fundamental:
- Evalúe el rendimiento general de las aplicaciones con conjuntos de datos de prueba mediante métricas predefinidas, incluida la eficacia del modelo y la solicitud.
- Compare los resultados de estas pruebas, establezca una línea base y, a continuación, implemente el código en producción.
Tercera fase
- Muchos experimentos se realizan mientras la aplicación se usa activamente en producción. Es importante supervisar la solución para asegurarse de que funciona adecuadamente. Durante esta fase:
- La instrumentación de telemetría insertada en la aplicación emite los seguimientos, las métricas y los registros pertinentes.
- Los servicios en la nube emiten el estado de Azure OpenAI y otras métricas pertinentes.
- El almacenamiento de telemetría personalizado contiene datos sobre seguimientos, métricas, registros, uso, consentimiento y otras métricas pertinentes.
- Las experiencias de panel precontenidas permiten a los desarrolladores, científicos de datos y administradores supervisar el rendimiento de la API llM y el estado del sistema en el entorno de producción.
- Los comentarios de los usuarios finales se envían de vuelta a los desarrolladores y científicos de datos para su evaluación para ayudar a mejorar la solución.
La recopilación de datos y telemetría proporciona información sobre las áreas para abordar y mejorar en el futuro. Al realizar pasos preventivos durante la fase de ideación, como identificar las métricas adecuadas y realizar evaluaciones rigurosas de la solución al compilar la aplicación, podrá preparar la solución para que se realice correctamente más adelante.
Desafíos de observabilidad en la inteligencia artificial generativa
Aunque la observabilidad en general puede requerir ISV para navegar por muchos obstáculos, las soluciones de IA generativas presentan consideraciones y desafíos específicos.
Evaluación cualitativa
Dado que las respuestas de solicitud de IA generativas se proporcionan en forma de lenguaje natural, deben evaluarse de forma única. Por ejemplo, se pueden comprobar las cualidades, como la base y la relevancia.
Los ISV deben tener en cuenta la mejor ruta para medir estas cualidades, tanto si eligen la evaluación manual como las métricas asistidas por IA con un humano en el bucle para la validación final.
Independientemente de cómo lo evalúe, es probable que también necesite conjuntos de datos preexistentes para comparar las respuestas a las solicitudes. Estos preparativos pueden significar más trabajo durante el desarrollo de la aplicación a medida que identifica una respuesta ideal a temas comunes de solicitud.
IA responsable
Las nuevas consideraciones y expectativas para la inteligencia artificial ética presentan una necesidad de supervisar la privacidad, la seguridad, la inclusividad, etc. Los ISV deben supervisar estos atributos para promover la seguridad del usuario final, reducir el riesgo y minimizar las experiencias de usuario negativas.
Los seis principios de inteligencia artificial responsable de Microsoft ayudan a promover sistemas de inteligencia artificial seguros, éticos y de confianza. Para promover estos valores dentro de la solución, evaluar la aplicación con estos estándares es fundamental.
Métricas de uso y supervisión de costos
Los tokens son la unidad de medida principal para las aplicaciones de IA generativas, y todas las solicitudes y respuestas se tokenizan para que se puedan medir. El seguimiento del número de tokens usados es esencial, ya que afecta al costo de ejecutar la aplicación.
Métricas de la utilidad
La supervisión de la satisfacción del usuario y el impacto empresarial de la aplicación son tan críticas como métricas de rendimiento o calidad. Dado que la inteligencia artificial interactúa con los clientes de diferentes maneras, hay nuevas consideraciones para supervisar la participación y la retención de los clientes.
La medición de la utilidad de las respuestas de la inteligencia artificial se puede lograr de muchas maneras diferentes. Por ejemplo, los embudos de solicitud y respuesta realizan un seguimiento del tiempo que tarda la interacción en dar lugar a una respuesta útil o utilizable. También es importante tener en cuenta el seguimiento del tiempo que el usuario interactúa con la inteligencia artificial, la longitud de la conversación y el número de veces que el usuario acepta la respuesta proporcionada. En escenarios en los que el usuario puede editar la respuesta, es esencial medir la distancia de edición o la medida en que edite la respuesta.
Métricas de rendimiento
La inteligencia artificial requiere sistemas cada vez más complejos y de alto rendimiento que deben mantenerse correctamente para asegurarse de que la solución pueda procesar rápidamente y eficazmente las solicitudes y los datos. A medida que la inteligencia artificial genera contenido cualitativo con un gran grado de variedad, es importante tener sistemas implementados para evaluar y probar la inteligencia artificial en diferentes escenarios.
Dado que las interacciones de LLM son más complejas que una aplicación típica, deben medirse en varias capas para identificar problemas con la latencia. Por ejemplo, las horas para tokenizar el mensaje del usuario, generar una respuesta y devolver la respuesta a un usuario se pueden medir por separado o en su conjunto. Cada componente individual del flujo de trabajo debe evaluarse para identificar áreas de posibles problemas.
La capacidad de observar la solución también depende del método de implementación. Los ISV suelen adoptar uno de los dos patrones de implementación para sus aplicaciones copilot. Puede implementar y administrar las aplicaciones en un entorno que posee o implementar aplicaciones en un entorno que pertenezca a sus clientes.
Para obtener más información sobre cómo la implementación afecta a la observabilidad en los tipos de solución, visite la guía de observabilidad pro-code.
Métricas para supervisar y evaluar
En el dominio del ISV de las aplicaciones de IA generativas y los modelos de aprendizaje automático, es importante evaluar continuamente la solución e intervenir rápidamente para reducir los comportamientos no deseados. Las métricas de supervisión relacionadas con la experiencia del usuario o los comentarios, los límites de protección y la inteligencia artificial responsable, la coherencia de la salida, la latencia y el costo son esenciales para optimizar el rendimiento de las aplicaciones de copilot.
Evaluación cualitativa mediante métricas asistidas por IA
Para medir la información cualitativa, los ISV pueden usar métricas asistidas por IA para supervisar sus soluciones. Las métricas asistidas por IA usan VM como GPT-4 para evaluar métricas de forma similar al criterio humano, lo que proporciona una entrada más matizadas sobre las funcionalidades de la solución.
Estas métricas suelen requerir parámetros como la pregunta, la respuesta y cualquier contexto circundante de la conversación. En general se dividen en dos categorías:
- Las métricas de riesgo y seguridad supervisan contenido de alto riesgo, como violencia, autolesión, contenido sexual y contenido odioso
- Las métricas de calidad de generación realizan un seguimiento de las medidas cualitativas, como:
- Con base: la respuesta del modelo se alinea con la información del origen del mensaje o de entrada.
- Relevancia: la respuesta del modelo se relaciona con el mensaje original.
- Coherencia: la medida en que la respuesta del modelo es comprensible y similar a la humana.
- Fluidez: la lingüística, la gramática y la sintaxis de la respuesta del modelo.
Las métricas como estas permiten a los ISV evaluar con más facilidad la calidad de las respuestas de su aplicación. Proporcionan una evaluación rápida y medible de muchos valores diferentes que pueden ser difíciles de interpretar.
Estándares de IA responsables
Microsoft se compromete a mantener los estándares de inteligencia artificial responsable. Para admitir esto, hemos establecido un conjunto de estándares de inteligencia artificial responsable que pueden ayudarle a mitigar los riesgos asociados con la ia generativa:
- Responsabilidad
- Transparencia
- Imparcialidad
- Inclusividad
- Confiabilidad y seguridad
- Privacidad y seguridad
Los ISV pueden supervisar las métricas que les notifican cuándo surge un problema. Estas notificaciones podrían incluir métricas cualitativas asistidas por inteligencia artificial que después de la pantalla de respuestas o solicita contenido dañino, o alertar a los ISV a determinados errores o mensajes marcados.
Por ejemplo, Azure OpenAI ofrece soluciones que pueden medir el porcentaje de solicitudes filtradas y respuestas que no devolvieron contenido debido al filtrado de contenido. Los ISV deben supervisar las solicitudes que devuelvan estos errores y apunten a reducir la cantidad que se producen.
Uso y satisfacción del cliente
Algunas características de la inteligencia artificial se pueden supervisar de forma similar a otros tipos de aplicaciones, como supervisar la retención de clientes y el tiempo invertido en usar la aplicación. Sin embargo, hay muchas diferencias en la supervisión de la satisfacción del cliente que se aplican específicamente a la inteligencia artificial:
- Reacción del usuario a la respuesta. Esto se puede medir mediante métricas tan sencillas como si un usuario reacciona a una respuesta con un pulgar hacia arriba o hacia abajo.
- Los cambios del usuario en la respuesta. En escenarios en los que el usuario puede modificar la respuesta de la inteligencia artificial para adaptarse a sus necesidades, se puede obtener información supervisando cuánto modifica el usuario la respuesta. Por ejemplo, es probable que un correo electrónico borrador que el usuario haya cambiado drásticamente no sea tan útil como un correo electrónico borrador que el usuario envió tal como está.
- Uso del usuario de la respuesta. Considere la posibilidad de supervisar si el usuario realiza una acción a través de la aplicación en respuesta a la inteligencia artificial. Si una inteligencia artificial sugiere realizar una acción a través de la aplicación, mida la tasa de usuarios que aceptan la sugerencia.
El objetivo de muchas aplicaciones de inteligencia artificial es crear una respuesta que el usuario encuentre útil. El uso de un embudo de solicitud y respuesta es una manera común de medir la rapidez con la que la solución puede generar una respuesta útil. Este embudo mide la cantidad de tiempo e interacciones que tarda la solución en crear una respuesta con la que el usuario mantiene o finaliza la conversación.
En este concepto, el embudo comienza cuando un usuario envía un mensaje. A medida que la inteligencia artificial genera respuestas con las que el usuario puede interactuar, el embudo se limita a medida que las respuestas se acercan a lo que el usuario quiere. Por ejemplo, el usuario puede editar la respuesta de IA o pedir una respuesta ligeramente diferente. Una vez que el usuario está satisfecho con la interacción, tiene la información específica que estaba buscando y termina el embudo. Medir cuántas interacciones se necesitan para que el mensaje pase de amplia a útil y específica es útil para determinar la eficacia de la aplicación para el cliente.
Al observar cómo los usuarios interactúan con la solución, puede hacer inferencias sobre lo útil que es la aplicación. Si los usuarios usan constantemente las salidas de LLM sin tomar más medidas, es probable que la respuesta sea útil para ellos.
Supervisión de costos
A medida que los recursos necesarios para ejecutar una aplicación de IA generativa pueden agregarse rápidamente, es esencial observarlos de forma coherente.
Algunas áreas que pueden afectar a la optimización de costos de la aplicación incluyen:
- Uso de GPU
- Consideraciones y costos de almacenamiento
- Consideraciones sobre escalado
Garantizar la visibilidad de estas métricas puede ayudarle a mantener los costos bajo control, mientras que la configuración de sistemas de alertas o procesos automáticos relacionados con estas métricas también puede ser útil para solicitar una acción inmediata.
Por ejemplo, el número de tokens de solicitud y finalización que usa la aplicación afecta directamente al uso de GPU y al costo de operar la solución. Supervisar detenidamente el uso del token y configurar alertas si cruza determinados umbrales puede ayudarle a mantenerse al tanto del comportamiento de la aplicación.
Disponibilidad y rendimiento de la solución
Al igual que con todas las soluciones, la supervisión coherente de las aplicaciones de inteligencia artificial puede ayudar a impulsar un alto nivel de rendimiento. Una diferencia importante entre las aplicaciones de IA generativas y otras es el concepto de tokenización, que debe tenerse en cuenta al medir el rendimiento.
Los ISV que crean soluciones de inteligencia artificial generativa pueden medir:
- Hora de representar el primer token
- Los tokens representados por segundo
- Solicitudes por segundo que la aplicación puede administrar
Aunque todas estas métricas se pueden medir como un grupo, también es importante tener en cuenta que las VM tienen varias capas. Por ejemplo, el tiempo necesario para que la inteligencia artificial genere una respuesta se compone del tiempo que se tarda en:
- Recepción del mensaje del usuario
- Procesamiento de la solicitud a través de la tokenización
- Inferencia de cualquier información pertinente que falte
- Generar una respuesta
- Compile esta información en una respuesta mediante la destokenización.
- Devolver esta respuesta al usuario
La medición en cada uno de estos pasos puede ayudarle a identificar retrasos y dónde se producen, lo que le permite solucionar el problema en su origen.
Otras técnicas de evaluación de ia generativa
Conjuntos de datos Dorados
Un Golden Dataset es una colección de respuestas de expertos a preguntas realistas del usuario que se usan para proporcionar garantía de calidad de copilot. Estas respuestas no se usan para entrenar el modelo, pero se pueden comparar con las respuestas que el modelo proporciona a la misma pregunta de usuario.
Aunque no es una métrica que puede medir, tener una respuesta estandarizada de alta calidad, puede comparar las respuestas de LLM para ayudar a las salidas de la solución. De este modo, crear sus propios conjuntos de datos golden para evaluar el rendimiento de copilot ayuda a acelerar el proceso de evaluación de copilot.
Simulación de conversación multiturno
La selección manual de conjuntos de datos de evaluación se puede limitar principalmente a las conversaciones de un solo turno debido a la dificultad de crear chats multiturno de sonido natural. En lugar de escribir interacciones con scripts para comparar las respuestas del modelo, los ISV pueden desarrollar conversaciones simuladas para probar las capacidades de conversación multiturno de su copiloto.
Esta simulación podría generar diálogo al permitir que la inteligencia artificial interactúe con un usuario virtual sencillo. A continuación, este usuario interactuaría con la inteligencia artificial a través de un script generado previamente de avisos o lo generaría a través de la inteligencia artificial, lo que le permite crear un gran número de conversaciones de prueba que se van a evaluar. También puede emplear evaluadores humanos para interactuar con la aplicación y generar conversaciones más largas para revisar.
Al evaluar las interacciones de la aplicación dentro de una conversación más larga, puede evaluar la eficacia con la que identifica la intención del usuario y usa el contexto en toda la conversación. Tantas soluciones de IA generativas están diseñadas para basarse en varias interacciones del usuario, es esencial evaluar cómo controla la aplicación las conversaciones de varios turnos.
Herramientas de desarrollo para empezar
Los desarrolladores de ISV y los científicos de datos deben usar herramientas y métricas para evaluar sus soluciones LLM. Microsoft tiene muchas opciones disponibles para explorar.
Azure AI Foundry
azure AI Foundry proporciona características de observabilidad para la administración de modelos, pruebas comparativas de modelos, seguimiento, evaluación y ajuste de la solución LLM.
Admite dos tipos de métricas automatizadas para evaluar aplicaciones de IA generativas: métricas tradicionales de ML y métricas asistidas por IA. También puede usar el área de juegos de chat y las características relacionadas fácilmente probar el modelo.
Flujo de avisos
El flujo de avisos es un conjunto de herramientas de desarrollo diseñadas para simplificar el ciclo de desarrollo integral de aplicaciones de inteligencia artificial basadas en LLM, desde la creación de prototipos y pruebas hasta la implementación y la supervisión. El SDK de flujo de mensajes proporciona:
- Evaluadores integrados que admiten evaluadores personalizados basados en código o basados en mensajes a través de Prompty para satisfacer las necesidades de evaluación específicas de la tarea.
- Seguimiento de mensajes que realiza un seguimiento de las entradas, salidas y contexto de las solicitudes, y permite a los desarrolladores identificar las causas y los orígenes de los problemas del modelo.
- Paneles de supervisión incluidos el sistema (por ejemplo, el uso de tokens, la latencia) y las métricas personalizadas desde la evaluación hasta admitir la observabilidad previa y posterior a la implementación en Fundición de IA de Azure y Application Insights.
Otras herramientas
Prompty es una clase de recurso independiente del lenguaje para crear y administrar mensajes de LLM. Permite acelerar el proceso de desarrollo proporcionando opciones para diseñar, probar y mejorar sus soluciones.
PyRIT (Python Risk Identification Tool for Generative AI) es el marco de automatización abierto de Microsoft para sistemas de inteligencia artificial generativa de formación de equipos rojos. Permite evaluar la solidez de los copilotos contra diferentes categorías de daños.
Pasos siguientes
Al diseñar la aplicación de inteligencia artificial generativa con observabilidad y supervisión en mente, puede evaluar su calidad desde el desarrollo hasta la producción. Empiece a trabajar con las herramientas disponibles para empezar a desarrollar la aplicación o explorar las opciones para supervisar una solución que ya está en producción.
Recursos adicionales
Evaluación de LLM: Un marco de métrica completo: Microsoft Research
Instrucciones adicionales sobre cómo evaluar la aplicación LLM
Introducción al flujo de mensajes: Azure Machine Learning | Microsoft Learn
Información sobre cómo configurar y empezar a trabajar con el flujo de solicitud