Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Este artículo detalla cómo modificar la versión y la configuración del modelo en el generador de indicaciones. La versión y la configuración del modelo pueden afectar al rendimiento y al comportamiento del modelo IA generativa.
Selección del modelo
Para cambiar el modelo, seleccione Modelo en la parte superior del generador de mensajes. El menú desplegable le permite seleccionar entre los modelos IA generativa que generan respuestas a su solicitud personalizada.
El uso de mensajes en Power Apps o Power Automate consume créditos de creación de mensajes, mientras que el uso de mensajes en Copilot Studio consume créditos de Copilot. Obtenga más información en Licencias y créditos del generador de solicitudes en la documentación de AI Builder.
Información general
La siguiente tabla describe los diferentes modelos disponibles.
Los modelos tienen una disponibilidad diferente entre regiones y se actualizan periódicamente. Obtenga más información en Preguntar la disponibilidad del modelo por región y actualizaciones.
Nota
- GPT-4o mini y GPT-4o siguen utilizándose en regiones gubernamentales de EE. UU. Estos modelos siguen las reglas de licencias y ofrecen funcionalidades comparables a GPT-4.1 mini y GPT-4.1, respectivamente.
- Los modelos antrópicos se hospedan fuera de Microsoft y están sujetos a términos y tratamiento de datos antrópicos. Descubre más en Elige un modelo externo como modelo principal de IA.
| Modelo GPT | Licencias | Funcionalidades | Categoría |
|---|---|---|---|
| GPT-4.1 mini (modelo por defecto) | Tasa básica | Entrenado en datos hasta junio de 2024. Introduce hasta 128K tokens. | Mini |
| GPT-4.1 | Tasa estándar | Entrenado en datos hasta junio de 2024. Contexto permitido hasta 128K tokens. | General |
| Chat de GPT-5 | Tasa estándar | Entrenado en datos hasta septiembre de 2024. Contexto permitido hasta 128K tokens. | General |
| GPT-5 razonamiento | Tarifa Premium | Entrenado en datos hasta septiembre de 2024. Contexto permitido hasta 400K tokens. | Profundo |
| Razonamiento de GPT-5.2 | Tarifa Premium | Entrenado en datos hasta octubre de 2024. Contexto permitido hasta 400K tokens. | Profundo |
| Chat de GPT-5.3 | Tasa estándar | Modelo administrado. Contexto permitido hasta 128K tokens. | General |
| Claude Soneto 4.6 | Tasa estándar | Modelo externo de Anthropic. Contexto permitido hasta 200K tokens. | General |
| Claude Opus 4.6 | Tarifa Premium | Modelo externo de Anthropic. Contexto permitido hasta 200K tokens. | Profundo |
| Grok 4.1 Fast (sin razonamiento) (consulte la nota importante siguiente) | Tasa estándar | Modelo externo de xAI. | General |
Importante
Las evaluaciones de inteligencia artificial responsable y seguridad de Microsoft encontraron que Grok-4.1 Fast (sin razonamiento) está menos alineado que otros modelos evaluados, lo que genera (i) mayores riesgos de que el modelo produzca contenido potencialmente dañino y (ii) puntuaciones más bajas en los indicadores de seguridad y jailbreak. Grok-4.1 Fast (sin razonamiento) es capaz de producir contenido explícito y puede hacerlo con una mayor propensión que otros modelos. Los clientes deben cumplir con el Código de Conducta de los Servicios de IA Empresarial de Microsoft y los Términos de Servicio Empresariales de xAI, incluida su Directiva de Uso Aceptable. Además, puede haber categorías de daño que este modelo puede producir que no están cubiertos por los sistemas de seguridad de contenido de Microsoft. Por lo tanto, al igual que con todos los modelos experimentales, Grok-4.1 Fast (sin razonamiento) no se recomienda para el uso en producción y los clientes deben revisar las limitaciones de los modelos experimentales y de vista previa y realizar sus propias evaluaciones antes de elegir Grok-4.1 Fast (sin razonamiento).
Licencias
En agentes, flujos o aplicaciones, las solicitudes que usan modelos consumen Créditos de Copilot, independientemente de la fase de lanzamiento de los modelos. Infórmate más sobre tarifas y gestión de facturación.
Si tiene créditos de AI Builder, el sistema los consume primero cuando se usan mensajes en Power Apps y Power Automate. El sistema no consume créditos de AI Builder cuando se utilizan solicitudes en Copilot Studio. Obtenga más información en Información general de licencias en la documentación de AI Builder.
Etapas de lanzamiento
Los modelos pasan por diferentes etapas de lanzamiento. Puedes probar modelos experimentales y de vista previa nuevos y de vanguardia, o elegir un modelo fiable y ampliamente probado y disponible en general.
| Etiqueta | Descripción |
|---|---|
| Experimental | Pensadas para experimentación, no para uso en producción. Sujeto a los términos de versión preliminar y puede tener limitaciones en la disponibilidad y la calidad. |
| Previsualizar | Finalmente, se convierte en un modelo disponible con carácter general, pero actualmente no se recomienda para su uso en producción. Sujeto a los términos de versión preliminar y puede tener limitaciones en la disponibilidad y la calidad. |
| Sin etiqueta | Disponible con carácter general. Puede usar este modelo para el uso de escalado y producción. En la mayoría de los casos, los modelos disponibles con carácter general no tienen limitaciones sobre la disponibilidad y la calidad, pero es posible que algunos todavía tengan algunas limitaciones, como la disponibilidad regional. Importante: Los modelos de Claude antrópicos están en la fase experimental, aunque no muestren una etiqueta. |
| Predeterminada | Modelo predeterminado para todos los agentes y, normalmente, el modelo con mejor rendimiento disponible con carácter general. El modelo predeterminado se actualiza periódicamente a medida que los modelos nuevos y más capaces estén disponibles con carácter general. Los agentes también usan el modelo predeterminado como reserva si un modelo seleccionado está desactivado o no disponible. |
Los modelos experimentales y de vista previa pueden mostrar variabilidad en el rendimiento, la calidad de respuesta, la latencia o el consumo de mensajes. Pueden expirar o no estar disponibles. Están sujetos a términos de versión preliminar.
Categorización
La siguiente tabla describe las diferentes categorías de modelo.
| Categoría | Mini | General | Profundo |
|---|---|---|---|
| Rendimiento | Excelente para la mayoría de tareas | Adecuado para tareas complejas | Entrenado para tareas de razonamiento |
| Velocidad | Procesamiento más rápido | Puede ser más lento debido a la complejidad | Más lento, porque razona antes de responder |
| Casos de uso | Resumen, tareas de información, procesamiento de imágenes y documentos | Tareas avanzadas de creación de contenido y procesamiento de imágenes y documentos | Tareas de análisis y razonamiento de datos, procesamiento de imágenes y documentos |
Elige un mini modelo cuando necesites una solución rentable para tareas moderadamente complejas, tengas recursos computacionales limitados o necesites un procesamiento más rápido. Los mini modelos son ideales para proyectos con limitaciones presupuestarias y aplicaciones como soporte al cliente o análisis eficiente de código.
Elige un modelo general cuando trates con tareas altamente complejas y multimodales que requieren un rendimiento superior y un análisis detallado. Es la mejor opción para proyectos a gran escala donde la precisión y las capacidades avanzadas son cruciales. Un modelo general también es una buena opción cuando tienes el presupuesto y los recursos computacionales para apoyarlo. Los modelos generales son preferibles para proyectos a largo plazo que pueden crecer en complejidad con el tiempo.
Los modelos profundos destacan para proyectos que requieren capacidades avanzadas de razonamiento. Son adecuados para escenarios que requieren resolución de problemas sofisticada y pensamiento crítico. Los modelos Profundos destacan en entornos donde el razonamiento matizado, la toma de decisiones complejas y el análisis detallado son importantes.
Elige entre los modelos según la disponibilidad de la región, funcionalidades, casos de uso y costes. Obtenga información sobre qué modelos están disponibles en su región y las programaciones de retirada de modelos en Disponibilidad del modelo por región y actualizaciones. Obtenga más información sobre los precios en la tabla de tarifas de capacidad de AI Builder.
Configuración del modelo
Puedes acceder al panel de ajustes seleccionando los tres puntos (...) >Ajustes en la parte superior del generador de prompts. También puede modificar las configuraciones siguientes:
- Temperatura: las temperaturas más bajas conducen a resultados predecibles. Las temperaturas más altas permiten respuestas más diversas o creativas.
- Recuperación de registro: número de registros recuperados como fuentes de conocimiento.
- Incluir vínculos en la respuesta: cuando se selecciona, la respuesta incluye citas de vínculos para los registros recuperados.
- Habilitar intérprete de código: Cuando se selecciona, el intérprete de código para generar y ejecutar código está habilitado.
- Nivel de moderación de contenido: El nivel más bajo genera más respuestas, pero puede contener contenido dañino. El nivel más alto de moderación de contenido aplica un filtro más estricto para restringir el contenido dañino y genera menos respuestas.
Temperatura
Establece la temperatura para el modelo de IA generativa usando el control deslizante. Varía entre 0 y 1. Este valor guía al modelo de IA generativa sobre cuánta creatividad (1) frente a la respuesta determinista (0) aporta.
Nota
La configuración de temperatura no está disponible para el modelo de razonamiento GPT-5. Por este motivo, el control deslizante se deshabilita al seleccionar el modelo de razonamiento GPT-5.
La temperatura es un parámetro que controla la aleatoriedad de la salida generada por el modelo de IA. Una temperatura más baja da como resultado resultados más predecibles y conservadores. En comparación, una temperatura más alta permite más creatividad y diversidad en las respuestas. Es una forma de afinar el equilibrio entre aleatoriedad y determinismo en la salida del modelo.
De forma predeterminada, la temperatura es 0, como en las indicaciones creadas anteriormente.
| Temperatura | Funcionalidad | Usar en |
|---|---|---|
| 0 | Resultados más predecibles y conservadores. Las respuestas son más coherentes. |
Solicitudes que requieren alta precisión y menos variabilidad. |
| 1 | Más creatividad y diversidad en las respuestas. Respuestas más variadas y a veces más innovadoras. |
Indicaciones que crean contenido nuevo e innovador. |
Ajustar la temperatura puede influir en la salida del modelo, pero no garantiza un resultado específico. Las respuestas de la IA son inherentemente probabilísticas y pueden variar con el mismo ajuste de temperatura.
Nivel de moderación de contenido
Establece el nivel de moderación de contenido para el prompt usando el control deslizante. Con un nivel de moderación más bajo, tu prompt puede proporcionar más respuestas. Sin embargo, el aumento de respuestas podría afectar la inclusión de contenido dañino (odio y justicia, sexual, violencia, autolesión) de la solicitud.
Nota
La configuración de nivel de moderación de contenido está disponible solo para modelos gestionados. Por este motivo, el control deslizante no está disponible al seleccionar los modelos Anthropic o Fundición de IA de Azure.
Los niveles de moderación varían de Bajo a Alto. El nivel de moderación por defecto para los prompts es Moderado.
Una menor moderación aumenta el riesgo de contenido dañino en las respuestas de su solicitud. Una mayor moderación reduce ese riesgo, pero podría disminuir el número de respuestas.
| Nivel de moderación de contenido | Descripción | Sugerencia de uso |
|---|---|---|
| Low | Podría permitir contenido de odio y equidad, sexual, violencia o autolesiones que muestre instrucciones, acciones, daños o abusos explícitos y graves. Incluye el respaldo, glorificación o promoción de actos graves y dañinos, formas extremas o ilegales de daño, radicalización o intercambio o abuso de poder no consentido. | Utilice para las solicitudes datos de procesamiento que se podrían considerar contenido dañino (por ejemplo, descripciones de violencia o procedimientos médicos). |
| Moderado | Podría permitir contenido de odio y equidad, sexual, violencia o autolesión que utilice lenguaje ofensivo, insultante, burlón, intimidante o denigrante hacia grupos de identidad específicos. Incluye representaciones de búsqueda y ejecución de instrucciones dañinas, fantasías, glorificación y promoción del daño a intensidad media. | Filtrado predeterminado. Adecuado para la mayoría de los usos. |
| High | Podría permitir contenido de odio, falta de equidad, sexual, violencia o autolesión que exprese opiniones prejuiciosas, juiciosas o parciales. Incluye uso ofensivo del lenguaje, estereotipos, casos de uso que exploran un mundo ficticio (por ejemplo, videojuegos, literatura) y representaciones de baja intensidad. | Úsalo si necesitas más filtrado, más restrictivo que el nivel Moderado. |
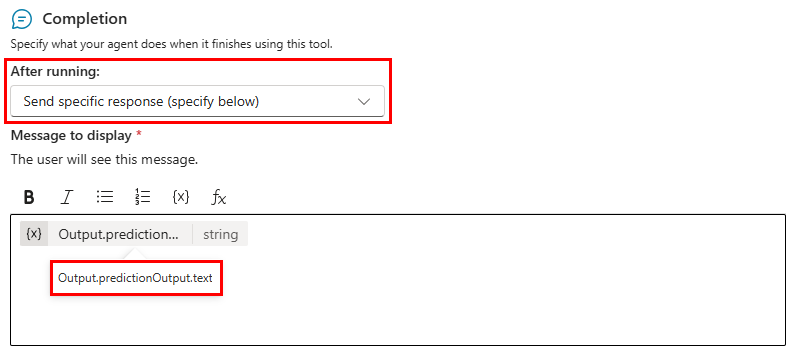
Para anular la configuración de moderación de contenido del agente al usar la solicitud en un agente, establezca la opción Después de ejecutar en la pantalla de Finalización de la herramienta de solicitud a Enviar respuesta específica (especificar a continuación). El mensaje a mostrar debe contener la variable personalizada Output.predictionOutput.text .