Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Los valores de clúster crean automáticamente grupos con valores similares mediante un algoritmo de coincidencia aproximada y, a continuación, asignan el valor de cada columna al grupo con el que mejor se adapte. Esta transformación es útil cuando se trabaja con datos que tienen muchas variaciones diferentes del mismo valor y necesita combinar valores en grupos coherentes.
Considere una tabla de ejemplo con una columna id que contiene un conjunto de identificadores y una columna Person que contiene un conjunto de versiones escritas y en mayúsculas de los nombres Miguel, Mike, William y Bill.
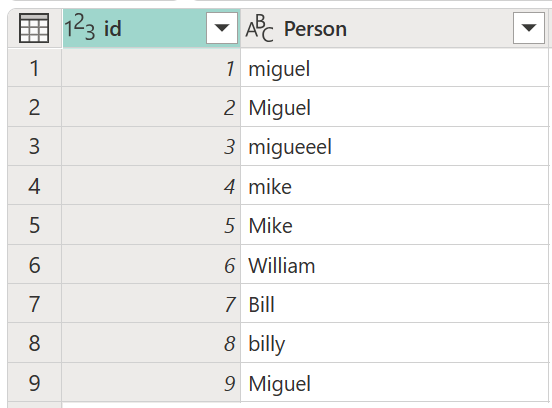
En este ejemplo, el resultado que busca es una tabla con una nueva columna que muestra los grupos correctos de valores de la columna Person y no todas las variaciones diferentes de las mismas palabras.
Nota:
La característica Valores de clúster solo está disponible para Power Query Online.
Creación de una columna de clúster
Para los valores del clúster, seleccione primero la columna Persona , vaya a la pestaña Agregar columna de la cinta de opciones y, a continuación, seleccione la opción Valores de clúster .
![]()
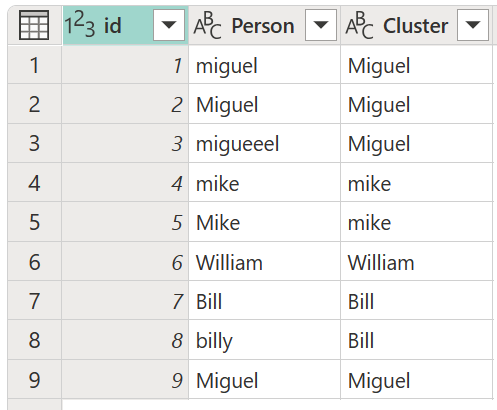
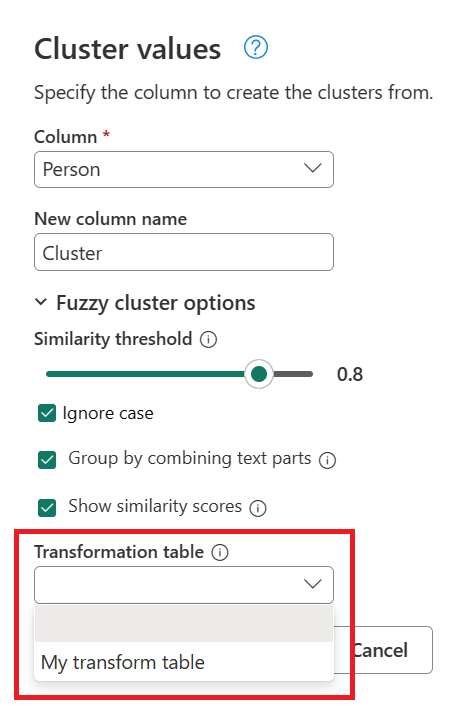
En el cuadro de diálogo Valores de clúster , confirme la columna a partir de la que desea usar para crear los clústeres y escriba el nuevo nombre de la columna. En este caso, asigne un nombre a esta nueva columna Cluster.
El resultado de esa operación se muestra en la siguiente imagen.
Nota:
Para cada clúster de valores, Power Query elige la instancia más frecuente de la columna seleccionada como la instancia "canónica". Si se producen varias instancias con la misma frecuencia, Power Query elige la primera.
Uso de las opciones de clúster difuso
Las siguientes opciones están disponibles para los valores de agrupación en clústeres en una nueva columna:
- Umbral de similitud (opcional): esta opción indica cómo deben agruparse dos valores similares. El valor mínimo de cero (0) hace que todos los valores se agrupe juntos. El valor máximo de 1 solo permite agrupar los valores que coinciden exactamente. El valor predeterminado es 0.8.
- Omitir casos: cuando se comparan cadenas de texto, se ignoran las mayúsculas y minúsculas. Esta opción está habilitada de forma predeterminada.
- Agrupar combinando partes de texto: el algoritmo intenta combinar partes de texto (como combinar Micro y soft en Microsoft) para agrupar valores.
- Mostrar puntuaciones de similitud: muestra puntuaciones de similitud entre los valores de entrada y los valores representativos calculados después de la agrupación en clústeres aproximadas.
- Tabla de transformación (opcional): puede seleccionar una tabla de transformación que asigne valores (como asignar MSFT a Microsoft) para agruparlos.
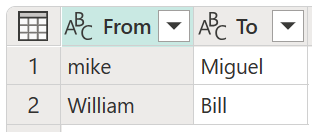
En este ejemplo, se usa una nueva tabla de transformación con el nombre My transform table (Mi tabla de transformación ) para mostrar cómo se pueden asignar los valores. Esta tabla de transformación tiene dos columnas:
- From: cadena de texto que se va a buscar en la tabla.
- To: la cadena de texto que se va a usar para reemplazar la cadena de texto en la columna From .
Importante
Es importante que la tabla de transformación tenga las mismas columnas y nombres de columna que se muestran en la imagen anterior (tienen que denominarse "From" y "To"), de lo contrario, Power Query no reconocerá esta tabla como una tabla de transformación y no tendrá lugar ninguna transformación.
Con la consulta creada anteriormente, haga doble clic en el paso Valores agrupados y, a continuación, en el cuadro de diálogo Valores de clúster, expanda Opciones de clúster aproximadas. En Opciones de clúster aproximadas, habilite la opción Mostrar puntuaciones de similitud . En Tabla de transformación (opcional), seleccione la consulta que tiene la tabla de transformación.
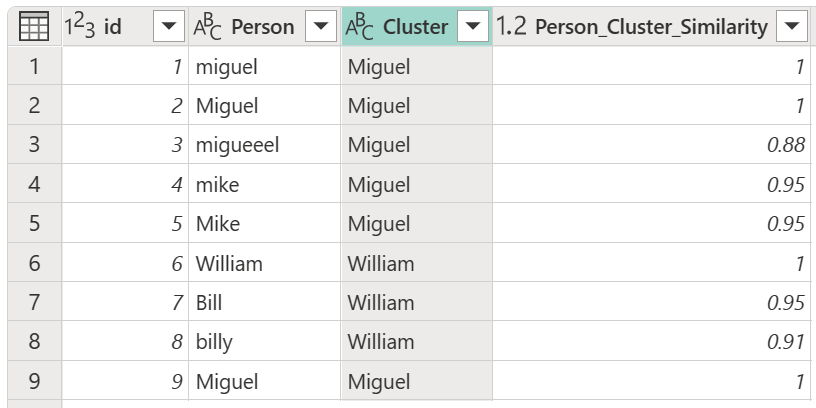
Después de seleccionar la tabla de transformación y habilitar la opción Mostrar puntuaciones de similitud , seleccione Aceptar. El resultado de esa operación proporciona una tabla que contiene las mismas columnas id y Person que la tabla original, pero también incluye dos columnas nuevas denominadas Cluster y Person_Cluster_Similarity. La columna Cluster contiene las versiones correctamente escritas y en mayúsculas de los nombres Miguel para las versiones de Miguel y Mike, y William para las versiones de Bill, Billy y William. La columna Person_Cluster_Similarity contiene las puntuaciones de similitud para cada uno de los nombres.
Preceptos de la tabla de transformación
Es posible que observe que la tabla de transformación de la sección anterior parecía indicar que las instancias de Mike se cambiaron a Miguel y las instancias de William se cambiaron a Bill. Sin embargo, en la tabla resultante, las apariciones de Bill y "billy" se cambiaron a William. En la tabla de transformación, en lugar de ser una ruta directa desde a hasta, la tabla de transformación es simétrica durante el clustering, lo que significa que "mike" es equivalente a "Miguel" y viceversa. El resultado de los equivalentes proporcionados en la tabla de transformación depende de las reglas siguientes:
- Si hay una mayoría de valores idénticos, estos valores tienen prioridad sobre los valores no identificadores.
- Si no hay mayoría de valores, el valor que aparece primero tiene prioridad.
Por ejemplo, en la tabla original usada en este artículo, las versiones de Miguel (tanto "miguel" como Miguel) en la columna Person constituyen la mayoría de las instancias del nombre Miguel y Mike. Además, el nombre Miguel con mayúsculas iniciales constituye la mayoría del nombre Miguel. Por lo tanto, la asociación de Miguel y sus derivados y Mike y sus derivados en la tabla de transformación da como resultado el nombre Miguel que se usa en la columna Clúster .
Sin embargo, para los nombres William, Bill y "billy", no hay mayoría de valores, ya que los tres son únicos. Como William aparece primero, William se usa en la columna Clúster . Si "billy" había aparecido primero en la tabla, se usaría "billy" en la columna Clúster . Además, dado que no hay mayoría de valores, se emplea el mismo caso que usan los nombres individuales. Es decir, si William es primero, William con una mayúscula "W" se utilizará como valor de resultado; si "billy" es primero, se utilizará "billy" con una "b" minúscula.