Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Las características de Power Query, como la combinación aproximada, los valores del clúster y la agrupación aproximada , usan los mismos mecanismos para funcionar como coincidencia aproximada.
En este artículo se describen muchos escenarios que muestran cómo aprovechar las opciones que tiene la coincidencia aproximada, con el objetivo de aclarar "aproximadamente".
Nota:
Aunque la opción de valores de clúster solo está disponible en Power Query Online, los mecanismos que se muestran en esta sección también se aplican a la combinación aproximada y la agrupación aproximada.
Ajuste del umbral de similitud
El mejor escenario para aplicar el algoritmo de coincidencia aproximada es cuando todas las cadenas de texto de una columna contienen solo las cadenas que deben compararse y no hay componentes adicionales. Por ejemplo, comparar Apples con produce puntuaciones de similitud más altas que comparar con 4ppl3sApplesMy favorite fruit, by far, is Apples. I simply love them! .
Dado que la palabra Apples de la segunda cadena es solo una pequeña parte de la cadena de texto completa, esa comparación produce una puntuación de similitud inferior.
Por ejemplo, el siguiente conjunto de datos consta de respuestas de una encuesta que solo tenía una pregunta: "¿Cuál es su fruta favorita?"
| Fruta |
|---|
| Arándanos |
| Las bayas azules son simplemente las mejores |
| Fresas |
| Fresas = <3 |
| Apples |
| 'sples |
| 4ppl3s |
| Plátanos |
| Mi fruta favorita son los plátanos. |
| Banas |
| Mi fruta favorita, de lejos, es Manzanas. ¡Simplemente los amo! |
La encuesta proporcionó un único cuadro de texto para introducir el valor y no tenía ninguna validación.
Ahora tiene la tarea de agrupar en clústeres los valores. Para realizar esa tarea, cargue la tabla anterior de frutas en Power Query, seleccione la columna y, a continuación, seleccione la opción Valores de clúster en la pestaña Agregar columna de la cinta de opciones.
![]()
Aparece el cuadro de diálogo Valores del clúster , donde puede especificar el nombre de la nueva columna. Asigne a esta nueva columna el nombre Cluster (Clúster ) y seleccione Aceptar.
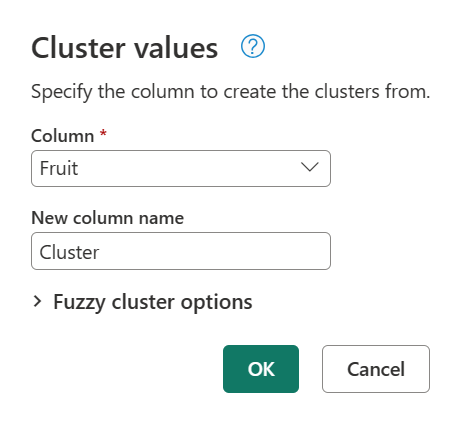
De forma predeterminada, Power Query usa un umbral de similitud de 0,8 (o 80%). El valor mínimo de 0,00 hace que todos los valores con cualquier nivel de similitud coincidan entre sí y el valor máximo de 1,00 solo permite coincidencias exactas. Una "coincidencia exacta" aproximada podría omitir diferencias como mayúsculas y minúsculas, orden de palabras y puntuación. El resultado de la operación anterior produce la tabla siguiente con una nueva columna Clúster .
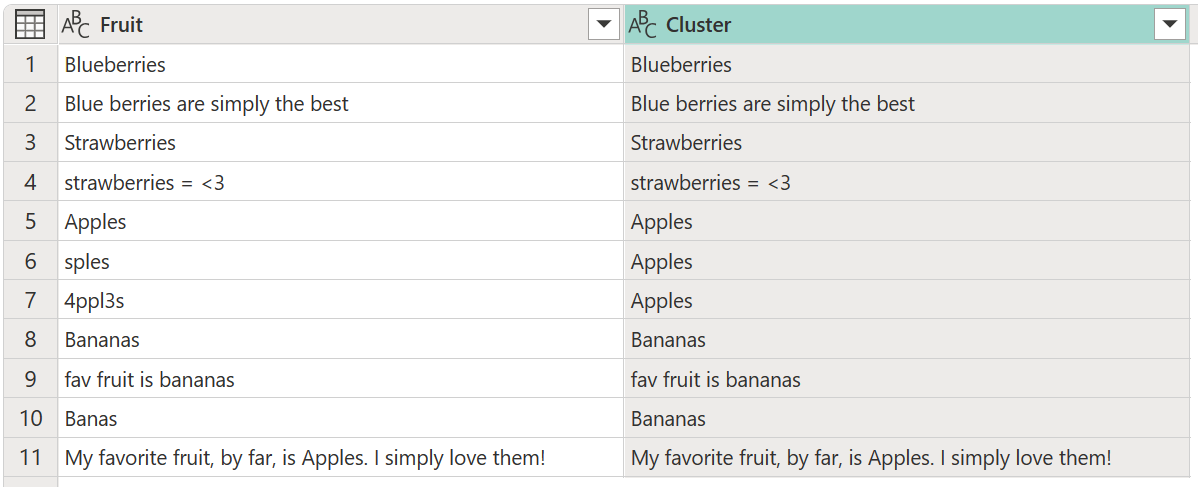
Mientras se realiza la agrupación en clústeres, no proporciona los resultados esperados para todas las filas. El número de fila dos (2) todavía tiene el valor Blue berries are simply the best, pero debe estar agrupado en Blueberries, y algo similar sucede con las cadenas Strawberries = <3de texto , fav fruit is bananasy My favorite fruit, by far, is Apples. I simply love them!.
Para determinar lo que está causando esta agrupación en clústeres, haga doble clic en Valores agrupados en el panel Pasos aplicados para devolver el cuadro de diálogo Valores del clúster. Dentro de este cuadro de diálogo, expanda Opciones de clúster aproximadas. Habilite la opción Mostrar puntuaciones de similitud y seleccione Aceptar.
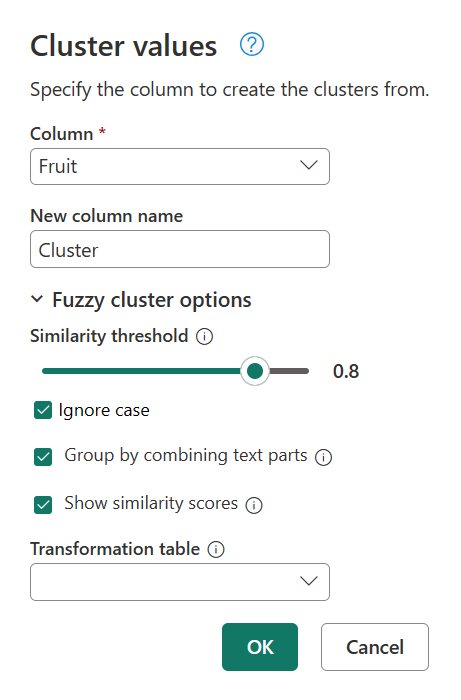
Al habilitar la opción Mostrar puntuaciones de similitud , se crea una nueva columna en la tabla. Esta columna muestra la puntuación de similitud exacta entre el clúster definido y el valor original.

Tras una inspección más detallada, Power Query no pudo encontrar ningún otro valor en el umbral de similitud de las cadenas Blue berries are simply the bestde texto ,Strawberries = <3 , fav fruit is bananasy My favorite fruit, by far, is Apples. I simply love them!.
Vuelva al cuadro de diálogo Valores de clúster una vez más haciendo doble clic en Valores agrupados en el panel Pasos aplicados . Cambie el umbral de similitud de 0,8 a 0,6 y, a continuación, seleccione Aceptar.
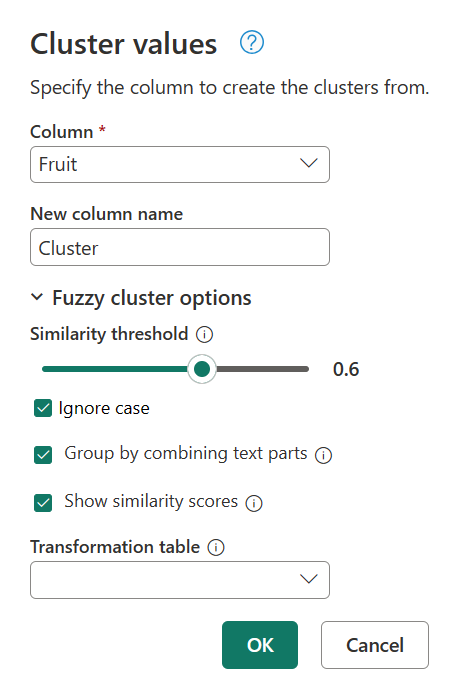
Este cambio le acerca al resultado que busca, excepto para la cadena My favorite fruit, by far, is Apples. I simply love them!de texto . Al cambiar el valor del umbral de similitud de 0,8 a 0,6, Power Query ahora pudo usar los valores con una puntuación de similitud que comienza de 0,6 hasta 1.

Nota:
Power Query siempre usa el valor más cercano al umbral para definir los clústeres. El umbral define el límite inferior de la puntuación de similitud aceptable para asignar el valor a un clúster.
Puede intentarlo de nuevo cambiando la puntuación de similitud de 0,6 a un número inferior hasta que obtenga los resultados que busca. En este caso, cambie la puntuación de similitud a 0,5. Este cambio produce el resultado exacto que espera con la cadena My favorite fruit, by far, is Apples. I simply love them! de texto asignada ahora al clúster Apples.

Nota:
Actualmente, solo la característica Valores de clúster de Power Query Online proporciona una nueva columna con la puntuación de similitud.
Consideraciones especiales para la tabla de transformación
La tabla de transformación le ayuda a asignar valores de la columna a nuevos valores antes de realizar el algoritmo de coincidencia aproximada.
Algunos ejemplos de cómo se puede usar la tabla de transformación:
- Tabla de transformación en valores de clúster
- Tabla de transformación en consultas de combinación aproximadas
- Tabla de transformación en grupo por
Importante
Cuando se usa la tabla de transformación, la puntuación de similitud máxima para los valores de la tabla de transformación es 0,95. Esta penalización deliberada de 0,05 se aplica para distinguir que el valor original de dicha columna no es igual a los valores a los que se comparó desde que se produjo una transformación.
En escenarios en los que primero desea asignar los valores y, a continuación, realizar la coincidencia aproximada sin la penalización 0,05, se recomienda reemplazar los valores de la columna y, a continuación, realizar la coincidencia aproximada.