Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a:![]() SQL Server en Linux
SQL Server en Linux
En esta guía se proporcionan instrucciones para crear un clúster e conmutación por error de disco compartido de dos nodos para SQL Server en Red Hat Enterprise Linux. La capa de agrupación en clústeres se basa en el complemento de alta disponibilidad de Red Hat Enterprise Linux (RHEL) sobre Pacemaker. La instancia de SQL Server está activa en un nodo o en el otro.
Nota
El acceso al complemento de alta disponibilidad y la documentación de Red Hat exige una suscripción.
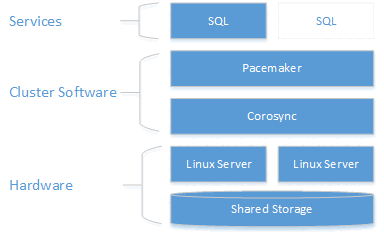
Como se muestra en el diagrama siguiente, el almacenamiento se presenta en dos servidores. Los componentes de agrupación en clústeres (Corosync y Pacemaker) coordinan las comunicaciones y la administración de recursos. Uno de los servidores tiene la conexión activa a los recursos de almacenamiento y SQL Server. Cuando Pacemaker detecta un error, los componentes de agrupación en clústeres son responsables del traslado de los recursos al otro nodo.
Para obtener más información sobre la configuración del clúster, las opciones de los agentes de recursos y la administración, vaya a la documentación de referencia de RHEL.
En este momento, la integración de SQL Server con Pacemaker no es tan perfecta como con WSFC en Windows. Desde dentro de SQL Server no hay conocimiento sobre la presencia del clúster, toda la orquestación está fuera y Pacemaker controla el servicio como una instancia independiente. Por ejemplo, el clúster dmvs sys.dm_os_cluster_nodes y sys.dm_os_cluster_properties no tendrá ningún registro.
Para usar una cadena de conexión que apunte al nombre de servidor de una cadena y no use la dirección IP, se tiene que registrar en su servidor DNS la dirección IP usada para crear el recurso de IP virtual (como se explica en las secciones siguientes) con el nombre de servidor elegido.
En las secciones siguientes, se describen los pasos necesarios para configurar una solución de clúster de conmutación por error.
Requisitos previos
Para completar el siguiente escenario de un extremo a otro, necesita dos máquinas para implementar el clúster de dos nodos y otro servidor para configurar el servidor de NFS. En los pasos siguientes se describe cómo configurar estos servidores.
Instalación y configuración del sistema operativo en cada nodo de clúster
El primer paso es configurar el sistema operativo en los nodos del clúster. A efectos de este tutorial, use RHEL con una suscripción válida para el complemento de alta disponibilidad.
Instalación y configuración de SQL Server en cada nodo de clúster
Instale y configure SQL Server en ambos nodos. Para obtener instrucciones detalladas, vea Guía de instalación de SQL Server en Linux.
Para configurarlos, designe un nodo como principal y el otro como secundario. Use estos términos durante esta guía.
En el nodo secundario, detenga y deshabilite SQL Server.
En el siguiente ejemplo se detiene y se deshabilita SQL Server:
sudo systemctl stop mssql-server sudo systemctl disable mssql-server
Nota
En el momento de la instalación, se genera una clave maestra del servidor para la instancia de SQL Server y se coloca en /var/opt/mssql/secrets/machine-key. En Linux, SQL Server siempre se ejecuta como una cuenta local denominada mssql. Dado que se trata de una cuenta local, su identidad no se comparte entre los nodos. Por lo tanto, debe copiar la clave de cifrado del nodo principal en cada nodo secundario para que cada cuenta local de mssql pueda acceder a ella y así descifrar la clave maestra del servidor.
En el nodo principal, cree un inicio de sesión de SQL Server para Pacemaker y conceda el permiso de inicio de sesión para ejecutar
sp_server_diagnostics. Pacemaker usa esta cuenta para comprobar qué nodo ejecuta SQL Server.sudo systemctl start mssql-serverConéctese a la base de datos de SQL Server
mastercon la cuenta desay ejecute lo siguiente:USE [master]; GO CREATE LOGIN [<loginName>] WITH PASSWORD = N'<password>'; ALTER SERVER ROLE [sysadmin] ADD MEMBER [<loginName>];Precaución
La contraseña debe seguir la directiva de contraseña predeterminada de SQL Server. De forma predeterminada, la contraseña debe tener al menos ocho caracteres y contener caracteres de tres de los siguientes cuatro conjuntos: mayúsculas, minúsculas, dígitos en base 10 y símbolos. Las contraseñas pueden tener hasta 128 caracteres. Use contraseñas lo más largas y complejas posible.
Como alternativa, puede establecer los permisos con más detalle. El inicio de sesión de Pacemaker requiere
VIEW SERVER STATEpara consultar el estado de mantenimiento consp_server_diagnostics,setupadminyALTER ANY LINKED SERVERpara actualizar el nombre de instancia de FCI con el nombre de recurso mediante la ejecución desp_dropserverysp_addserver.En el nodo principal, detenga y deshabilite SQL Server.
Configure el archivo de hosts para cada nodo de clúster. El archivo de host debe incluir la dirección IP y el nombre de cada nodo de clúster.
Compruebe la dirección IP de cada nodo. En el siguiente script se muestra la dirección IP del nodo actual.
sudo ip addr showEstablezca el nombre de equipo en cada nodo. Asigne a cada nodo un nombre único que tenga 15 caracteres o menos. Para establecer el nombre de equipo, agréguelo a
/etc/hosts. El siguiente script le permite editar/etc/hostsconvi.sudo vi /etc/hostsEn el ejemplo siguiente se muestra
/etc/hostscon adiciones para dos nodos denominadossqlfcivm1ysqlfcivm2.127.0.0.1 localhost localhost4 localhost4.localdomain4 ::1 localhost localhost6 localhost6.localdomain6 10.128.18.128 sqlfcivm1 10.128.16.77 sqlfcivm2
En la siguiente sección, configurará el almacenamiento compartido y moverá los archivos de base de datos a ese almacenamiento.
Configuración del almacenamiento compartido y movimiento de los archivos de base de datos
Hay varias soluciones para proporcionar almacenamiento compartido. En este tutorial se muestra cómo configurar el almacenamiento compartido con NFS. Se recomienda seguir los procedimientos recomendados y usar Kerberos para proteger NFS. Para obtener un ejemplo, consulte RHEL7: Usar Kerberos para controlar el acceso a los recursos compartidos de red NFS.
Advertencia
Si no protege NFS, cualquier persona que pueda acceder a la red y suplantar la dirección IP de un nodo SQL podrá acceder a los archivos de datos. Como siempre, asegúrese de llevar a cabo un análisis del modelo de amenazas de su sistema antes de usarlo en producción. Otra opción de almacenamiento es usar el recurso compartido de archivos SMB.
Configuración del almacenamiento compartido con NFS
Importante
En esta versión no se admite el hospedaje de archivos de base de datos en un servidor NFS con una versión <4. Esto incluye el uso de NFS para la agrupación en clústeres de conmutación por error de discos compartidos, así como las bases de datos en instancias no agrupadas. Estamos trabajando para habilitar otras versiones del servidor NFS en las próximas versiones.
Lleve a cabo los siguientes pasos en el servidor NFS:
Instale
nfs-utils:sudo yum -y install nfs-utilsHabilitar e iniciar
rpcbind:sudo systemctl enable rpcbind && sudo systemctl start rpcbindHabilitar e iniciar
nfs-server:sudo systemctl enable nfs-server && sudo systemctl start nfs-serverEdite
/etc/exportspara exportar el directorio que quiere compartir. Necesita una línea para cada recurso compartido que quiera. Por ejemplo:/mnt/nfs 10.8.8.0/24(rw,sync,no_subtree_check,no_root_squash)Exporte los recursos compartidos:
sudo exportfs -ravCompruebe que las rutas de acceso se comparten o exportan, ejecute desde el servidor NFS:
sudo showmount -eAgregue una excepción en SELinux:
sudo setsebool -P nfs_export_all_rw 1Abra el firewall en el servidor.
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reload
Configuración de todos los nodos de clúster para conectarse al almacenamiento compartido de NFS
Realice los pasos siguientes en todos los nodos del clúster:
Instale
nfs-utils:sudo yum -y install nfs-utilsAbra el firewall en clientes y servidor NFS:
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reloadCompruebe que puede ver los recursos compartidos NFS en máquinas cliente:
sudo showmount -e <IP OF NFS SERVER>Repita estos pasos en todos los nodos del clúster.
Para obtener más información sobre el uso de NFS, consulte los siguientes recursos:
- Servidores NFS y firewalls | Stack Exchange
- Montaje de un volumen NFS | Guía de administradores de red de Linux
- Configuración del servidor NFS | Portal del cliente de Red Hat
Montaje del directorio de archivos de base de datos para que apunte al almacenamiento compartido
Solo en el nodo principal, guarde los archivos de base de datos en una ubicación temporal. El siguiente script crea un directorio temporal, copia los archivos de base de datos en el nuevo directorio y quita los archivos antiguos de base de datos. Como SQL Server se ejecuta como el usuario local
mssql, debe asegurarse de que, después de transferir los datos al recurso compartido montado, el usuario local tiene acceso de lectura y escritura al recurso compartido.sudo su mssql mkdir /var/opt/mssql/tmp cp /var/opt/mssql/data/* /var/opt/mssql/tmp rm /var/opt/mssql/data/* exitEn todos los nodos del clúster, edite el archivo
/etc/fstabpara que incluya el comando mount.<IP OF NFS SERVER>:<shared_storage_path> <database_files_directory_path> nfs timeo=14,intrEl script siguiente muestra un ejemplo de la edición:
10.8.8.0:/mnt/nfs /var/opt/mssql/data nfs timeo=14,intr
Nota
Si usa un recurso del sistema de archivos (FS) como se recomienda aquí, no es necesario conservar el comando de montaje en /etc/fstab. Pacemaker se encargará de montar la carpeta cuando inicie el recurso en clúster del FS. Con la ayuda de las barreras, se asegurará de que el FS nunca se monta dos veces.
Ejecute el comando
mount -apara que el sistema actualice las rutas de acceso montadas.Copie los archivos de base de datos y de registro que guardó en
/var/opt/mssql/tmpen el recurso compartido/var/opt/mssql/datarecién montado. Este paso solo es necesario hacerlo en el nodo principal. Asegúrese de conceder permisos de lectura y escritura al usuario localmssql.sudo chown mssql /var/opt/mssql/data sudo chgrp mssql /var/opt/mssql/data sudo su mssql cp /var/opt/mssql/tmp/* /var/opt/mssql/data/ rm /var/opt/mssql/tmp/* exitCompruebe que SQL Server se inicia correctamente con la nueva ruta de acceso del archivo. Haga esto en cada nodo. En este momento, solo un nodo debe ejecutar SQL Server a la vez. No se pueden ejecutar ambos al mismo tiempo, ya que intentarán acceder a los archivos de datos simultáneamente (para evitar iniciar por error SQL Server en ambos nodos, use un recurso de clúster del sistema de archivos para asegurarse de que el recurso compartido no se monta dos veces en diferentes nodos). Los siguientes comandos inician SQL Server, comprueban el estado y después detienen SQL Server.
sudo systemctl start mssql-server sudo systemctl status mssql-server sudo systemctl stop mssql-server
En este momento, ambas instancias de SQL Server están configuradas para ejecutarse con los archivos de base de datos en el almacenamiento compartido. El siguiente paso consiste en configurar SQL Server para Pacemaker.
Instalación y configuración de Pacemaker en todos los nodos del clúster
En ambos nodos del clúster, cree un archivo para almacenar el nombre de usuario y la contraseña de SQL Server para el inicio de sesión de Pacemaker. Con el siguiente comando se crea y rellena este archivo:
sudo touch /var/opt/mssql/secrets/passwd echo '<loginName>' | sudo tee -a /var/opt/mssql/secrets/passwd echo '<password>' | sudo tee -a /var/opt/mssql/secrets/passwd sudo chown root:root /var/opt/mssql/secrets/passwd sudo chmod 600 /var/opt/mssql/secrets/passwdPrecaución
La contraseña debe seguir la directiva de contraseña predeterminada de SQL Server. De forma predeterminada, la contraseña debe tener al menos ocho caracteres y contener caracteres de tres de los siguientes cuatro conjuntos: mayúsculas, minúsculas, dígitos en base 10 y símbolos. Las contraseñas pueden tener hasta 128 caracteres. Use contraseñas lo más largas y complejas posible.
En ambos nodos del clúster, abra los puertos de firewall de Pacemaker. Para abrir estos puertos con
firewalld, ejecute el comando siguiente:sudo firewall-cmd --permanent --add-service=high-availability sudo firewall-cmd --reloadSi usa otro firewall que no tiene una configuración de alta disponibilidad integrada, deberán abrirse los puertos siguientes para que Pacemaker pueda comunicarse con otros nodos del clúster:
- TCP: puertos 2224, 3121, 21064
- UDP: puerto 5405
Instale paquetes de Pacemaker en cada nodo.
sudo yum install pacemaker pcs fence-agents-all resource-agentsEstablezca la contraseña para el usuario predeterminado que se crea al instalar paquetes de Pacemaker y Corosync. Use la misma contraseña en ambos nodos.
sudo passwd haclusterHabilite e inicie el servicio
pcsdy Pacemaker. Esto permitirá que los nodos se unan al clúster después del reinicio. Ejecute el comando siguiente en ambos nodos.sudo systemctl enable pcsd sudo systemctl start pcsd sudo systemctl enable pacemakerInstale el agente de recursos de FCI para SQL Server. Ejecute los comandos siguientes en ambos nodos.
sudo yum install mssql-server-ha
Configuración del agente de barrera
Un dispositivo STONITH proporciona un agente de barrera. En Configuración de Pacemaker en Red Hat Enterprise Linux en Azure se proporciona un ejemplo de cómo crear un dispositivo STONITH para este clúster en Azure. Modifique las instrucciones para el entorno.
Creación del clúster
En uno de los nodos, cree el clúster.
sudo pcs cluster auth <nodeName1 nodeName2 ...> -u hacluster sudo pcs cluster setup --name <clusterName> <nodeName1 nodeName2 ...> sudo pcs cluster start --allConfigure los recursos de clúster para SQL Server, el sistema de archivos y los recursos de IP virtual e inserte la configuración en el clúster. Necesita la siguiente información:
- Nombre del recurso de SQL Server: nombre de recurso de SQL Server en clúster.
- Nombre de recurso de IP flotante: nombre de recurso de la dirección IP virtual.
- Dirección IP: dirección IP que los clientes usan para conectarse a la instancia en clúster de SQL Server.
- Nombre de recurso del sistema de archivos: nombre de recurso del sistema de archivos.
- dispositivo: ruta de acceso del recurso compartido de NFS.
- dispositivo: ruta de acceso local que se monta en el recurso compartido.
-
fstype: tipo de recurso compartido de archivos (es decir,
nfs)
Actualice los valores del siguiente script para su entorno. Ejecute en un nodo para configurar e iniciar el servicio en clúster.
sudo pcs cluster cib cfg sudo pcs -f cfg resource create <sqlServerResourceName> ocf:mssql:fci sudo pcs -f cfg resource create <floatingIPResourceName> ocf:heartbeat:IPaddr2 ip=<ip Address> sudo pcs -f cfg resource create <fileShareResourceName> Filesystem device=<networkPath> directory=<localPath> fstype=<fileShareType> sudo pcs -f cfg constraint colocation add <virtualIPResourceName> <sqlResourceName> sudo pcs -f cfg constraint colocation add <fileShareResourceName> <sqlResourceName> sudo pcs cluster cib-push cfgPor ejemplo, el siguiente script crea un recurso en clúster de SQL Server denominado
mssqlhay recursos con una dirección IP flotante10.0.0.99. También crea un recurso de sistema de archivos y agrega restricciones para que todos los recursos se coloquen en el mismo nodo que el recurso de SQL.sudo pcs cluster cib cfg sudo pcs -f cfg resource create mssqlha ocf:mssql:fci sudo pcs -f cfg resource create virtualip ocf:heartbeat:IPaddr2 ip=10.0.0.99 sudo pcs -f cfg resource create fs Filesystem device="10.8.8.0:/mnt/nfs" directory="/var/opt/mssql/data" fstype="nfs" sudo pcs -f cfg constraint colocation add virtualip mssqlha sudo pcs -f cfg constraint colocation add fs mssqlha sudo pcs cluster cib-push cfgUna vez insertada la configuración, SQL Server se iniciará en un nodo.
Confirme que se ha iniciado SQL Server.
sudo pcs statusEn los siguientes ejemplos se muestran los resultados si Pacemaker ha iniciado correctamente una instancia en clúster de SQL Server.
fs (ocf::heartbeat:Filesystem): Started sqlfcivm1 virtualip (ocf::heartbeat:IPaddr2): Started sqlfcivm1 mssqlha (ocf::mssql:fci): Started sqlfcivm1 PCSD Status: sqlfcivm1: Online sqlfcivm2: Online Daemon Status: corosync: active/disabled pacemaker: active/enabled pcsd: active/enabled